📄 PC-MCL: Patient-Consistent Multi-Cycle Learning with Multi-Label Bias Correction for Respiratory Sound Classification
#音频分类 #数据增强 #多任务学习
✅ 7.5/10 | 前10% | #音频分类 | #数据增强 | #多任务学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Seung Gyu Jeong(首尔科技大学应用AI系)
- 通讯作者:Seong-Eun Kim(首尔科技大学应用AI系)
- 作者列表:Seung Gyu Jeong(首尔科技大学应用AI系),Seong-Eun Kim(首尔科技大学应用AI系)
💡 毒舌点评
亮点在于论文系统性地指出了一个在多周期拼接方法中普遍存在但易被忽视的实际问题(多标签分布偏差),并提出了一个简单有效的三标签公式进行纠正,具有明确的临床直觉和可解释性。短板是作为主要正则化手段的“患者匹配”辅助任务,其带来的性能增益(如表3所示,+0.25分)在统计上并不显著,使得该核心创新点略显乏力;同时,论文对关键训练细节(如超参数、硬件)的交代不够完整,影响了可复现性。
🔗 开源详情
- 代码:论文中未提及任何代码仓库链接或开源计划。
- 模型权重:未提及公开的模型权重。
- 数据集:使用公开的ICBHI 2017呼吸音数据库,但论文未说明数据获取方式或预处理脚本。
- Demo:未提及在线演示。
- 复现材料:论文提供了实验设置的部分描述(如数据集划分、音频采样率、梅尔频谱图参数、固定输入长度),但缺失了大部分训练超参数和硬件信息,不足以完全复现。
- 引用的开源项目:论文引用了AST、BEATs等预训练模型作为骨干网络,这些是公开的。
📌 核心摘要
- 要解决什么问题:呼吸音自动分类面临两个主要限制:一是传统方法多为单周期分析,忽略了病理音在真实听诊中短暂且间歇出现的时序上下文;二是模型容易过拟合到特定患者的声学特征,而非通用的病理特征。
- 方法核心是什么:提出PC-MCL框架,包含三个核心组件:a) 多周期拼接作为数据增强,以模拟更真实的听诊场景;b) 一种新的3标签(正常、爆裂音、哮鸣音)标注方案,用于纠正传统2标签方案在拼接混合周期时导致的“正常”信息丢失问题;c) 一个患者匹配辅助任务,作为正则化器以减轻患者特异性过拟合。
- 与已有方法相比新在哪里:最关键的新颖性在于识别并解决了“多标签分布偏差”——即在使用传统2标签方案时,将正常周期与异常周期拼接后,标签会完全变成异常标签,从而系统性地削弱了模型对正常信号的建模能力。本文提出的3标签独立建模方案是解决此问题的关键。
- 主要实验结果如何:在ICBHI 2017基准数据集上,PC-MCL(使用BEATs骨干网络)达到了65.37% 的ICBHI Score,超过了此前最佳的64.84%。消融实验表明,多标签公式对提高灵敏度(+2.31%)贡献最大,而患者匹配任务则进一步提升了特异性和整体分数。与基线CE模型相比,在两个不同骨干网络(AST, BEATs)上均带来了显著的性能提升(分数提升约3-4个百分点)。
