📄 Musicdetr: A Position-Aware Spectral Note Detection Model for Singing Transcription
#歌唱语音转录 #音乐信息检索 #对象检测 #注意力机制 #端到端
🔥 8.5/10 | 前10% | #歌唱语音转录 | #对象检测 | #音乐信息检索 #注意力机制
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Mengqiao Chen(华中科技大学电子信息与通信学院,湖北省智能互联网技术重点实验室)
- 通讯作者:Wei Xu(华中科技大学电子信息与通信学院,湖北省智能互联网技术重点实验室)
- 作者列表:Mengqiao Chen(华中科技大学电子信息与通信学院,湖北省智能互联网技术重点实验室)、Qikai He(华中科技大学电子信息与通信学院,湖北省智能互联网技术重点实验室)、Zhuoyuan Zhang(华中科技大学电子信息与通信学院,湖北省智能互联网技术重点实验室)、Wenqing Cheng(华中科技大学电子信息与通信学院,湖北省智能互联网技术重点实验室)、Wei Xu(华中科技大学电子信息与通信学院,湖北省智能互联网技术重点实验室)
💡 毒舌点评
亮点:首次将DETR引入歌声转录领域,并非简单套用,而是通过设计音符位置解码器、多目标单匹配策略和质量敏感损失函数三个针对性模块进行了深度改造,在多个基准上达到SOTA,证明了对象检测范式在AST中的有效性。 短板:论文计算复杂度(特别是引入额外解码器层)未作分析,在音符密集或快速演唱等复杂场景下的鲁棒性有待进一步验证;此外,部分训练细节(如具体优化器参数)的缺失略微影响了技术方案的完整透明度。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:
https://github.com/ChenMengqiao/MusicDETR。 - 模型权重:论文未提及是否公开预训练模型权重。
- 数据集:论文扩展的SSVD3.0数据集公开可用,提供了下载链接 (
https://github.com/hust-itec2/SSVD3.0)。MIR-ST500和ISMIR2014为公开数据集。 - Demo:论文未提供在线演示链接。
- 复现材料:论文提供了代码仓库,但未详细列出训练配置文件、检查点或附录中的超参数设置。
- 引用的开源项目:论文未明确列出所有依赖的开源项目,但方法基于DETR框架,并使用了
mir_eval库进行评估。
📌 核心摘要
问题:自动歌声转录(AST)旨在从歌声音频中推断音符的起始、结束时间和音高。传统方法或简单的帧级预测模型在准确性和端到端能力上仍有提升空间。
