📄 Phrased: Phrase Dictionary Biasing for Speech Translation
#语音翻译 #偏差学习 #多语言 #流式处理 #多模态模型
✅ 7.5/10 | 前25% | #语音翻译 | #偏差学习 | #多语言 #流式处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Peidong Wang(Microsoft CoreAI)
- 通讯作者:Jinyu Li(Microsoft CoreAI)
- 作者列表:Peidong Wang(Microsoft CoreAI)、Jian Xue(Microsoft CoreAI)、Rui Zhao(Microsoft CoreAI)、Junkun Chen(Microsoft CoreAI)、Aswin Shanmugam Subramanian(Microsoft CoreAI)、Jinyu Li(Microsoft CoreAI)
💡 毒舌点评
亮点:本文提出的PHRASED方法具有良好的通用性,能将同一个思路(利用双语短语对)同时应用于传统的流式端到端模型(CTC-GMM)和新兴的多模态大模型,并在后者上实现了显著的短语召回率提升。短板:实验仅在中-英翻译任务上验证,且所用的“短语列表”规模(3K)与真实工业场景(可能包含数十万条目)的匹配度和鲁棒性存疑;此外,论文未提供任何代码或模型,极大地限制了其可复现性和直接应用价值。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:评估使用了RealSI和OntoNote5,但未说明是否提供了预处理后的版本或获取方式。
- Demo:未提及。
- 复现材料:论文给出了一些训练超参数(如学习率、步数)和模型规模,但未提供完整的训练配置、数据预处理脚本或评估代码。不足以支撑完全复现。
- 论文中引用的开源项目:未提及依赖的特定开源工具/模型,Phi-4-multimodal为外部开源模型。
- 总体,论文中未提及开源计划。
📌 核心摘要
- 要解决的问题:实体短语(如专有名词、新词)因在训练数据中罕见,在端到端语音翻译(ST)中容易被错误翻译,影响核心语义理解。
- 方法核心:提出短语字典偏差(PHRASED),利用用户提供的源语言-目标语言实体短语对
{I: O}来增强翻译。核心是先从中间表示(如ASR文本)中匹配源语言短语I,再对匹配到的目标语言短语O进行概率加分。 - 新在何处:首次为端到端语音翻译设计并验证了“短语字典偏差”机制,与传统的仅使用目标短语列表(PLB)的偏差方法不同,它显式利用了源语言信息。同时,将该方法成功适配到流式Transducer模型和多模态大模型两种架构。
- 主要实验结果:在中文到英文的RealSI测试集上,PHRASED使流式CTC-GMM模型的短语召回率相对PLB提升了21%;使Phi-4多模态大模型的BLEU提升2.9点,短语召回率相对基线提升85%,远超PLB在大模型上失败的表现。关键数据见下表。
