📄 On The Design of Efficient Neural Methods for Geometry-Agnostic Multichannel Speech Enhancement
#语音增强 #波束成形 #麦克风阵列 #实时处理
✅ 6.5/10 | 前50% | #语音增强 | #波束成形 | #麦克风阵列 #实时处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Dongzhe Zhang(意大利米兰理工大学 Dipartimento di Elettronica, Informazione e Bioingegneria)
- 通讯作者:未说明
- 作者列表:Dongzhe Zhang(意大利米兰理工大学)、Jianfeng Chen(中国西北工业大学 海洋科学与技术学院)、Mou Wang(中国科学院 声学研究所)、Alessandro Ilic Mezza(意大利米兰理工大学)、Alberto Bernardini(意大利米兰理工大学)
💡 毒舌点评
亮点: 论文最大的价值在于为基于空间滤波器组(SFB)的几何无关语音增强系统,从理论上解决了“滤波器通道数I该设为多少”这个一直靠拍脑袋决定的关键超参数问题,并提出了简洁有效的计算准则,这对工程实践有切实指导意义。 短板: 创新性有限,主要贡献在于对已有框架(SFB)的参数优化和后端网络的“降级”替换(用LSTM替代Attention),属于系统效率优化范畴,而非提出新的信号处理原理或学习范式。此外,论文未开源代码、模型和完整训练细节,大大削弱了其可复现性和实际影响力。
🔗 开源详情
- 代码: 论文中未提及代码链接。
- 模型权重: 未提及。
- 数据集: 使用了公开的LibriSpeech和Nonspeech7k数据集,但模拟生成数据的具体脚本未提供。
- Demo: 未提及。
- 复现材料: 论文中给出了部分训练配置(如STFT参数、数据切分长度、随机阵列设置),但缺少损失函数、优化器、学习率、batch size等关键训练细节。
- 论文中引用的开源项目: 引用了gpuRIR库用于模拟房间冲激响应,以及TorchMetrics库用于计算PESQ和STOI。
📌 核心摘要
- 问题: 当前深度学习驱动的多通道语音增强方法严重依赖于特定的麦克风阵列几何结构,导致硬件泛化能力差。虽然几何无关方法(如SFB)出现,但其核心参数——SFB的通道数I——一直依赖经验选择,往往设置过高,导致特征冗余和计算开销巨大。
- 方法核心: 本文提出了一个理论框架来确定任意波束方向图下的最优SFB通道数I,该框架基于确保空间无缝覆盖并最小化信息冗余的原则(公式6)。同时,作者将基线模型(SFB-TSCBM)中计算量大的多头自注意力(MHSA)层替换为更高效的LSTM网络,构建了新的SFB-LSTM架构。
- 新意: 新意在于两点:一是为SFB通道数设计提供了有理论依据的通用启发式原则(见表1);二是证明了在优化前端通道数后,一个相对简单的LSTM后端就能达到甚至超越复杂注意力模型的性能,同时计算量显著降低。
- 主要实验结果: 实验在随机生成的阵列几何、房间声学和噪声条件下进行。核心结果见下表:
