📄 PADAM: Perceptual Audio Defect Assessment Model
#音频分类 #对比学习 #预训练 #音频安全
✅ 7.0/10 | 前50% | #音频分类 | #对比学习 | #预训练 #音频安全
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Alex Mackin, Pratha Khandelwal(共同贡献,论文中未明确区分第一作者)
- 通讯作者:论文中未明确标注通讯作者
- 作者列表:Alex Mackin (Amazon Prime Video), Pratha Khandelwal (Amazon Prime Video), Veneta Haralampieva (Amazon Prime Video), Michael Lau (Amazon Prime Video), Benoit Vallade (Amazon Prime Video), David Higham (Amazon Prime Video), Josh Anderson (Amazon Prime Video)
💡 毒舌点评
亮点:合成缺陷生成流程设计得相当扎实,考虑了从源到转码的整个制作管道,并针对七种缺陷给出了具体的生成算法和参数范围,这使得模型训练数据更贴近真实的工业场景。短板:模型在区分“技术缺陷”和“创意意图”上表现拙劣(生产评估中68.1%的“问题”实为创意意图),这暴露了纯信号层面检测的根本局限,也让“无参考感知评估”的“感知”二字打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:合成数据生成流程描述详细,但未提供生成的脚本或数据本身。未提及。
- Demo:未提及。
- 复现材料:论文提供了合成数据生成的详细参数范围、模型架构和训练超参数,为复现提供了必要的信息基础,但缺少可直接运行的配置和脚本。
- 论文中引用的开源项目:引用了AST[37]、ViViT[39]、SimCLR[11]、InfoNCE[40]等模型的实现框架概念,但未提及依赖的具体开源代码库。
- 总结:论文中未提及任何开源计划。复现依赖于读者根据文中描述自行搭建流程。
📌 核心摘要
- 问题:专业媒体内容中的音频缺陷(如削波、丢包、噪声)会严重影响用户体验,但传统检测方法难以应对多样化的创意内容和大规模处理流程。
- 方法核心:提出PADAM模型,一个三阶段的无参考感知评估架构:(1) 通过音视频对比学习训练一个通用的音频特征提取器;(2) 使用融合质量指标的软聚类对比学习,训练一个感知质量头;(3) 使用SVM分类器进行鲁棒的缺陷检测。为解决标注数据稀缺,设计了一套合成缺陷生成工作流,模拟七种常见音频缺陷及其在制作管道中的交互。
- 新在何处:主要在于将现有的对比学习、自监督预训练和合成数据生成技术,针对专业媒体音频缺陷检测这一特定工业场景进行了系统性的整合与适配。创新性地提出了融合多质量指标的“软分配”对比损失,以更好地处理质量评估的不确定性。
- 主要结果:在离线测试集(包含真实缺陷)上,PADAM的片段级F1分数达到0.66,标题级(经时间过滤后)F1分数达到0.75,显著优于Audio Artifacts、DNSMOS、NISQA、SRMR和SCOREQ等基线模型(见下表)。在17K标题的生产流量评估中,模型仅将0.8%(135个)标题标记为需人工审查,其中包含35个真实缺陷,人工审查的精确率为25.9%(若将创意意图也算作正确检测,则达94.1%)。
表2:与基线模型在离线测试集上的片段级性能对比
| 模型 | 阈值 | 精确率 (↑) | 召回率 (↑) | F1分数 (↑) |