方法核心:本文提出了MusicDETR,一个基于Transformer的端到端AST模型。它将转录问题转化为频谱图上的音符对象检测问题,并首次在AST领域引入DETR框架。其核心创新在于设计了利用音符间位置关系的音符位置解码器、增加训练正样本的多目标单匹配(MTSM)策略以及对检测质量更敏感的质量敏感匹配损失(QML)。
创新点:a) 位置感知解码:通过量化音符在频谱图中的位置相关性(MC值接近0.8),并在解码器自注意力中显式融入音符间的相对位置关系编码。b) 训练策略优化:采用MTSM策略,通过复制目标图像来增加每个训练批次中的正样本数量,缓解O2O匹配导致的样本稀缺问题。c) 损失函数设计:提出QML损失,同时对预测框的IoU和分类分数敏感,避免因匹配错误导致的重叠检测和漏检。
实验结果:在SSVD3.0、ISMIR2014和MIR-ST500三个数据集上进行了广泛实验。MusicDETR在最具挑战性的COnPOff指标上取得了最优结果。例如,在SSVD3.0测试集上,COnPOff F1分数达到93.65%;在ISMIR2014上达到74.83%,均优于现有SOTA模型(如Phoneme, MusicYOLO)。消融研究证明了三个提出模块的有效性。
- 关键实验结果表格(转录F1分数对比):
模型 ISMIR2014 COnPOff F1 (%) SSVD3.0 COnPOff F1 (%) MIR-ST500 COnPOff F1 (%) TONY 47.10 67.39 26.27 FU&SU 59.40 57.79 23.25 Phoneme 72.44 85.56 33.02 MusicYOLO 71.56 82.99 31.03 MusicDETR (ours) 74.83 93.65 35.24 MusicDETR* (trained on MIR-ST500) 69.72 67.85 60.88 实际意义:该工作推动了AST从帧级预测向更直接的音符对象检测范式发展,为音乐信息检索、音乐教育辅助、歌声编辑等应用提供了更精准的技术基础。
主要局限性:a) 模型结构比传统帧级模型更复杂,可能带来更高的计算开销。b) 论文未讨论模型在处理极度密集、快速或滑音等复杂演唱技巧时的表现。c) 部分关键的训练超参数(如学习率、优化器具体配置)未在论文中详细说明。
🏗️ 模型架构
MusicDETR是一个端到端的音符检测模型,其整体流程如下:
- 输入:原始歌声音频被转换为频谱图(Spectrogram)。
- 骨干网络:使用卷积神经网络(CNN,具体架构未说明)从频谱图中提取高维特征图。
- 查询初始化:一组可学习的查询向量(Query Embeddings)作为解码器的输入,数量通常预设为最大可能检测的音符数量。
