📄 PG-SE: Predictive Acceleration and Correction for Generative Speech Enhancement
#语音增强 #扩散模型 #生成模型 #预测模型 #语音增强的加速推理
✅ 7.5/10 | 前25% | #语音增强 | #扩散模型 | #生成模型 #预测模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yikai Huang(清华大学深圳国际研究生院)
- 通讯作者:Zhiyong Wu(清华大学深圳国际研究生院),Shiyin Kang(商汤科技)
- 作者列表:Yikai Huang(清华大学深圳国际研究生院)、Jinjiang Liu(清华大学深圳国际研究生院)、Zijian Lin(清华大学深圳国际研究生院)、Xiang Li(清华大学深圳国际研究生院)、Renjie Yu(清华大学深圳国际研究生院)、Zhiyong Wu(清华大学深圳国际研究生院)、Shiyin Kang(商汤科技)
💡 毒舌点评
亮点在于“前后夹击”的架构设计非常巧妙:用前级预测模型为扩散过程提供高质量起点以大幅压缩采样步数,再用后级预测校正器修复加速带来的瑕疵,形成一个闭环。短板是其实验仅在一个广泛使用的合成数据集(VB-DMD)上完成,缺乏在真实复杂声学环境或不同语言上的验证,其通用性和实际部署效果仍需进一步证明。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及公开模型权重。
- 数据集:使用公开的VB-DMD数据集,但论文中未说明获取方式,需读者自行查找。
- Demo:论文中未提供在线演示。
- 复现材料:提供了部分训练细节(优化器、学习率、批大小、训练轮数)、SDE超参数和网络架构(NCSN++),但缺失硬件信息、音频预处理参数、校正器独立损失细节等关键信息。
- 引用的开源项目:论文中未提及具体引用的开源代码库,其基础模型(如NCSN++)来自已发表的论文。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 问题:基于扩散模型的语音增强方法虽然能生成细节丰富的语音,但面临两大挑战:一是噪声抑制能力通常弱于预测(判别式)模型;二是逆采样过程需要大量的神经函数评估(NFEs),导致计算成本高,难以满足低延迟部署需求。
- 方法核心:提出PG-SE框架,在扩散推理的前后阶段分别引入预测模型。前级预测模型(先验估计器)生成粗略估计,并将其扩散到一个浅时间步作为逆过程的起点,从而大幅减少所需采样步数。后级预测模型(校正器)则以原始含噪语音和扩散生成结果为条件,对输出进行细化,以抑制残余噪声和生成伪影。
- 创新点:相比于将预测目标与扩散目标紧密耦合(如CRP),本方法将预测组件解耦为独立的预处理和后处理模块,分别专注于加速和细化,提供了更灵活的优化空间。创新还包括基于KL散度分析来启发式地选择最优的浅层起始时间步。
