📄 Personal Sound Zones with Flexible Bright Zone Control
#空间音频 #卷积神经网络 #信号处理 #麦克风阵列
✅ 7.5/10 | 前25% | #空间音频 | #卷积神经网络 | #信号处理 #麦克风阵列
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Wenye Zhu(浙江大学;西湖大学 & 西湖高等研究院)
- 通讯作者:Xiaofei Li(西湖大学 & 西湖高等研究院)
- 作者列表:Wenye Zhu(浙江大学,西湖大学 & 西湖高等研究院),Jun Tang(西湖大学 & 西湖高等研究院),Xiaofei Li(西湖大学 & 西湖高等研究院)
💡 毒舌点评
亮点:实验设计非常用心,创新性地引入“监控点网格”和“随机网格掩码”训练策略,有效解决了过拟合和泛化性问题,使网络真正学习到空间连续信息,而非仅仅拟合离散控制点。
短板:网络架构采用了非常成熟的3D ResNet,缺乏针对声学问题本身的结构性创新;此外,所有实验均基于模拟数据,未在真实房间和硬件系统中进行验证,结论的工程实用性仍需打上问号。
📌 核心摘要
- 问题:传统个人声区(PSZ)系统依赖于固定的麦克风控制网格来测量声学传递函数(ATF),当目标声场或控制点位置变化时,需要重新测量和计算,这限制了其实际应用的灵活性和便捷性。
- 方法核心:提出了一种基于3D卷积神经网络(CNN)的端到端模型,该模型以目标声区的ATF(在灵活或稀疏的麦克风网格上采样)为输入,直接输出用于扬声器阵列的预滤波器组。
- 创新性:与传统压力匹配(PM)等方法相比,该方法在一次训练后,能够同时处理可变的目标声场、灵活的麦克风网格模式以及更稀疏的控制点,显著提升了系统的适应性和轻量化潜力。
- 主要实验结果:在模拟混响环境中,所提方法在亮区相对均方根误差(REB)和声学对比度(AC)等关键指标上全面优于基线PM方法。例如,在3×3稀疏控制网格(Grid-3#1)下,Neural PSZ的REB为-21.79 dB,远优于PM的-9.67 dB;AC为14.12 dB,也高于PM的9.61 dB(见表1)。图表4和表2显示,其性能在网格变得稀疏时下降缓慢,而PM性能则急剧下降。
- 实际意义:该工作推动了PSZ技术向更灵活、轻量化的实际应用迈进,使得利用少量麦克风快速部署和切换不同虚拟声学场景成为可能,适用于AR/VR、家庭娱乐等场景。
- 主要局限性:研究完全基于仿真实验,未涉及真实硬件系统部署;网络架构为通用设计,未探索针对声学问题的特定优化;模型训练细节(如具体迭代次数)和计算开销分析不够详细。