- 音符位置解码器:这是模型的核心创新。解码器采用Transformer结构,包含多个解码层。在每一层的自注意力计算中,不仅使用查询和键的内积,还显式地融合了来自上一层预测的音符边界框之间的位置关系信息。具体地,通过一个音符关系编码(NRE) 模块(公式5-6)计算出每对预测框之间的相对位置、尺寸关系等特征,经正弦余弦编码后加入到注意力分数中(公式2)。这鼓励模型学习音符在时间-频率平面上存在的位置规律性(如音高变化趋势、节奏规律)。解码器输出更新后的查询向量。
- 预测头:更新后的查询向量经过前馈网络(FFN)和多层感知机(MLP),最终输出每个查询对应的音符预测,包括边界框(onset, offset在时间轴上的范围) 和 音高(pitch)(公式4)。
- 输出:一组预测的音符实例,每个包含起始时间、结束时间、音高和置信度分数。
关键设计动机:传统DETR的目标位置关系是隐式学习的。论文通过统计分析发现,歌声频谱图中的音符对象位置相关性(MC≈0.8)远高于自然图像,且音符类别单一。因此,显式建模这种强位置关系先验能提供更强的监督信号,提升检测精度,尤其是在音高和时间边界上。
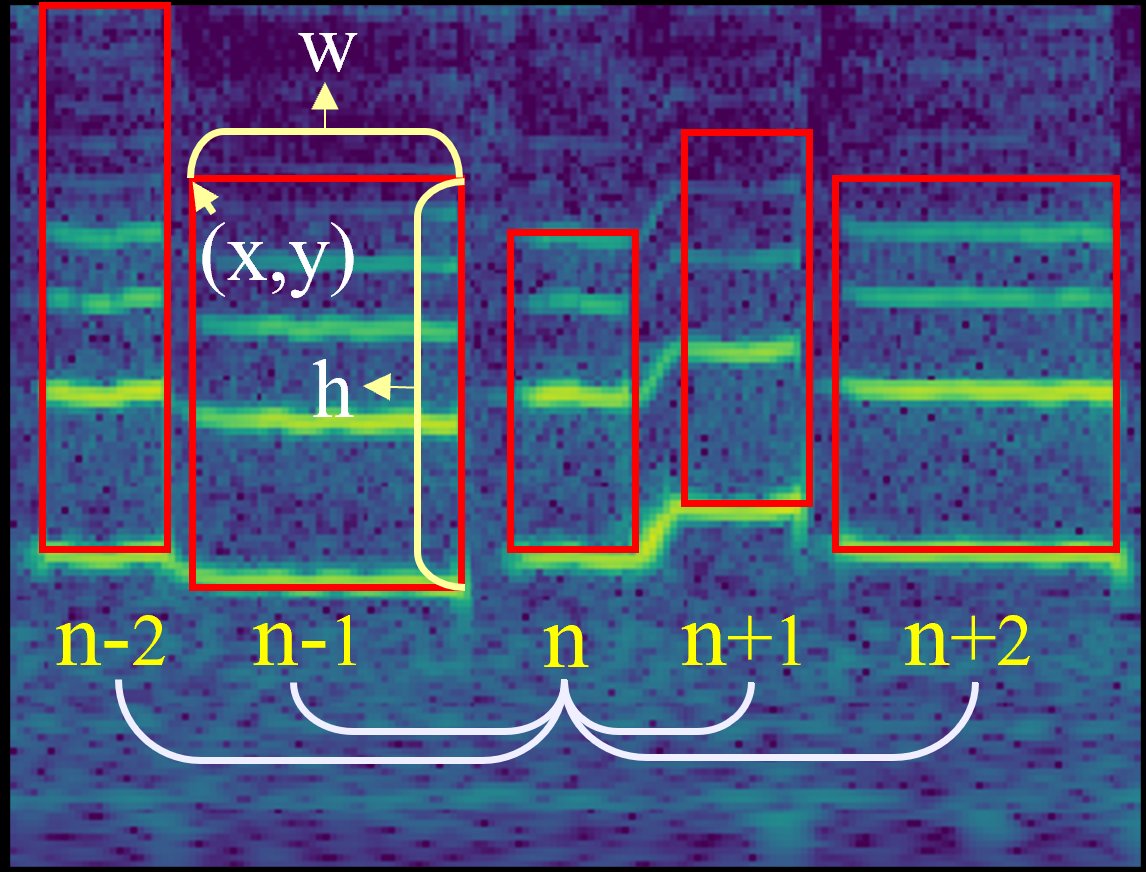 图2:MusicDETR总体架构示意图。图中清晰展示了频谱图输入、CNN骨干网络、具有位置关系融合的解码器、以及最终输出的音符边界框和音高预测。
图2:MusicDETR总体架构示意图。图中清晰展示了频谱图输入、CNN骨干网络、具有位置关系融合的解码器、以及最终输出的音符边界框和音高预测。
💡 核心创新点
- 音符位置解码器:将频谱图中音符间的强位置相关性先验,显式地编码进Transformer解码器的自注意力机制中。与依赖数据驱动学习的通用DETR相比,这为AST任务引入了更有效的归纳偏置,显著提升了音符定位的精度(消融实验中,引入NRE后COnP F1在SSVD3.0上提升6.97%)。
- 多目标单匹配策略(MTSM):针对AST任务中音符样本相对稀疏、O2O匹配导致正样本不足的问题,MTSM通过下采样复制训练图像,在不增加解码器复杂度的情况下,将每个训练批次中的检测目标数扩大4倍,为模型提供更密集的监督信号,有效缓解漏检和误检。
- 质量敏感匹配损失(QML):重新设计了AST任务中的损失函数。相比VFL,QML对“预测置信度高但IoU低”(错误匹配)的情况施加更大的惩罚,强制模型学习更精确的边界框定位,从而提升了最终音符转录的完整性和准确性(消融实验中,加入QML后COnPOff召回率显著提升)。
🔬 细节详述
- 训练数据:
- SSVD3.0:论文作者基于SSVD2.0扩展而来。训练集包含300首歌曲(原SSVD2.0为67首);测试集包含100首歌曲(从原127首中划分)。验证集也包含100首歌曲。数据集公开可用。
