📄 Optimizing Speech Language Models for Acoustic Consistency
#语音合成 #语音大模型 #自监督学习 #鲁棒性 #模型评估
🔥 8.0/10 | 前25% | #语音合成 | #自监督学习 | #语音大模型 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未明确说明,但根据论文署名顺序和邮箱格式,Morteza Rohanian可能是第一作者。其机构为:苏黎世大学(University of Zurich)、ETH AI Center。
- 通讯作者:未明确说明。两位作者的邮箱后缀均为
@uzh.ch,可能共同负责。 - 作者列表:Morteza Rohanian(苏黎世大学、ETH AI Center)、Michael Krauthammer(苏黎世大学、ETH AI Center)。
💡 毒舌点评
这篇论文的亮点在于其“纯粹”的实验哲学:通过精心设计的语言模型训练策略(语义初始化、一致性增强、辅助损失)来解决声学一致性问题,而完全不依赖更复杂的模型架构或编码器改动,这为研究语音LM的内在能力提供了干净的对比视角。短板在于,虽然证明了“更小但更专注”的模型在一致性上能打败“更大但更泛化”的模型,但对于“语义-声学对齐”这一同样关键的能力,其交错训练方案带来的提升幅度有限(与人类仍有明显差距),论文对此的深入分析和改进方案略显不足。
🔗 开源详情
- 代码:论文中未提及代码链接。文末提供了Demo和模型权重的外部链接,但未明确说明训练代码是否开源。
- 模型权重:是。论文明确提供了Hugging Face模型卡片链接:
https://huggingface.co/KrauthammerLab/cast-0.7b-s2s。 - 数据集:论文使用了公开数据集LibriLight和People’s Speech,但未提供额外的数据处理或增强脚本。
- Demo:是。论文提供了在线演示链接:
https://mortezaro.github.io/speech-cast/。 - 复现材料:论文给出了一些训练超参数(学习率、batch size等),但未提供完整的训练配置、检查点或详细的复现说明。
- 论文中引用的开源项目:引用了WavTokenizer(分词器)、HuBERT(SSL编码器)、Gemma(语言模型骨干)等相关工作。
📌 核心摘要
- 解决什么问题:针对语音语言模型在生成语音时,难以保持说话人身份、性别、情感、背景环境等声学属性跨时间一致性的挑战。
- 方法核心:提出CAST方法,在不修改冻结的语音编解码器和模型推理路径的前提下,仅在语言模型侧进行适配。主要包括:使用自监督模型(HuBERT)的聚类中心初始化语音token嵌入,并加入对齐损失;训练时采用多速率稀疏化(Thinning)和跨段擦除(Span Erasure)增强鲁棒性;引入延迟的粗粒度(Coarse)和细粒度(Next-Code)辅助损失,引导模型先规划宏观结构再预测细节。
- 新在哪里:相比之前引入多阶段解码器、适配器或监督头的复杂架构改进,CAST将优化焦点严格限定在语言模型的嵌入空间和训练目标上,使得模型对声学一致性的贡献更容易被隔离和分析。同时,论文系统研究了“纯语音训练”与“文本-语音交错训练”对模型能力的不同影响,揭示了声学稳定性与语义基础之间存在的可控权衡。
- 主要实验结果:0.7B参数的纯语音模型在SALMON声学一致性基准上表现最佳(例如,说话人一致性90.8%),超越了参数量达7B的基线模型(如SpiritLM 81.0%)。交错训练虽然降低了声学一致性,但提升了语义(sWUGGY从65.6%提升至73.7%)和语义-声学对齐能力。消融实验证明辅助损失对维持说话人/性别等身份一致性至关重要。