🏗️ 模型架构
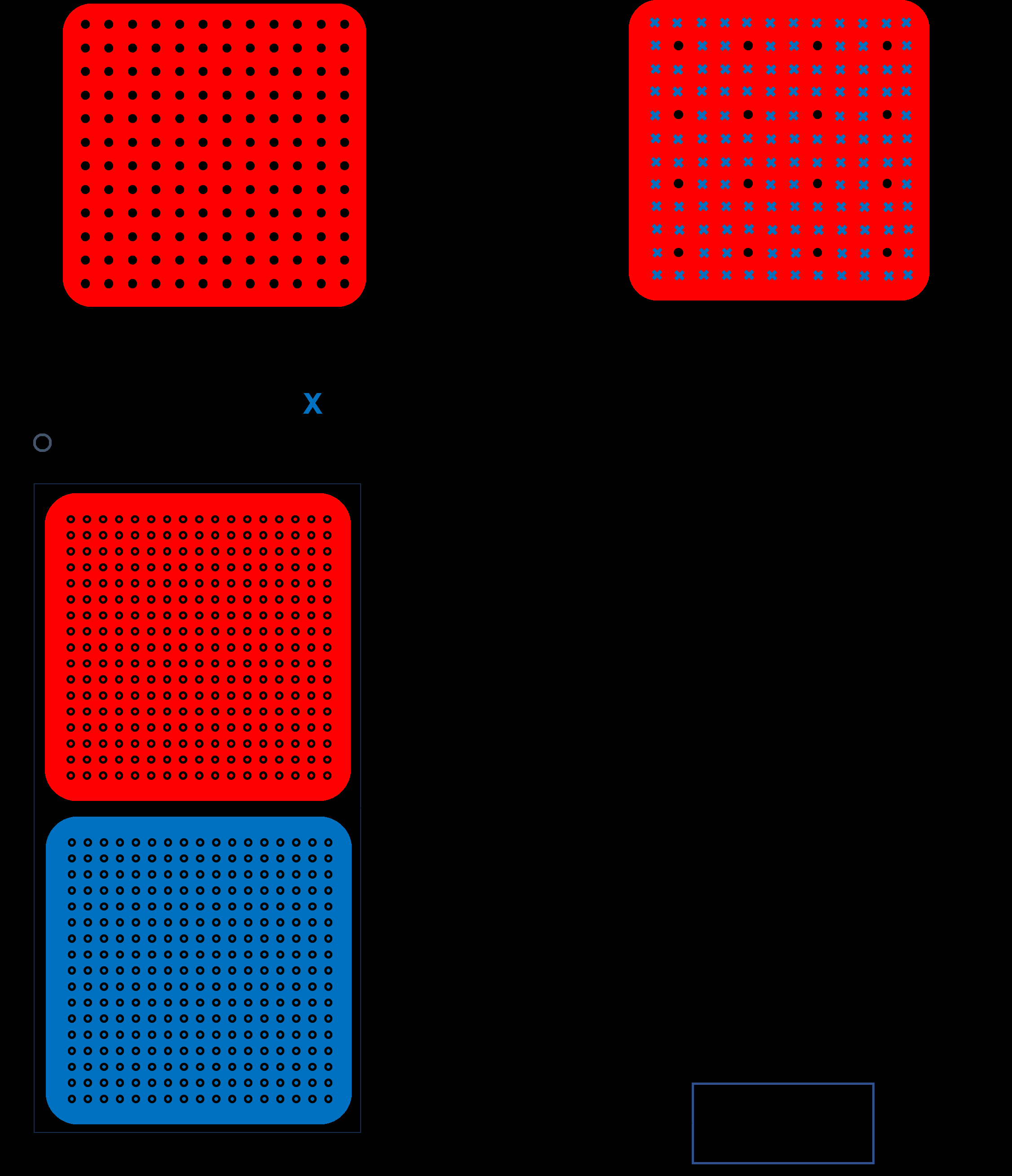

该模型是一个端到端的监督学习系统,核心任务是将目标声学传递函数(ATF)映射为扬声器阵列的预滤波器。其完整架构与数据流如下:
输入预处理:
- 输入数据:目标声区(BZ)在控制麦克风网格上的期望ATF
˜gB,这是一个复数值向量。 - 数据整形:为了保留空间分布信息,将一维向量
˜gB重塑为与麦克风网格(P^B_x × P^B_y)匹配的二维矩阵Ĝk(针对每个频率点k)。将所有K个频率点的矩阵堆叠,得到三维张量Ĝ ∈ C^{P^B_x × P^B_y × K}。 - 实值转换:将复数张量拆分为实部和虚部,扩展最后一维,最终得到网络输入
G ∈ R^{2 × P^B_x × P^B_y × K},如图2左侧所示。 - 随机掩码:为增强泛化性,在训练时会对输入
G应用随机网格掩码。即,将未被选中的控制点对应的ATF值置零(如图2中间所示),模拟稀疏或不同的控制点分布。
- 输入数据:目标声区(BZ)在控制麦克风网格上的期望ATF
神经网络主体(图3左):
- 核心架构:基于3D残差网络(ResNet)。选择3D卷积是因为输入数据是三维张量(空间×空间×频率),需要同时提取空间和频率维度的特征。
- 残差块:如图3右所示,每个残差块包含两个3D卷积层(使用PReLU激活函数),并通过快捷连接(Shortcut)相加。这种设计能缓解梯度消失问题,便于训练更深的网络以捕获复杂的空间-频率关系。
- 网络流程:输入张量
G经过多个残差块的堆叠处理,逐步提取高维特征。
输出层:
- 全连接层:在特征提取之后,连接两个全连接层。第一个全连接层作用于频率维度,将特征映射到扬声器通道维度;第二个全连接层调整通道维度,最终输出维度为
R^{2L × K}(L个扬声器,每个扬声器输出实部和虚部)。 - 分组线性层:论文提到使用了分组线性层,其作用是让每个频率点K拥有独立的全连接参数,这符合声学处理中通常对每个频率独立优化的惯例。
- 输出重塑:最终输出被重塑为预滤波器张量
a^{CNN} ∈ R^{2 × L × K},即图2右侧所示。
- 全连接层:在特征提取之后,连接两个全连接层。第一个全连接层作用于频率维度,将特征映射到扬声器通道维度;第二个全连接层调整通道维度,最终输出维度为
损失计算与训练:
- 监控点网格:为防止网络过拟合到离散的控制点,引入了与训练控制点不重叠的“监控点网格”。
- 损失函数:将网络输出的预滤波器
