📄 nGPT as a Scalable Architecture for Speech Recognition and Translation
#语音识别 #语音翻译 #nGPT #多语言 #位置编码
✅ 7.5/10 | 前25% | #语音识别 | #nGPT | #语音翻译 #多语言
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Nune Tadevosyan (NVIDIA, Santa Clara, CA 95051, USA) (论文中注明*贡献相等)
- 通讯作者:未说明
- 作者列表:Nune Tadevosyan (NVIDIA), Nithin Rao Koluguri (NVIDIA), Monica Sekoyan* (NVIDIA), Piotr Zelasko (NVIDIA), Nikolay Karpov (NVIDIA), Jagadeesh Balam (NVIDIA), Boris Ginsburg (NVIDIA)。所有作者均隶属于NVIDIA公司。
💡 毒舌点评
亮点:在将Transformer编码器稳定扩展到3B参数上展现了工程实力,nGPT架构在单阶段训练下即在X→EN翻译任务上展现出强泛化能力,这是一个扎实的架构贡献。 短板:论文声称“首次将ALiBi应用于语音”,但核心贡献更像是将NLP领域成熟技术适配到语音任务,创新高度有限;同时,在ASR任务上,费尽心思提出的nGPT-3B在多阶段微调的1B FastConformer面前并未取得全面优势,削弱了其“可扩展性”叙事的部分说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。模型实现基于NVIDIA NeMo框架。
- 模型权重:未提及是否公开nGPT-3B/1B或FastConformer的预训练模型权重。
- 数据集:使用了内部数据集Granary和NeMo ASR Set 3.0,未说明是否对外公开。引用的评估集FLEURS、CoVoST、MLS是公开数据集。
- Demo:未提及。
- 复现材料:提供了详细的训练超参数、流程(多阶段)、数据混合比例、评估方法。引用了外部工具(Lhotse, OOMptimizer)。
- 论文中引用的开源项目:依赖于NeMo(NVIDIA的开源工具包,用于语音处理),以及Lhotse(用于数据处理)和OOMptimizer(用于批次大小优化)。
📌 核心摘要
- 要解决什么问题:现有语音识别(ASR)和语音翻译(ST)编码器架构在扩展到大规模参数和训练数据时,面临收敛不稳定、泛化能力不足以及处理长序列音频性能下降的问题。
- 方法核心是什么:提出将nGPT(一种采用超球面归一化技术的Transformer变体)作为语音编码器。该技术约束所有嵌入和激活值位于单位超球面上,防止梯度爆炸,实现稳定的大规模训练。同时,为解决长序列问题,首次将注意力线性偏置(ALiBi)应用于语音,并设计了对称版本以适应离线双向编码。