- MIR-ST500:一个包含500首中文流行歌曲的公开AST数据集。
- ISMIR2014:包含38首英文流行歌曲片段的公开数据集。
- 预处理:未详细说明(通常包括频谱图计算,如STFT参数)。
- 数据增强:MTSM策略可视为一种数据增强。其他未说明。
- 损失函数:质量敏感匹配损失(QML),公式为 Eq.7。它结合了预测类别分数
p和预测框与真实框的IoU值q,对正样本(y=1)施加同时考虑p和q的损失,对负样本(y=0)仅基于p计算损失。参数γ控制样本难度平衡。 - 训练策略:论文指出“训练使用SSVD3.0训练集”。MTSM策略在训练时对目标图像进行缩小并复制成四份独立副本进行检测。未说明具体的学习率、优化器、batch size、训练轮数等关键超参数。
- 关键超参数:未明确说明模型具体大小(如Transformer层数、隐藏维度、查询向量数量等)。
- 训练硬件:论文未提及。
- 推理细节:推理时直接对测试频谱图进行前向传播,解码器输出预测的音符列表。未说明是否使用NMS或其他后处理(DETR本身通常不需要NMS)。
- 正则化技巧:未说明。
📊 实验结果
- 主要对比实验:
起始/偏移点检测:在ISMIR2014和SSVD3.0数据集上,对比了COn和COff指标。MusicDETR在所有设置下均取得最佳结果。
- 表1: 起始/偏移点检测结果 (%)
模型 ISMIR2014 COn ISMIR2014 COff SSVD3.0 COn SSVD3.0 COff TONY 67.63 74.47 79.28 93.54 FU&SU 78.76 75.87 83.87 86.03 omnizart 79.51 78.52 78.47 79.01 Phoneme 93.05 86.03 94.82 96.56 MusicYOLO 90.01 84.96 95.18 97.95 MusicDETR 93.07 86.23 95.95 98.44
- 表1: 起始/偏移点检测结果 (%)
音符转录:在三个数据集上对比COnP和COnPOff(最严格指标)的F1分数。MusicDETR在SSVD3.0和ISMIR2014上全面超越所有基线。在MIR-ST500上,使用相同训练数据时也显著优于原论文作者的模型。
表2: COnP结果 (%) (部分关键数据)
模型 ISMIR2014 F1 SSVD3.0 F1 MIR-ST500 F1 Phoneme 83.06 87.92 51.73 MusicYOLO 82.50 85.45 44.79 MusicDETR (ours) 88.50 94.77 49.85 MusicDETR* (on MIR-ST500) 85.97 86.71 74.92 表3: COnPOff结果 (%) (关键数据已在核心摘要中列出)