a^{CNN}与监控点处的扬声器到该点RIR矩阵H'相乘,得到重构的ATFg'。损失函数L定义为g'与监控点处的目标ATF˜g'之间的均方误差(MSE),如公式(1)所示。这强制网络学习整个区域内的声场,而非仅拟合控制点。
💡 核心创新点
支持灵活控制网格模式的PSZ系统:
- 局限:传统PM、ACC等方法要求目标ATF测量和本地RIR测量使用完全一致的固定网格,缺乏灵活性。
- 创新:通过引入随机网格掩码训练策略,使单一神经网络能够处理多种稀疏或不规则的麦克风网格输入,并生成有效的预滤波器。实验证明,即使输入仅来自一个或几个麦克风点,网络也能利用其学到的空间先验知识进行合理的声场重建。
从稀疏点学习全局空间信息的能力:
- 局限:传统方法依赖密集、均匀分布的控制点来离散化和控制声场,当控制点稀疏时性能急剧下降(如图4中PM曲线所示)。
- 创新:所提出的CNN架构在训练后,能够从非常稀疏的控制点(如3×3甚至2×2网格)中提取足够的空间线索,推断出整个声区的声场分布。图5的定性对比显示,在Grid-3#1模式下,PM方法无法重建BZ边缘的声场,而Neural PSZ方法重建结果与Ground Truth高度接近。
端到端、一次训练多目标的框架:
- 局限:传统方法每次更换虚拟声源位置或场景都需要重新测量和计算滤波器。
- 创新:模型以任意目标ATF作为输入,直接输出预滤波器。这意味着在一次训练后,系统可以通过输入不同的
˜gB张量,实时渲染不同的虚拟声学场景,极大提升了实用性。表2对比了“灵活网格训练”(一次训练,适应多种网格)与“固定网格训练”(为每个网格单独训练)的性能,证明了该框架在轻微性能代价下获得了巨大的灵活性收益。
🔬 细节详述
- 训练数据:使用
gpuRIR生成器(基于镜像源方法)在模拟混响环境(RT60=250ms)中生成数据集。房间尺寸8×8×3 m³。数据包括20,000对ATF,每对对应一个随机位置的虚拟声源(约束在半径[1.7, 3.5]m的环形区域内)。频率范围为[0, 2000] Hz,共512个频率点。数据分为控制网格(12x12=144点)和监控网格(17x17=289点)两套。 - 损失函数:监控点上的均方误差(MSE),具体公式为
L = (1/(M' × K)) * Σ_k ||H'(k)a^{CNN}(k) - ˜g'(k)||^2。该损失直接衡量重构声场与目标声场在监控点上的差异。 - 训练策略:使用Adam优化器,学习率为0.001。未提及具体训练轮数(Epochs)、批次大小(Batch Size)或学习率调度策略。
- 关键超参数:模型总参数量为21.59M。输入张量尺寸基于
