📄 PhoenixDSR: Phoneme-Guided and LLM-Enhanced Dysarthric Speech Recognition
#语音识别 #构音障碍语音 #音素混淆矩阵 #大语言模型 #少样本学习
✅ 7.0/10 | 前50% | #语音识别 | #音素混淆矩阵 | #构音障碍语音 #大语言模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未明确说明(论文作者列表首位为 Yuxuan Wu)
- 通讯作者:赵杰罗 (Zhaojie Luo)(东南大学生物科学与医学工程学院 / 数字医学工程国家重点实验室;深圳环宇研究院)
- 作者列表:
- Yuxuan Wu(东南大学,数字医学工程国家重点实验室 / 生物科学与医学工程学院)
- Yifan Xu(东南大学,数字医学工程国家重点实验室 / 生物科学与医学工程学院)
- Junkun Wang(东南大学,数字医学工程国家重点实验室 / 生物科学与医学工程学院)
- Xin Zhao(东南大学,数字医学工程国家重点实验室 / 生物科学与医学工程学院)
- Jiayong Jiang(东南大学,数字医学工程国家重点实验室 / 生物科学与医学工程学院)
- Zhaojie Luo(东南大学,数字医学工程国家重点实验室 / 生物科学与医学工程学院;深圳环宇研究院)
💡 毒舌点评
亮点在于提出了一个清晰、模块化且可解释的“音素中介”框架,将病理语音识别的难题分解为“健康音素识别器+混淆建模+LLM解码”三步,巧妙利用健康数据资源,并通过少量个性化数据即可快速适配,思路非常扎实。短板在于实验仅在单个中文数据集CDSD上进行,缺乏对其他语言、其他疾病类型(如帕金森、中风)或更复杂噪声环境下的验证,其普适性有待商榷;此外,论文声称超越Whisper-FT,但对比的Whisper-FT性能(34.4% CER)似乎异常差,暗示其微调策略或数据处理可能存在未言明的问题,削弱了对比的说服力。
🔗 开源详情
- 代码:提供了GitHub仓库链接:github.com/wyxuan721/PHOENIXDSR。
- 模型权重:未提及是否公开预训练的音素识别器权重或微调后的LLM适配器权重。
- 数据集:实验使用公开数据集AISHELL-1和CDSD。论文未提供新数据集。
- Demo:未提及在线演示。
- 复现材料:论文给出了主要的模型架构、训练阶段划分、关键超参数(如学习率、LoRA配置)和训练流程描述。但部分细节(如平滑参数β, κ, τ, α的具体值,阶段损失权重λ的具体值,完整的数据预处理脚本)未在正文给出,可能需参考代码库。
- 论文中引用的开源项目:
chinese-wav2vec2-large[21]Qwen3-4B-Instruct-2507(作为基座LLM)
- 总体开源情况:论文提供了核心代码入口,具备基本复现条件,但完整的开源生态(如模型权重、详细配置)未完全开放。
📌 核心摘要
- 解决的问题:构音障碍(Dysarthria)语音识别因病理数据稀缺、说话人之间差异巨大而面临严峻挑战,传统端到端模型性能显著下降。
- 方法核心:提出PhoenixDSR框架,采用“音素中介”策略解耦声学变异与语言解码。首先,用健康语音训练的Wav2Vec2-CTC模型提供稳定的音素序列;其次,从有限的病理数据中估计一个融合全局与个人特性的加权音素混淆概率矩阵;最后,使用一个轻量级、经过多任务训练的大语言模型解码器,结合音素混淆先验,将(可能存在错误的)音素序列转换为正确的文本。