- 与已有方法相比新在哪里:1) 在语音领域引入了nGPT编码器,利用超球面归一化实现了稳定扩展至3B参数的训练,而FastConformer等基线需要多阶段训练。2) 提出并应用了对称ALiBi作为语音任务的长序列位置编码新方案。3) 证明了在大规模多语言数据上,nGPT编码器能以更简洁的训练流程(单阶段100k步)达到可比甚至更优的翻译性能。
- 主要实验结果如何:在1.7M小时多语言数据上训练。在FLEURS翻译基准(X→EN)上,nGPT-3B在100k步训练后COMET分数达78.36%,比同阶段训练的FastConformer单阶段模型(73.18%)高出5.18个绝对点。但在多阶段微调后,FastConformer(79.27%)反超。ASR任务上两者表现接近。长音频实验显示,ALiBi在长上下文ASR上持续优于RoPE插值。
- 实际意义是什么:为构建更稳定、更易扩展的大规模多语言语音模型提供了新的编码器架构选择,尤其是在数据充足、追求快速训练部署的场景下。对称ALiBi为长音频处理提供了新的位置编码思路。
- 主要局限性是什么:1) nGPT在ASR任务上并未显著超越强基线,且在多阶段训练后优势消失。2) 训练数据高度依赖内部数据集(Granary),且含大量伪标签,可能限制结论的普适性。3) 论文未提供代码和模型权重,可复现性依赖于读者对NeMo框架的熟悉程度。4) 将ALiBi应用于语音虽为首次,但本身属于技术迁移,创新性增量有限。
🏗️ 模型架构
本文提出的nGPT语音模型采用经典的编码器-解码器架构,核心创新集中在编码器部分。
整体流程:
- 输入:语音信号经过前端处理转换为声谱图特征。
- 前端:一个线性子采样模块(Linear Subsampling)对输入声谱图进行降维,降低时间序列长度。
- 编码器:由一堆堆叠的nGPT层组成,负责从降维后的特征中提取高级语言表示。每个nGPT层包含多头自注意力、门控前���网络,并应用关键的超球面归一化。
- 解码器:采用标准的Transformer解码器,基于编码器输出自回归地生成文本序列(识别结果或翻译文本)。
nGPT编码器层内部结构(结合图1):
- 输入/输出归一化:在层内,所有嵌入表示和中间激活值都通过超球面归一化约束到单位超球面上。这意味着向量的方向被保留,但幅度被固定为1。这通过在整个嵌入维度上进行归一化实现,并引入可学习的缩放因子α和σ来调节来自注意力路径和前馈路径的贡献比例。
- 多头自注意力:使用标准的缩放点积注意力,但位置信息通过旋转位置嵌入(RoPE) 或改进的对称ALiBi注入。自注意力的输入输出都经过超球面归一化。
- 门控前馈网络:采用两阶段门控设计,使用SiLU激活函数,平衡表达能力和效率。同样,其输入输出也经过超球面归一化。
- 残差连接:在每个子模块周围都保留残差连接,确保梯度稳定流动,使得模型可以逐层提炼表示。
- 权重归一化:除了激活值,论文还提到在每次优化器更新后对权重矩阵施加额外的归一化,以进一步稳定训练。
