📄 Phoneme-Level Visual Speech Recognition via Point-Visual Fusion and Language Model Reconstruction
#视觉语音识别 #音素建模 #关键点检测 #大语言模型 #数据增强
✅ 7.5/10 | 前25% | #视觉语音识别 | #音素建模 #关键点检测 #大语言模型 | #音素建模 #关键点检测
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Matthew Kit Khinn Teng(九州工业大学)
- 通讯作者:未说明
- 作者列表:Matthew Kit Khinn Teng(九州工业大学)、Haibo Zhang(九州工业大学)、Takeshi Saitoh(九州工业大学)
💡 毒舌点评
这篇论文巧妙地将人脸关键点的几何信息与视觉外观特征相融合,为解决唇读中的视素歧义问题提供了一条清晰的音素建模路径,其使用紧凑的NLLB模型替代巨型LLM进行句子重建的思路也颇具工程吸引力。然而,论文的“故事”讲得不够完整——关键点特征在复杂场景下的脆弱性(如侧脸、遮挡)被明确提出,却缺乏系统性的解决或更鲁棒的融合机制;同时,核心的两阶段框架高度依赖于上游音素预测的准确性,而实验中对第一阶段(PV-ASR)音素预测性能的分析篇幅和深度,相较于对第二阶段LLM的调优,显得有些头重脚轻。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开预训练或微调后的模型权重。
- 数据集:实验使用的是公开数据集LRS2、LRS3、LRW,但论文未说明其获取方式或是否提供处理后的版本。
- Demo:未提供在线演示。
- 复现材料:论文描述了主要架构和训练策略,但未提供完整的配置文件、检查点或附录中的详细实现说明。
- 论文中引用的开源项目:MediaPipe(用于关键点提取)、NVIDIA NeMo toolkit(用于文本规范化)、SoundChoice toolkit(用于音素转换)。这些是工具依赖,而非论文本身的开源贡献。
- 论文中未提及开源计划。
📌 核心摘要
- 解决的问题:视觉语音识别(唇读)面临视素歧义(多个音素对应相似唇部视觉外观)和说话者差异性带来的挑战,导致直接进行词或字符级预测困难且容易出错。
- 方法核心:提出一种两阶段、基于音素的框架(PV-ASR)。第一阶段,将视频帧和密集唇部关键点运动特征分别通过视觉编码器(3D CNN + ResNet-18 + Conformer)和关键点编码器(ST-GCN + Conformer)提取并融合,使用混合CTC/Attention损失预测音素序列。第二阶段,使用预训练的NLLB(No Language Left Behind)编码器-解码器模型,将预测的音素序列重构为自然语言句子。
- 与已有方法相比的新意:1) 创新地融合了密集的唇部/下巴区域关键点运动特征(117个点)与视觉外观特征,以建模发音几何信息;2) 使用紧凑的、非自回归的NLLB模型(而非大型自回归LLM如LLaMA)进行音素到文本的重建;3) 在训练第二阶段LLM时引入音素级数据增强(随机插入、删除、替换),以提高对第一阶段预测噪声的鲁棒性。
- 主要实验结果:在LRS2测试集上达到16.0% WER,在LRS3测试集上达到20.3% WER。消融实验表明,PV-ASR(视频+关键点)优于单独的V-ASR和P-ASR;在训练中引入10%-20%的音素错误率能显著降低第二阶段LLM重建的WER,其中NLLB-1.3B模型表现最佳。具体结果见下表。
表1:在LRS2和LRS3数据集上与最新方法的WER(%)对比
| 方法 | 输入模态 | LLM | 额外数据 | LRS2 WER [%] | LRS3 WER [%] | 总训练小时数 (LRS2/LRS3) |