- 创新之处:不同于端到端微调或直接使用LLM后编辑,本方法显式地将病理语音的系统性音素偏差建模为混淆先验,并利用LLM强大的上下文语言能力进行纠错。通过两阶段训练(先学习健康数据的音素-文本映射,再适应病理数据)和基于贝叶斯更新的少样本个性化机制,实现了高效的数据利用。
- 主要结果:在CDSD中文构音障碍数据集上,PhoenixDSR(个性化版本)达到18.3%的字符错误率(CER)和13.7%的音素错误率(PER)。相比端到端微调的Whisper(34.4% CER)和LLM后编辑(30.0% CER)有显著提升。消融实验证实了阶段一预训练和混淆先验的关键作用。仅用100句个性化数据即可实现显著增益。
| 系统 | CER (%) | PER (%) |
|---|---|---|
| CDSD 强基线 | 22.4 | 19.8 |
| Whisper-FT | 34.4 | 27.9 |
| LLM-Post (Qwen3-4B) | 30.0 | 27.1 |
| PhoenixDSR (全局混淆) | 20.2 | 16.7 |
| PhoenixDSR (个性化, K=100) | 18.3 | 13.7 |
| 变体 | CER (%) | PER (%) |
|---|---|---|
| PhoenixDSR (个性化, K=100) | 18.3 | 13.7 |
| 去除阶段I预训练 | 25.9 | 30.6 |
| 去除混淆先验 | 21.9 | 18.0 |
| K (句/说话人) | CER (%) | PER (%) |
|---|---|---|
| 0 | 20.2 | 16.7 |
| 50 | 18.9 | 14.6 |
| 100 | 18.3 | 13.7 |
| 200 | 18.3 | 13.6 |
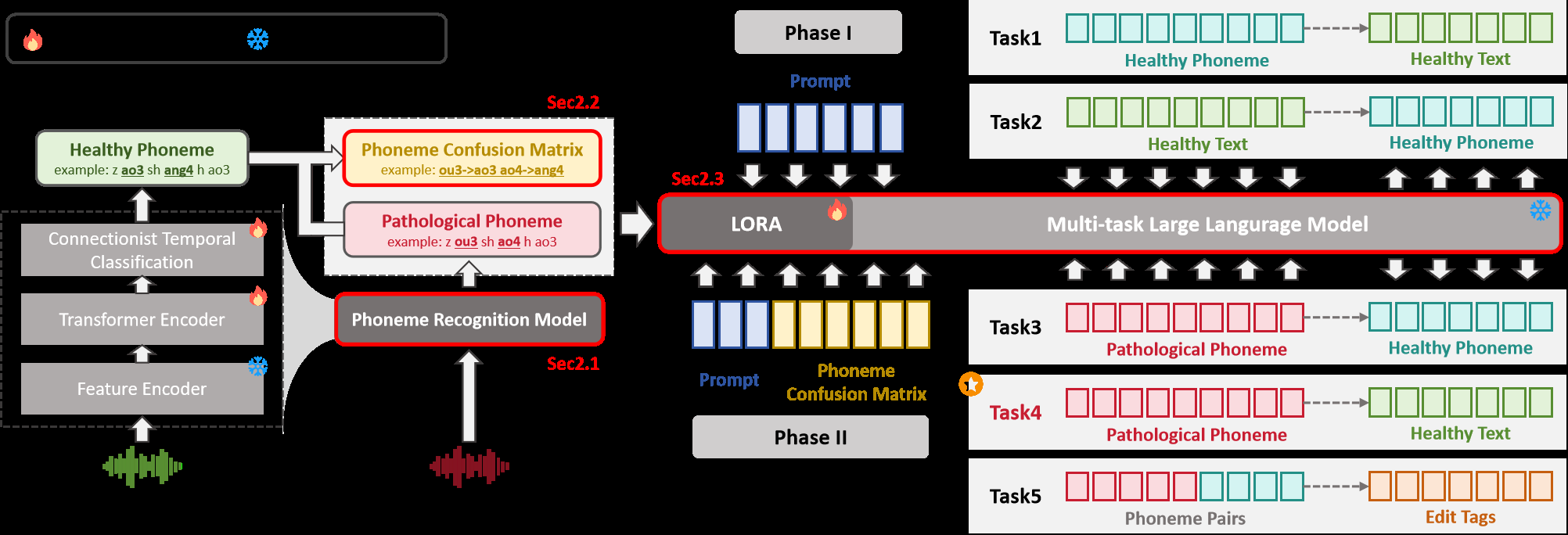 图1展示了PhoenixDSR的整体流程。左侧为音素识别模型(基于Wav2Vec2-CTC),将输入的病理语音(Dysarthric Speech)转换为音素序列。中间的“Phoneme Confusion Matrix”模块利用健康语音的基准和病理数据的对齐信息,估计并个性化一个音素混淆先验。右侧为多任务大语言模型解码器,其输入是病理音素序列(
图1展示了PhoenixDSR的整体流程。左侧为音素识别模型(基于Wav2Vec2-CTC),将输入的病理语音(Dysarthric Speech)转换为音素序列。中间的“Phoneme Confusion Matrix”模块利用健康语音的基准和病理数据的对齐信息,估计并个性化一个音素混淆先验。右侧为多任务大语言模型解码器,其输入是病理音素序列(p(d))和从混淆矩阵中检索出的候选音素及概率(P)。LLM通过多任务训练,最终输出纠正后的文本(t(h))和中间的规范化音素(p(h))。
 图2可视化了在CDSD数据集上最常见的音素混淆对,揭示了构音障碍语音中系统性的发音偏差模式,例如声调替换(如u5→u4)、齿龈音与卷舌音混淆(z→zh)、元音或韵尾的偏移等。这正是PhoenixDSR框架试图显式建模和纠正的核心问题。
图2可视化了在CDSD数据集上最常见的音素混淆对,揭示了构音障碍语音中系统性的发音偏差模式,例如声调替换(如u5→u4)、齿龈音与卷舌音混淆(z→zh)、元音或韵尾的偏移等。这正是PhoenixDSR框架试图显式建模和纠正的核心问题。
- 实际意义:为构音障碍患者提供了一种更高效、可解释的语音识别方案,只需少量个性化数据即可定制,有助于改善其沟通辅助工具的体验。