- 位置编码策略:论文重点对比了两种方案:
- RoPE:原始nGPT的默认选项,通过旋转向量编码相对位置。
- 对称ALiBi:本文首次引入语音领域的方案。它为注意力分数添加一个静态的、与位置成线性关系的偏置。与原始因果ALiBi不同,本文将其修改为对称矩阵(见图2),使得编码器在处理完整音频序列时,左右上下文受到同等对待,更适合离线任务。
架构图示例:
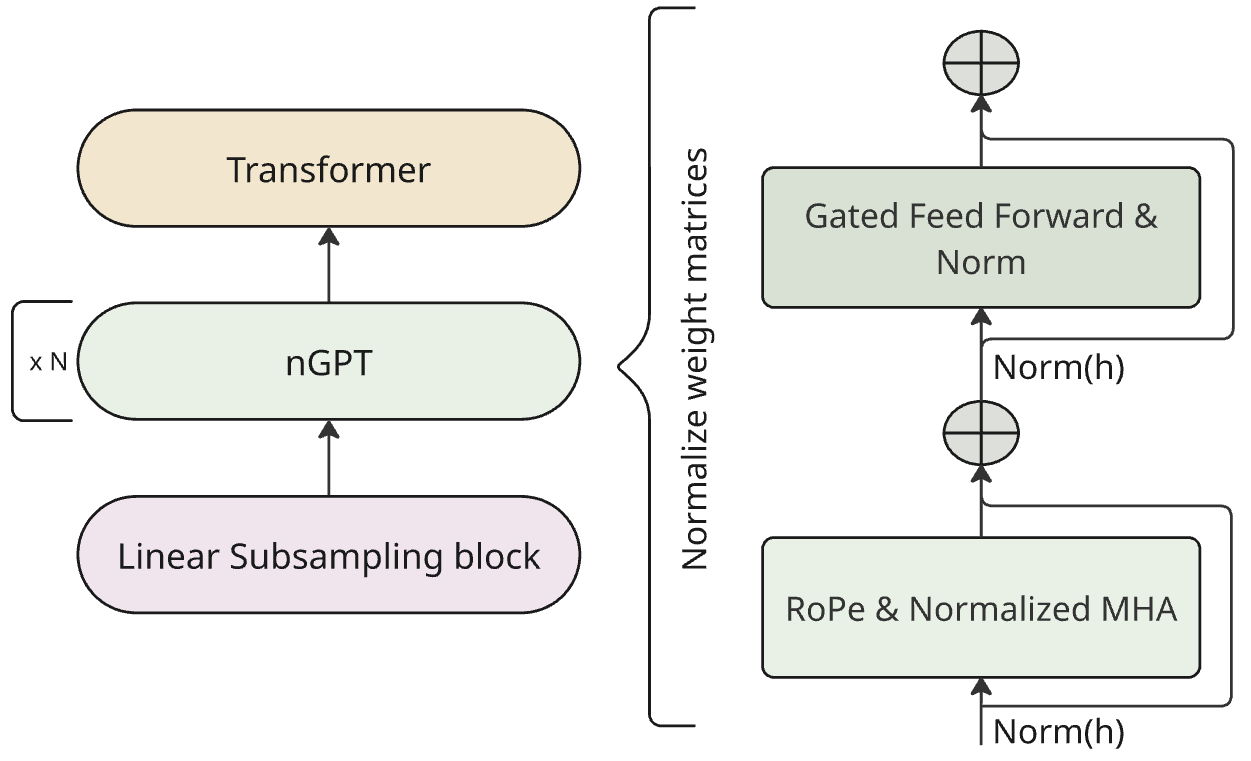 图1展示了nGPT的完整流程:输入特征经线性子采样后进入nGPT编码器层堆叠,每个层包含RoPE、多头注意力、门控前馈模块,并全程应用超球面归一化。最后由Transformer解码器生成文本。
图1展示了nGPT的完整流程:输入特征经线性子采样后进入nGPT编码器层堆叠,每个层包含RoPE、多头注意力、门控前馈模块,并全程应用超球面归一化。最后由Transformer解码器生成文本。
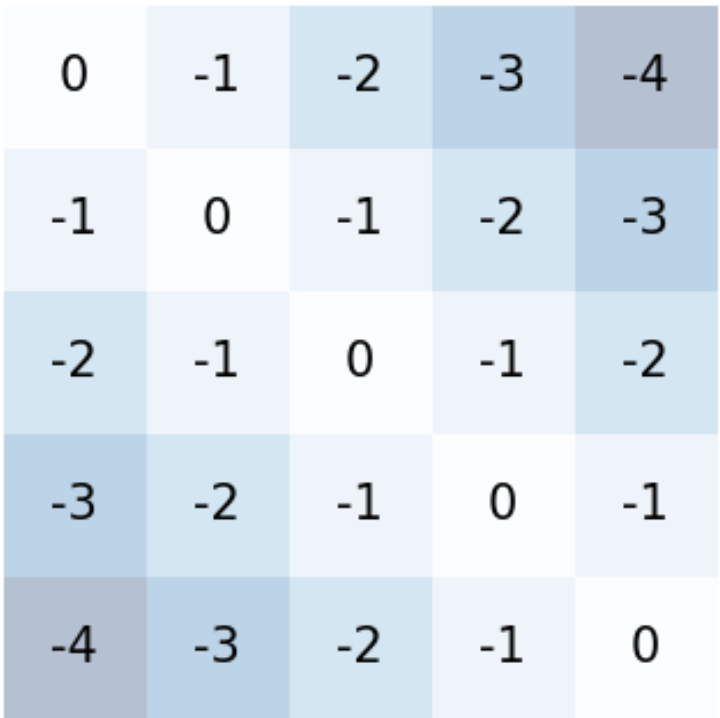 图2展示了对称ALiBi的偏置矩阵。与因果ALiBi不同,该矩阵关于对角线对称,确保对当前token左侧和右侧的token施加的线性惩罚是相等的,从而平衡双向上下文。
图2展示了对称ALiBi的偏置矩阵。与因果ALiBi不同,该矩阵关于对角线对称,确保对当前token左侧和右侧的token施加的线性惩罚是相等的,从而平衡双向上下文。
💡 核心创新点
将超球面归一化Transformer(nGPT)适配为语音编码器:
- 之前局限:基于Conformer的编码器在参数规模扩展到十亿级别时,常出现训练不稳定和收敛困难。
- 如何起作用:通过强制所有嵌入和激活值位于单位超球面上,防止了梯度爆炸,并改善了优化动力学。
- 收益:成功稳定训练了3B参数的语音编码器,无需依赖预训练检查点,且单阶段训练即可在翻译任务上达到强性能。
首次将对称ALiBi位置编码应用于语音任务:
- 之前局限:RoPE在长序列推理时性能可能下降;原始ALiBi仅适用于因果模型,不适用于双向编码的离线语音处理。
- 如何起作用:设计了对称的ALiBi偏置矩阵,适用于非因果编码器,允许模型在训练长度之外进行泛化,并对远距离token施加可控的注意力惩罚。
- 收益:在长序列ASR任务上,ALiBi相比RoPE插值提供了更稳定和更优的性能(见图3)。
在大规模多语言数据上展示nGPT的快速泛化能力:
- 之前局限:强基线如FastConformer通常需要复杂的多阶段训练和微调流程才能在多语言翻译上取得好结果。
- 如何起作用:nGPT架构的稳定性使其能够高效利用大规模数据,直接在全量数据上进行端到端训练。
- 收益:nGPT-3B仅通过100k步训练,在X→EN翻译任务上就大幅超越了处于相同训练阶段的FastConformer,证明了其在数据充足场景下的优势。
系统性的位置编码策略比较:
