📄 Noise-Robust Contrastive Learning with an MFCC-Conformer for Coronary Artery Disease Detection
#音频分类 #对比学习 #Conformer #鲁棒性 #医疗AI
✅ 7.0/10 | 前50% | #音频分类 | #对比学习 | #Conformer #鲁棒性
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Milan Marocchi, Matthew Fynn(*表示贡献相等)
- 通讯作者:未说明
- 作者列表:Milan Marocchi(Curtin University),Matthew Fynn(Curtin University),Yue Rong(Curtin University)
- 机构:Curtin University, Bentley 6102, WA, Australia(未说明具体学院或实验室)
💡 毒舌点评
论文的亮点在于将相对复杂的Conformer架构成功应用于心音信号,并设计了一个实用的多通道噪声段拒绝流程,在真实噪声数据集上验证了其有效性。短板是,其噪声拒绝核心算法(能量阈值)的创新性较为有限,且消融实验部分缺失,使得我们难以精确评估各个组件(如对比学习、中心损失、噪声拒绝)的具体贡献。
🔗 开源详情
- 代码:提供了完整的代码仓库链接:
https://github.com/MilanMarocchi/noise-robust-cad-conformer。 - 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:数据集来自特定医院的采集,论文中未提及公开该数据集。
- Demo:未提供在线演示。
- 复现材料:论文提供了详细的超参数配置(表1)、训练策略、硬件环境、评估指标定义等,有利于复现。代码仓库的提供是最大的复现支持。
- 论文中引用的开源项目:提到了使用的开源工具包括PyTorch、Optuna(用于超参优化)、AdamW优化器(参考文献[14])。
📌 核心摘要
- 要解决什么问题:在真实临床噪声环境下,提高基于心音图(PCG)信号的冠状动脉疾病(CAD)检测的鲁棒性和准确性。
- 方法核心是什么:提出一个包含噪声感知预处理和深度学习分类的端到端流程。核心包括:(1) 一种基于能量的多通道噪声段拒绝算法,利用听诊器内置的心声麦克风(HM)和噪声参考麦克风(NM)识别并剔除受非平稳噪声污染严重的信号段;(2) 一个将梅尔频率倒谱系数(MFCC)作为输入的Conformer编码器,并结合监督混合对比学习(包含对比损失、分类损失和中心损失)进行训练。
- 与已有方法相比新在哪里:首次将Conformer模型应用于心音分类任务;提出了一种联合利用HM和NM能量信息的噪声段拒绝方法;在同一个框架内集成了多通道MFCC特征提取、Conformer建模和混合对比学习,以应对真实世界噪声数据。
- 主要实验结果如何:在297名受试者的数据集上,所提出的方法(带噪声拒绝)在受试者级别取得了78.4%的准确率和78.2%的平衡准确率(UAR),相比不进行噪声拒绝的基线模型,准确率和UAR分别提升了4.1%和4.3%。与之前基于Wav2Vec 2.0的方法相比,准确率和UAR分别提升了1.3%和3.9%。具体实验数据如下表所示(仅列受试者级别关键指标):
| 方法 | 准确率 (Acc) | 平衡准确率 (UAR) | 真阳性率 (TPR) | 真阴性率 (TNR) | MCC |
|---|---|---|---|---|---|
| 不带噪声拒绝的MFCC-Conformer | 74.3±0.09% | 73.9±0.10% | 80.9±0.11% | 66.9±0.30% | 0.490±0.019 |
| 本文方法(带噪声拒绝的MFCC-Conformer) | 78.4±0.29% | 78.2±0.32% | 81.9±0.49% | 74.5±0.97% | 0.570±0.058 |
| Noisy Wav2Vec 2.0 [13] | 77.1±1.50% | 74.3±1.73% | 86.5±1.30% | 62.0±2.76% | 0.510±0.035 |
- 实际意义是什么:为在真实世界噪声条件下(如嘈杂的医院环境)进行无创、低成本的CAD预筛查提供了更鲁棒的深度学习解决方案,有助于推动基于可穿戴设备的心脏病早期预警技术。
- 主要局限性是什么:实验仅在一个来源的特定数据集上进行验证;噪声拒绝算法的阈值(2.5倍中值)是固定的,缺乏自适应性讨论;论文未提供充分的消融实验以区分各技术组件(噪声拒绝、Conformer、对比学习等)的独立贡献。
🏗️ 模型架构