- 实际意义:证明了通过巧妙的语言模型训练设计,可以在保持架构简单和推理高效的同时,显著提升语音生成的鲁棒性和一致性,为部署更可靠的语音交互应用(如对话、旁白生成)提供了技术路径。
- 主要局限性:研究局限于英语朗读/对话数据,在更复杂、噪声更大或涉及跨语言场景下的泛化能力未被验证。此外,尽管证明了权衡的存在,但尚未找到一种能同时大幅提升声学一致性和语义-声学对齐的方法。
🏗️ 模型架构
CAST方法的核心架构是一个解码器专用Transformer,它在原始文本LLM(如Gemma 3 1B)的基础上,扩展了语音token的词表,形成统一的文本-语音词汇空间。
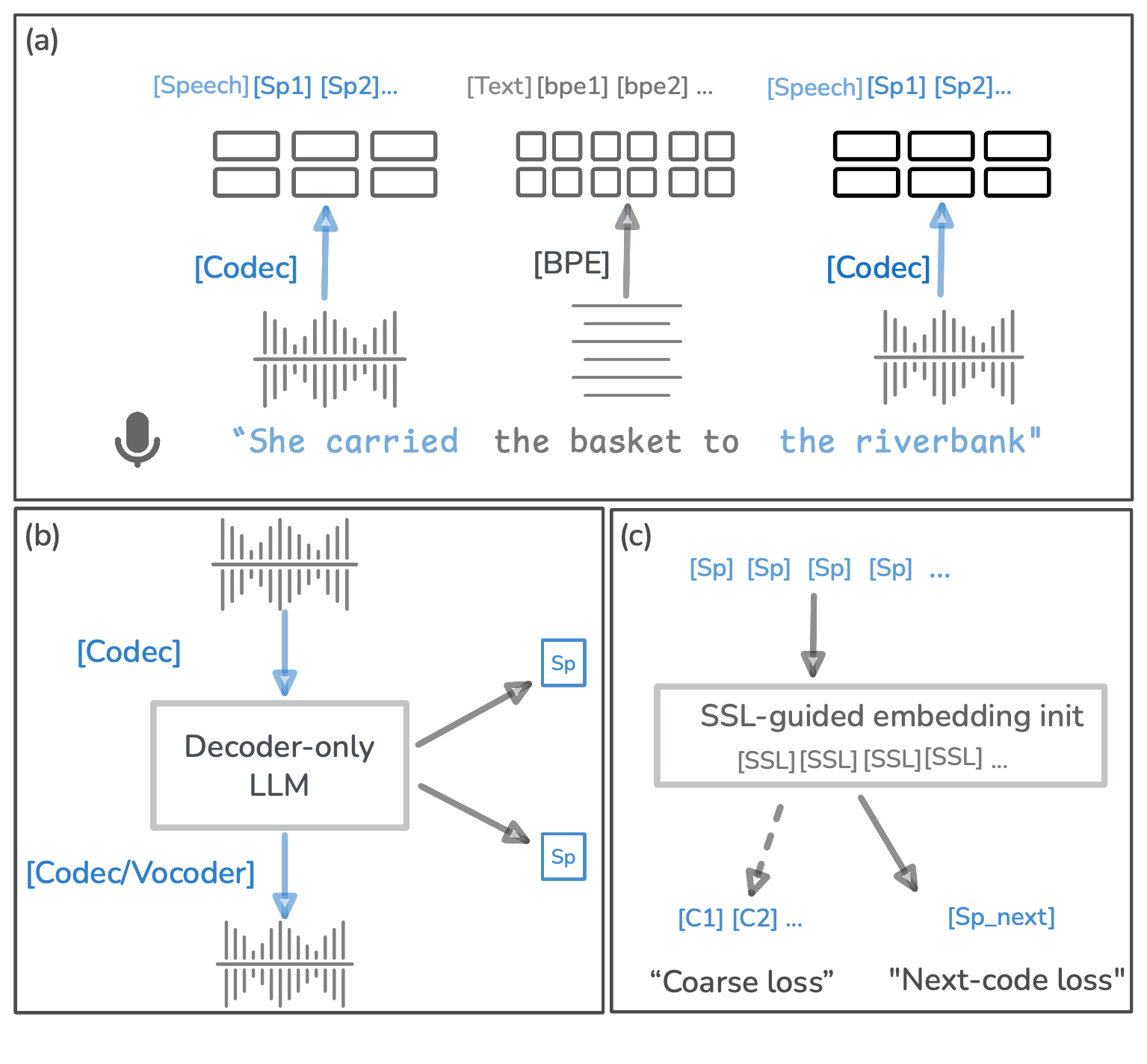 图1说明:该图展示了CAST的整体设计。(a) 语音(通过Codec)和文本(通过BPE)被分词并交错排列。(b) 解码器Transformer在统一序列上预测下一个token。(c) 通过SSL初始化的语音token嵌入,结合粗粒度和下一个Code的辅助目标,来改进语音建模。
图1说明:该图展示了CAST的整体设计。(a) 语音(通过Codec)和文本(通过BPE)被分词并交错排列。(b) 解码器Transformer在统一序列上预测下一个token。(c) 通过SSL初始化的语音token嵌入,结合粗粒度和下一个Code的辅助目标,来改进语音建模。
完整输入输出流程与组件交互:
- 输入:一段语音音频(采样率24kHz)。
- 语音编码:使用冻结的神经音频编解码器(WavTokenizer)将连续语音波形离散化为一系列整数索引(码本大小4096)。每个索引对应一个声学单元。
- 分词:将得到的语音token序列送入扩展后的LM分词器。同时,根据需要,可以插入文本token(通过BPE分词),形成交错序列。
- 语言模型处理:Transformer解码器接收整个token序列(包含文本和语音标记),并基于自回归方式预测下一个token的概率分布。
- 输出:在生成时,通过掩码仅从语音token集合
{[Sp*], </s>}中采样,得到输出的语音token序列。 - 语音解码:将输出的语音token序列送入冻结的WavTokenizer解码器,重建为连续的语音波形。
关键设计选择与动机:
- 冻结Codec:将声学编码视为固定的前端,所有适应工作在LM侧完成,简化系统并清晰隔离研究变量。
- 统一词汇表:使LM能够无缝处理文本和语音,支持交错训练。
- 语义蒸馏初始化:用HuBERT的聚类中心(包含丰富音素信息)初始化语音token的嵌入,避免LM从头学习语音的底层表示,使其更专注于序列建模。
💡 核心创新点
- LM侧的语义蒸馏与对齐:使用冻结的自监督语音模型(HuBERT)的聚类中心初始化语音token嵌入,并在训练中添加停止梯度的对齐损失(
Lssl)。这解决了神经编解码器码本优化目标(重建)与下游任务(理解/生成)需求不匹配的问题,为LM提供了良好的声学-语义起点。 - 一致性训练策略:引入多速率稀疏化(随机降低采样率)和跨段擦除(随机删除连续token)作为数据增强。这迫使模型在输入存在时序抖动和上下文缺失时,仍能做出一致的预测,从而增强了对声学不变性的学习。
- 延迟粗-细粒度辅助损失:设计辅助损失引导模型先预测语音的粗粒度属性(如从聚类得到的类别
bt),再预测细粒度的下一个声学单元(yt)。这模仿了人类语言规划过程(先想好大意再说具体词汇),从而提升了生成语音在宏观结构(如说话人身份)上的连贯性。 - 揭示稳定性-基础性权衡:通过对比纯语音模型和文本-语音交错模型,系统地量化并证实了语音LM中“声学一致性”与“语义-声学对齐/语义能力”之间存在一种固有的、可通过训练混合比例调节的权衡。这是对语音LM训练动态的重要洞察。