|---|---|---|---|---|
| AA | - | 0.02 | 0.50 | 0.04 |
| DNSMOS | 2.12 | 0.03 | 0.27 | 0.05 |
| NISQA | 1.11 | 0.03 | 0.58 | 0.05 |
| SRMR | 0.33 | 0.19 | 0.38 | 0.25 |
| SCOREQ | 1.24 | 0.03 | 0.26 | 0.05 |
| PADAM | 0.67 | 0.79 | 0.56 | 0.66 |
表3:PADAM组件消融研究及与基线模型在标题级(经时间过滤)的性能对比
| 模型 | 滤波器 | 阈值 | 精确率 (↑) | 召回率 (↑) | F1分数 (↑) |
|---|---|---|---|---|---|
| 基线模型 | |||||
| DNSMOS | 100s/100s | 2.12 | 0.67 | 0.20 | 0.31 |
| NISQA | 120s/120s | 1.11 | 0.04 | 0.20 | 0.07 |
| SRMR | 100s/100s | 0.28 | 0.43 | 0.30 | 0.35 |
| SCOREQ | 20s/20s | 0.99 | 0.01 | 0.10 | 0.02 |
| PADAM消融 | |||||
| +特征提取器 | 45s/45s | 0.63 | 0.20 | 0.80 | 0.32 |
| +质量头 | 90s/110s | 0.62 | 0.57 | 0.40 | 0.47 |
| +SVM分类器 | 20s/80s | 0.67 | 1.00 | 0.60 | 0.75 |
- 实际意义:该模型已在Amazon Prime Video生产环境中部署,能有效辅助内容操作员进行质量审查,大幅降低人工检查范围。
- 主要局限:模型最大的软肋是无法区分音频缺陷和具有相似声学特征的创意意图(如雨声与噪声)。此外,离线评估数据集规模较小,且仅覆盖了七种缺陷中的三种。
🏗️ 模型架构
PADAM是一个三阶段、可独立训练的无参考音频缺陷检测模型。其整体流程是:输入10秒音频 -> 特征提取器生成序列嵌入 -> 质量头处理嵌入得到全局表示 -> SVM分类器输出缺陷概率。各阶段在后续阶段训练时冻结。
- 阶段1:特征提取器
- 目标:学习对音频内容和质量变化均敏感的通用表示。
- 架构与数据流:采用一个在音视频对比学习任务上预训练的多模态模型。
- 音频编码器:使用AST(音频频谱图Transformer),将16kHz音频转为梅尔频谱图(128 mels x 41 时间步),输出维度为3×384的序列嵌入(对应约133ms分辨率)。
- 视频编码器:使用ViViT(视频Vision Transformer),处理144×256帧,输出5×384嵌入。训练后丢弃。
- 训练:使用双向InfoNCE对比损失。正样本为同步的音频-视频时间平均嵌入对,负样本为其他干净片段的配对。温度参数τ1 = 0.1。
- 设计动机:利用音视频同步性作为监督信号,无需文本或缺陷标签,即可学习到对内容和质量变化都敏感的音频表示。
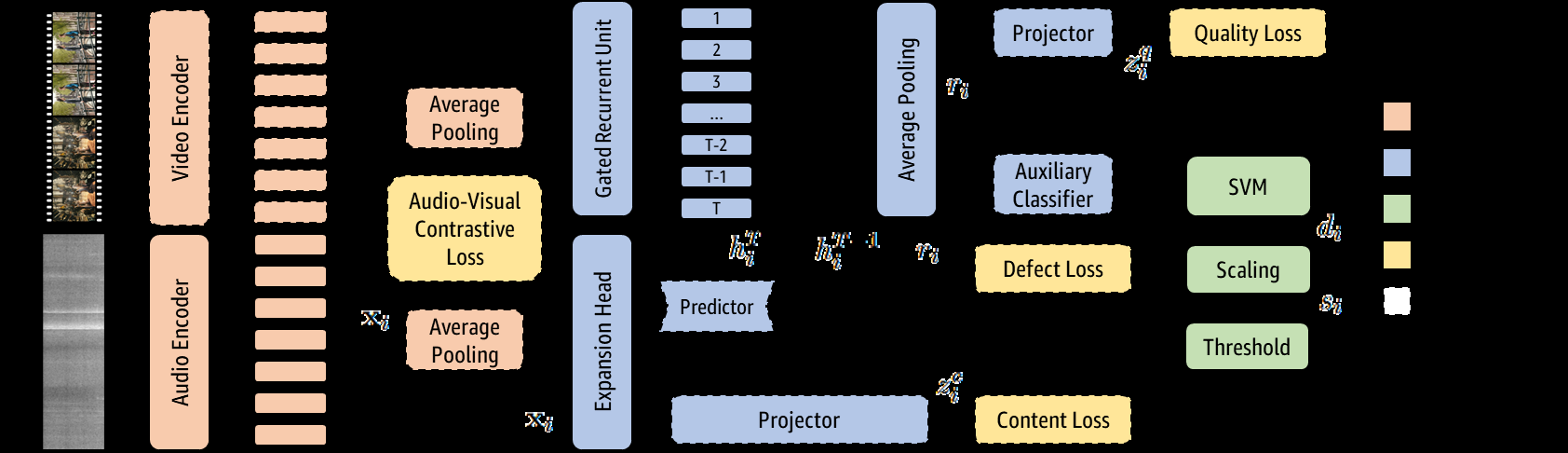 图2:PADAM三阶段架构。阶段1和2训练完成后被冻结,仅在阶段2训练时移除。最终推理仅需特征提取器和SVM分类器。
图2:PADAM三阶段架构。阶段1和2训练完成后被冻结,仅在阶段2训练时移除。最终推理仅需特征提取器和SVM分类器。
阶段2:质量头
- 目标:将通用嵌入转化为针对感知音频质量的表示。
- 架构与数据流:
- 输入冻结的特征提取器输出的嵌入序列
xi ∈ R^(T×384),其中T=75(10秒音频)。 - 通过两层MLP(
fhead: 384→384→512,GELU激活,25% Dropout)和一个GRU,得到时间步隐藏状态hti ∈ R^512。 - 定义两个投影头:
fproj: 512→512→128,用于生成用于聚类的质量/内容嵌入zi。fpred: 512→128→512,用于预测未来时间步的表示,用于内容损失。 损失函数:总损失L = 1/2 Ld - Lq - Lc
Lq(质量损失):使用带软分配掩码的掩码对比损失。掩码mq_ij = 1 - |q̂i - q̂j|,其中q̂i是融合质量指标分数。这使得质量相似的样本在嵌入空间中接近,处理了质量评估固有的不确定性。Lc(内容损失):使用二元掩码(同一片段为1,否则为0),鼓励同一音频片段不同部分的表示保持一致,实现时间稳定性。Ld(辅助分类损失):7标签二元交叉熵损失,用于引导表示学习区分七种缺陷类型。
- 输入冻结的特征提取器输出的嵌入序列
- 设计动机:结合内容感知(时间一致性)和质量感知(基于融合指标的软聚类)的对比学习,使模型学习到与感知质量对齐的表示。软分配比硬阈值更适合处理质量分数的噪声和连续性。
阶段3:SVM分类器
- 目标:在质量头输出的表示之上,进行稳健的二分类。
- 架构与数据流:
输入质量头输出的全局表示
ri = (1/T) Σhti。- 使用RBF核的SVM,优化参数ν(异常值分数)和γ(核系数)。
- 输出分数通过sigmoid-like函数缩放:
si = (1 + exp(-di/σ))⁻¹,其中σ是训练集所有SVM分数di的均方根。对si设置阈值进行二分类。
- 设计动机:SVM在高维空间处理复杂决策边界能力强,且对异常值鲁棒,适合部署。相比复杂的神经网络分类器更轻量、稳定。
💡 核心创新点
- 面向专业媒体的端到端无参考评估流水线:系统性地整合了预训练特征提取、自监督质量建模和传统机器学习分类器,形成了一个可部署于生产环境的完整解决方案。其创新在于针对特定工业场景(专业媒体、七种缺陷、制作管道)的整合与适配,而非提出全新的基础模型。
- 基于融合质量指标的软分配对比学习:提出使用多个客观质量指标(PESQ, CDPAM, ViSQOL, DNSMOS)的加权融合作为监督信号,并通过计算样本间质量差异的连续值来定义对比损失中的掩码(
mq_ij = 1 - |q̂i - q̂j|)。局限:之前方法(如RankDVQA)使用基于VMAF排名的硬阈值二元掩码,无法处理质量分数的不确定性和噪声,且依赖单一指标。该创新使模型能更稳健地从质量分数中学习。 - 多层次合成缺陷生成工作流:设计并实现了一套详细的流程,用于生成七种真实世界音频缺陷(Hum, Hiss, Drops/Ticks/Stutter, Clipping, Quantization, Packet Loss, Clicks)。该流程模拟了从源内容、源编码到转码的三阶段制作管道,并考虑了缺陷与压缩算法的交互。局限:之前研究多使用现有数据集(如语音数据集)或简单的扰动,难以覆盖专业媒体中复杂的缺陷组合与传播路径。该工作流为解决训练数据稀缺问题提供了可复现的方案。
🔬 细节详述
- 训练数据:
- 合成数据:250K个10秒立体声片段。其中75%用于训练,25%用于验证。包含单缺陷(65%)、多缺陷(25%)和干净样本(10%)。
- 源内容:从内部数据集随机采样的干净片段。
- 缺陷生成:针对七种缺陷各有具体算法和参数范围(见论文3.1.1节)。
- 编码/转码:源编码(50%概率,使用AAC/MP3/Opus)和转码(50%概率,使用AAC,可选响度归一化和低通滤波)。
