📄 NeuroSIFT: A Biologically-Inspired Framework with Explicit Signal-Noise Separation for Robust Multimodal Emotion Recognition
#多模态情感识别 #神经形态计算 #多任务学习 #鲁棒性 #跨模态
🔥 8.0/10 | 前25% | #多模态情感识别 | #神经形态计算 | #多任务学习 #鲁棒性
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Gang Xie(杭州电子科技大学计算机学院)
- 通讯作者:Wanzeng Kong(杭州电子科技大学计算机学院)
- 作者列表:Gang Xie(杭州电子科技大学计算机学院)、Jiajia Tang(杭州电子科技大学计算机学院)、Tianyang Qin(杭州电子科技大学计算机学院)、Yiwen Shen(杭州电子科技大学计算机学院)、Wanzeng Kong(杭州电子科技大学计算机学院)
💡 毒舌点评
这篇论文最亮眼的地方是它“仿生”不玩虚的,直接模仿海马体神经回路的选择性抑制机制来做信号分离,并在两个主流数据集上取得了显著的性能提升(如CH-SIMSv2上F1值提升5.44%),证明了思路的有效性。但短板也很明显:一是生物启发到计算模型的映射稍显简单化(如将复杂的神经元交互简化为两个门控信号),理论解释有待深化;二是全文未开源任何代码或模型,对于一篇强调“框架”和“复现”的论文来说,这严重削弱了其影响力。
🔗 开源详情
论文中未提及开源计划。具体来说:
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的CH-SIMSv2和MUStARD数据集,但论文中未说明具体获取或预处理方式。
- Demo:未提及。
- 复现材料:论文提供了部分关键架构和损失函数公式,但缺少完整的超参数配置、训练日志和检查点。
- 论文中引用的开源项目:未提及引用了哪些特定的开源代码库。
📌 核心摘要
- 问题:现有多模态情感识别(MER)方法因无法显式分离真实世界中的复杂噪声(感知、结构、语义噪声)而性能下降,多依赖隐式的噪声适应策略。
- 方法核心:提出NeuroSIFT框架,受海马体-前额叶回路中SST+、PV+和VIP+中间神经元的选择性抑制机制启发。框架包含三个核心组件:语义模拟噪声生成器(生成与输入语义对齐的噪声参考)、神经回路选择性抑制模块(利用噪声参考显式分解输入为情感信号和结构化噪声)、双流对抗训练框架(分别处理并利用分解后的信号与噪声流)。
- 创新点:与已有方法相比,核心创新在于实现了显式的信号-噪声分离,而非隐式适应。具体创新包括:1) 基于批次负采样的语义噪声生成;2) 模仿生物神经抑制与去抑制的分离模块;3) 利用噪声流增强对抗鲁棒性的双流训练。