|---|---|---|---|---|---|---|
| Auto-AVSR [2] | 视频 | - | 是 | 14.6 | 19.1 | 3448 |
| VALLR [8] | 视频 | LLaMA | 否 | 20.8 | 18.7 | 28 / 30 |
| ViT-3D [18] | 视频 | - | 是 | - | 17.0 | 90000 |
| Ours (P-ASR) | 117个关键点 | NLLB(1.3B) | 否 | 72.2 | 66.4 | 223 / 438 |
| Ours (V-ASR) | 视频 | NLLB(1.3B) | 否 | 17.1 | 17.3 | 223 / 438 |
| Ours (PV-ASR) | 视频+117个关键点 | NLLB(1.3B) | 否 | 16.0 | 20.3 | 223 / 438 |
表2:不同LLM及噪声水平下的WER(%)对比(部分关键数据)
| 模型输入 | LLM | 训练噪声错误率 | LRS2 WER (Beam) [%] | LRS3 WER (Beam) [%] |
|---|---|---|---|---|
| PV-ASR | NLLB (1.3B) | 0.0% | 24.93 | 32.90 |
| PV-ASR | NLLB (1.3B) | 10.0% | 16.48 | 21.82 |
| PV-ASR | NLLB (1.3B) | 20.0% | 16.03 | 20.26 |
| PV-ASR | NLLB (1.3B) | 30.0% | 17.70 | 21.32 |
- 实际意义:该工作为在有限计算资源下实现较高性能的视觉语音识别提供了一种可行方案。其两阶段解耦的设计和对音素级建模的坚持,为处理视素歧义和跨说话者泛化提供了新思路。
- 主要局限性:1) 对关键点检测质量高度依赖,在人脸大角度或遮挡时性能会下降;2) 第二阶段重建完全依赖第一阶段的音素预测,存在错误传播风险;3) 论文未提供代码和模型权重,可复现性存疑。
🏗️ 模型架构
论文提出的是一个两阶段框架。
整体流程:输入视频帧序列 -> 第一阶段(PV-ASR):视觉编码器+关键点编码器 -> 特征融合 -> CTC/Attention解码 -> 输出音素序列。-> 第二阶段:NLLB模型 -> 将音素序列解码为英文句子。
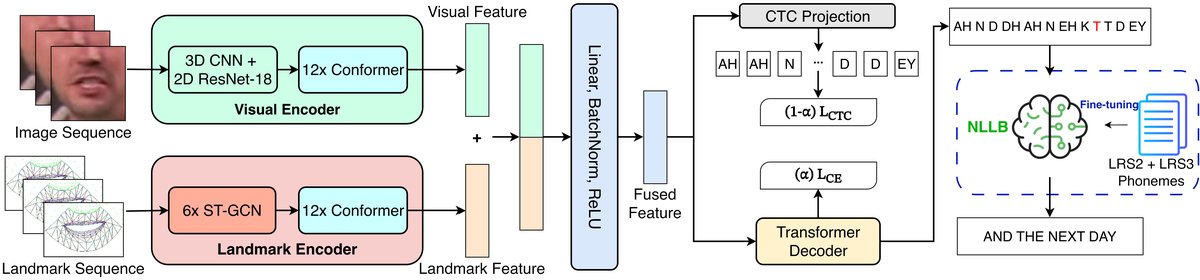 图1. 该论文提出的架构概览。视觉编码器提取视觉特征,关键点编码器提取唇部关键点特征。这两种表示被融合后,通过CTC投影和Transformer解码器进行序列建模。融合后的输出进一步由NLLB模型处理以重建音素。
图1. 该论文提出的架构概览。视觉编码器提取视觉特征,关键点编码器提取唇部关键点特征。这两种表示被融合后,通过CTC投影和Transformer解码器进行序列建模。融合后的输出进一步由NLLB模型处理以重建音素。
主要组件详解:
- 视觉编码器 (Visual Encoder):
- 前端:基于3D CNN和修改版ResNet-18。第一层是时空卷积层(步长1×2×2,核大小5×7×7),从输入视频帧中提取低级和中级时空特征。
- 后端:一个12层的Conformer。结合了多头自注意力和卷积模块,用于捕捉长程时间依赖(如音素间的协同发音)和局部时间模式(如短促的唇部运动),生成每个时间步的上下文感知嵌入。
- 关键点编码器 (Landmark Encoder):
- 前端:受[10]启发的时空图卷积网络(ST-GCN)。包含6个顺序模块,每个模块结合了时空图卷积。输入为2通道的关键点特征(来自MediaPipe提取的117个面部点,聚焦于内/外唇及周围区域),经过6层变换后输出64通道特征。最后一层通过线性层+BatchNorm+Mish激活生成关键点嵌入。