🔬 细节详述
- 训练数据:使用LibriLight英文数据集(约57k小时有声书)和People’s Speech子集(约20k小时对话/广播),总计约77k小时。数据为相对干净的英语语音。
- 损失函数:
- 主损失:标准的自回归交叉熵损失,预测序列中的下一个token(文本或语音)。
- 对齐损失(
Lssl):在语音token位置,计算LM隐藏状态ht与经过线性映射的HuBERT特征P(SSLt)之间的L2范数损失,并应用停止梯度(stop-gradient)以防止影响LLM训练。 - 粗粒度辅助损失(
Lcoarse):预测语音token的粗粒度类别bt(由HuBERT质心聚类得到)。 - 细粒度辅助损失(
Lnext):标准的下一个Code预测损失(已包含在主损失中,但论文将其作为辅助目标强调)。
- 训练策略:
- 模型规模:基于Gemma 3 1B Transformer骨干。训练了三种变体:CAST 0.7B(纯语音,词表56k文本+4096语音),CAST 1.0B(纯语音,词表262k文本+4096语音),CAST 1.0B(交错,完整文本词表+语音词表)。
- 优化:学习率
3.0 × 10^{-5},有效batch size每设备16,使用bfloat16精度。优化器设置未详细说明。 - 交错训练:文本和语音片段按时间顺序交错,文本占时长35-55%,随机插入。
- 关键超参数:语音Codec码本大小4096,采样率24kHz。稀疏化采样率
r ∈ {1,2,3,4},擦除概率perase(值未说明)。粗粒度聚类桶数K(值未说明)。 - 训练硬件:未说明。
- 推理细节:生成时,logits掩码为语音token集合
{[Sp*], </s>},使用冻结的WavTokenizer解码。评估时,输入重采样至24kHz,使用长度归一化的负对数似然作为评分。 - 正则化:稀疏化和擦除操作本身可视为一种强数据增强,起到正则化作用,防止模型过拟合到特定的时间对齐模式。
📊 实验结果
- 声学一致性与对齐性能(SALMON基准)
| 方法 | 情感一致性↑ | 说话人性别一致性↑ | 性别一致性↑ | 背景一致性(域内)↑ | 背景一致性(随机)↑ | 房间一致性↑ | 情感对齐↑ | 背景对齐↑ |
|---|---|---|---|---|---|---|---|---|
| CAST 0.7B (纯语音) | 81.8 | 90.8 | 90.0 | 80.0 | 77.5 | 90.0 | 51.0 | 56.0 |
| CAST 1B (纯语音) | 81.8 | 90.0 | 90.0 | 78.0 | 68.5 | 91.0 | 48.5 | 51.5 |
| CAST 1B (交错) | 73.0 | 83.5 | 83.5 | 75.0 | 71.5 | 84.5 | 54.5 | 58.0 |
| SpiritLM 7B | 73.5 | 81.0 | 85.0 | 55.0 | 64.0 | 55.5 | 52.0 | 59.5 |
| Twist 7B | 61.5 | 71.0 | 70.0 | 55.0 | 60.5 | 62.0 | 51.5 | 54.5 |
| 人类 | 97.2 | 91.5 | 98.6 | 83.1 | 88.7 | 94.4 | 93.3 | 95.8 |
关键结论:纯语音的0.7B模型在声学一致性(说话人、性别等)上取得最高分,超越了参数量大得多的基线。交错训练在所有一致性指标上下降,但在对齐指标上提升。