P^B_x = P^B_y = 12,输出基于L=30个扬声器。训练时使用了10种不同的掩码网格模式。 - 训练硬件:在NVIDIA V100 Tensor Core GPU上进行训练和推理。未提及训练时长。
- 推理细节:推理时,将目标声区的ATF张量(可能经过掩码)输入训练好的网络,一次前向传播即可得到所有扬声器的预滤波器组。
- 正则化技巧:主要的正则化手段是使用监控点网格和随机掩码训练,防止网络过拟合到特定控制点或网格模式。
📊 实验结果
主要对比实验(与PM基线): 图4和表1展示了在不同控制网格下,所提Neural PSZ方法与传统PM方法在REB、RED和AC指标上的对比。
关键结论:
- 网格稀疏性影响:随着控制网格变稀疏(从Grid-12到Grid-1),PM方法的性能(REB增大,AC减小)显著恶化。而Neural PSZ方法的性能保持稳定,仅在极端稀疏的Grid-1(单点输入)时性能才明显下降。
- 具体数值对比(表1,3×3网格系列):
| 方法 | 网格模式 | REB↓ (dB) | RED↓ (dB) | AC↑ (dB) |
|---|---|---|---|---|
| PM | Grid-3#1 | -9.67 | -17.25 | 9.61 |
| Grid-3#2 | -9.87 | -17.23 | 9.13 | |
| Grid-3#3 | -8.70 | -16.39 | 7.73 | |
| Neural PSZ (Prop.) | Grid-3#1 | -21.79 | -33.36 | 14.12 |
| Grid-3#2 | -21.86 | -33.33 | 14.12 | |
| Grid-3#3 | -21.87 | -33.32 | 14.12 |
分析:在相同数量(3×3=9)但分布不同的控制点下,Neural PSZ的REB比PM好约12 dB,AC高约4.5 dB,且性能几乎不受网格分布影响。
消融实验(灵活网格训练 vs 固定网格训练): 表2展示了Neural PSZ网络在不同训练策略下的性能。
(注:表2内容已整合入下方表格)
| 训练策略 | 网格模式 | REB↓ (dB) | RED↓ (dB) | AC↑ (dB) |
|---|---|---|---|---|
| 灵活网格训练 | Grid-12 | -22.41 | -32.16 | 14.17 |
| Grid-6 | -22.21 | -32.94 | 14.13 | |
| Grid-4 | -22.03 | -33.11 | 14.14 | |
| Grid-3#1 | -21.79 | -33.36 | 14.13 | |
| Grid-2#1 | -20.90 | -33.76 | 14.12 | |
