📄 Obstructive Sleep Apnea Endotype Prediction During Wakefulness Using Voice Biomarkers
#语音生物标志物 #多任务学习 #自编码器 #特征选择 #医疗健康
✅ 6.5/10 | 前50% | #语音生物标志物 | #多任务学习 | #自编码器 #特征选择
学术质量 5.5/7 | 选题价值 2.0/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Shiva Akbari(多伦多大学生物医学工程研究所、KITE研究所)
- 通讯作者:未说明
- 作者列表:Shiva Akbari(多伦多大学生物医学工程研究所、KITE研究所)、Behrad Taghibeyglou(多伦多大学生物医学工程研究所、KITE研究所)、Atousa Assadi(多伦多大学生物医学工程研究所、KITE研究所)、Dominick Madulid(麦克马斯特大学)、Devin Brown(密歇根大学神经学系)、Daniel Vena(哈佛医学院布莱根妇女医院睡眠与昼夜节律疾病科)、Scott Sands(哈佛医学院布莱根妇女医院睡眠与昼夜节律疾病科)、Azadeh Yadollahi(多伦多大学生物医学工程研究所、KITE研究所)
💡 毒舌点评
亮点:首次尝试从清醒期语音直接预测OSA的核心生理内型(气道塌陷性和肌肉补偿性),这个思路跳出了传统睡眠监测的框架,为低成本个性化诊断开辟了极具想象力的道路。短板:仅靠45人的小样本就得出强相关性结论,且缺乏外部验证集和与更强大基线的对比,这份“可行性”的证据链显得有些脆弱,离临床应用还有很长的路要走。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未提及是否公开及获取方式。
- Demo:未提及。
- 复现材料:未提供详细的训练配置、超参数搜索过程或检查点。
- 论文中引用的开源项目:提及使用了Librosa(用于声学特征提取)、Parselmouth(用于语音特征提取)、PUPbeta toolkit(用于从PSG数据提取内型金标准)等开源工具。
- 总体:论文中未提及开源计划。
📌 核心摘要
这篇论文旨在解决阻塞性睡眠呼吸暂停(OSA)个性化治疗中的一个关键瓶颈:如何非侵入性地确定其潜在病理生理内型(如气道塌陷性、肌肉补偿能力)。现有方法依赖昂贵且侵入性的多导睡眠监测(PSG)或食道压测定。论文提出了一种全新的机器学习框架,在患者清醒状态下,利用其持续元音发声的声学特征来预测这些内型。其核心方法是:首先,利用一个同时优化特征重构和内型预测任务的监督自编码器,将高维声学特征压缩至32维潜在表示;然后,通过互信息最大化进一步筛选出最相关的20个特征;最后,将这些特征输入一个采用Swish激活、批量归一化和Dropout的改进型多层感知机(MLP)进行回归预测。与传统机器学习方法相比,该方法的创新点在于整合了监督表征学习、特征选择和深度回归模型,以应对小样本和高维数据的挑战。主要实验结果表明,该框架在45名参与者的数据集上,预测气道塌陷性(r=0.8)和肌肉补偿性(r=0.83)与金标准测量值表现出高相关性,且MAE较低(见下表)。这证明了语音生物标志物作为非侵入性、可扩展的OSA内型预测工具的潜力。然而,该研究的主要局限性包括:样本量较小(n=45)可能限制泛化能力;仅聚焦于两个与发声结构最相关的内型;未在独立数据集上进行外部验证。
主要实验结果对比(表2):