- 实际意义是什么:该框架提升了呼吸音分类的鲁棒性和泛化能力,对于辅助肺部疾病的低风险、低成本筛查具有潜在价值。它强调了在医疗音频分析中,数据增强策略需谨慎设计以保持标签的生物学合理性。
- 主要局限性是什么:a) 患者匹配辅助任务的贡献相对较小且不够稳定;b) 训练和推理之间存在微小的领域偏移(训练用拼接长音频,推理用单周期短音频),尽管论文称其稳健,但未深入分析;c) 论文未提供代码和模型权重,且关键训练细节缺失。
🏗️ 模型架构
论文的整体架构如图1所示。其核心流程为:
- 输入:输入为一对单独的呼吸音周期(x⁽¹⁾, x⁽²⁾)。
- 多周期拼接与预处理:每个周期被归一化到固定长度(T/2),然后进行拼接,形成一个长度为T的复合输入信号
˜x。该信号随后被转换为128维的梅尔频谱图。 - 共享编码器:梅尔频谱图被输入到一个共享的骨干编码器(fθ)中,例如AST或BEATs,提取一个高维特征向量z ∈ R^D。
- 任务特定头:特征向量z被同时输入到两个独立的投影头中:
- 主任务头(h_ϕ^main):执行病理分类任务,输出3维的概率向量,对应[正常, 爆裂音, 哮鸣音]三个标签。
- 辅助任务头(h_ϕ^aux):执行患者匹配任务,输出一个二分类概率,判断输入的两个周期是否来自同一患者(y_aux)。
- 输出:主任务头的输出用于计算主任务损失(L_main),辅助任务头的输出用于计算辅助任务损失(L_aux)。最终损失为两者的加权和。
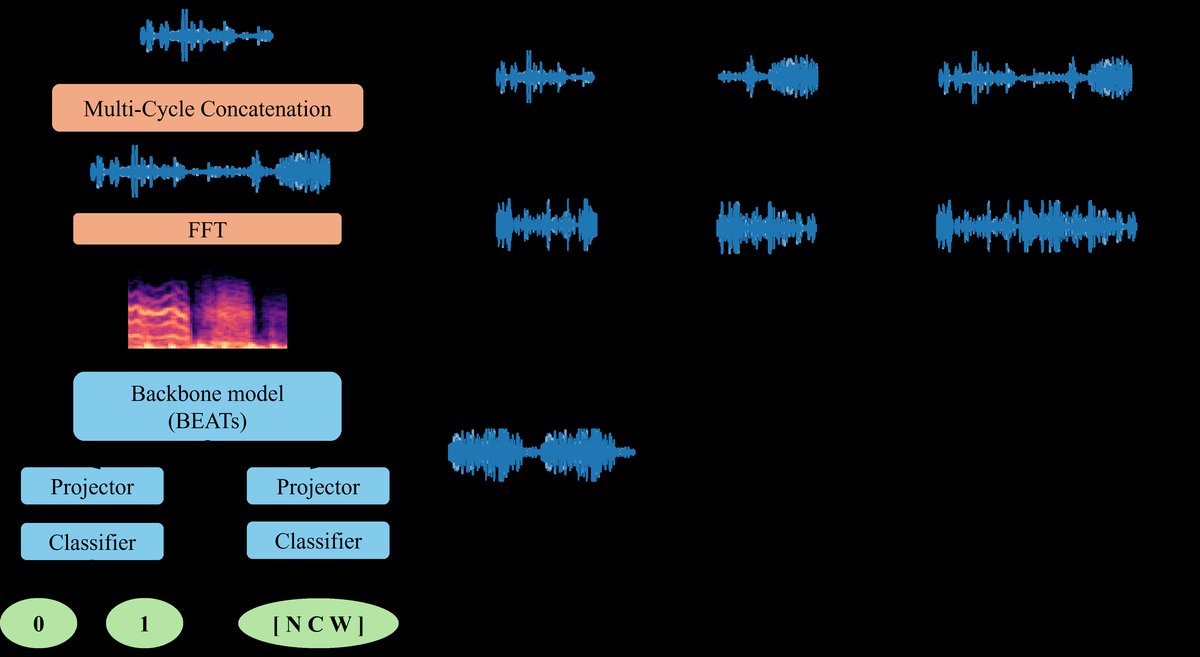 图1说明:该图清晰地展示了PC-MCL的流程。左侧是输入的多周期拼接与转换为梅尔频谱图的过程。中间是共享的编码器(Backbone Encoder)。右侧是两个并行的任务头:上方的主任务(Pathology Classification)和下方的辅助任务(Patient-Matching)。这体现了多任务学习的框架设计。
图1说明:该图清晰地展示了PC-MCL的流程。左侧是输入的多周期拼接与转换为梅尔频谱图的过程。中间是共享的编码器(Backbone Encoder)。右侧是两个并行的任务头:上方的主任务(Pathology Classification)和下方的辅助任务(Patient-Matching)。这体现了多任务学习的框架设计。
💡 核心创新点
多周期拼接数据增强:
- 是什么:将两个呼吸周期(可以是同类或跨类,也可以是跨患者)拼接成一个更长的输入序列。
- 之前局限:单周期分析无法捕捉异常声音在连续呼吸周期中短暂出现的时序模式。
- 如何起作用:模拟真实听诊场景,强制模型学习在更长的上下文中识别病理声音,尤其是与正常呼吸混合出现的异常声音。
- 收益:提供了更丰富的训练样本,使模型学习到更鲁棒的特征表示。
3标签独立-正常标注方案:
- 是什么:将传统的二分类(爆裂音/哮鸣音)扩展为三标签(正常, 爆裂音, 哮鸣音),每个标签独立建模。
- 之前局限:传统的2标签方案在拼接正常+异常周期时,标签会变成纯异常标签,导致模型在训练混合样本时丢失了“正常”部分的信息,造成系统性偏差。
