📄 MuseTok: Symbolic Music Tokenization for Generation and Semantic Understanding
#音乐生成 #音乐理解 #预训练 #数据集
🔥 8.5/10 | 前25% | #音乐生成 | #预训练 | #音乐理解 #数据集
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Jingyue Huang(University of California San Diego, USA)
- 通讯作者:未说明
- 作者列表:Jingyue Huang(University of California San Diego, USA)、Zachary Novack(University of California San Diego, USA)、Phillip Long(University of California San Diego, USA)、Yupeng Hou(University of California San Diego, USA)、Ke Chen(University of California San Diego, USA)、Taylor Berg-Kirkpatrick(University of California San Diego, USA)、Julian McAuley(University of California San Diego, USA)
💡 毒舌点评
本文首次尝试为符号音乐构建一个“通用”的离散表示学习框架,并通过生成和多个语义理解任务进行了验证,这种“一体两面”的评估视角比多数只关注单一任务的工作更为全面。然而,其在核心的旋律提取任务上表现远低于专用模型(81.92% vs. 92.62%),暴露了当前“通用”表示在捕获细粒度、关键音乐结构上的根本局限,说明“通用”与“专用”之间的鸿沟依然显著。
🔗 开源详情
- 代码:提供GitHub仓库链接(https://github.com/Yuer867/MuseTok)。
- 模型权重:论���中提及提供检查点(checkpoints),但未明确说明是否与代码一同开源。未明确提及模型权重是否公开。
- 数据集:使用公开数据集(PDMX, POP909, EMOPIA等),并说明了数据获取和预处理方式。
- Demo:提供在线演示网站(https://musetok.github.io/)。
- 复现材料:提供了详细的训练超参数、模型架构配置、评估指标和训练硬件信息。
- 论文中引用的开源项目:论文中提及并引用了SimVQ和旋转技巧(Rotation Trick)的相关工作。
📌 核心摘要
解决的问题:当前离散表示学习在图像、语音和语言领域成果显著,但在符号音乐领域发展滞后,缺乏一种能同时支持音乐生成和多维度语义理解的通用表示方法。
方法核心:提出MuseTok,采用基于残差向量量化变分自编码器(RQ-VAE)的编码器-解码器框架,在Transformer架构下对小节(bar)级别的音乐片段进行离散化编码,生成多层级的音乐代码(codes)。
创新之处:这是首个针对符号音乐的通用离散表示学习框架,其创新在于将RQ-VAE应用于音乐小节,并证明了单一表示在生成、旋律提取、和弦识别、情感识别等多个任务上的有效性,同时揭示了不同代码层对不同音乐概念(如节奏、音高)的隐式分离能力。
主要实验结果:
- 重建性能:MuseTok-Large在单声部、合唱和多声部音乐上的重建准确率分别达到99.58%、93.71%和82.68%,接近或超越VAE上界。
- 音乐生成:在音乐续写任务中,MuseTok在客观指标(色度相似度、律动相似度)上优于REMI和AMT基线,但在主观“音高”评分上落后。
- 语义理解:在情感识别任务上显著超越所有基线(78.95% vs. 最高73.15%),在和弦识别上也表现最佳(49.87% vs. 38.03%),但在旋律提取任务上表现最差(81.92% vs. 最高92.62%)。