- 主要实验结果:在VB-DMD数据集上,PG-SE仅需5个NFEs(对比全步骤方法需30+ NFEs),在PESQ、ESTOI、SI-SDR等多项指标上超越了全步骤的SGMSE+、同等NFEs的FlowSE和CRP等SOTA基线。例如,PESQ分数达到3.40,高于FlowSE(3.09)和CRP(3.06)。消融实验显示,去掉校正器后性能仍有竞争力,证明了前级加速的有效性。
- 实际意义:该框架为平衡生成式语音增强的性能和效率提供了一个有效范式,通过将推理NFEs减少80%以上,使其更适用于实时或低延迟的应用场景。
- 主要局限性:实验仅在单一基准数据集上进行,未在真实世界噪声或复杂场景中验证其鲁棒性;论文未提供代码和模型,复现性依赖读者自行实现;此外,性能提升幅度在某些指标上相对有限(如SI-SDR提升0.2dB),且校正器引入了额外的推理计算(尽管NFEs总计仍很低)。
🏗️ 模型架构
PG-SE的整体架构是一个三阶段的流水线,如图1所示。以下是结合图示的详细描述:
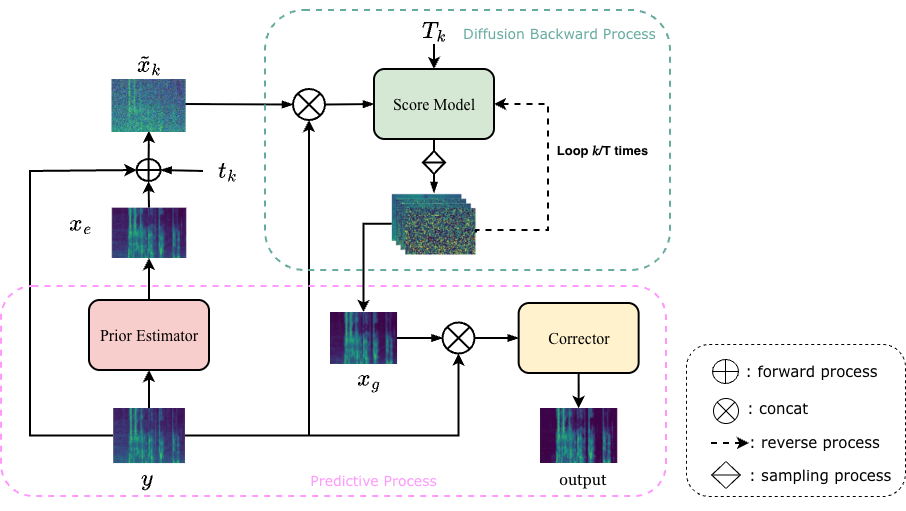
完整输入输出流程:
- 输入:含噪语音信号
y。 - 输出:增强后的干净语音信号
x(频谱或时域)。
主要组件及数据流:
预测性先验估计器(Predictive Prior Estimator):
- 功能:接收含噪语音
y,生成一个对干净语音的粗略估计xe。它本质上是一个训练好的预测性(判别式)语音增强模型。 - 结构:与分数模型共享相同的NCSN++(多分辨率U-Net)架构。论文中未详细说明其独立的损失函数,但根据其功能可推断它通过监督学习(如MSE、SI-SNR)进行训练。
- 交互:其输出
xe被用于生成逆向扩散过程的初始状态x̃k。
- 功能:接收含噪语音
分数模型(Score Model)与加速的逆向扩散过程:
- 功能:执行核心的生成式去噪。在传统方法中,它从纯噪声(或基于
y的噪声分布)开始迭代数百步。在PG-SE中,它从x̃k开始,在截断的时间区间[tk, tε]内进行仅k步(实验中k=3)的逆向SDE求解。 - 结构:同样是NCSN++架构,用于近似条件分数函数
∇x log p(x|y)。 - 交互:从先验估计器获得初始点
x̃k,输出中间结果xg。tk的选择基于KL散度准则(公式9),确保从预测估计出发的轨迹与从真实干净语音出发的轨迹在tk时刻分布足够接近。
- 功能:执行核心的生成式去噪。在传统方法中,它从纯噪声(或基于
预测性校正器(Predictive Corrector):
- 功能:接收原始含噪语音
y和扩散模型输出xg作为条件输入,生成最终的精细输出x̂θ。其目的是修正由离散化误差、分数模型不准确以及先验失配引入的残余误差。 - 结构:也是一个条件NCSN++模型。其训练采用混合损失函数(公式10),结合了时域SI-SNR损失、频谱MSE损失和可微分的PESQ感知损失。
- 训练技巧:为鼓励模型充分利用
y的信息,在训练时会随机遮挡参考信号xg的一段连续区域。 - 交互:作为最后阶段,负责“打磨”生成结果,提升感知质量和可懂度。
- 功能:接收原始含噪语音
关键设计选择:
- 解耦设计:将加速和细化功能分配给两个独立的预测模块,与将预测目标融入扩散训练(如CRP)相比,允许更灵活、针对性的训练和优化。
