📄 Perceptual Loss Optimized HRTF Personalization in Spherical Harmonic Domain
#空间音频 #信号处理 #迁移学习
✅ 7.0/10 | 前25% | #空间音频 | #信号处理 | #迁移学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Yuanming Zheng(武汉大学计算机学院 NERCMS)
- 通讯作者:Yuhong Yang(武汉大学计算机学院 NERCMS,Hubei Key Laboratory of Multimedia and Network Communication Engineering)
- 作者列表:
- Yuanming Zheng(武汉大学计算机学院 NERCMS)
- Yuhong Yang(武汉大学计算机学院 NERCMS;Hubei Key Laboratory of Multimedia and Network Communication Engineering)
- Weiping Tu(武汉大学计算机学院 NERCMS)
- Zhongyuan Wang(武汉大学计算机学院 NERCMS)
- Mengdie Zhou(广东OPPO移动通信公司)
- Song Lin(广东OPPO移动通信公司)
💡 毒舌点评
亮点:论文清晰地指出了HRTF个性化面临的“空间复杂性高”与“数据集规模小”两大痛点,并给出了一个工程上直觉有效的“组合拳”解决方案——用球谐变换(SH)压缩空间维度,再用通用HRTF作为强先验,最后用更符合听觉感知的损失函数来“校准”预测,思路务实且结果改善明显。短板:论文没有开源代码,且实验仅在HUTUBS一个数据集上进行验证,虽然方法描述详尽,但对于一个声称“增强泛化能力”的未来方向而言,当前工作的可复现性和验证广度略显不足,可能影响其作为可靠基准的潜力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文使用了公开数据集 HUTUBS,并提供了引用和网址(https://doi.org/10.14279/depositonce-8487)。但这是第三方数据,并非论文作者自己发布。
- Demo:未提及在线演示。
- 复现材料:论文提供了较为详细的训练策略(优化器学习率调度、早停、Dropout率等)和超参数(SH阶数L=7,损失权重比),但模型的具体网络结构参数(如卷积核大小、通道数、各层维度)未完全公开。
- 论文中引用的开源项目:
- HUTUBS数据集 [23]。
- FABIAN头部仿真器 [24],用于获取通用HRTF。
- 其他引用的基线方法(如DP-SHT [12], HRIR-DDPM [16])的原始论文,但未提及是否使用了它们的公开代码。
📌 核心摘要
本文针对个性化头相关传递函数(HRTF)生成中面临的空间复杂度高和现有数据集规模有限的挑战,提出了一种在球谐域(SH domain)进行HRTF个性化的方法。其核心方法是:首先将通用HRTF转换到球谐域作为群体级空间先验,然后设计一个深度神经网络(DNN),该网络以个体的头部与耳部人体测量参数和频率索引为输入,预测对球谐系数(SH coefficients)的个性化修正,最后通过逆球谐变换(iSHT)重建出个性化的HRTF。与已有方法相比,本文的创新主要在于:1)将球谐变换与通用HRTF先验相结合,在降低计算复杂度的同时,利用通用HRTF提供了良好的初始空间结构;2)引入了感知损失函数,该函数结合了与人耳听觉感知紧密相关的临界带(CB)损失和均方误差(MSE)损失,引导模型更关注感知关键区域。主要实验结果表明,在HUTUBS数据集上,提出的方法取得了3.71 dB的对数谱失真(LSD),相比基线方法(DP-SHT, HRIR-DDPM)提升了至少21.7%。消融研究验证了SH和感知损失各自的有效性。主观听音测试证实,该方法能显著降低前后混淆率(水平面从52.08%降至31.25%,上中面从50.00%降至30.56%)并提高方位准确率(从39.58%提升至81.25%)。本工作的实际意义在于为VR/AR等应用提供了更高质量的个性化空间音频渲染基础。主要局限性在于评估仅基于HUTUBS一个数据集,且论文未提供开源代码和模型,泛化性有待更多数据集验证。