- 提供了RoPE与ALiBi在语音长序列任务中的首次全面对比,发现ALiBi更利于ASR,而RoPE可能对需要全局上下文的ST任务更优。
🔬 细节详述
训练数据:
- 来源与规模:主要基于内部Granary数据集,包含约100万小时、25种语言的多任务(ASR, X→EN)语音数据,其中许多是伪标签数据。
- 高质量补充:加入了22.7万小时的人工标注高质量数据(NeMo ASR Set 3.0),来自AMI、FLEURS、Common Voice、MLS等标准数据集,覆盖相同25种语言的ASR、X→EN和En→X任务。此部分占总训练数据的13%。
- En→X补充数据:由于原始Granary缺少En→X数据,作者从Granary中采样英语语音,并通过翻译方法生成了约48万小时的英语到非英语音频-转录对。
- 总训练数据量:约170万小时(1.7M hours)。
- 评估数据集:主要使用FLEURS(覆盖全部25种语言),辅以CoVoST和MLS(覆盖部分语言)。
损失函数:论文中未明确说明解码器使用的具体损失函数名称(如交叉熵、CTC等),但通常此类端到端模型使用交叉熵损失。
训练策略:
- nGPT:两个模型(1B和3B)均从头训练(scratch),未使用预训练检查点。在完整数据集(1.7M小时) 上训练100k步。学习率5e-4,500步预热,使用余弦调度器。优化器为AdamW,权重衰减0.001。
- FastConformer基线:展示了两种策略:
- 单阶段训练:从同一个混合RNN-T/CTC检查点开始,在完整数据集上训练250k步。
- 多阶段训练(三阶段):第一阶段在X→EN和EN ASR数据上训练150k步;第二阶段在完整数据集上继续训练100k步;第三阶段为高质量数据微调。第一阶段学习率4e-4,5k步预热,逆平方根衰减。
- 优化技巧:使用NeMo的2D duration bucket estimation结合Lhotse动态分桶来处理变长序列。使用OOMptimizer来确定每个分桶的最大可行批次大小,以最大化GPU利用率(~95%)。
关键超参数:
- 模型规模:论文对比了1B和3B参数的nGPT编码器,以及1B参数的FastConformer编码器。
- 架构细节:nGPT编码器包含门控前馈网络、多头自注意力、超球面归一化、可学习缩放因子(α, σ)。解码器为标准Transformer。
训练硬件:论文中未说明具体的GPU/TPU型号和数量。
推理细节:
- 长序列处理:探索了修改位置编码(RoPE插值、ALiBi放松偏置缩放因子)来提升长序列(如>40秒)推理性能。
- 解码策略:未提及具体的解码策略(如Beam Search大小、温度等)。
正则化/稳定训练技巧:核心是超球面归一化技术本身,它通过约束表示空间来稳定训练。此外,残差连接、权重衰减(AdamW)也是标准技巧。
📊 实验结果
主要对比表(nGPT vs FastConformer在不同训练阶段)
表1(a):ASR结果(WER%,越低越好)