表1:流式语音翻译模型结果(RealSI 中-英)
| 方法 | BLEU | 召回率 |
|---|---|---|
| CT基线 | 16.5 | 21.62% |
| CT + PLB | 19.2 | 32.43% |
| CTC-GMM基线 | 18.3 | 28.83% |
| CTC-GMM + PLB | 19.9 | 43.24% |
| CTC-GMM + PHRASED_PS | 20.0 | 52.25% |
| CTC-GMM + PLB (大bonus) | 4.6 | 49.55% |
表2:多模态大模型结果(RealSI 中-英)
| 方法 | BLEU | 召回率 |
|---|---|---|
| Phi-4-multimodal 基线 | 21.1 | 36.04% |
| Phi-4-multimodal + PLB | 1.1 | 8.11% |
| Phi-4-multimodal + PHRASED_PS | 23.8 | 54.95% |
| Phi-4-multimodal + PHRASED_JB | 24.0 | 66.67% |
- 实际意义:为解决语音翻译中的“冷启动”实体短语问题提供了有效且灵活的工程化方案,尤其在多模态大模型框架下展示了利用外部知识库的可行性。
- 主要局限性:方法高度依赖预先构建的源-目标短语对字典;在流式模型中的效果依赖于中间ASR表示(z)的质量;实验场景单一(中-英),缺乏在其他语言对、极长上下文或真实噪声环境下的验证。
🏗️ 模型架构
本文提出PHRASED作为一种通用的偏差方法,应用于两种不同的ST模型架构:
- 基于CTC-GMM的流式端到端ST模型:
- 整体流程:输入语音
x→ CTC-GMM编码器(包含CTC压缩模块)→ 中间表示z(BBPE分词的ASR文本) → Transducer解码器 → 输出翻译y。 - 关键组件:CTC压缩模块是核心,它将语音编码器输出进行压缩,对齐到文本模态,其输出可自然地作为中间表示
z。该模块预训练于多语言ASR数据。 - PHRASED_PS集成:在解码阶段,利用中间表示
z与源语言短语列表I进行匹配,选择出匹配的短语Im及其对应的目标短语Om。然后,在计算每个解码步的输出概率时,对与Om当前未完成匹配的词片(word piece)对应的输出维度施加额外的奖励(bonus)。这改变了最终的解码得分(公式4)。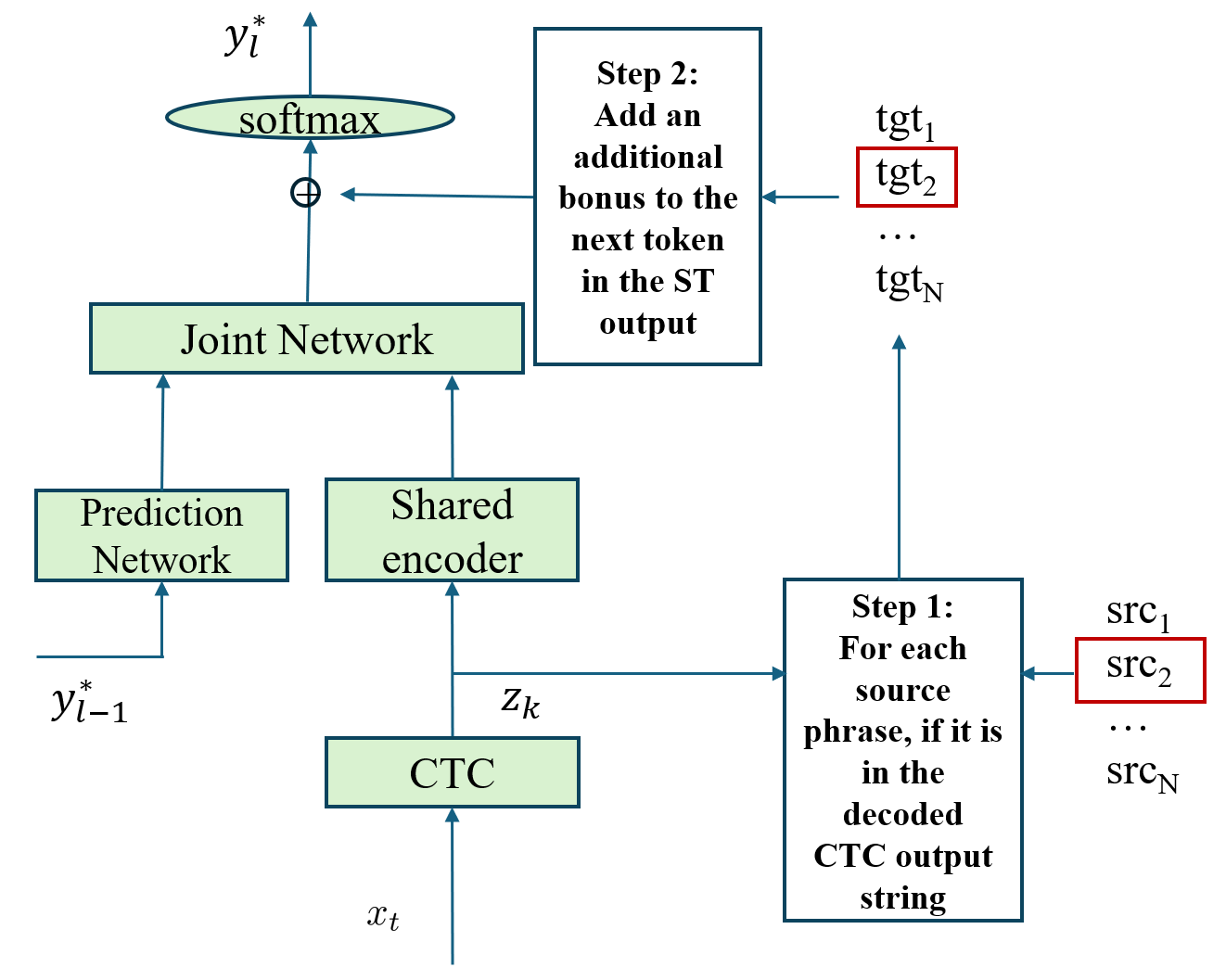 图1:PHRASED_PS应用于CTC-GMM的示意图。Step 1 在ASR中间表示z中匹配源语言短语;Step 2 对匹配到的目标语言短语在ST模型输出时加分。
图1:PHRASED_PS应用于CTC-GMM的示意图。Step 1 在ASR中间表示z中匹配源语言短语;Step 2 对匹配到的目标语言短语在ST模型输出时加分。
- 基于Phi-4-multimodal的多模态LLM:
- 整体流程:输入音频 → 模型ASR功能 → 文本转录
z→ 利用提示(prompt)引导模型进行翻译 → 输出y。 - 关键组件:利用现成的多模态LLM(Phi-4-multimodal,5.6B参数)的ASR和翻译能力。核心创新在于如何将短语字典信息注入到提示中。
- PHRASED集成:
- PHRASED_PS:提示为“The output should contain [Om].”,其中
Om是从z中匹配出的目标短语(公式6)。 - PHRASED_JB:提示为“The [Im] in the audio clip should be translated to [Om].”,同时提供了源短语
Im、目标短语Om以及它们在z中出现的上下文信息(公式7)。这显式地利用了字典映射关系。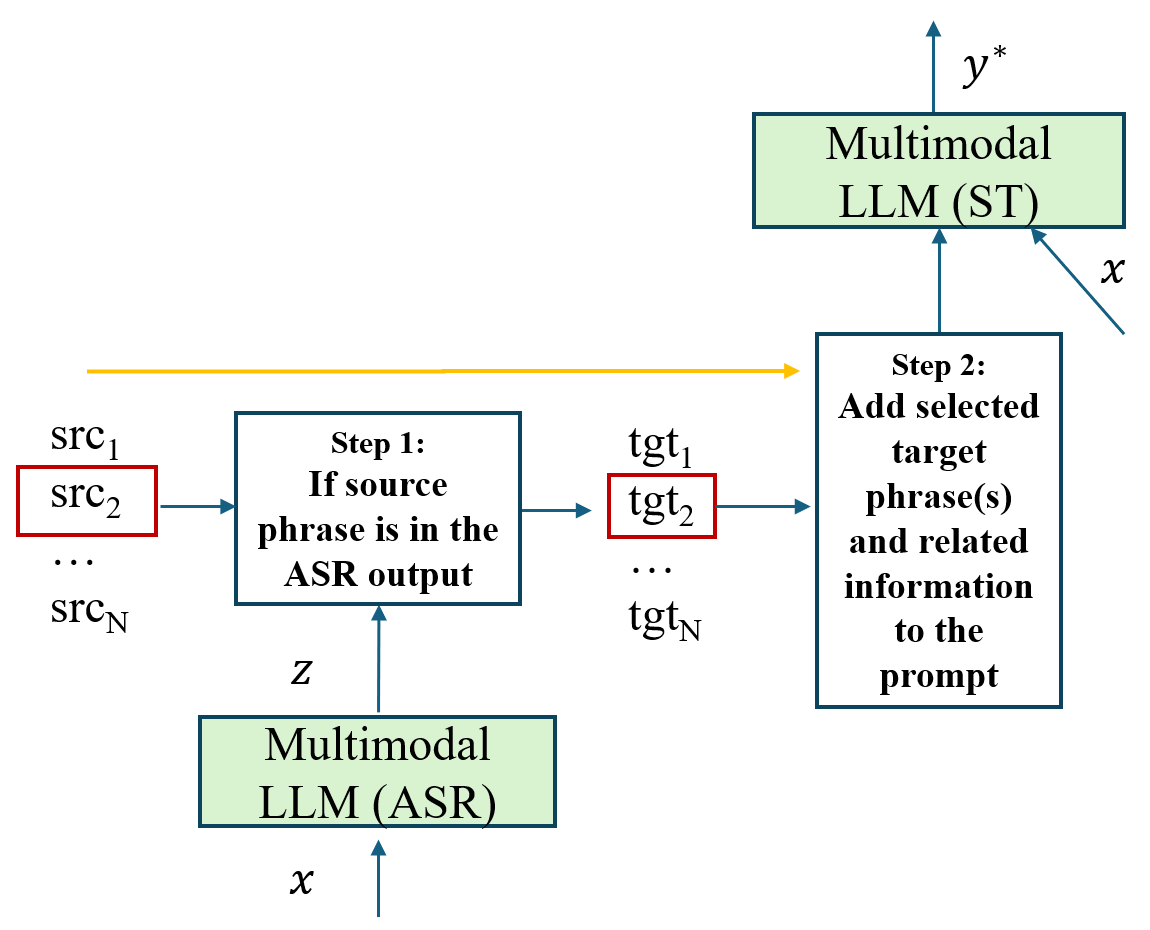 图2:PHRASED_JB应用于多模态LLM的示意图。Step 1匹配短语;Step 2将选中的目标短语及相关信息(源短语、上下文)添加到提示中。
图2:PHRASED_JB应用于多模态LLM的示意图。Step 1匹配短语;Step 2将选中的目标短语及相关信息(源短语、上下文)添加到提示中。
- PHRASED_PS:提示为“The output should contain [Om].”,其中
💡 核心创新点
- 提出“短语字典偏差”(PHRASED)范式:针对语音翻译任务,设计了一种利用源语言-目标语言实体短语对进行偏差的方法。相比仅使用目标短语列表(PLB),PHRASED能更精准地利用外部知识,因为源语言短语的出现为激活对应的目标翻译提供了可靠信号。
- 为流式端到端模型设计PHRASED_PS:巧妙利用CTC-GMM模型自带的中间ASR表示(z) 作为桥梁,实现了在无文本输入的情况下,对流式ST解码过程进行短语级偏差。这是将传统ASR偏差技术适配到端到端ST的关键一步。
- 为多模态大模型设计并验证PHRASED_JB:首次探索了如何让多模态LLM有效利用大规模外部短语字典。论文发现直接放入长列表(PLB)会导致LLM失效,而PHRASED_JB通过结构化的提示(明确给出源→目标映射及上下文),成功激活了LLM的短语翻译能力,实现了高达85%的召回率提升。
- 统一方法与显著增益验证:在同一个工作框架下,将PHRASED应用于流式小模型(400M)和大模型(5.6B),并都取得了相对于PLB或基线的显著提升,证明了该方法的通用性和有效性。
🔬 细节详述
- 训练数据:
- CT模型:351K小时弱监督内部数据,通过将多语言ASR转录翻译为英文生成。
- CTC-GMM模型:除上述ST数据外,额外使用了日、意、韩、法、西、葡、中、德到英的纯文本机器翻译数据,以暴露更多实体短语。
- 多模态LLM(Phi-4-multimodal):论文未说明其训练数据,指出其为开源模型。
- 损失函数:
- CTC-GMM:结合Transducer损失和CTC损失,权重分别为1.0和0.1。