🏗️ 模型架构
论文的整体模型架构如图1所示。
完整输入输出流程:
- 输入:对于每个频率索引k,输入包括:(a) 通用HRTF(作为先验);(b) 该个体的17个标准化人体测量参数(9个耳部相关,8个头部相关);(c) 当前频率索引k。
- 处理流程:
- 球谐变换(SHT)阶段:通用HRTF在每个频率点被转换到球谐域,得到一组SH系数(维度为(L+1)^2,L=7,即64维)。这一步将原始的空间域表示压缩为低维的频域-空间混合表示。
- DNN模型预测阶段:
- HRTF编码器:接收通用HRTF的SH系数(64维),通过两个带批归一化(BN)的1D卷积层(内核大小未说明)提取高级空间特征,然后通过一个全连接(FC)层投影到紧凑的潜在空间,并应用Dropout。
- 特征融合:人体测量参数通过一个FC层处理;频率索引k通过一个嵌入层(Embedding Layer)编码。这些特征与编码器输出的潜在HRTF表征通过“融合块”(Fusion Block, 图中显示为拼接“C”和全连接层“FC”)进行整合。
- HRTF解码器:结构与编码器对称(镜像),将融合后的特征映射回SH系数空间,输出预测的个性化HRTF在球谐域的SH系数。
- 逆球谐变换(iSHT)阶段:将预测出的SH系数通过逆SHT变换回空间域,得到最终预测的个性化HRTF(时域为HRIR,频域为HRTF幅度谱)。
- 输出:个性化HRTF的对数幅度谱(用于计算LSD)或HRIR(用于渲染)。
主要组件与功能:
- SHT/iSHT模块:功能是实现空间域与球谐域之间的转换。动机是降低HRTF的空间复杂度,使其更适合神经网络处理,同时保持整体空间结构并便于与Ambisonics渲染兼容。
- HRTF编码器:功能是从SH域的通用HRTF中提取有意义的、低维的空间特征。内部结构为“Conv1d -> BN -> Conv1d -> BN -> FC -> Dropout”。
- 特征融合块:功能是将从通用HRTF提取的空间先验特征、个体特异性的人体测量特征以及频率位置信息进行融合,使模型能结合全局先验与个体差异进行预测。
- HRTF解码器:功能是根据融合后的特征,重构(或说“预测”)出个性化SH系数。内部结构为“FC -> BN -> Conv1d -> BN -> Conv1d”,与编码器结构镜像。
- 关键设计选择:使用通用HRTF作为输入先验是核心设计,模型的任务不是从头预测HRTF,而是学习对通用HRTF在SH域的个性化修正,这被认为能缓解小数据集训练难题。模型结构相对简单,以平衡性能与数据集规模限制。
💡 核心创新点
SH域结合通用HRTF先验的个性化预测框架:
- 是什么:在球谐域中,以通用HRTF的SH系数为基准,利用DNN学习其与个性化HRTF SH系数之间的残差(或映射)。
- 先前方法局限:单独使用SH(如DP-SHT)直接从人体测量参数预测SH系数,忽略了通用HRTF中蕴含的群体共性空间结构。使用生成模型(如DDPM)直接生成HRIR则面临数据维度高、训练不稳定的问题。
- 如何起作用:SH变换降低了空间维度,通用HRTF提供了良好的初始化。DNN只需学习个性化调整,降低了学习难度,使模型在有限数据集上更易训练。