- 主要局限性:实验评估仅限于单一中文数据集(CDSD),缺乏跨语言、跨病理类型的泛化验证;框架复杂度较高,涉及音素识别、混淆矩阵估计和LLM解码多个环节,实时性可能存在挑战;论文中对比的Whisper-FT基线性能异常低,可能影响结论的强支撑。
🏗️ 模型架构
PhoenixDSR是一个模块化、两阶段的语音识别框架,其核心思想是将语音识别分解为声学-音素映射和音素-文本解码两个独立且可解释的阶段,并通过音素混淆先验来衔接病理语音与健康文本。
完整输入输出流程:
- 输入:构音障碍患者的语音波形。
- 中间表示:通过健康语音训练的音素识别器,输出一个可能包含错误的音素序列
p(d),以及该序列与真实健康音素序列p(gt)的对齐关系(用于训练阶段估计混淆矩阵)。 - 输出:正确、流利的健康文本
t(h)。
主要组件及功能:
- 音素识别模型(Phoneme Recognizer):
- 功能:将输入的语音信号映射为音素序列。其关键设计是仅使用健康语音数据(如AISHELL-1)进行训练,旨在学习一个稳定、通用的声学-音素映射能力。
- 结构与动机:采用
Wav2Vec2-CTC架构。Wav2Vec2提供强大的自监督语音表征,CTC损失使其能处理未对齐的序列数据。训练后模型被冻结,作为后续流程的固定“编码器”。这解耦了声学表征学习与病理适应问题。
- 音素混淆矩阵(Phoneme Confusion Matrix):
- 功能:量化并建模病理语音中音素的系统性偏差模式,为下游LLM解码提供先验知识。
- 结构与数据流:
- 全局混淆矩阵:在训练集上,将病理语音的识别结果
p(d)与真实音素p(gt)对齐,统计替换、删除等操作的频率,经过层级平滑得到全局混淆分布Cg(o|t)。 - 个性化混淆矩阵:以全局矩阵为贝叶斯先验,利用测试说话人的少量数据(如K=50-200句)进行贝叶斯更新,得到说话人特异的混淆分布
bCs(o|t)。通过一个门控机制(公式5)自动平衡全局与个性化信息,在样本少时依赖全局,样本多时偏向个人。
- 全局混淆矩阵:在训练集上,将病理语音的识别结果
- 在推理时的应用:对于每个输入的病理音素,从其个性化混淆矩阵中检索概率最高的K个候选健康音素及其概率,连同原始病理音素一起序列化,作为LLM的条件输入
U = [OBS = p(d); PRIOR = P]。
- 多任务大语言模型解码器(Multi-task LLM Decoder):
- 功能:接收带有混淆先验的音素序列,利用其强大的上下文语言建模能力,输出纠正后的文本。
- 结构与训练:使用预训练LLM(如
Qwen3-4B-Instruct),通过 LoRA 适配器进行参数高效微调,基座模型参数冻结。训练分为两个阶段:- 阶段I(健康语音监督):在健康数据(AISHELL-1)上训练两个序列到序列任务:文本→音素(T1)和音素→文本(T2)。此阶段让LLM学习标准的、双向的音素-文本映射关系和语言学规律。
- 阶段II(构音障碍适应):在病理数据(CDSD)上,以阶段I初始化的适配器为基础,训练三个任务:音素规范化(T3,病理音素→健康音素)、核心解码(T4,病理音素→文本)、编辑操作预测(T5,预测音素间的编辑类型)。输入均包含混淆先验
U,使LLM能根据候选概率和上下文进行推理和纠错。
- 关键设计选择:多任务学习(T3, T4, T5)提供了互补的监督信号;混淆先验作为条件输入,将外部知识直接注入LLM;两阶段训练确保LLM首先掌握“标准知识”,再学习“病理适应”。
- 音素识别模型(Phoneme Recognizer):