- 如何起作用:通过元素级逻辑或运算生成混合样本的新标签(例如,正常[1,0,0] + 爆裂音[0,1,0] -> [1,1,0]),完整保留了所有组成部分的存在信息。
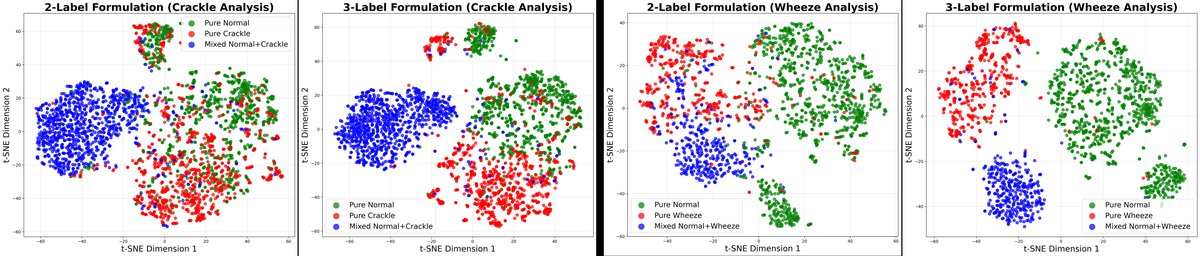
- 收益:纠正了标签分布偏差。如图2所示,该方案使模型在特征空间中成功区分了纯正常、纯异常和混合样本(而2标签模型无法区分)。表4显示,虽然2标签方案灵敏度更高,但特异性极低,导致整体分数(60.42%)远低于3标签方案(65.37%)。
患者匹配辅助任务:
- 是什么:一个二分类任务,用于判断输入的两个拼接周期是否属于同一患者。
- 之前局限:模型容易学习到患者特有的声学“指纹”,而非疾病共有的病理特征,导致对新患者泛化能力差。
- 如何起作用:作为一个正则化器,鼓励编码器在提取病理特征的同时,显式地关注或忽略患者身份信息。采用“困难负样本挖掘”(从相同病理但不同患者中采样)来增强难度。
- 收益:作为多任务学习的正则化手段,理论上可以提升主任务的泛化能力。表3显示,加入PM任务后,Specificity和Score均有小幅提升。
🔬 细节详述
- 训练数据:使用ICBHI 2017呼吸音数据库,采用官方的60%-40%训练/测试划分。音频被重采样至16kHz。
- 数据增强:核心增强为多周期拼接。对于每个原始样本,生成一个增强样本,包含同类拼接和跨类拼接,并同时考虑跨患者和患者内拼接以增加多样性。梅尔频谱图参数:128维,25ms窗长,10ms帧移。
- 损失函数:
- 主任务损失(L_main):二值交叉熵损失(Binary Cross-Entropy with Logits Loss),作用于3维预测向量和3维标签。
- 辅助任务损失(L_aux):交叉熵损失(Cross-Entropy Loss),作用于二分类预测。
- 总损失:
L_total = L_main + α * L_aux,其中α是权重。论文中说明α=0.1基于验证集上的网格搜索确定。
- 训练策略:论文未明确说明学习率、优化器、batch size、训练轮数等具体训练策略和超参数。
- 关键超参数:输入固定长度T=10秒(即每个周期T/2=5秒)。骨干网络使用预训练的AST(在ImageNet和AudioSet上预训练)或BEATs(在AudioSet上预训练)。
- 训练硬件:论文未提及具体的GPU型号、数量或训练时长。
- 推理细节:在推理时,每个测试周期被单独填充或截断到目标长度(未说明具体值),输入模型得到3维概率输出。通过阈值0.5二值化后,根据临床优先级规则(共存则为‘both’)转换为4类(Normal, Crackle, Wheeze, Both)进行评估。
- 正则化技巧:除了患者匹配辅助任务外,论文未提及其他显式的正则化技巧(如Dropout)。骨干网络使用了预训练权重,本身是一种迁移学习正则化。
📊 实验结果
表1:与先前方法在ICBHI数据集上的性能对比(4分类任务)
| 方法 | 骨干网络 | 预训练 | 增强 | 特异性 (Sp %) | 灵敏度 (Se %) | ICBHI Score (%) |
|---|---|---|---|---|---|---|