- 浅层初始化:通过数学分析(公式7-9)为预测先验提供了理论动机,即估计误差的影响随时间指数衰减,因此可以在足够早的时间点安全地启动逆过程。
💡 核心创新点
- 双阶段预测-生成协同框架:是什么:首次系统性地将预测模型作为“夹层”插入到扩散推理的前后两个阶段。之前局限:之前的工作要么仅使用预测模型引导扩散过程(但未解决计算负担),要么将预测目标与扩散模型耦合训练(如CRP),限制了优化灵活性。如何起作用:前级预测模型提供高质量起点以实现近无损加速;后级预测模型专门用于修复加速可能引入的误差和生成伪影。收益:在显著降低计算成本(NFEs >80%)的同时,性能超越了全步骤基线和现有混合方法。
- 基于KL散度分析的起始步选择策略:是什么:通过分析从预测估计和真实干净语音出发的前向过程分布的KL散度,提出了一种数据驱动的、可解释的浅层起始时间步
tk选择方法。之前局限:加速扩散模型的常见做法是随机或凭经验选择起始步,缺乏理论依据。如何起作用:比较预测轨迹与真实轨迹的差异(公式7)与传统初始化方法的差异(公式8),选择前者差异小于后者的最早时刻。收益:确保加速过程几乎不损失性能,实验(图2)验证了该策略的有效性。 - 设计解耦的独立校正器:是什么:将后处理校正器设计为一个独立的、以条件输入为基础的预测模型。之前局限:将预测目标与扩散目标在同一框架内训练(如CRP)可能无法完全发挥预测模型在显式监督最终输出方面的优势。如何起作用:校正器接受扩散输出作为输入,但不依赖于扩散过程的内部状态,从而可以独立使用如SI-SNR和PESQ等强监督损失进行优化。收益:更直接地利用预测模型的强噪声抑制能力,并通过消融实验(表1)证明其对提升性能(尤其是PESQ)和抑制伪影至关重要。
🔬 细节详述
- 训练数据:
- 数据集:VB-DMD数据集。
- 来源:VCTK语料库的干净语音 + DEMAND数据库的8种真实噪声 + 2种人工噪声(babble, speech-shaped)。
- 预处理与增强:训练集SNR为0,5,10,15 dB;测试集为不匹配的2.5,7.5,12.5,17.5 dB。训练集被进一步划分为训练和验证子集(验证集说话人:p226, p287)。论文中未提及具体的音频预处理(如采样率、帧长、FFT点数)。
- 损失函数:
- 校正器损失(公式10):
L_hybrid = L_sisnr(x̂θ, x0) + α||x̂θ - x0||² - α_p * PESQ(x̂θ, x0)。L_sisnr(公式11):尺度不变的信噪比损失,优化时域保真度和噪声抑制。- MSE项:频谱一致性约束,稳定训练。
- PESQ项:使用可微分的PESQ损失,直接优化感知质量和可懂度。
- 超参数:
α=1,α_p=5e-4。 - 分数模型损失(公式6):标准的去噪匹配损失
L_DSM,用于训练分数网络。
- 校正器损失(公式10):
- 训练策略:
- 优化器:Adam。
- 学习率:
1e-4。 - Batch Size:8。
- 训练轮数:最多150个epoch。
- 模型选择:在验证集上选择最高PESQ分数的checkpoint。