组件间交互:音素识别器产生“有问题”的音素序列;混淆矩阵模块分析这些问题的模式并生成先验;LLM解码器则结合音素序列、先验知识和自身语言能力,进行“翻译”和“纠错”,最终输出正确文本。整个系统将病理语音识别的复杂性,从一个端到端黑盒模型,分解为多个可分析、可干预的模块。
💡 核心创新点
- 音素中介框架解耦声学与语义:核心创新在于提出并系统化了一个“音素中介”框架。以往端到端方法或LLM后编辑都直接处理声学特征或文本,而PhoenixDSR通过引入一个由健康数据训练的音素识别器作为中间桥梁,将高度可变的病理声学信号转换为相对稳定、可解释的音素符号。这使后续的个性化适应和语言建模都建立在更规范化的表示之上,显著降低了建模复杂度。
- 融合全局与个人的音素混淆先验:创新性地将病理语音的音素偏差建模为一个概率混淆矩阵,并设计了基于贝叶斯更新和门控机制的自适应方法。这实现了两个关键目标:(a)用全局先验解决数据稀疏问题;(b)用少量个人数据快速捕捉说话人特异性错误模式(如将/c/总是发成/ch/),实现了高效、可解释的少样本个性化,且无需更新模型参数,仅更新先验。
- 面向高错误率的多任务LLM微调策略:针对构音障碍语音ASR错误率高的特点,设计了专门的两阶段、多任务LLM微调方案。阶段I的“音素文本双向映射”任务为LLM提供了坚实的音素学基础。阶段II的“音素规范化”、“核心解码”和“编辑操作预测”三个任务,共同为LLM提供了从“规范化”到“翻译”再到“具体错误定位”的多层次纠错能力,使其能有效处理系统性的、非局部的音素错误。
🔬 细节详述
- 训练数据:
- 健康语音:AISHELL-1(中文),用于训练音素识别器和LLM阶段I。具体规模未在本文明确,通常为数百小时。采用8:1:1划分。
- 病理语音:CDSD(中文构音障碍语音数据库),用于估计混淆矩阵和LLM阶段II训练。采用说话人独立划分(8:1:1),共44位说话人(训练36,开发4,测试4)。
- 音素集:采用声调感知的中文音素,将声母和韵母分开,并将韵母与其声调绑定(如
f,an1,an2等)形成独立的音素单元。 - 数据增强:未明确提及针对病理数据的特定数据增强方法。
- 损失函数:
- 音素识别器:CTC损失
L_CTC。 - LLM阶段I:文本→音素(T1)和音素→文本(T2)的交叉熵损失加权和
L(I) = λ1 L_T1 + λ2 L_T2。权重λ1, λ2未具体说明。 - LLM阶段II:生成任务(T3, T4)的负对数似然损失与序列标注任务(T5)的交叉熵损失加权和
L(II) = λ3 L_gen(T3) + λ4 L_gen(T4) + λ5 L_T5。核心任务T4的权重λ4应更大。
- 音素识别器:CTC损失
- 训练策略:
- 音素识别器:使用
chinese-wav2vec2-large初始化,优化器AdamW,学习率2e-4,训练200k步,预热10k步,使用SpecAugment。 - LLM解码器:使用
Qwen3-4B-Instruct-2507,应用LoRA(rank 16, α=32, dropout 0.05)于注意力层和MLP投影层。基座权重冻结。阶段I和阶段II严格顺序训练(不混合)。阶段II优化器AdamW,学习率1e-4。早停基于开发集CER。
- 音素识别器:使用
- 关键超参数:
- 个性化:少样本适应句数K ∈ {0, 50, 100, 200}。
- 混淆矩阵平滑:全局平滑参数β,个性化平滑参数κ,门控平滑参数τ和α。具体值未在正文给出。
- LLM输入构造:混淆先验中检索的top-k候选音素数量未具体说明。
- 训练硬件:论文中未说明。