- 收益:实现了比DP-SHT(直接预测)和HRIR-DDPM(生成模型)更低的LSD(3.71dB vs 4.60dB/5.1dB),且输出SH系数可直接用于基于Ambisonics的渲染系统。
引入与听觉感知紧密相关的感知损失函数:
- 是什么:将经典的均方误差(MSE)损失与临界带(CB)损失线性加权组合成总损失函数。
- 先前方法局限:大多数方法仅使用MSE损失,它平等对待所有频率的误差,未能体现人耳对不同频段感知敏感度的差异。
- 如何起作用:CB损失根据人耳听觉的临界带特性,为不同频率的误差赋予不同权重(公式3),引导模型在训练时更加关注对听觉感知影响大的频段(通常是中低频和特定共振/陷波区域)。
- 收益:消融研究表明,加入CB损失(w/o LCB -> w/ LCB)在两个评估基准下均进一步降低了LSD(从3.82dB降至3.71dB,从2.14dB降至1.92dB)。主观测试显示,它显著降低了前后混淆率(例如上中面从47.22%降至30.56%),并提高了方位准确率。
系统的组件验证与全面的评估体系:
- 是什么:通过设计严谨的消融实验,分别验证了SH变换和感知损失的有效性,并同时采用了客观指标(LSD)和主观听力测试(前后混淆率、方位准确率)进行评估。
- 先前方法局限:部分研究可能只报告客观指标,或仅对比部分基线。
- 如何起作用:消融实验清晰地展示了每个组件的独立贡献(单独SH:4.14dB;单独LCB:3.82dB;组合:3.71dB)。主观实验直接关联到实际应用体验(减少定位错误)。
- 收益:使论文的贡献声明(三个贡献点)得到了实证支持,结果更具说服力。
🔬 细节详述
- 训练数据:HUTUBS数据集,包含96个受试者的头部冲激响应(HRIR)和人体测量参数。其中93人提供完整参数。受试者1(FABIAN头部仿真器)的HRIR被用作通用HRTF。预处理:将右耳HRIR镜像以保持一致性;使用256点FFT转换为对数幅度谱;对17个人体测量参数进行z-score标准化。数据增强:未说明。
- 损失函数:总损失函数为 L_total = λ1 L_MSE + λ2 L_CB。L_MSE是预测SH系数与真实SH系数之间的均方误差。L_CB是结合了CB加权的损失,其中CB权重根据公式(3)计算,与频率f的临界带宽成反比。论文通过实验探索了λ1和λ2的比值,最终选择 λ1 : λ2 = 5 : 5 作为最终模型配置。
- 训练策略:
- 训练/验证方式:留一法交叉验证(LOOCV),即每次留出一个受试者作为测试集,其余作为训练集。
- 优化器:未明确说明(可能默认Adam)。
- 学习率:初始学习率0.001,每100个epoch衰减20%。
- 训练步数/轮数:最多训练500个epoch,采用早停策略(若20个epoch无改善则停止)。
- Batch Size:未说明。
- Warmup:未说明。
- 关键超参数:
- SH阶数:截断阶数 L=7,生成64维SH系数。
- 模型规模:论文称采用“简单而有效”的模型,但未明确给出网络各层的通道数、隐藏维度等具体参数。从图1看,编码器和解码器各有2个1D卷积层和若干FC层。
- Dropout率:编码器FC层后使用 50% 的Dropout。
- 训练硬件:NVIDIA GeForce RTX 4060 Ti 单卡。
- 推理细节:推理时,输入个体的测量参数和频率索引,与预定义的通用HRTF一起,经模型前向传播得到预测的SH系数,再通过iSHT重建HRTF。论文提到使用了通用HRTF的相位谱与预测的幅度谱结合来生成用于主观测试的HRIR。
- 正则化或稳定训练技巧:使用了批归一化(BN)和Dropout。此外,采用早停策略防止过拟合。
📊 实验结果
论文在HUTUBS数据集上进行了全面的评估。
主要目标实验结果(表2):
| 方法 | 对比基准:实测HRTF | 对比基准:SHT重建HRTF |