- 训练顺序:先训练先验估计器,再训练分数模型,最后训练校正器(论文中明确“trained sequentially”)。
- 关键超参数:
- 网络架构:NCSN++,多分辨率U-Net,估计复数频谱的实部和虚部。
- SDE超参数:
γ=1.5,σ_min=0.05,σ_max=0.5。最小和最大过程时间:tε=0.03,T=1。 - 推理步数:扩散阶段k=3步(在
[tk, tε]区间内)。总NFEs:先验估计器(1) + 分数模型(3) + 校正器(1) = 5。
- 训练硬件:论文中未提及。
- 推理细节:
- 解码策略:预测-校正采样(Predictor-Corrector),但PG-SE的扩散部分本身就在进行截断的逆向SDE求解。
- 流式设置:论文中未提及。根据其基于帧的处理方式和低延迟设计目标,推测可能支持流式,但未明确说明。
- 正则化或稳定训练技巧:在校正器训练中对参考信号
xg进行随机遮挡,以防止模型过度依赖可能不完美的扩散输出,并增强对原始含噪语音y中互补信息的利用。
📊 实验结果
主要Benchmark与数据集:VB-DMD数据集。
核心对比表格(Table 1):
| 方法 | 类型 | NFEs | PESQ | ESTOI | SI-SDR | SI-SIR | SI-SAR | OVRL (DNSMOS) | SIG (DNSMOS) | BAK (DNSMOS) |
|---|---|---|---|---|---|---|---|---|---|---|
| 预测型 | ||||||||||
| Conv-TasNet+ | P | 1 | 2.63 | 0.85 | 19.1 | - | - | - | - | 3.37 |
| MetricGAN+ | P | 1 | 3.13 | 0.83 | 8.5 | - | - | - | - | 3.37 |
| NCSN++ | P | 1 | 2.87 | 0.87 | 19.4 | 32.6 | 19.9 | 3.14 | 3.42 | 4.02 |
| 生成型 | ||||||||||
| SGMSE+ | G | 30 | 2.90 | 0.86 | 17.8 | 29.3 | 18.2 | 3.18 | 3.49 | 4.01 |
| PESQ-SB | G | 64 | 3.50 | 0.87 | 14.1 | - | - | - | - | 3.55 |
| BBED | G | 60 | 3.09 | 0.87 | 18.7 | 30.1 | 19.4 | 3.20 | 3.48 | 4.04 |
| FlowSE | G | 5 | 3.09 | 0.87 | 19.1 | 32.2 | 19.5 | 3.21 | 3.49 | 4.05 |
| 集成型 | ||||||||||
| CRP | I | 5 | 3.06 | 0.87 | 19.3 | 30.8 | 20.1 | 3.18 | 3.47 | 4.03 |
| PG-SE (本文) | I | 5 | 3.40 | 0.88 | 19.7 | 33.9 | 20.2 | 3.22 | 3.48 | 4.09 |