- 主要实验结果:在CH-SIMSv2和MUStARD数据集上全面超越现有SOTA方法。具体如下表所示:
数据集 方法 主要指标 CH-SIMSv2 NeuroSIFT (Ours) Acc-2: 89.13, F1-2: 89.14, Corr: 0.835 最佳基线 (Coupled Mamba) Acc-2: 83.40, F1-2: 83.50, Corr: 0.758 提升 +5.33% (Acc), +5.44% (F1) MUStARD NeuroSIFT (Ours) Acc: 77.68, F1: 77.51 最佳基线 (CAF-I) Acc: 75.50, F1: 75.20 提升 +1.95% (Acc), +2.12% (F1) - 实际意义:为构建对真实世界噪声更鲁棒的多模态情感识别系统提供了一种新的生物启发设计范式,其“分离-再利用”的思路可能对其他多模态感知任务有借鉴意义。
- 主要局限性:1) 生物机制到算法的映射是高度简化的,可能未能完全捕捉真实神经回路的复杂性;2) 论文承认双流设计引入了计算开销;3) 未开源代码与模型,限制了可复现性。
🏗️ 模型架构
NeuroSIFT的整体架构如图1所示,其处理流程是:输入多模态数据(文本、音频、视频) -> 语义模拟噪声生成 -> 神经回路选择性抑制进行显式分解 -> 双流并行处理与对抗训练 -> 输出情感分类。
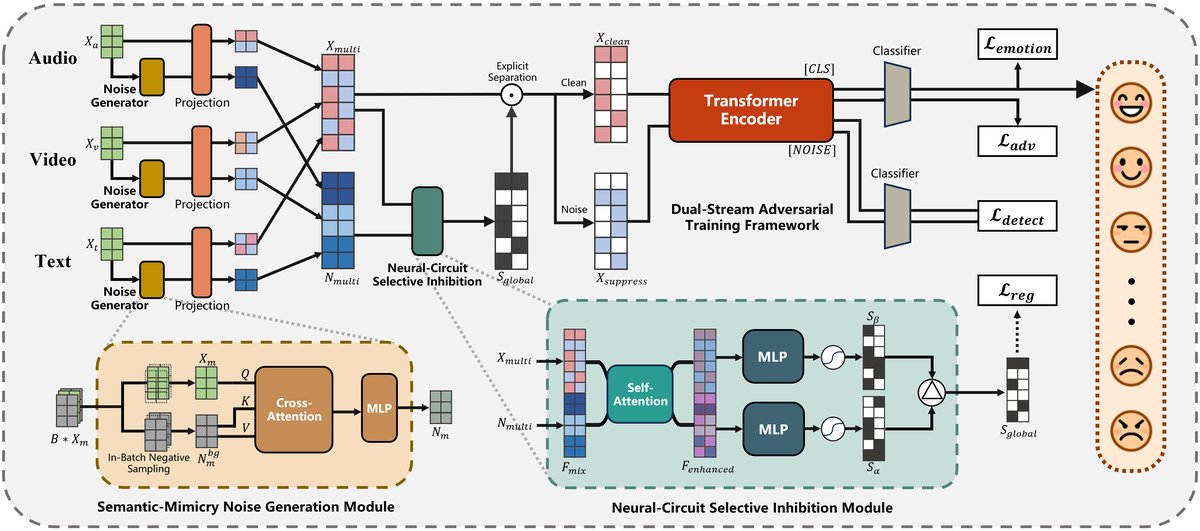
语义模拟噪声生成模块:
- 功能:为每个输入样本生成一个“语义上相似但情感信息不同”的噪声参考,作为后续分离的锚点。
- 过程:对批次内同一模态的其他样本特征取平均,得到背景噪声参考
N_bg_m。然后,以原始特征X_m为键(Key),噪声参考为查询(Query)和值(Value),进行交叉注意力增强,再通过MLP和层归一化得到最终噪声参考N_m。最后,所有模态的原始特征和噪声参考被投影到统一维度并拼接,得到X_multi和N_multi。
神经回路选择性抑制模块:
- 功能:这是框架的核心,旨在模拟海马体中间神经元的竞争性抑制机制,显式地将
X_multi(混合了信号与噪声)分解为干净信号流和噪声流。 - 过程:将
X_multi和N_multi拼接后通过多头自注意力增强。增强后的表示被拆分回增强的原始表示X_enh和噪声表示N_enh。 - 生物启发机制:
- 自发抑制路径(模拟SST+中间神经元):从噪声表示
N_enh生成抑制信号S_alpha(范围(0,2)),表示噪声驱动的抑制强度。 - 去抑制路径(模拟PV+和VIP+神经元):从原始特征
X_enh生成去抑制信号S_beta(范围(0,2)),表示需要保留的情感信号强度。 - 全局抑制信号
S_global由两者组合而成:S_global = S_alpha ⊙ (1 - S_beta) + S_beta/2。此公式实现竞争:当S_beta高(情感信号强)时,S_alpha的影响被削弱;反之,噪声抑制占主导。 - 正则化:通过最大化