|---|---|---|
| 系数分析(本文方法) | ||
| Ours (λ1:λ2=7:3) | 3.74 dB | 2.02 dB |
| Ours (λ1:λ2=5:5) | 3.71 dB | 1.92 dB |
| Ours (λ1:λ2=3:7) | 3.76 dB | 2.03 dB |
| 基线对比 | ||
| DP-SHT [12] | 4.74 dB | 3.81 dB |
| DP-SHT*[12] (复现) | 4.60 dB | 3.26 dB |
| HRIR-DDPM [16] | 5.1 dB | - |
| 消融研究 | ||
| Ours (w/o LCB) | 3.82 dB | 2.14 dB |
| Ours (w/o SHT) | 4.14 dB | - |
| Ours (w/o SHT & LCB) | 4.84 dB | - |
- 结论:提出方法(λ1:λ2=5:5)在LSD指标上达到最优(3.71 dB),比复现的DP-SHT基线(4.60 dB)降低约19.3%,比HRIR-DDPM(5.1 dB)降低约27.3%,论文称“至少改善21.7%”。消融研究证实,SH变换和LCB损失各自都对性能提升有贡献。
主观实验结果(表3):
| 方法 | 前后混淆率(水平面) ↓ | 前后混淆率(上中面) ↓ | 方位准确率 ↑ |
|---|---|---|---|
| Generic HRTF | 52.08% | 50.00% | 39.58% |
| DP-SHT* [12] | 40.63% | 46.88% | 72.92% |
| Ours (w/o LCB) | 34.38% | 47.22% | 77.08% |
| Ours (w/ LCB) | 31.25% | 30.56% | 81.25% |
- 结论:提出方法(w/ LCB)在减少前后混淆率和提高方位准确率上均显著优于使用通用HRTF和基线DP-SHT。特别是在上中面,引入CB损失使混淆率从47.22%大幅下降到30.56%。论文将此归因于对HRTF陷波(notch)频率更准确的预测,如图2(f)所示。
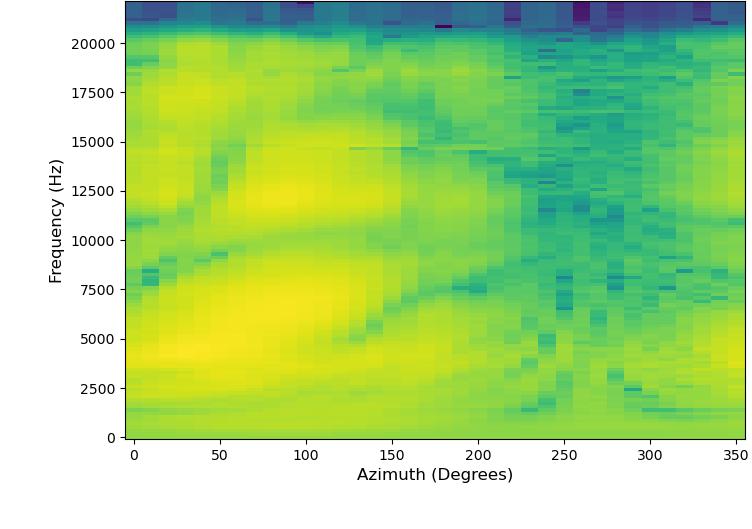
HRTF可视化对比(图2):
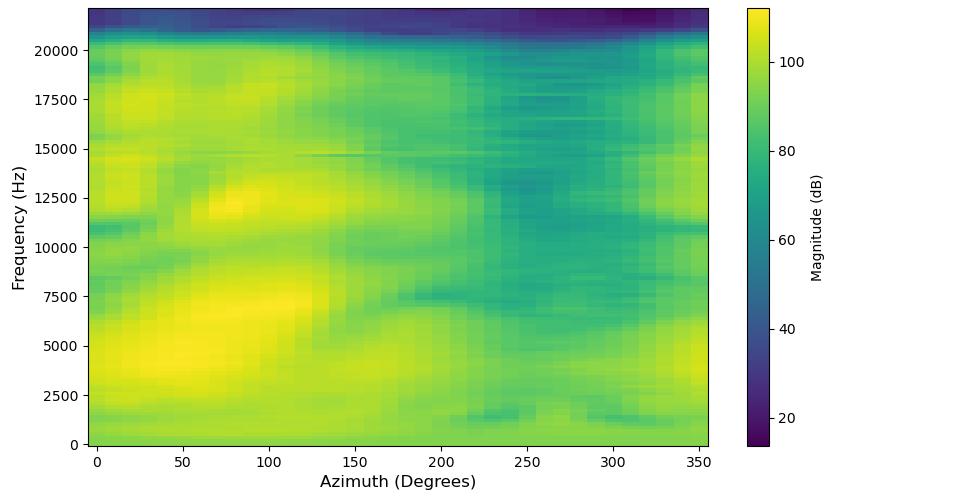
- 子图(a)-(d):展示了水平面上对数幅度谱的俯视图。可以直观看出,(d) 提出方法预测的HRTF比(c) 基线DP-SHT预测的HRTF,在细节纹理(如亮线和暗带)上更接近(a) 真实HRTF和(b) SHT重建的真实HRTF。
- 子图(e)-(f):在特定方向(正前方)的幅度谱对比。图(f)的红框区域显示,提出方法对频率陷波(notch)的预测(橙线)比基线(绿线)更接近真实值(蓝线)和SHT重建值(虚线),这被认为是改善垂直定位的关键。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个清晰、合理且有效的技术方案,将球谐变换、通用HRTF先验和感知损失三者有机结合。实验设计规范,包含消融实验、客观与主观评估,数据呈现清晰。主要不足是创新性更多体现在系统整合与工程优化上,而非提出全新的理论或模型架构。实验仅在单一数据集上进行,泛化性验证不足。
- 选题价值:1.5/2:HRTF个性化是沉浸式音频(VR/AR)的核心技术难题,具有明确的应用需求和前沿性。但该问题领域相对专业和垂直,其研究成果对更广泛的音频/语音处理社区的直接启发性和影响力有限。
- 开源与复现加成:0/1:论文未提供代码、模型权重或任何可直接复现的资源链接。虽然详细描述了训练细节,但缺少这些关键材料使得独立验证和基于此工作的后续研究门槛较高。因此,此项无加分。