- 后端:同样是一个Conformer,作为时间后端,将唇部关键点的运动动态编码为上下文感知嵌入。
- 融合层 (Fusion Layer):一个多层感知机头,包含线性层+BatchNorm+ReLU+线性层。将视觉编码器和关键点编码器的嵌入投影到任务特定的特征空间,并引入非线性。
- CTC投影与Transformer解码器:融合后的嵌入通过线性层映射到音素logits,用于计算CTC损失。同时,该嵌入也输入到一个标准的Transformer解码器(包含自注意力、编码器-解码器注意力、前馈网络),用于基于Attention的解码。训练采用混合CTC/Attention损失:L = αLCE + (1-α)LCTC。
- NLLB Transformer编码器-解码器:第二阶段的核心。编码器将输入的音素序列映射到上下文感知嵌入;解码器通过关注这些嵌入和之前生成的token,逐步生成单词。最终通过线性层+softmax输出词汇概率分布,实现从音素到句子的重建。
关键设计选择:
- 双编码器融合:旨在同时利用唇部的外观纹理(视觉编码器)和动态几何形状(关键点编码器),后者被认为对说话者差异和光照变化更鲁棒。
- 音素级建模:为缓解视素歧义,提供比词更细粒度的语言单元。
- 解耦训练:第一阶段专注音素预测,第二阶段专注语言模型,使得第二阶段可以使用纯文本数据训练,并通过数据增强缓解错误传播。
💡 核心创新点
- 密集关键点与视觉特征融合的PV-ASR:将117个面部关键点的运动特征(通过ST-GCN建模)与视频外观特征(通过3D CNN+ResNet建模)进行融合。之前的唇读方法要么只用视频,要么使用稀疏关键点(如ASSTGCN的38点)。这种更密集的几何信息输入被证明能提升音素预测准确性。
- 使用紧凑NLLB模型进行音素-文本重建:与近期一些使用大型自回归LLM(如LLaMA, 数十亿参数)进行句子重建的工作(如VALLR)不同,本文选用预训练的多语言NLLB模型(有600M和1.3B版本)作为编码器-解码器LLM。这展示了在保持竞争力的同时,使用更轻量级、非自回归架构的可行性。
- 训练时引入音素噪声增强LLM鲁棒性:在第二阶段训练NLLB时,对音素输入施加随机插入、删除、替换操作,模拟第一阶段可能产生的预测错误。这迫使LLM学习利用上下文信息进行纠错,而非依赖完美的音素对齐,实验证明此策略能显著降低最终WER。
🔬 细节详述
- 训练数据:
- 数据集:LRS2 (224.5小时,预训练195小时,训练28小时), LRS3 (438.9小时,预训练408小时,训练30小时), LRW(词级数据集,用于初始化部分权重)。
- 预处理:裁剪96x96像素的嘴部区域。使用MediaPipe提取面部关键点,仅保留内/外唇及周围共117个点,包括下巴区域。如果人脸检测失败,关键点序列用零填充。文本先进行规范化(数字、日期等转为口语形式),然后使用SoundChoice工具包转换为ARPAbet音素序列(39个音素+2个特殊token)。
- 数据增强:仅在第二阶段训练中,对音素序列进行随机插入、删除、替换,噪声错误率分别为0%, 10%, 20%, 30%(仅对最终模型测试)。
- 损失函数:第一阶段采用混合CTC/Attention损失:L = α L_CrossEntropy + (1-α) L_CTC。论文未明确给出α值,只说明其在[0, 1]范围内。
- 训练策略:
- 第一阶段:在LRS2/LRS3上微调P-ASR, V-ASR, PV-ASR。视觉特征提取器(3D CNN + ResNet-18)的权重来自[2](在LRW, LRS2, LRS3的5000词上预训练),并保持冻结。CTC投影器和Transformer解码器也初始化自[2]。ST-GCN层使用在LRW上预训练的权重初始化,其余层随机初始化。训练50个epoch,使用AdamW优化器,余弦学习率调度器,5个epoch的warm-up。初始学习率1e-4。每个batch最大帧数1800帧。评估时对最后10个epoch的检查点取平均。