| - w/o corrector | I | 4 | 2.95 | 0.86 | 19.5 | 31.7 | 20.0 | 3.20 | 3.48 | 4.04 |
| NCSN++ w/ corrector | P | 1 | 3.44 | 0.87 | 19.2 | 33.8 | 19.8 | 3.21 | 3.46 | 4.09 |
| SGMSE+ w/ corrector | I | 31 | 3.36 | 0.87 | 19.5 | 33.9 | 20.2 | 3.21 | 3.48 | 4.08 |
与SOTA基线的差距:在相同的5个NFEs下,PG-SE的PESQ (3.40) 显著高于FlowSE (3.09) 和CRP (3.06),且在SI-SDR, SI-SIR, SI-SAR等失真指标上也全面领先。即使与需要30-64个NFEs的全步骤扩散基线(如SGMSE+, BBED)相比,PG-SE在性能上也具有竞争力或更优。
关键消融实验及数字变化:
- 去掉校正器(w/o corrector):NFEs降至4,PESQ从3.40大幅下降至2.95,但SI-SDR (19.5) 仍接近全步骤SGMSE+ (17.8)。这证明了先验引导的加速过程本身是有效的(近乎无损加速),而校正器对感知质量(PESQ)的提升至关重要。
- 纯预测级联(NCSN++ w/ corrector):相当于没有生成阶段。其PESQ (3.44) 略高于PG-SE,但SI-SDR (19.2) 和SI-SAR (19.8) 更低,ESTOI (0.87) 也略低。这表明纯预测模型可能产生过平滑的频谱,而扩散过程对于恢复细节和抑制伪影不可或缺,验证了混合框架的必要性。
- 将校正器应用于全步骤SGMSE+(SGMSE+ w/ corrector):性能(PESQ 3.36)也显著提升,证明了校正器作为独立模块的通用价值。
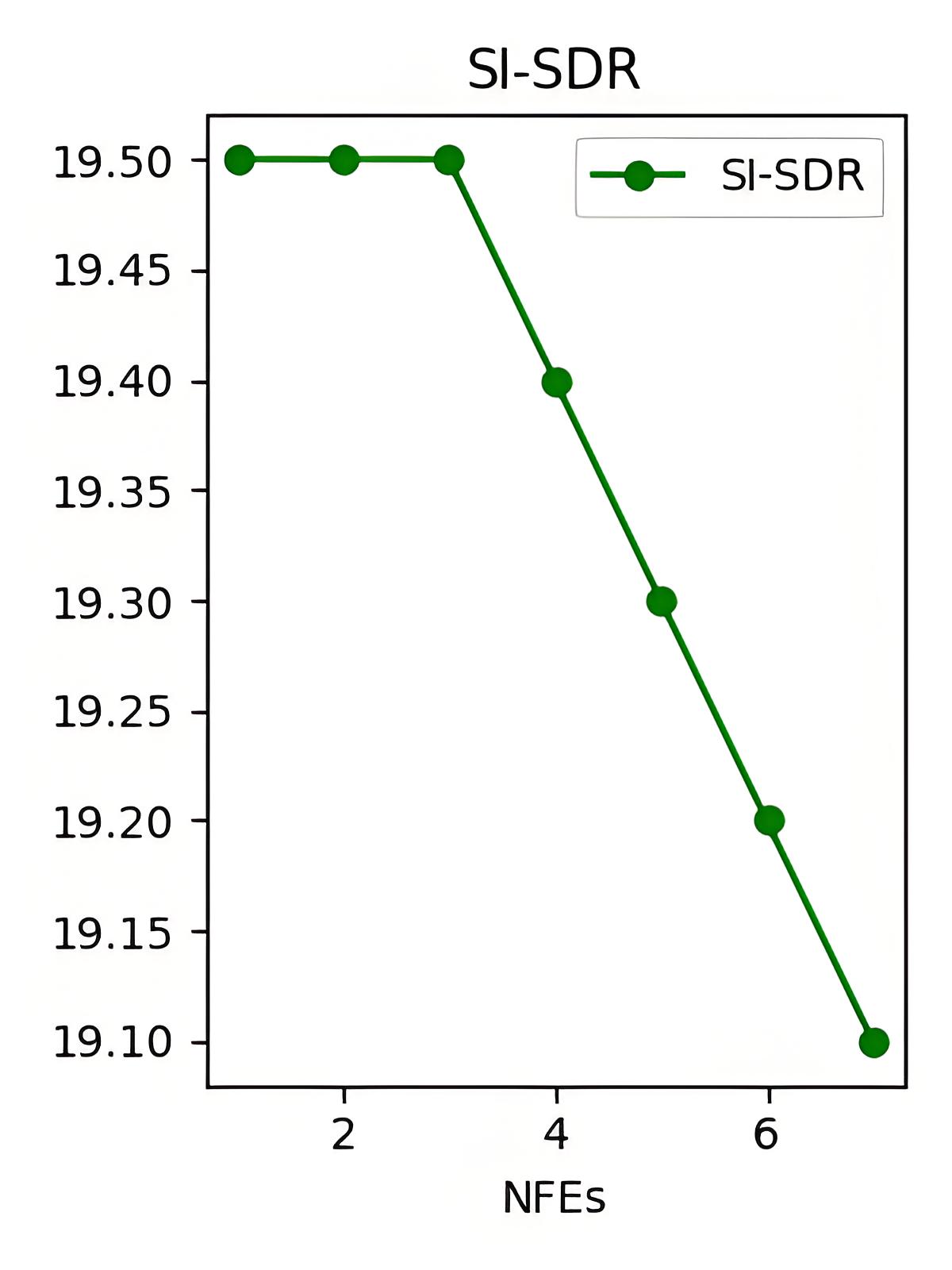
不同条件下的结果:图2展示了在不同起始时间步 tk 下,SGMSE+(无先验)的性能变化。结果表明,tk 设为3(即从时间步t=0.03向前扩散3步到tk)是性能与效率的最佳平衡点,验证了论文提出的起始步选择策略的有效性。
⚖️ 评分理由
- 学术质量:6.0/7:创新性明确,将预测模型系统性地用于解决扩散模型的两个核心缺陷,且设计(解耦、KL分析)合理。技术正确性高,基于成熟的扩散理论和预测模型。实验充分,设置了合理的对比组(预测、生成、混合方法)、多指标评估和详细的消融研究。证据可信度高,所有结论都有数据支持。主要扣分点在于创新属于对现有技术的有效整合与优化,而非开辟全新方向。
- 选题价值:1.5/2:语音增强是音频处理领域长期存在且实用的任务,其进展直接惠及助听、通信、语音识别等多个应用。论文针对生成模型部署中的实际痛点(速度与性能)进行改进,具有明确的应用价值和一定的前沿性。对从事语音增强或扩散模型加速的研究者和工程师有较高的参考意义。
- 开源与复现加成:0.0/1:论文全文未提供代码仓库链接、预训练模型权重、或详细的训练配置文件。也未提及开源计划。虽然描述了数据集和主要超参数,但完整的复现仍存在显著障碍。