S_global在序列和特征维度上的方差,避免均匀抑制,鼓励选择性分离。
- 自发抑制路径(模拟SST+中间神经元):从噪声表示
- 功能:这是框架的核心,旨在模拟海马体中间神经元的竞争性抑制机制,显式地将
双流对抗训练框架:
- 功能:利用全局抑制信号
S_global对原始多模态特征X_multi进行门控,产生两个并行流。 - 过程:
- 干净信号流:
X_clean = S_global ⊙ X_multi。添加专门的[CLS]和[NOISE] token,送入共享的Transformer编码器T_theta,主要任务是预测正确的情感标签。 - 噪声流:
X_suppress = (1 - S_global) ⊙ X_multi。同样添加token并送入共享编码器,主要任务是预测错误的标签(对抗训练)并判断自己的[NOISE] token为“噪声”(0)。
- 干净信号流:
- 共享权重的设计确保了两个流使用相同的表示能力进行学习。
- 功能:利用全局抑制信号
💡 核心创新点
- 生物启发的显式信号-噪声分离机制:不同于传统注意力权重调整或隐式对抗去噪,本文首次将海马体抑制性神经回路的计算原理(抑制与去抑制竞争)应用于多模态情感识别,实现了对混合输入的显式、可解释分解。
- 语义模拟噪声生成:针对传统随机噪声无法模拟真实语义干扰的局限,提出基于批次负采样和交叉注意力增强的方法,生成与输入内容相关、但情感信息不同的噪声参考,为分离提供了更有效的锚点。
- 双流对抗训练框架:创新性地设计了双流并行架构,不仅利用干净流进行分类,更首次系统性地利用被分离出的“噪声流”进行对抗性训练(学习预测错误标签)和噪声检测,从而同时提升了分类性能和模型鲁棒性。
🔬 细节详述
- 训练数据:使用CH-SIMSv2(中文,包含二分类、三分类、五分类和回归任务)和MUStARD(英文,讽刺检测)数据集。论文未提供具体的预处理、数据增强细节。
损失函数:总损失
L_total = L_emotion + λ1L_adv + λ2L_detect + λ3L_reg。L_emotion:干净流[CLS] token的分类交叉熵损失。L_adv:噪声流[CLS] token的对抗损失。针对分类任务为预测错误标签的交叉熵;针对回归任务为与腐败目标的MSE损失。L_detect:二元交叉熵损失,确保干净流的[NOISE] token预测为1(噪声),噪声流的预测为0(信号)。L_reg:抑制信号S_global的方差最大化损失。- 损失权重
{λ1, λ2, λ3}未具体给出。
- 训练策略:优化器、学习率、batch size、训练轮数等关键训练超参数在正文中未说明。
- 关键超参数:模型参数量仅1.58M,FLOPs 0.08G,推理时间2.1ms(在RTX 3080上),非常轻量。统一维度