- 语义能力(sWUGGY与sBLiMP)
| 方法 | sWUGGY | sBLiMP |
|---|---|---|
| CAST 0.7B (纯语音) | 65.6 | 55.9 |
| CAST 1B (纯语音) | 67.0 | 57.2 |
| CAST 1B (交错) | 73.7 | 58.3 |
| SpiritLM 7B | 75.5 | 58.3 |
| Twist 7B | 82.8 | 56.2 |
| Flow-SLM 1B | 73.2 | 60.0 |
关键结论:交错训练显著提升了语音模型的词汇知识(sWUGGY),但对句法知识(sBLiMP)提升有限。
- 线性探针分类准确率(验证语义蒸馏初始化效果)
| 变体 | 阶段 | ESC-50 | US8K | VIVAE | RAVDESS | SLURP | EMOVO |
|---|---|---|---|---|---|---|---|
| 原始基线 | 100% | 26.5 | 40.2 | 30.0 | 33.1 | 8.0 | 31.2 |
| 语义蒸馏 | 10% | 27.9 | 40.8 | 27.7 | 33.5 | 7.9 | 29.8 |
| 40% | 30.6 | 43.1 | 26.5 | 34.8 | 8.1 | 29.3 | |
| 100% | 32.6 | 45.9 | 27.5 | 38.9 | 8.1 | 29.3 |
关键结论:语义蒸馏初始化在环境声音(ESC-50, US8K)和混合情感(RAVDESS)等任务上,能更快达到更高准确率,但对纯粹的韵律/情感任务(VIVAE, EMOVO)略有负面影响,证实了初始化策略偏向内容结构。
- 辅助损失消融实验
| 方法 | 情感 | 说话人 | 性别 | 背景(域内) | 背景(随机) | 房间 |
|---|---|---|---|---|---|---|
| CAST 0.7B (+Aux) | 81.8 | 90.8 | 90.0 | 80.0 | 77.5 | 90.0 |
| CAST 0.7B (-Aux) | 75.5 | 83.5 | 83.0 | 76.0 | 71.0 | 89.5 |
| CAST 1B (+Aux) | 81.8 | 90.0 | 90.0 | 78.0 | 68.5 | 91.0 |
| CAST 1B (-Aux) | 75.0 | 83.0 | 82.0 | 75.0 | 71.0 | 90.0 |
关键结论:移除辅助损失导致声学一致性,尤其是身份相关指标(说话人、性别)显著下降,证明了辅助规划损失的重要性。
⚖️ 评分理由
- 学术质量(6.0/7):论文在明确的问题定义下,提出了一个系统、自洽且有效的技术方案(CAST)。实验设计全面,不仅评估了最终性能,还通过线性探针和消融实验深入分析了各组件的作用和模型的内部表征,证据链较为完整。创新点清晰,且结果(小模型超越大模型)具有启发性。未给满分是因为在跨更多数据集、更多语言的泛化验证以及与其他前沿方法的直接、全面的对比分析上还有提升空间。
- 选题价值(1.5/2):语音生成的鲁棒性与一致性是产业落地的关键瓶颈,具有高实用价值。本研究提出的“LM侧优化”思路,为在资源受限或需要保持架构简洁的场景下提升语音模型性能提供了可行方案。但相较于探索全新的生成范式(如扩散、流匹配)或超大规模多模态模型,本课题的影响力范围相对聚焦。
- 开源与复现加成(0.5/1):论文提供了模型权重和在线Demo的直接链接,极大方便了结果验证和应用探索,这是一个显著的加分点。但复现所需的关键要素——训练代码、详细的配置文件、数据处理脚本——均未提及,因此只能给予部分分数。