论文提出的模型是一个基于Conformer的编码器,用于处理从多通道PCG信号中提取的MFCC特征序列,以实现二分类(CAD vs. 正常)。
完整流程:
- 输入预处理:原始多通道PCG信号经过拼接、噪声段拒绝、去尖峰、带通滤波(25-450Hz)和k峰归一化。
- 特征提取:从处理后的每个通道信号中提取128维MFCC特征(25-450Hz,窗长512,跳长160)。来自同一片段的所有通道的MFCC在时间通道轴上进行拼接,形成一个统一的特征表示。
- 线性投影:拼接后的特征序列(维度 F)通过一个线性层投影到模型内部维度 D=1024。
- Conformer编码器:由 B=3 个堆叠的Conformer块组成。每个Conformer块包含:
- 两个前馈网络子层(FFN),每个FFN内部包含两个线性层和一个Swish激活,并且在进入FFN之前乘以0.5的缩放因子。
- 一个多头自注意力(MHSA)子层,头数 H=8。
- 一个卷积模块,包含点式扩展(使用门控线性单元GLU)、深度可分离卷积(卷积核大小 k=31)、批归一化、SiLU激活和点式投影。
- 每个主要子层(FFN, MHSA, 卷积模块)前后都有层归一化(Pre-LN)和残差连接。在注意力和卷积子层前应用层归一化,在FFN路径中使用Dropout(比率0.2903)。
- 聚合与分类:最后一个Conformer块的输出经过自适应平均池化,得到一个固定长度的嵌入向量。该向量被送入一个浅层MLP分类器(一个隐藏层 + ReLU + Dropout)输出最终的CAD/正常预测概率。
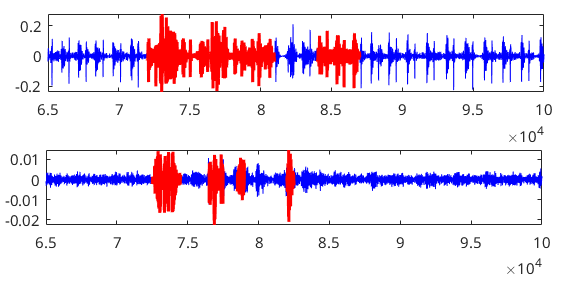 图1:展示了听诊器上的HM(上)和NM(下)信号示例,其中受噪声污染的段落(红色高亮)在所有通道的下游任务中被剔除。这直观说明了噪声段拒绝算法的工作效果。
图1:展示了听诊器上的HM(上)和NM(下)信号示例,其中受噪声污染的段落(红色高亮)在所有通道的下游任务中被剔除。这直观说明了噪声段拒绝算法的工作效果。
关键设计选择及���机:
- 选择Conformer:动机在于其在语音识别任务上(尤其在噪声条件下)展现出的优异性能,结合了Transformer的全局建模能力和CNN的局部特征提取能力,论文假设这同样适用于捕捉心音信号中的时频局部特征和全局依赖关系。
- 多通道MFCC拼接(早期特征融合):与之前使用Wav2Vec 2.0的后期融合不同,本文在特征提取后即进行通道拼接,旨在让模型更早地学习跨通道的交互信息,同时控制模型规模。
- 混合对比学习:动机是通过监督对比损失拉近同类样本嵌入、推远异类样本嵌入,从而学习到更具判别性和噪声鲁棒性的表示空间,这被认为比单纯的交叉熵分类更能利用标签信息塑造嵌入空间。
💡 核心创新点
- 多通道能量噪声段联合拒绝算法:提出了一种新的预处理方法。与仅依赖心声麦克风(HM)的方法不同,该算法创新性地联合使用HM和噪声参考麦克风(NM)的能量信息。通过为HM和NM设置不同的帧长(2.5秒 vs. 0.25秒)和统一的能量阈值(2.5倍中值),分别针对长时摩擦噪声(如患者移动)和短时冲击噪声(如关门声)进行检测,并合并所有通道标记的噪声段索引,确保剔除的是整个多通道记录中受污染的公共段。这比单一通道或单一策略的噪声检测更全面、更稳健。
- MFCC-Conformer集成流程:首次将Conformer架构系统地应用于基于MFCC特征的心音图分类任务。之前的研究或使用传统分类器+手工特征,或使用预训练的语音模型(如Wav2Vec)但采用不同架构。本工作将专为时序音频设计的Conformer与经典的声学特征MFCC结合,并在目标数据集上从头训练(或微调),验证了该组合在噪声PCG数据上的有效性和潜力。
- 带噪声感知的监督混合对比学习:在训练目标中,除了传统的交叉熵分类损失,还集成了监督对比损失和中心损失。这种混合损失函数旨在同时实现三个目标:(a) 通过交叉熵进行分类;(b) 通过对比损失在嵌入空间中将相同类别(CAD/正常)的片段拉近,不同类别的推远,增强类内紧凑性和类间可分性,这对噪声导致的特征模糊尤为重要;(c) 通过中心损失进一步约束每个类别的特征围绕其原型中心分布,提升表示的判别力。
🔬 细节详述
- 训练数据:数据集包含297名男性受试者(155 CAD, 142正常)的同步多通道PCG信号,由嵌入式听诊器的可穿戴背心采集。采集地点为印度Fortis医院,分三轮进行(2023年5-6月,2024年1-2月,2025年2月)。环境为临床环境,存在背景噪声。每个受试者有1-3段60秒的录音。使用了背心7个通道中的1、2、3、4通道。未说明具体的数据增强方法。
- 损失函数:混合对比损失
L = β L_contr + α L_CE + λ_c L_center。其中:L_contr:监督对比损失(公式4),温度τ=0.8050。L_CE:标准交叉熵分类损失。L_center:中心损失(公式5),用于约束类内距离。- 权重:α=0.7235, β=0.9807, λ_c=0.00281。