模型 参数量(M) GFLOPS 二阶超心形PESQ 一阶超心形PESQ SFB-TSCBM (I=9) 0.50 21.99 2.03 1.97 SFB-TSCBM (I=3) 0.50 21.94 2.06 1.99 SFB-LSTM (I=9) 0.48 16.48 2.09 2.01 SFB-LSTM (I=3) 0.48 16.36 2.08 2.01 固定波束成形(需DOA) – – 1.87 1.80 未处理(含噪) – – 1.62 1.62 关键结论: SFB-LSTM (I=3) 在几乎所有指标上都略优于或持平于SFB-TSCBM (I=9),同时GFLOPS降低了约25.4%。将I从9降至3对性能几乎无损,验证了理论预测。 - 实际意义: 为在资源受限设备(如助听器、智能音箱)上部署高性能、适配任意阵列的语音增强模型提供了更清晰的设计路径,降低了算法与硬件的耦合度。
- 主要局限性: 论文没有公开代码、模型权重和完整的训练配置,复现难度较大。所提方法属于系统级优化,其核心理论贡献(公式6)的普适性和在更复杂场景(如强混响、高相关噪声)下的鲁棒性有待更多验证。
🏗️ 模型架构
本文提出的SFB-LSTM框架是一个端到端的多通道语音增强系统,其整体架构(如图2所示)可分为三个核心模块:SFB前端、增强网络(编码器与增强网络)和解码器。
输入与SFB前端:
- 输入: 任意M个麦克风采集的时域信号,经过STFT变换到频域。
- SFB操作: 通过公式(4)的滤波器组矩阵H(ω)对M个麦克风信号进行线性组合,将其投影到I维的几何无关信道空间。这一步将几何依赖的M维信号转换为标准化的I维特征,是“几何无关”设计的关键。I的取值由本文提出的理论准则(公式6)确定。
增强网络(编码器与增强网络):
- 编码器: 首先计算SFB输出的复数表示(Complex as Channels, CaC),将实部和虚部作为两个独立的通道。接着通过一个点卷积层将通道数扩展到64。随后,数据流被重塑并分别送入两个并行的DenseNet块(DenseNet (d=1) 处理时频图的一个维度,DenseNet (d=2) 处理另一个维度),进行特征提取和初步建模。
- 增强网络(时序建模): 核心是两个LSTM块。第一个LSTM块接收来自编码器的特征,专注于建模长程时间依赖。第二个LSTM块则对前一个块的输出进行转置,专注于建模频率间的依赖。每个LSTM块内部包含FFN、LSTM层、2D卷积层以及跳跃连接,结构高效。
解码器:
- 增强网络的输出被整合后,送入解码器。解码器通过一系列转置卷积(上采样卷积)操作,将低分辨率、高通道数的特征图逐步恢复到原始的STFT分辨率,最终输出对应增强语音实部和虚部的二维特征图。最后通过iSTFT变换回时域,得到增强后的语音信号。
数据流示例(参照图2):
任意麦克风阵列信号 → STFT → SFB (M维→I维) → CaC表示 → 点卷积(扩展至64通道) → DenseNet块(特征提取) → LSTM块(时序建模) → LSTM块(频率建模) → 解码器(上采样重建) → iSTFT → 增强语音
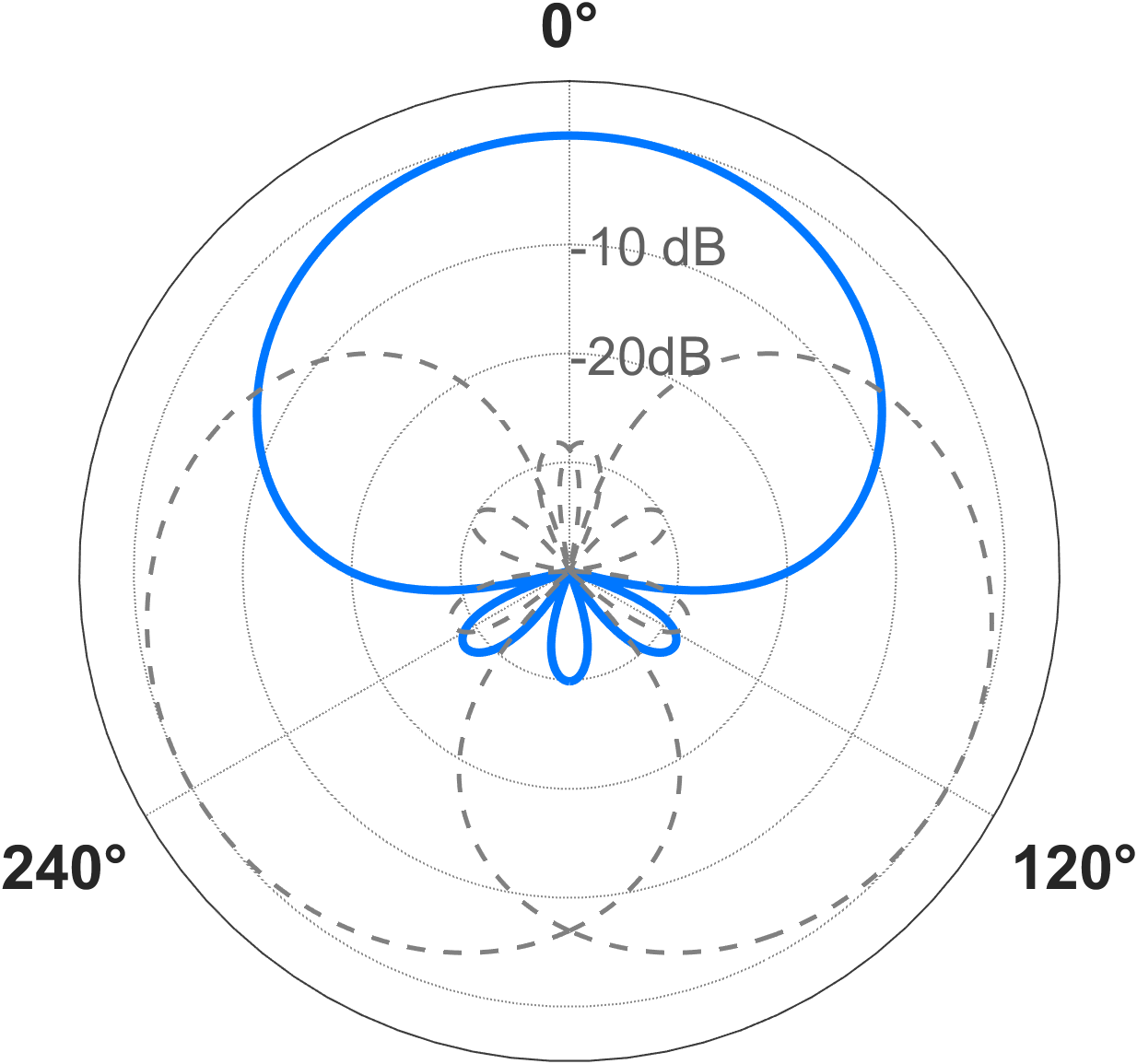 图2:SFB-LSTM框架示意图,清晰地展示了从任意麦克风阵列输入到增强语音输出的完整数据流,包括SFB前端、编码器、增强网络(含LSTM)和解码器各组件及其连接关系。