| 固定网格训练 | Grid-12 | -22.67 | -32.70 | 14.07 |
| Grid-6 | -22.68 | -32.66 | 14.08 | |
| Grid-4 | -22.64 | -32.64 | 14.08 | |
| Grid-3#1 | -22.60 | -32.69 | 14.06 | |
| Grid-2#1 | -22.18 | -33.09 | 14.05 |
分析:灵活网格训练(一个模型适配所有网格)相比为每个网格单独训练的固定网格模型,在REB上有约0.5-1.3 dB的轻微损失。这表明为获得灵活性,存在一个可接受的性能折衷。
定性结果:
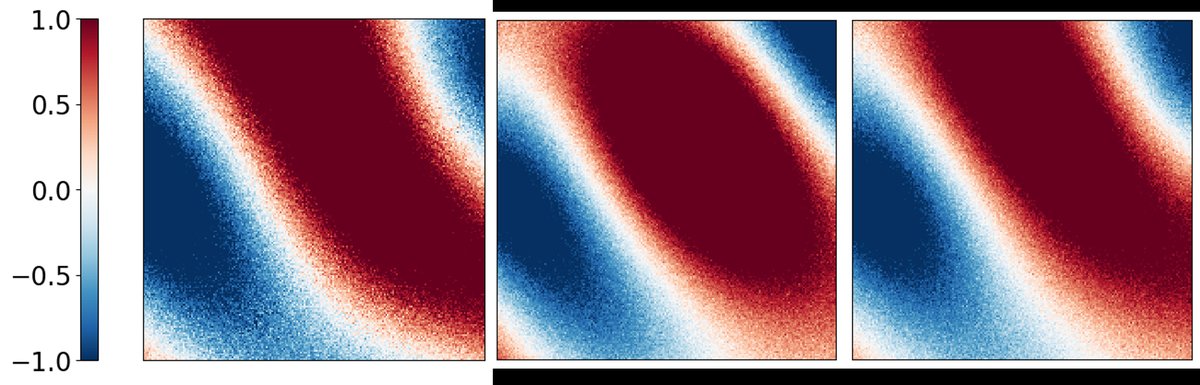
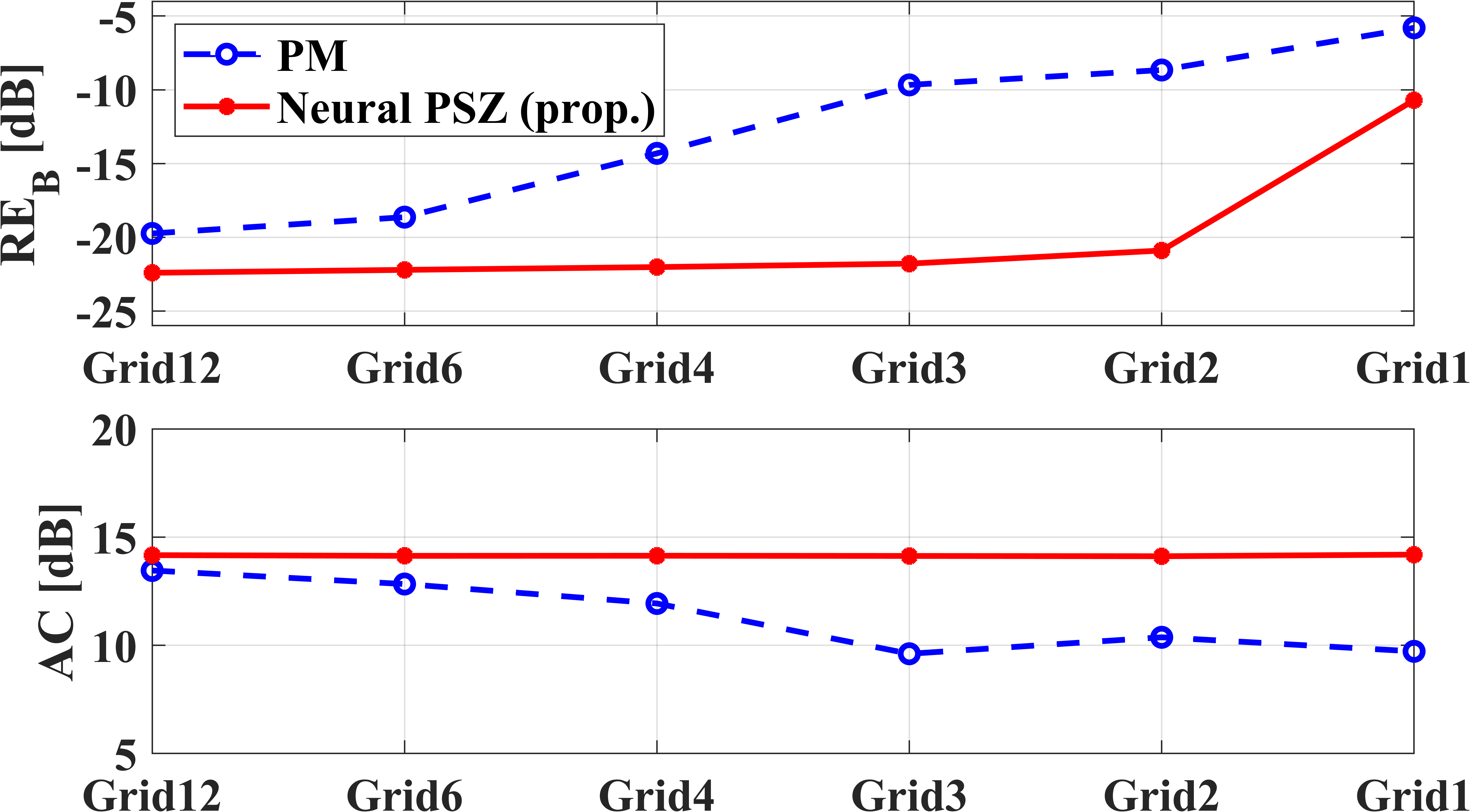 图5展示了在875 Hz频率下,对于一个位于(1.2, 1.8)的虚拟声源,在Grid-3#1输入下,PM方法(中)与Neural PSZ方法(右)重构的BZ声场(实部)与Ground Truth(左)的对比。Neural PSZ的重建结果在空间连续性和平滑度上明显更接近真实值。
图5展示了在875 Hz频率下,对于一个位于(1.2, 1.8)的虚拟声源,在Grid-3#1输入下,PM方法(中)与Neural PSZ方法(右)重构的BZ声场(实部)与Ground Truth(左)的对比。Neural PSZ的重建结果在空间连续性和平滑度上明显更接近真实值。
⚖️ 评分理由
- 学术质量:6.0/7 - 论文明确指出了现有PSZ系统的实际部署痛点(固定网格),并提出了一个针对性强、技术路径清晰的解决方案。3D CNN的应用和随机掩码训练策略设计合理。实验设置了公平的基线对比(PM方法正则化以匹配AE),并进行了多角度消融研究(网格稀疏性、分布、训练策略),证据充分且可信。扣分点在于创新主要停留在方法组合与应用层面,核心的神经网络架构为成熟技术,未在声学领域进行针对性创新。
- 选题价值:1.5/2 - 个人声区是空间音频的一个重要子方向,具有明确的工业应用场景(如个人音频设备、汽车座舱)。本研究直接针对该技术从实验室走向实用化过程中的一个关键障碍(网格固定性)展开,价值明确。与音频/语音读者的关联性较强,尤其关注信号处理和阵列技术的群体。
- 开源与复现加成:0.0/1 - 论文未提供任何开源信息(代码、模型、数据)。虽然描述了实验设置(gpuRIR),但具体的网络超参数、掩码生成策略、训练轮数等关键复现细节缺失,使得独立复现难度较大。因此不给予加成。