任务/模型 MuseTok REMI / RNN MusicBERT / AMT PianoBART / MIDI-BERT 音乐生成 (Objective) 色度相似度 (simchr) 95.19 94.61 94.72 - 律动相似度 (simgrv) 88.77 87.41 84.08 - 语义理解 (Accuracy %) 旋律提取 81.92 89.98 92.47 92.62 和弦识别 49.87 38.03 - - 情感识别 78.95 53.46 71.06 73.15 实际意义:该工作为符号音乐领域提供了一种统一的、数据驱动的离散表示学习范式,有望推动音乐AI在生成、检索、理解等多个下游任务上的协同发展。
主要局限性:模型在旋律提取任务上表现不佳,表明其学习到的通用表示未能充分编码旋律相关的细粒度语义信息;同时,固定深度的量化方案可能对不同复杂度的音乐(如简单单声部)不够自适应。
🏗️ 模型架构
MuseTok的整体架构如图1所示,包含一个核心的音乐编码器,以及两个下游任务(生成和理解)的分支。
- 核心编码器(Tokenization Model):
- 输入:符号音乐(如MIDI)首先被转换为REMI+序列表示,该序列按小节(bar)分割,即
X = {X_1, ..., X_B}。 - 编码器:一个Transformer编码器(
P_ϵ)处理每个小节,生成潜在嵌入z_1, ..., z_B。 - 残差量化(RQ):这是核心离散化步骤。对于每个小节嵌入
z_b,通过D个连续的码本(codebook)C_1, ..., C_D进行量化。首先在C_1中找到与z_b最近的嵌入r_1^b,得到第一个代码c_1^b。然后计算残差z_b - r_1^b,并在C_2中量化此残差,以此类推。最终,z_b被表示为D个代码(c_1^b, ..., c_D^b)和其对应的嵌入之和r_b = Σ r_d^b。 - 解码器:一个Transformer解码器(
P_δ)以自回归方式,基于所有小节的聚合嵌入{r_b}来重建原始音乐事件序列X。训练目标是重建损失的负对数似然L_recon和用于提升码本利用率的承诺损失L_commit(采用SimVQ和旋转技巧)之和。
- 音乐生成任务分支:
- 采用两阶段生成。第一阶段,一个独立的Transformer生成器(
P_γ)学习预测由冻结的编码器产生的代码序列c_1^1, ..., c_D^B。 - 推理时,
P_γ先生成代码序列(代表高层音乐结构),然后由冻结的解码器P_δ将这些代码转换为详细的REMI+事件序列(细粒度音乐细节)。
- 音乐理解任务分支:
- 利用已训练好的编码器生成的代码嵌入
r_b作为条件或输入,连接简单的分类器(如Transformer或MLP)来完成下游任务。 - 旋律提取:以每个事件所在小节的代码嵌入
r_b为条件,分类器预测该音符属于人声旋律、器乐旋律或伴奏。 - 和弦识别:以每个小节的代码嵌入
r_b为条件,分类器预测该小节每个拍的和弦标签。 - 情感识别:将整首歌所有小节的代码嵌入序列
r_1, ..., r_B作为输入,分类器预测歌曲的情感类别。
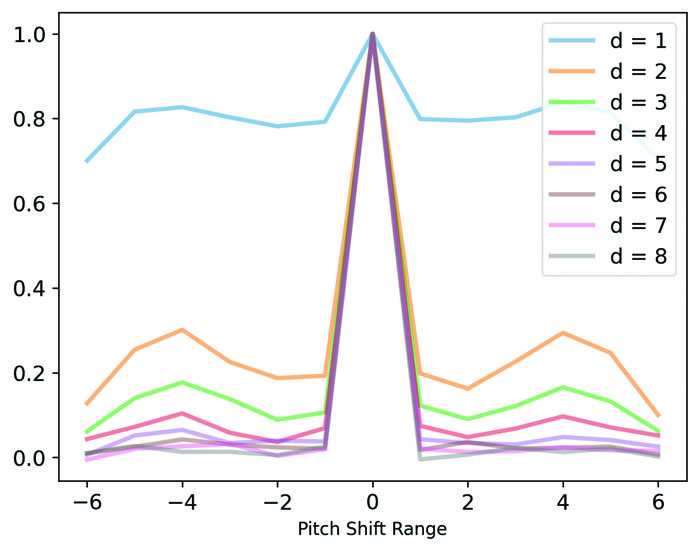 图1展示了MuseTok的整体流程。左侧是基于RQ-VAE的音乐标记化核心模块:Transformer编码器处理小节级REMI+序列,通过残差量化得到离散代码和嵌入,再由Transformer解码器重建音乐。中间和右侧展示了两个下游应用:音乐生成(中)使用另一个Transformer解码器预测代码序列,再解码为音乐事件;音乐理解(右)使用代码嵌入作为条件或输入,连接分类器完成旋律提取、和弦识别和情感识别任务。
图1展示了MuseTok的整体流程。左侧是基于RQ-VAE的音乐标记化核心模块:Transformer编码器处理小节级REMI+序列,通过残差量化得到离散代码和嵌入,再由Transformer解码器重建音乐。中间和右侧展示了两个下游应用:音乐生成(中)使用另一个Transformer解码器预测代码序列,再解码为音乐事件;音乐理解(右)使用代码嵌入作为条件或输入,连接分类器完成旋律提取、和弦识别和情感识别任务。