图2:SFB-LSTM框架示意图,清晰地展示了从任意麦克风阵列输入到增强语音输出的完整数据流,包括SFB前端、编码器、增强网络(含LSTM)和解码器各组件及其连接关系。
💡 核心创新点
- SFB通道数的理论设计准则: 本文首次为几何无关SFB前端中的通道数I建立了一个通用的理论框架。该准则(公式6)利用波束方向图的3dB和6dB波束宽度,计算出能保证空间无缝覆盖且信息冗余最小的I值范围。之前局限: I值通常凭经验设置为较大的固定值(如9),造成特征冗余。如何起作用: 通过分析波束特性,为不同阶数的微分麦克风阵列(如心形、超心形等)提供了最优I值的理论计算(见表1)。收益: 消除了设计不确定性,指导前端设计更精简高效,实验验证了将I设为3即可达到与I=9相当的性能。
- 用高效LSTM替代计算昂贵的自注意力机制: 在已优化前端(I值较小)的前提下,证明了后端模型无需使用计算复杂的MHSA(如Conformer)。用LSTM构建的SFB-LSTM模型在性能上匹配甚至略优于基于Conformer的SFB-TSCBM基线。之前局限: SOTA模型(SFB-TSCBM)采用计算量大的注意力机制。如何起作用: LSTM在序列建模上计算更高效,且在优化后的低维特征上能有效工作。收益: 计算复杂度(GFLOPS)降低超过25%,同时参数量也略有减少,更适合边缘部署。
- 构建并验证高效的SFB-LSTM端到端框架: 将上述两点结合,提出了一个从信号处理前端到神经网络后端均经过效率优化的完整系统。该系统保持了强大的性能(优于基线和固定波束成形),同时计算成本显著降低,且适用于多种波束类型(二阶超心形、一阶超心形)。证据: 表2中SFB-LSTM (I=3) 在多个客观指标(PESQ, STOI, CSIG等)上全面优于或持平于SFB-TSCBM (I=9),同时GFLOPS从21.99降至16.36。
🔬 细节详述
- 训练数据:
- 来源: 语音来自LibriSpeech,噪声来自Nonspeech7k。
- 模拟: 通过gpuRIR库模拟房间冲激响应(RIR)。房间尺寸随机(3×3×2.5m 至 7×9×3m),混响时间T60在0.2-0.4s之间。信噪比(SNR)随机在-5dB到+5dB之间。
- 阵列设置: 麦克风数量M随机选择6到10个,在1.5cm半径的圆内随机布置,以测试几何无关性。
- 数据切分: 训练使用2秒片段,评估使用完整语音。
- 损失函数: 论文中未明确说明。
- 训练策略:
- 优化器、学习率、调度等: 论文中未详细说明。
- 硬件与时间: 论文中未说明。
- 关键超参数:
- SFB参数: 核心超参数为通道数I。实验主要比较了I=9(基线)和I=3(优化)两种设置。波束方向均匀分布。
- 网络参数: SFB-LSTM模型参数量为0.48M。增强网络中LSTM的隐藏层大小等未说明。
- 推理细节: 未提及特殊解码策略,直接输出增强的STFT。
- 正则化技巧: 未说明。
📊 实验结果
主要对比实验(Table 2): 论文在完全随机的阵列几何下评估了多个模型。核心对比如下表所示:
| 模型 | 参数量(M) | GFLOPS | 二阶超心形SFB | 一阶超心形SFB | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PESQ | STOI | CSIG | COVL | PESQ | STOI | CSIG | COVL | |||