| 模型 | 训练阶段 | FLEURS (25语言) | MLS (6) | CoVoST2 (12) | EN |
|---|---|---|---|---|---|
| FastConformer 1B | 单阶段 | 7.73 | 10.66 | 7.35 | 8.11 |
| nGPT 1B | 第1阶段 | 8.94 | 9.94 | 8.11 | 9.96 |
| nGPT 3B | 第1阶段 | 7.73 | 10.18 | 8.35 | 10.48 |
| FastConformer 1B | 第3阶段(多阶段) | 7.15 | 8.69 | 7.11 | 10.33 |
| nGPT 3B | 第2阶段 | 7.32 | 10.31 | 8.32 | 10.30 |
表1(b):语音翻译AST (X→EN) 结果(COMET%,越高越好)
| 模型 | 训练阶段 | FLEURS (24语言) | CoVoST2 (11) |
|---|---|---|---|
| FastConformer 1B | 单阶段 | 73.18 | 75.39 |
| nGPT 1B | 第1阶段 | 76.72 | 74.02 |
| nGPT 3B | 第1阶段 | 78.36 | 75.75 |
| FastConformer 1B | 第3阶段 | 79.27 | 76.82 |
| nGPT 3B | 第2阶段 | 79.14 | 75.90 |
表1(c):语音翻译AST (EN→X) 结果(COMET%,越高越好)
| 模型 | 训练阶段 | FLEURS (24语言) | CoVoST2 (5) |
|---|---|---|---|
| FastConformer 1B | 单阶段 | 84.30 | 80.63 |
| nGPT 1B | 第1阶段 | 83.05 | 78.31 |
| nGPT 3B | 第1阶段 | 84.22 | 80.00 |
| FastConformer 1B | 第3阶段 | 84.38 | 80.32 |
| nGPT 3B | 第2阶段 | 84.28 | 79.48 |
关键实验结论:
- 扩展性与快速训练:在“第1阶段”(相同数据、相同100k步)对比中,nGPT-3B在X→EN翻译任务(FLEURS)上COMET分数达到78.36%,比FastConformer-1B的73.18%高出5.18个绝对点,展现出卓越的单阶段训练泛化能力。在ASR任务上,两者WER接近(例如nGPT-3B在FLEURS上为7.73,与FC-1B持平)。
- 多阶段训练的威力:经过多阶段训练和微调后,FastConformer-1B在几乎所有基准上都达到了最佳性能(如X→EN COMET 79.27%),略微超越了nGPT-3B在第二阶段的结果(79.14%)。这表明FastConformer在精心设计的训练流程下上限很高,而nGPT的优势在于流程更简单直接。