| LungRN+NL [16] | ResNet-NL | - | Mixup (2-label) | 63.20 | 41.32 | 52.26 |
| RespireNet [5] | ResNet34 | IN | Concat (同类) | 72.30 | 40.10 | 56.20 |
| Domain [6] | ResNeSt | IN | Splicing (同类) | 70.40 | 40.20 | 55.30 |
| Patch-Mix CL [17] | AST | IN + AS | Patch-Mix | 81.66 | 43.07 | 62.37 |
| RepAugment [18] | AST | IN + AS | RepAugment | 82.47 | 40.55 | 61.51 |
| PAFA [9] | BEATs | AS | - | 82.05 | 47.63 | 64.84 |
| AST + PC-MCL | AST | IN + AS | Concat (同类/跨类) | 78.54±1.87 | 46.05±1.62 | 62.30±0.50 |
| BEATs + PC-MCL | BEATs | AS | Concat (同类/跨类) | 79.04±1.90 | 51.71±2.98 | 65.37±0.73 |
表2:与基线CE模型的性能对比
| 模型 | 方法 | 预训练 | Sp (%) | Se (%) | Score (%) |
|---|---|---|---|---|---|
| AST | CE | IN + AS | 77.14±5.43 | 41.97±5.04 | 59.55±0.50 |
| AST | PC-MCL | IN + AS | 78.54±1.87 | 46.05±1.62 | 62.30±0.50 |
| BEATs | CE | AS | 76.85±1.88 | 48.79±1.72 | 62.82±0.62 |
| BEATs | PC-MCL | AS | 79.04±1.90 | 51.71±2.98 | 65.37±0.73 |
表3:组件消融研究(基于BEATs骨干网络)
| Concat | Multi | PM | Sp (%) | Se (%) | Score (%) |
|---|---|---|---|---|---|
| 76.85±1.88 | 48.79±1.72 | 62.82±0.62 | |||
| ✓ | 73.10±2.47 | 51.10±2.97 | 62.10±0.64 | ||
| ✓ | 78.05±2.49 | 50.33±2.93 | 64.19±0.31 | ||
| ✓ | ✓ | 76.66±2.93 | 51.91±2.25 | 64.28±0.62 | |
| ✓ | ✓ | ✓ | 79.04±1.90 | 51.71±2.98 | 65.37±0.73 |
表4:2标签与3标签公式对比(基于BEATs)
| 标签公式 | Sp (%) | Se (%) | Score (%) |