- 推理细节:未明确说明解码策略(如beam search)、温度或流式设置。推测使用标准的自回归解码。
- 正则化:LoRA的dropout(0.05);混淆矩阵估计中的层级平滑和门控机制本身也起到防止过拟合的作用。
📊 实验结果
- 主要Benchmark与数据集:在 CDSD 数据集上进行评估,采用说话人独立的测试集(4位未见说话人)。
- 指标:字符错误率(CER)和音素错误率(PER)。
- 主要对比结果:
| 系统 | CER (%) | PER (%) |
|---|---|---|
| CDSD 强基线 | 22.4 | 19.8 |
| Whisper-FT | 34.4 | 27.9 |
| LLM-Post (Qwen3-4B) | 30.0 | 27.1 |
| PhoenixDSR (全局混淆) | 20.2 | 16.7 |
| PhoenixDSR (个性化, K=100) | 18.3 | 13.7 |
表2:主要实验结果。PhoenixDSR(个性化)在CER和PER上均优于所有基线。与CDSD文献强基线相比,CER相对降低约18.3%,PER降低约30.8%。与端到端微调的Whisper-FT相比,优势显著。
- 关键消融实验:
| 变体 | CER (%) | PER (%) |
|---|---|---|
| PhoenixDSR (个性化, K=100) | 18.3 | 13.7 |
| 去除阶段I预训练 | 25.9 | 30.6 |
| 去除混淆先验 | 21.9 | 18.0 |
表3:消融实验。去除任一组件都会导致性能下降,尤其是去除阶段I预训练后PER飙升,证明健康数据预训练对学习音素-文本映射至关重要。
- 少样本个性化分析:
| K (句/说话人) | CER (%) | PER (%) |
|---|---|---|
| 0 | 20.2 | 16.7 |
| 50 | 18.9 | 14.6 |
| 100 | 18.3 | 13.7 |
| 200 | 18.3 | 13.6 |
表4:个性化效率。仅更新混淆先验,无需梯度更新模型,CER和PER随个性化数据增加而单调下降,并在K=100时趋于饱和。
- 错误模式分析:图2展示了CDSD上最常见的音素混淆对,如声调替换(
u5→u4)、齿龈/卷舌音混淆(z→zh)、元音变化(v→u)等。PhoenixDSR通过混淆先验显式建模这些模式并指导LLM纠正,而LLM-Post后编辑则效果不佳。 - 与SOTA对比:论文声称在CDSD数据集上超越了给出的基线(包括端到端和后编辑方法)。但需注意,其对比的Whisper-FT(CER 34.4%)性能异常低下,可能暗示该微调策略或数据预处理不是当前最佳实践,这削弱了对比的强度。
⚖️ 评分理由
- 学术质量(6.5/7):论文提出的方法具有清晰的逻辑链条和创新性(音素中介、可解释混淆先验、多任务LLM适应),技术细节描述充分,实验设计合理,消融实验有效。主要扣分点在于:(1)实验局限于单一数据集CDSD,泛化性未知;(2)与Whisper-FT的对比显得其性能异常差,使得超越的结论参考价值打折扣;(3)未报告统计显著性检验,尽管作者在未来工作中提及。
- 选题价值(1.5/2):解决病理语音识别这一重要但小众的实际问题,体现了AI向善的应用潜力。对特定读者群体价值高,但对更广泛的语音AI社区的引领性有限。
- 开源与复现加成(0.5/1):提供了代码仓库链接是重要加分项。但模型权重未公开,且部分训练细节(如硬件、完整超参数)缺失,可能影响快速、精确复现。