d、Transformer层数、头数等未说明。 - 训练硬件:仅提及推理测试使用单张RTX 3080 GPU,训练硬件未说明。
- 推理细节:标准前向传播,未提及特殊解码策略。
- 正则化:除了
L_reg,未提及Dropout等其他正则化技巧。
📊 实验结果
- 主实验对比:在CH-SIMSv2和MUStARD上与17+种方法(包括传统模型和大型语言模型)进行比较,NeuroSIFT在所有指标上均取得最优。关键结果表格已在核心摘要中列出。论文指出其性能提升在统计学上显著(p < 0.05)。
- 消融实验:
- 噪声生成策略消融(表2):在MUStARD上,语义模拟噪声(负采样)的准确率(77.43%)优于高斯噪声(76.02%)和椒盐噪声(75.99%)约1.4%,验证了语义噪声参考的有效性。
- 多任务损失消融(图2):在MUStARD上移除各损失组件的影响:
L_adv(准确率-2.10%)、L_detect(-1.66%)、L_reg(-1.42%),证明了每个组件的必要性。
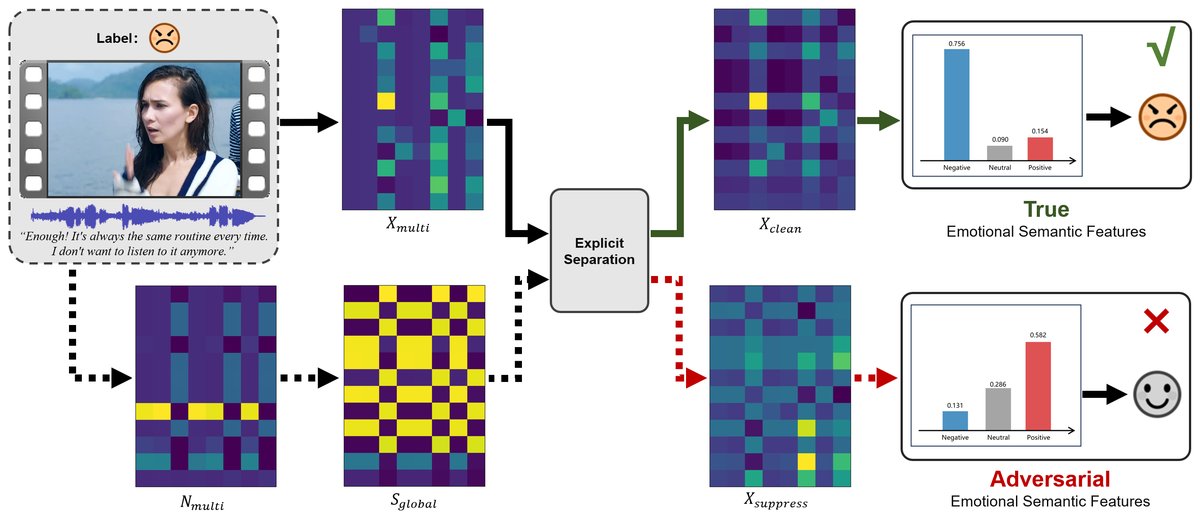 图2展示了不同训练配置(移除不同损失组件)下的准确率变化,清晰地显示了每个组件对最终性能的贡献。
图2展示了不同训练配置(移除不同损失组件)下的准确率变化,清晰地显示了每个组件对最终性能的贡献。
- 案例研究:图3展示了一个负向情感样本的分离可视化。干净流
X_clean以0.756置信度正确预测为负向,而噪声流X_suppress预测失败,直观验证了分离的有效性。
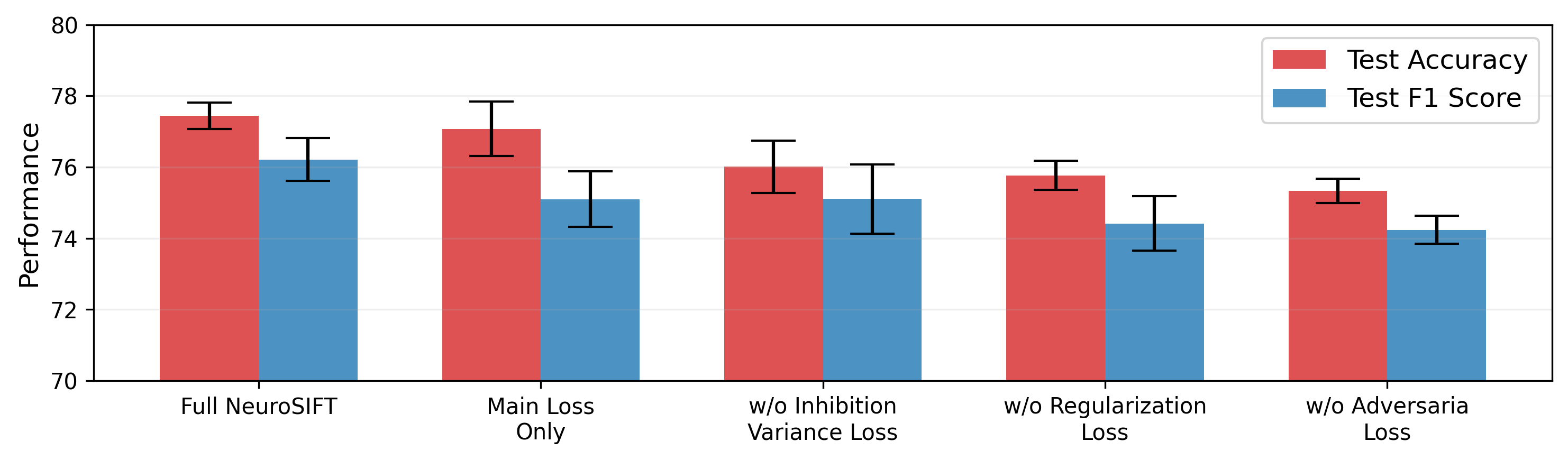 图3可视化了模型对一个负向情感样本的分离结果,左列为原始多模态特征,右列显示经过选择性抑制后,干净信号流保留了关键特征,而噪声流则混合了无关信息。
图3可视化了模型对一个负向情感样本的分离结果,左列为原始多模态特征,右列显示经过选择性抑制后,干净信号流保留了关键特征,而噪声流则混合了无关信息。
- 计算复杂度(表3):与Self-MM(44.3M参数)和Coupled Mamba(8.9M参数)相比,NeuroSIFT参数量(1.58M)和计算开销(0.08G FLOPs, 2.1ms)显著更低,体现了效率优势。
⚖️ 评分理由
- 学术质量:6.5/7。创新性明确(生物启发+显式分离),技术路线完整,实验设计全面(主实验、消融实验、案例分析、复杂度分析),结果提升显著且可信。扣分点在于生物模型到计算模型的映射理论解释相对初级,且部分超参数细节缺失。
- 选题价值:1.5/2。多模态情感识别的鲁棒性是重要且实际的问题,生物启发的方法为该领域提供了新的视角。应用场景主要在情感计算,虽然特定但有价值。
- 开源与复现加成:0/1。论文中未提及任何代码、模型权重或详细复现指南的开源计划,这极大地阻碍了该工作的验证和应用,因此无加分。