|---|---|---|---|
| 2-label | 58.86 ± 9.59 | 61.98 ± 8.04 | 60.42 ± 1.31 |
| 3-label (Ours) | 79.04 ± 1.90 | 51.71 ± 2.98 | 65.37 ± 0.73 |
表5:患者匹配辅助任务的负样本策略对比(基于BEATs)
| 设置 | Sp (%) | Se (%) | Score (%) |
|---|---|---|---|
| Base | 78.30±4.20 | 51.21±3.77 | 64.76±0.26 |
| Hard | 79.04±1.90 | 51.71±2.98 | 65.37±0.73 |
关键结论:
- 表1:PC-MCL(BEATs)取得了65.37% 的最高分,超越了之前最佳的PAFA(64.84%)。PC-MCL在灵敏度(Se)上取得了显著提升(51.71% vs 47.63%),但特异性(Sp)略低于PAFA。
- 表2:无论在AST还是BEATs骨干上,PC-MCL相比标准CE基线都带来了显著的分数提升(+2.75% 和 +2.55%),特别是在灵敏度上。
- 表3:三个组件协同作用。单独添加拼接(Concat)主要提升Se但Sp下降;单独添加多标签(Multi)显著提升Se和Score;同时使用两者(Concat+Multi)后,添加患者匹配(PM)任务进一步稳定提升了Sp和Score至最佳。
- 表4:3标签公式虽然Se低于2标签,但Sp大幅提升,导致最终Score远高于2标签公式,直观展示了纠正分布偏差的价值。
- 图2(t-SNE可视化):直观显示了3标签模型(右)能将混合样本(蓝色)与纯异常样本(红色)在特征空间中分开,而2标签模型(左)则将两者混杂,证实了3标签公式在保留信息上的有效性。
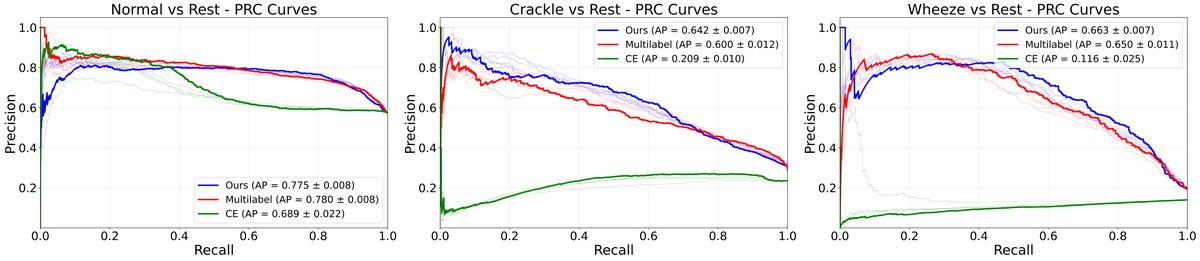
- 图3(精确率-召回率曲线):显示了从基线CE模型到中间模型(仅多标签)再到最终PC-MCL模型的逐步性能提升。仅引入多标签公式就使得异常类的平均精度(AP)大幅提升,而完整框架进一步小幅提升,验证了各组件的累积效益。
⚖️ 评分理由
- 学术质量:6.0/7:论文工作扎实,提出了一个解决实际问题的系统性框架。创新点(尤其是3标签公式)清晰且有说服力。实验设计全面,包括与SOTA对比、基线对比、详尽的消融研究(组件、标签公式、负样本策略)和无阈值分析(PR曲线)。数据统计可靠(报告均值±标准差)。扣分点在于:辅助任务的效果量相对较小;训练细节缺失影响了方法的透明度和可复现性判断。
- 选题价值:1.5/2:呼吸音分类是医疗AI中一个重要且活跃的分支,具有明确的实际应用价值(低成本筛查)。论文针对数据增强过程中的偏差提出了解决方案,对相关领域的研究者有较好的参考价值。虽然不是最前沿的大模型或多模态工作,但在垂直领域内具有很好的实践意义。
- 开源与复现加成:0.0/1:论文未提供代码仓库链接、模型权重或详细的训练���本/配置。关键的超参数(如优化器、学习率、batch size)和硬件信息也未说明。这严重限制了该工作的可复现性。因此此项不给加成。