| 模型 | 气道塌陷性(r) | 气道塌陷性(MAE) | 肌肉补偿性(r) | 肌肉补偿性(MAE) |
|---|---|---|---|---|
| Ridge Regression | 0.52 | 5.63 | 0.63 | 10.04 |
| Random Forest | 0.67 | 4.06 | 0.71 | 8.32 |
| Single-layer MLP | 0.57 | 4.93 | 0.25 | 41.09 |
| Proposed Approach | 0.80 | 2.6 | 0.83 | 4.32 |
🏗️ 模型架构
模型的整体架构(如图1所示)是一个多阶段的端到端处理流程,旨在从原始声学特征中学习并预测生理内型。
 图1:模型概览。该图清晰地展示了从输入到输出的完整流程。
图1:模型概览。该图清晰地展示了从输入到输出的完整流程。
- 输入层:输入是从持续元音和鼻音中提取的、经过归一化和Yeo-Johnson变换的高维声学特征向量(时域、频域、时频域特征)。
- 监督自编码器:这是模型的核心表示学习组件。
- 编码器:将高维输入特征压缩为一个低维(32维)的潜在表示(Latent Representation)。它学习如何提取与内型预测任务最相关的抽象特征。
- 解码器:从潜在表示尝试重构原始输入特征。
- 预测器(MLP头):同时从同一个潜在表示出发,回归预测两个连续的内型值(气道塌陷性和肌肉补偿性)。
- 联合优化:自编码器的训练由两个损失共同驱动:重构损失(确保潜在表示保留原始信息)和预测损失(确保潜在表示对任务有用)。这种双目标学习是其相对于无监督自编码器的关键改进。
- 互信息特征选择:对监督自编码器输出的32维潜在表示,使用互信息方法计算每个维度与目标内型之间的相关性,然后选择Top-20个最相关的维度。这一步进一步去除了冗余和噪声,增强了特征的判别力。
- 预测MLP:最终的预测器是一个三层MLP,结构为128 -> 32 -> 16个神经元,采用逐渐收敛的设计以控制过拟合。使用了Swish激活函数(相比ReLU更平滑)、每个隐藏层后的批量归一化(稳定训练)、以及Dropout正则化(第一层0.3,第二层0.2)。模型使用RMSprop优化器,以MAE为损失函数进行训练。
- 输出层:输出两个连续的预测值,分别对应气道塌陷性和肌肉补偿性的估计。
设计动机:整个架构是针对小样本(45人)、高维声学特征以及非受控录音环境等挑战而设计的。监督自编码器实现了任务导向的降维,特征选择增强了稳健性,而改进的MLP则在小样本下平衡了非线性建模能力和泛化能力。
💡 核心创新点
- 任务创新:首次用语音预测OSA核心内型。之前的研究要么用语音进行OSA筛查/严重程度评估,要么用PSG信号预测内型。本文首次将两者结合,探索从清醒期语音直接预测与治疗选择直接相关的生理内型(气道塌陷性、肌肉补偿性),开辟了新的研究方向。
- 方法创新:监督自编码器与互信息选择的结合。提出将监督自编码器(联合重构与预测)与互信息特征选择相结合的流程。自编码器学习任务相关的低维表示,互信息选择则进一步精炼,这种组合在处理小样本临床数据时,比单独使用其中一种方法可能更鲁棒。
- 应用创新:为无创精准医疗提供新工具。其核心价值在于将一项前沿的机器学习技术应用于解决一个具体的临床痛点,即OSA内型判定的非侵入化、低成本化和普及化,具有明确的转化医学意义。
🔬 细节详述
- 训练数据:数据集来自多伦多睡眠诊所和 shelter 的45名成年参与者。每个人员录制了5个元音(/i, a, u, e, o/)和2个鼻音(/n, m/)的持续发音。使用手持数字录音机在非受控噪声环境下录制(44.1kHz, 16-bit)。所有参与者随后接受了II级便携式PSG,并使用PUPbeta工具包分析得到内型金标准。未说明数据集是否公开及如何获取。