- 第二阶段:分两步进行渐进式微调:1) 在LRS2和LRS3的联合音素数据上微调预训练的LLM;2) 在特定数据集(LRS2或LRS3)上进一步微调。使用AdamW优化器,初始学习率5e-5。使用默认英文分词器,将音素视为一种特殊语言。
- 关键超参数:论文未详细列出所有超参数(如Conformer的层数、隐藏维度、注意力头数)。仅提及视觉编码器前端为3D CNN + ResNet-18,后端为12层Conformer;关键点编码器前端为6模块的ST-GCN。LLM规模有Flan-T5 Small (77M), BART Base (139M), NLLB-600M, NLLB-1.3B。
- 训练硬件:NVIDIA A6000 GPU (49GB)。
- 推理细节:第二阶段解码使用束搜索(Beam Search)。论文强调所有实验使用相同的解码配置以保证公平对比。
📊 实验结果
主要Benchmark结果:在LRS2和LRS3上的性能对比见“核心摘要”中的表1。论文方法(PV-ASR + NLLB-1.3B)在LRS2上达到16.0% WER,优于大多数对比方法,且仅使用LRS2/LRS3自身数据(223/438小时),而对比方法Auto-AVSR虽然WER更低(14.6%/19.1%),但使用了3448小时数据进行预训练。在LRS3上为20.3% WER,与使用更大LLM或海量数据的方法(VALLR: 18.7%, ViT-3D: 17.0%)相比,仍具竞争力。
关键消融实验:
- 输入模态消融(表1):在LRS2上,PV-ASR(16.0%) 优于 V-ASR(17.1%) 和 P-ASR(72.2%),证明视觉+关键点融合有效。在LRS3上,PV-ASR(20.3%) 与 V-ASR(17.3%) 相比WER有所上升,论文解释为LRS3中关键点检测质量可能不足。
- LLM选择与噪声增强消融(表2):论文详细比较了V-ASR和PV-ASR分别与四种LLM(Flan-T5 77M, BART 139M, NLLB 600M, NLLB 1.3B)组合,并在0%,10%,20%,30%训练噪声下的表现。核心结论:(a) 所有LLM在引入10%-20%训练噪声时WER均显著下降,30%时略有回升,证实了数据增强策略的有效性;(b) WER随LLM参数量增大而一致下降,NLLB-1.3B表现最佳;(c) PV-ASR在大多数配置下优于V-ASR。
不同场景结果:论文主要关注不同数据集(LRS2 vs LRS3)和不同训练条件(有无关键点、不同LLM、不同噪声水平)的对比,未提供如不同光照、不同说话人角度的细分结果。但指出LRS3包含更多复杂场景,且关键点检测在侧脸或遮挡时可能失败。
⚖️ 评分理由
- 学��质量:6.0/7:论文技术路线清晰,融合关键点和使用NLLB的创新点明确且有一定价值。实验设计合理,包含主实验对比和充分的消融研究(模态、LLM、噪声),数据可信。但核心创新是基于现有组件的组合与改进,而非底层架构或理论的突破;部分实验设置细节(如超参数)描述不够完整。
- 选题价值:1.5/2:视觉语音识别是人工智能与辅助技术的重要交叉领域,具有明确的应用前景(如为听障人士辅助、安静或嘈杂环境通信)。论文针对该领域的核心挑战(视素歧义)提出解决方案,选题具有现实意义和前沿性。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重或详细的复现脚本。虽然描述了架构和训练流程,但缺少关键超参数和完整的训练配置,使得其他研究者难以直接复现其全部结果,因此在可复现性上没有加成。