- 训练策略:
- 优化器:AdamW。
- 学习率调度:指数衰减,初始学习率2.97e-06, 步长参数 s=2, 衰减率 γ=0.2903。
- 批次设置:基础批量大小 Nb=256, 梯度累积步数由 Nb 和最小批量 Nmb 决定。训练在片段级别进行。
- 训练轮数:10个epoch。模型选择基于训练集和验证集MCC的加权平均(0.9验证MCC + 0.1训练MCC)。
- 关键超参数(来自表1):
- 模型维度 D=1024, Conformer块数 B=3, 注意力头数 H=8, FFN隐藏维度 M=128。
- 卷积核大小 k=31。
- Dropout率:0.2903。
- 温度 τ:0.8050。
- 训练硬件:AMD Ryzen 7 3800X CPU, Nvidia RTX 3090 (24 GB) GPU。未说明具体训练时长。
- 推理细节:推理时,MLP分类器被移除,替换为支持向量机(SVM, RBF核)。受试者级别的预测通过对该受试者所有片段的预测结果进行多数投票得出。
- 正则化/技巧:使用了权重衰减(5.71e-05)、Dropout(0.2903)、层归一化、残差连接。训练使用了梯度累积来达到较大的有效批量大小(Nb=256)。超参数通过Optuna库的贝叶斯优化获得。
📊 实验结果
实验在同一个297受试者的数据集上进行,采用5折交叉验证,每折重复训练3次以报告均值±标准差。主要评估指标包括准确率(Acc)、平衡准确率/未加权平均召回率(UAR)、真阳性率(TPR)、真阴性率(TNR)、F1分数(F1+, F1-)和马修斯相关系数(MCC)。
关键对比结果(受试者级别):
| 方法 | Acc | UAR | TPR | TNR | F1+ | F1- | MCC |
|---|---|---|---|---|---|---|---|
| Noisy MFCC Conformer (基线) | 74.3±0.09% | 73.9±0.10% | 80.9±0.11% | 66.9±0.30% | 76.8±0.06% | 70.6±0.15% | 0.490±0.019 |
| Denoised MFCC Conformer (本文) | 78.4±0.29% | 78.2±0.32% | 81.9±0.49% | 74.5±0.97% | 79.9±0.20% | 76.4±0.48% | 0.570±0.058 |
| Noisy Wav2Vec 2.0 [13] (先前SOTA) | 77.1±1.50% | 74.3±1.73% | 86.5±1.30% | 62.0±2.76% | 82.3±1.10% | 67.1±2.56% | 0.510±0.035 |
关键结论:
- 噪声拒绝的有效性:应用噪声段拒绝算法后,模型在准确率和UAR上均获得超过4个百分点的提升,且TNR(识别正常样本的能力)从66.9%显著提升至74.5%,表明模型对噪声更鲁棒,判断更平衡。
- 超越先前SOTA:与使用更复杂模型(Wav2Vec 2.0)的先前工作相比,本文更轻量级的MFCC-Conformer模型在准确率(+1.3%)和UAR(+3.9%)上均取得提升,且MCC更高(0.570 vs. 0.510)。同时,本文方法在TNR上优势明显(74.5% vs. 62.0%),表明其对负类(正常)的识别更为可靠。
- 片段级别性能:噪声拒绝同样带来了片段级别的提升,准确率从71.2%提升至73.9%,UAR从70.9%提升至73.7%。
图表说明:
图1(pdf-image-page2-idx0)展示了噪声段拒绝算法的可视化效果。图中显示了来自同一段录音的HM(上)和NM(下)信号,红色高亮部分即为算法识别出的噪声段。可以看到,无论是HM上的持续摩擦噪声还是NM上的瞬时脉冲噪声,都被准确标记。这些段落在后续处理中被统一剔除,确保了输入模型的信号质量。
⚖️ 评分理由
- 学术质量(6.5/7):论文工作完整,解决了真实场景下的一个重要问题(噪声鲁棒性),提出的方法(噪声拒绝+Conformer+对比学习)有效且经过充分实验验证,结果可信。然而,创新性更多体现在系统集成和领域应用上,而非提出全新的、颠覆性的模型或理论。噪声拒绝算法本身相对简单,且缺乏更深入的消融研究来量化每个组件的贡献。
- 选题价值(2.0/2):选题具有明确的现实意义和应用价值,属于医疗AI与音频处理交叉的前沿方向。论文解决的问题(噪声鲁棒性)是该领域实际部署的关键瓶颈之一,因此具有较高的应用潜力。
- 开源与复现加成(+1.0/1):提供了详尽的超参数表、完整的代码仓库链接、训练框架、硬件环境等信息,复现门槛较低,是论文的一大亮点。