- 损失函数:论文未明确给出总损失函数的数学表达式。但根据描述,监督自编码器的损失是重构损失和预测损失(MAE)的联合。预测MLP的最终训练目标是均绝对误差(MAE),作者指出其对异常值更稳健。
- 训练策略:未详细说明学习率调度、batch size、具体的warmup策略、训练轮数。仅提到使用RMSprop优化器,学习率为0.001。
- 关键超参数:
- 自编码器潜在维度:32。
- 特征选择维度:20。
- 预测MLP结构:[128, 32, 16]。
- Dropout率:第一层0.3,第二层0.2。
- 评估方法:受试者独立K折交叉验证。
- 训练硬件:未说明。
- 推理细节:不适用(回归任务)。
- 正则化或稳定训练技巧:使用了Yeo-Johnson变换稳定方差;监督自编码器的双重目标防止表征退化;互信息特征选择减少过拟合;MLP中的批量归一化和分层Dropout(较大层使用较高dropout率)控制过拟合;采用MAE损失函数。
📊 实验结果
- 主要Benchmark与指标:在自收集的45人数据集上,使用Pearson相关系数(r)和均绝对误差(MAE)评估预测性能。
- 主要结果:
- 总体性能:气道塌陷性(r=0.8, MAE=2.6),肌肉补偿性(r=0.83, MAE=4.32)。
- 按性别细分(见图2):男性(r=0.78/0.91),女性(r=0.81/0.78),表明模型在两个性别中均表现良好。
- 与基线对比:提出的流程在所有指标上均显著优于Ridge回归、随机森林和单层MLP基线(具体数值见上文核心摘要中的表格)。
- 与SOTA差距:论文未直接与领域内其他语音-内型预测方法对比,因为据作者称这是首次该类研究。因此无法计算与SOTA的差距。
- 关键消融实验:论文未提供明确的消融实验(如去掉自编码器、去掉特征选择等)的具体数字结果,仅通过与不同复杂度的基线模型对比来间接验证各组件的贡献。
- 细分结果:如图2所示,按性别分层后性能依然稳健,表明模型学习到的特征与性别无关性较强。
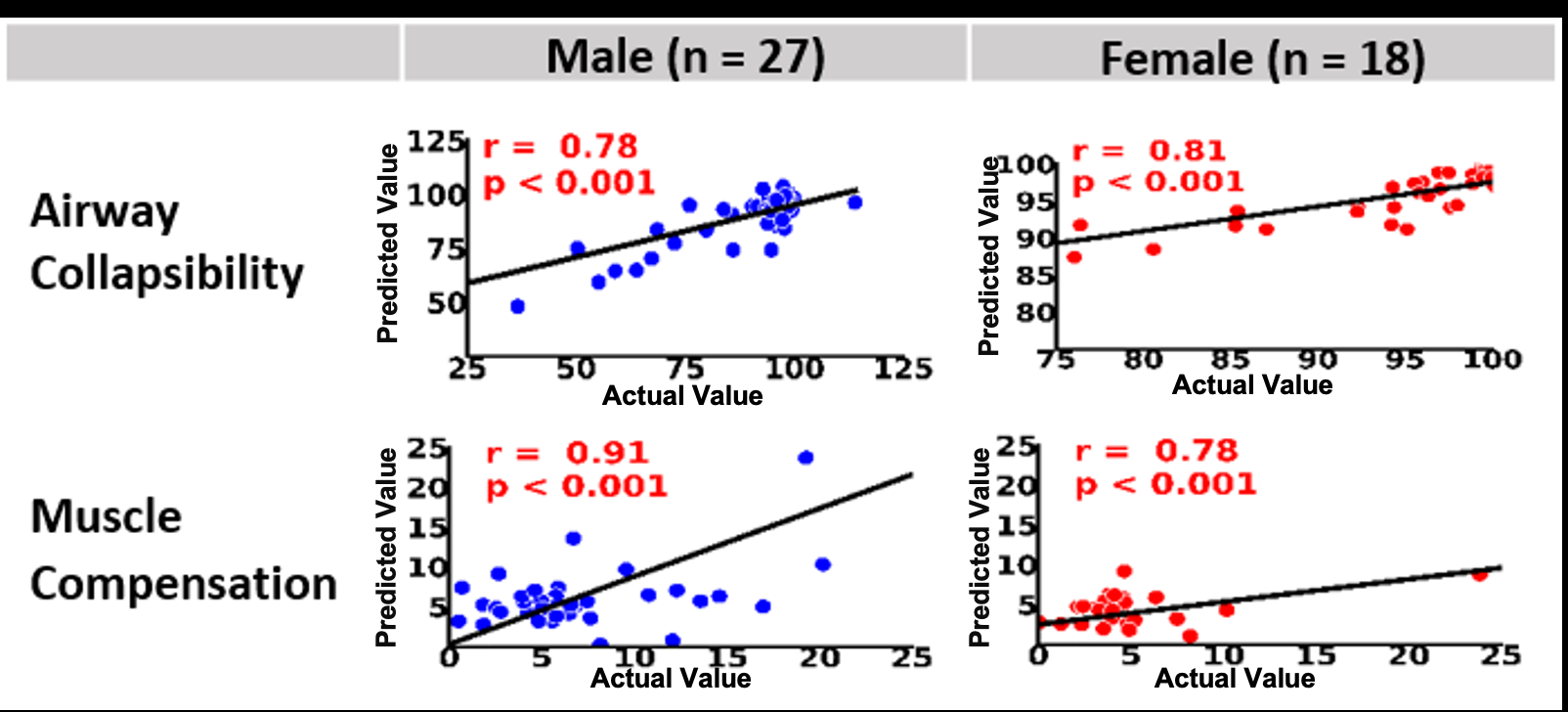 图2:气道塌陷性和肌肉补偿性在男性和女性亚组中的预测值与实际值散点图。图中数据点紧密分布在对角线附近,直观地展示了模型在两个性别亚组中均具有较高的预测准确性,与文本报告的高相关性结论一致。
图2:气道塌陷性和肌肉补偿性在男性和女性亚组中的预测值与实际值散点图。图中数据点紧密分布在对角线附近,直观地展示了模型在两个性别亚组中均具有较高的预测准确性,与文本报告的高相关性结论一致。
- 具体数值表格:已在“核心摘要”部分以Markdown表格形式完整列出表2内容。
⚖️ 评分理由
- 学术质量:5.5/7:创新性方面,提出了首个语音-内型预测框架,具有明确的应用导向,但模型本身是成熟技术的组合。技术正确性较高,方法描述清晰。实验充分性是主要短板:样本量小(n=45),缺乏外部验证,基线模型偏传统,未进行充分的消融研究来验证各组件的必要性。
- 选题价值:2.0/2:选题非常前沿且具有重大的实际应用潜力,有望革新OSA的诊断流程,为患者提供更便捷、低成本的个性化评估方案,与医疗AI和语音分析领域的读者高度相关。
- 开源与复现加成:-0.5/1:论文完全未提供代码、模型、数据或详细的超参数配置表。虽然提到了使用的工具库,但关键的实现细节缺失,使得复现该工作需要较多额外的探索和调试工作。