- 与最强基线差距:在SSVD3.0 COnPOff F1上,比第二强的Phoneme模型高出8.09个百分点(93.65% vs 85.56%)。
- 消融研究:在SSVD3.0和ISMIR2014上,逐步添加NRE、MTSM、QML三个模块。
- 表4: 关键模块消融研究 (%)
NRE MTSM QML SSVD3.0 COnP F1 SSVD3.0 COnPOff F1 ISMIR2014 COnP F1 ISMIR2014 COnPOff F1 86.60 85.12 82.17 71.17 ✓ 91.97 91.12 84.55 71.18 ✓ ✓ 94.22 93.40 85.48 72.19 ✓ ✓ ✓ 94.77 93.65 88.50 74.83 结果表明:NRE主要提升精度(Precision),MTSM在进一步提升精度的同时略微影响召回率(Recall),QML则显著提升召回率,三者组合达到最佳F1分数。
- 表4: 关键模块消融研究 (%)
- 其他图表:
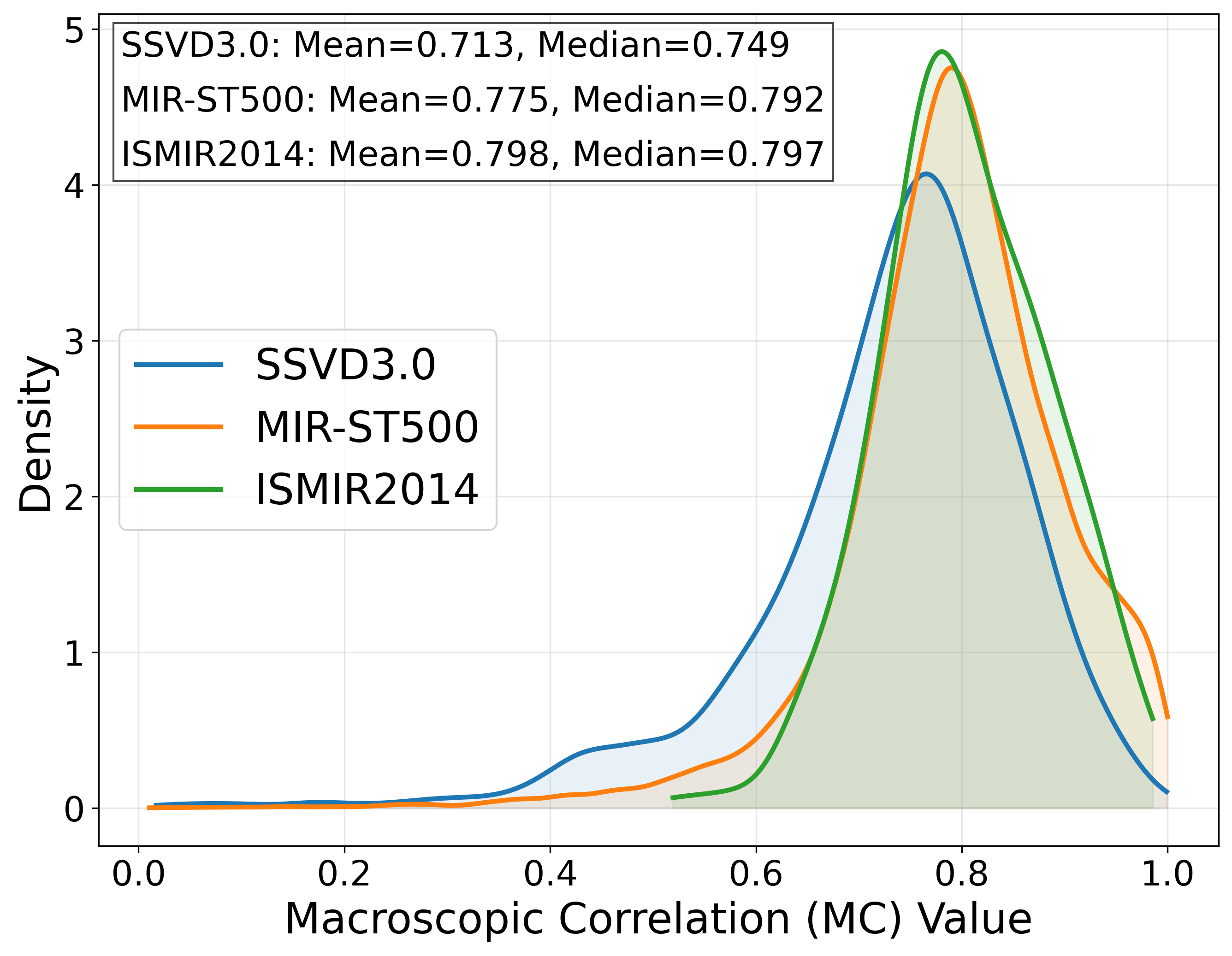 图1:(a) 频谱图中音符位置关系示意图。(b) 不同AST数据集上宏观相关性(MC)的统计分布。MC值普遍接近0.8,证实了音符间存在强位置相关性。
图1:(a) 频谱图中音符位置关系示意图。(b) 不同AST数据集上宏观相关性(MC)的统计分布。MC值普遍接近0.8,证实了音符间存在强位置相关性。
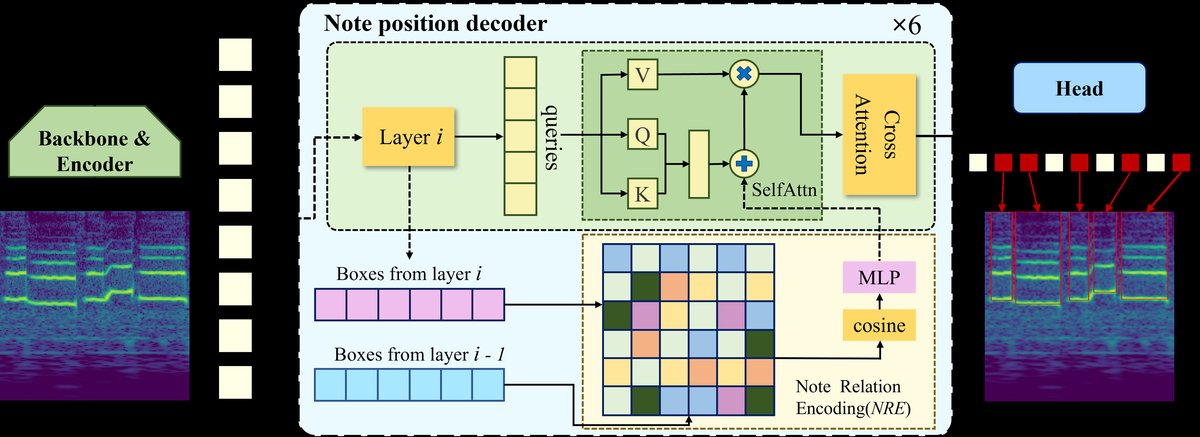 图3:(a) VFL损失函数可视化。(b) QML损失函数可视化。QML对“高置信度但低IoU”的样本施加更高惩罚。
图3:(a) VFL损失函数可视化。(b) QML损失函数可视化。QML对“高置信度但低IoU”的样本施加更高惩罚。
⚖️ 评分理由
- 学术质量(6.5/7):创新性强,将先进的视觉对象检测框架DETR成功移植并深度改造应用于AST领域,三个核心组件各有明确动机和实效。实验设计全面,在多个基准上均取得SOTA,消融研究扎实,结论可信。技术细节描述清晰,但在模型具体配置和部分训练超参数的透明性上略有欠缺。
- 选题价值(1.5/2):AST是音乐理解的重要环节,具有稳定的学术研究和应用价值。本文成果推动了该领域的技术进步,对音乐信息检索社区的从业者和研究者有直接参考意义。任务本身相对垂直,故未给满分。
- 开源与复现加成(0.5/1):提供了完整的代码仓库链接和扩展的数据集,这是极大的复现支持。但未提供模型权重和完整的训练配置文件(如超参数、环境配置),因此加成中等。