- 其他模型未说明。
- 训练策略:
- CT:峰值学习率0.0003,warm-up步数1M,总步数28M,优化器AdamW (betas [0.9, 0.98])。
- CTC-GMM:峰值学习率0.0004,warm-up步数1M,总步数54M。优化器未说明。
- 多模态LLM:未说明微调细节,本文主要研究其作为基座模型时的提示偏差方法。
- 关键超参数:
- 模型大小:CT/CTC-GMM为400M参数;Phi-4-multimodal为5.6B参数。
- 系统延迟:CT和CTC-GMM均为1秒,可访问18秒历史信息。
- 输出维度:CT为4332;CTC-GMM的CTC模块输出维度为30002。
- 偏差超参数:λ(全局短语列表权重)和µ(选中短语权重)为可调超参数。在多模态LLM实验中,λ被设为0。
- 训练硬件:未说明。
- 推理细节:
- 流式ST模型采用流式解码。
- PHRASED偏差在解码的每一步动态计算并叠加到输出分数上,涉及到对部分匹配短语的追踪和回滚(当匹配失败时)。
- 评估时使用3K规模的短语列表(包含真实短语和从OntoNote5采样的无关短语)。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
- 主要基准与结果:在RealSI数据集的中文到英文子集上进行评估,使用BLEU和短语召回率作为指标。
- 关键对比与数字:
- 流式模型:PHRASED_PS在CTC-GMM上,将短语召回率从PLB的43.24%提升至52.25%(相对提升21%)。消融实验表明,单纯增大PLB的bonus(至4.0)虽然召回率(49.55%)接近,但BLEU分暴跌(从19.9降至4.6),证明了短语选择机制的重要性,避免了盲目加分。
- 多模态LLM:PLB方法在Phi-4上完全失效(BLEU降至1.1)。PHRASED_PS将BLEU提升至23.8,召回率至54.95%;而PHRASED_JB进一步将召回率提升至66.67%(相比基线36.04%提升85%),证明了显式字典映射信息的价值。
- 定性分析:表2的样例显示,PHRASED能正确翻译“宣传和发行”和“YouTube”,而基线方法完全丢失或错误翻译这些实体,导致句意改变。
- 图表:图1和图2(已在架构部分描述)分别说明了两种模型下的偏差流程。
⚖️ 评分理由
- 学术质量:6.0/7:方法创新性明确(PHRASED范式),技术方案合理(利用中间表示和结构化提示),实验对比充分(有基线、PLB、消融、不同模型架构),证据可信(结果数字清晰)。扣分点在于实验场景单一(仅中英),且未讨论短语列表规模或领域变化对性能的敏感性分析。
- 选题价值:1.5/2:选题精准地瞄准了语音翻译中一个具体但重要的痛点(实体短语翻译)。方法在流式系统和多模态大模型两大前沿方向上都具有应用潜力,对提高翻译产品的关键概念准确性有直接价值。
- 开源与复现加成:0.0/1:论文未提及任何代码、模型权重、数据集或详细的复现环境,严重影响了其可复现性和社区贡献度。