- 任务差异性:nGPT在翻译任务(尤其是X→EN)上的优势比ASR任务更明显。
长序列位置编码实验(图3)
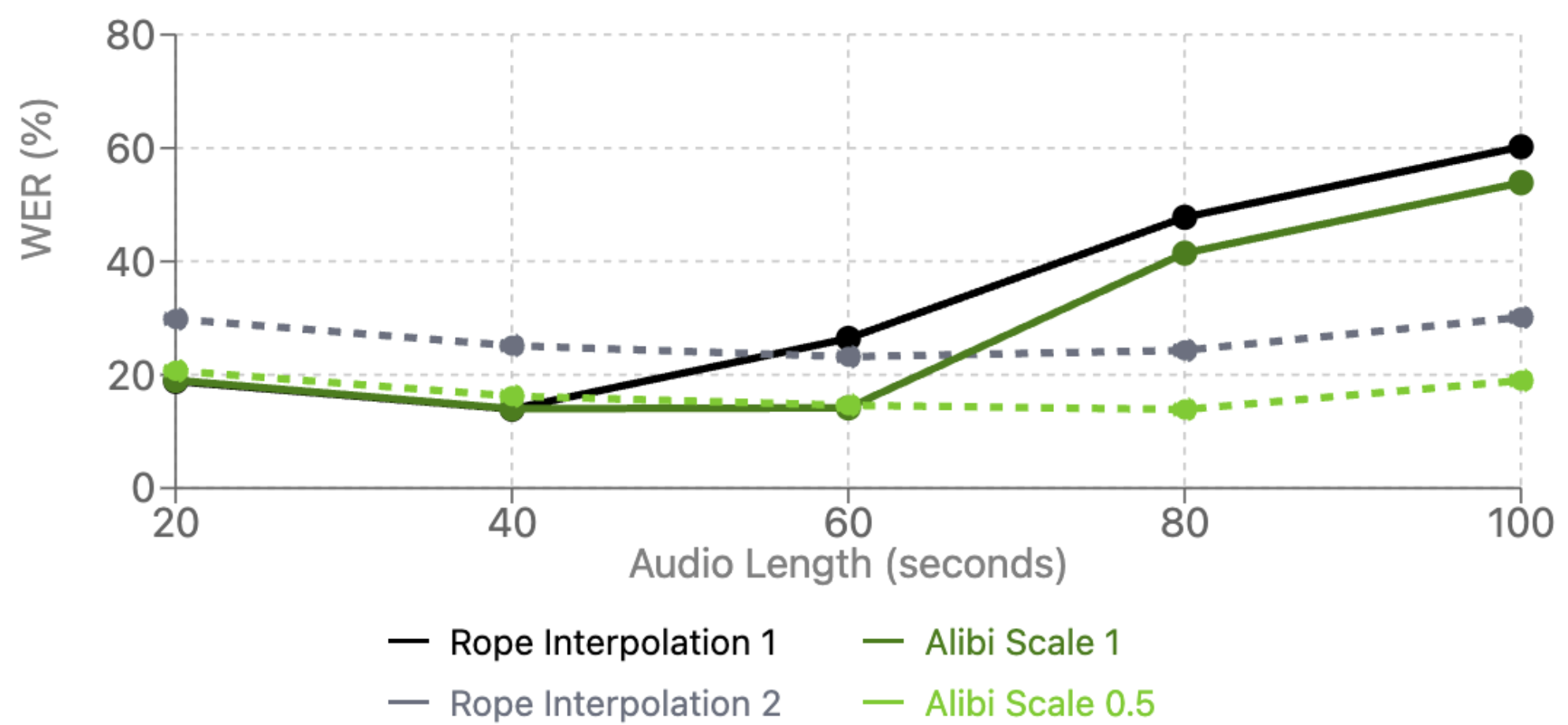 图3展示了在Earnings长音频数据集上的ASR性能(WER)。横轴代表不同的位置编码处理策略:对于RoPE,是插值因子(越大表示角速度减小越多以适应更长序列);对于ALiBi,是偏置缩放因子(越小表示对远距离token的惩罚越轻)。纵轴是词错误率(WER)。结果显示,ALiBi在处理长序列时WER更低(性能更好),且调整缩放因子带来的改善比RoPE调整插值因子更显著。
图3展示了在Earnings长音频数据集上的ASR性能(WER)。横轴代表不同的位置编码处理策略:对于RoPE,是插值因子(越大表示角速度减小越多以适应更长序列);对于ALiBi,是偏置缩放因子(越小表示对远距离token的惩罚越轻)。纵轴是词错误率(WER)。结果显示,ALiBi在处理长序列时WER更低(性能更好),且调整缩放因子带来的改善比RoPE调整插值因子更显著。
关键结论:在长上下文ASR推理中,ALiBi比RoPE插值更有效。论文指出,ASR任务更依赖局部上下文,因此ALiBi对远距离注意力的适度抑制反而有益;而ST任务可能需要更多全局上下文,RoPE可能更合适。
⚖️ 评分理由
学术质量:5.5/7
- 创新性(2.0/3):将nGPT引入语音是一个有价值的探索,解决了扩展性问题;首次引入对称ALiBi到语音是明确的创新点。但整体属于将已有技术进行领域适配和验证,非范式级突破。
- 技术正确性(1.5/2):实验设计合理,对比维度清晰(不同规模、不同训练阶段、不同位置编码),数据量大,评估指标(WER, COMET)选择恰当。技术细节描述基本完整。
- 实验充分性(1.5/2):实验覆盖了ASR和ST两大任务,进行了消融(位置编码比较)和规模分析(1B vs 3B)。不足之处在于缺少与近期强大基线(如Whisper, SeamlessM4T)的直接对比,且nGPT在ASR任务上未展示明显优势。
- 证据可信度(0.5):所有实验基于庞大的内部数据集,可信度较高,但部分数据为伪标签可能引入噪声。结论有数据支撑,未过度夸大。
选题价值:1.5/2
- 前沿性(0.5/1):多语言ASR/ST模型的可扩展架构和长序列处理是当前的研究热点。
- 潜在影响与应用空间(1.0/1):改进编码器的稳定性和扩展性对工业界训练大规模语音模型有直接价值。ALiBi的引入为不同任务的位置编码选择提供了新视角。对音频/语音领域读者(尤其是模型训练者)有较高参考价值。
开源与复现加成:0.5/1
- 论文详细公开了训练配置(学习率、优化器、步数)、数据构成、硬件使用效率工具(OOMptimizer),并依托于已知的NeMo框架,提供了良好的复现指引。
- 主要减分项是未提供代码仓库、预训练模型权重或详细的环境配置,这使得完全复现论文中的大模型实验门槛极高,只能依赖对NeMo和nGPT论文[12]的熟悉程度进行部分复现。