| 未处理(含噪) | – | – | 1.62 | 0.835 | 2.65 | 2.11 | 1.62 | 0.835 | 2.65 | 2.11 |
| 固定波束成形(需DOA) | – | – | 1.87 | 0.862 | 3.42 | 2.56 | 1.80 | 0.853 | 3.39 | 2.47 |
| FasNet-TAC | 2.76 | 43.12 | 1.90 | 0.873 | 3.47 | 2.65 | 1.90 | 0.873 | 3.47 | 2.65 |
| SFB-TSCBM (I=9) | 0.50 | 21.99 | 2.03 | 0.889 | 3.60 | 2.79 | 1.97 | 0.880 | 3.41 | 2.70 |
| SFB-LSTM (I=3) | 0.48 | 16.36 | 2.08 | 0.890 | 3.64 | 2.81 | 2.01 | 0.880 | 3.45 | 2.72 |
关键结论:
- 通道数优化验证(Fig. 3): 对于两种波束,性能(PESQ/STOI)在I=1到I=3时显著提升,在I=3之后趋于饱和。这验证了理论准则:I=3已能提供完整且冗余低的空间覆盖。
- SFB-LSTM vs. SFB-TSCBM: SFB-LSTM (I=3) 在PESQ、STOI、CSIG、COVL等关键指标上,全面持平或略优于更复杂的SFB-TSCBM (I=9),同时计算成本(GFLOPS)降低约25.4%。
- 多通道优势: 与使用理想DOA信息的单通道固定波束成形+SFB-LSTM (I=1, w/ DOA) 相比,使用3个通道(I=3)的SFB-LSTM性能更好(PESQ 2.08 vs. 1.99),证明了多个非目标方向波束能提供有用的上下文信息,帮助网络更好地抑制噪声和混响。
- 波束类型影响: 所有模型在一阶超心形波束下的性能普遍略低于二阶超心形波束。论文指出这源于更低阶波束本身更低的指向性指数和更大的后瓣。
 图3:SFB-TSCBM模型的PESQ和STOI指标随SFB通道数I的变化曲线。实线为二阶超心形,虚线为一阶超心形。清晰地显示了性能在I=3左右达到饱和的现象。
图3:SFB-TSCBM模型的PESQ和STOI指标随SFB通道数I的变化曲线。实线为二阶超心形,虚线为一阶超心形。清晰地显示了性能在I=3左右达到饱和的现象。
⚖️ 评分理由
- 学术质量:5.5/7 论文在解决一个具体的工程问题(SFB通道数选择)上展现了清晰的逻辑和扎实的实验验证,提出了一个有启发性且实用的理论准则。技术路线正确,实验设计合理,结论可信。扣分点在于创新性相对有限,属于对现有框架(SFB+神经网络)的优化和效率提升,而非开辟新方向。
- 选题价值:1.5/2 多通道语音增强的几何无关性是实际部署中的重要挑战,本文关注的效率问题(降低计算量)对边缘设备部署有直接意义。选题具有明确的应用价值和一定的时效性。但方向不算最前沿,且更偏系统优化。
- 开源与复现加成:-0.5/1 论文未提供代码、模型权重、训练配置(损失函数、优化器、超参数)等关键复现信息。这严重限制了研究的可验证性和后续工作的开展。论文中引用的开源项目(如gpuRIR)是数据生成工具,而非本文方法的代码。