- 损失函数:总损失
L = 0.5*Ld - Lq - Lc。Lq和Lc为带掩码的对比损失,Ld为二元交叉熵。 - 训练策略:
- 特征提取器:在64块V100 GPU上,使用1M干净音视频片段训练。优化器:Adam,使用单周期学习率(1e-4),梯度裁剪,水平翻转增强。温度τ1=0.1。
- 质量头:优化器:SGD,单周期学习率(2e-4),权重衰减(1e-5),批大小256,梯度裁剪。温度τ2=0.2。训练时冻结特征提取器。
- 关键超参数:嵌入维度384,GRU隐藏层维度512,投影头输出128。合成数据的缺陷参数(如信噪比、比特深度、中断频率等)有具体范围(见论文3.1.1节)。
- 训练硬件:特征提取器使用64块NVIDIA V100 GPU。质量头和SVM的硬件未说明。
- 推理细节:推理时仅使用特征提取器(提取75个时间步的嵌入)和SVM分类器。质量头在推理时仅计算全局平均嵌入
ri。缺陷检测通过设置SVM输出分数si的阈值实现。 - 正则化技巧:特征提取器使用梯度裁剪;质量头使用Dropout(25%)和权重衰减(1e-5);使用对比学习本身的负样本作为隐式正则化。
📊 实验结果
- 离线评估(基于真实缺陷的测试集) 测试集:596个干净视频和10个包含缺陷(stutter, hiss, quantization)的视频(总长20分钟至2小时)。缺陷段占比0.56%。
对比模型(片段级F1分数,见表2):PADAM (0.66) 显著高于最佳基线SRMR (0.25)。基线模型多为语音质量评估工具,泛化至媒体音频缺陷时性能下降。
消融研究与时间过滤(���题级F1分数,见表3):
- 组件贡献:特征提取器提供高召回率(0.80),质量头提升精确率并平衡性能(F1从0.32升至0.47),SVM进一步优化决策边界,最终实现最高F1(0.75)。
- 时间过滤:加入要求“X秒内检测到Y秒”的滚动窗口后,标题级性能相比片段级大幅提升(从0.66到0.75)。
- 生产评估(17K标题)
- 检测率:模型标记了135个标题 (0.8%)。
- 人工审查结果:
- 真实缺陷:35个(其中失真15,削波9,噪声7,其他4)。
- 创意意图:92个(其中环境音37,雨声27,嗡嗡声9,声道效果7,其他12)。
- 误报:8个。
- 关键结论:
- 精确率:对于真实缺陷,精确率为35/135 ≈ 25.9%。若将创意意图也视为正确检测,精确率高达 (35+92)/135 ≈ 94.1%。
- 核心挑战:68.1% (92/135) 的“问题”实为创意意图,这是模型的主要瓶颈。例如,雨声(创意)与底噪(缺陷)声学特征相似。
- 实际效用:0.8%的低标记率使得人工审查负担可控。
⚖️ 评分理由
学术质量:5.5/7
- 创新性(2/3):架构整合了现有技术(AST预训练、对比学习、SVM),针对特定问题进行了有效的工程化适配。软分配对比损失和详细合成数据流程是其有亮点的工程创新,但非基础理论或算法突破。
- 技术正确性(2/2):方法描述清晰,技术路线合理,实验设置(消融、生产验证)符合逻辑。
- 实验充分性(1/2):有离线和生产环境两种评估,且进行了消融研究。但离线测试集规模过小(仅10个缺陷视频),且未能全面覆盖所有七种缺陷;生产评估无法计算召回率。
选题价值:1.5/2
- 前沿性与应用空间(1.5/2):解决工业界真实存在的痛点,具有明确的应用场景和落地价值(已部署)。选题在工业界是前沿的,但在学术界属于垂直应用研究。
开源与复现加成:0.0/1
- 论文未提供代码、模型权重、数据集链接或详细的复现指南。虽然描述了合成数据的参数,但可复现性仍然不足。因此不给予加成。