💡 核心创新点
- 首个通用符号音乐离散表示框架:不同于以往针对特定任务(如风格迁移、可控生成)的离散表示工作,MuseTok旨在学习一种通用的符号音乐表示,能同时服务于生成和多维度的语义理解任务,填补了该领域的空白。
- 基于小节的分层语义学习:创新性地将RQ-VAE应用于音乐的“小节”这一自然结构单元进行量化。分析表明,不同的量化层级(codebook)能够隐式地分离不同粒度的音乐信息(如早期层捕获节奏等跨调性信息,深层层捕获绝对音高信息),实现了无监督的语义分层。
- 在“生成”与“理解”任务间的有效性验证:通过在音乐续写(生成)、旋律提取、和弦识别和情感识别(理解)等一系列任务上的全面评估,证明了所学表示的优越性,特别是在情感识别(+5.8%)和和弦识别(+11.84%)上超越了专用基线模型,展示了其强大的语义捕获能力。
🔬 细节详述
- 训练数据:
- 来源:大规模公共领域数据集PDMX,以及六个小型数据集(POP909, EMOPIA, Pop1k7, Hymnal, Multipianomide, Ragtime)。
- 规模:预处理后得到195,187个序列,其中单声部占83.7%,合唱13.1%,多声部3.2%。
- 预处理:移除速度和力度信息以聚焦结构与和声;将音符起始时间和时长量化到标准乐谱位置;按时间签名分段;所有数据编码为REMI+序列(词汇表大小140)。
- 数据增强:训练时使用随机移调(±6个半音);对合唱和多声部样本上采样以平衡纹理组。
- 损失函数:
L_recon:重建损失,即解码器预测下一个音乐事件的负对数似然。L_commit:承诺损失,鼓励编码器输出稳定在码本嵌入附近,使用SimVQ的线性变换W^d和停止梯度操作。- 总损失:
L = L_recon + L_commit。
- 训练策略:
- 优化器:Adam,学习率1e-4,带200步warm-up。
- 训练步数/轮数:编码器在单张RTX A6000上训练约45k步收敛;生成器训练约200k步(约4天)。
- 其他:码本通过指数移动平均更新。
- 关键超参数:
- MuseTok-Small:量化深度
D=8,每个码本大小K=1024,嵌入维度128。 - MuseTok-Large:
D=16,K=2048,嵌入维度未明确说明(推测与Small一致或更大)。 - 编码器/解码器:12层Transformer,8头,隐藏维度512。
- 生成器:12层Transformer,16头,隐藏维度1024,参数量152M。
- MuseTok-Small:量化深度
- 训练硬件:单张NVIDIA RTX A6000。
- 推理细节:
- 音乐生成:使用核采样(nucleus sampling,温度τ=1.1,概率p=0.9)和top-k采样(k=30)。
- 输入序列长度:编码器训练使用16小节序列;生成器训练使用长度为256的代码序列。
- 正则化或稳定训练技巧:采用了SimVQ和旋转技巧来改善码本坍塌问题,提升码本利用率(从87.77%提升到99.58%)和重建质量。
📊 实验结果
重建性能分析(表1): MuseTok-Large在三个纹理组上的重建准确率(Acc)和码本利用率(Util)均表现最佳,尤其在多声部音乐(poly.)上相比Small版本有显著提升。消融实验表明,SimVQ和旋转技巧对提升码本利用率(从87.77%到99.58%)和重建质量至关重要。仅使用PDMX数据训练会降低在合唱组上的准确率,证明了多源数据平衡训练的有效性。
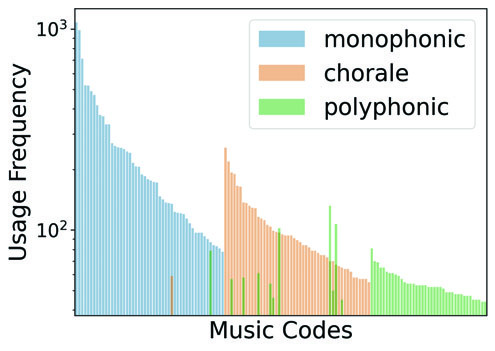 图2(对应论文中图2)展示了MuseTok-Small模型在不同条件下的Top-50最常用代码分布。(a)和(b)显示在第一个和最后一个码本(d=1, d=8)中,单声部(mono.)、合唱(chora.)和多声部(poly.)三组音乐使用的代码集合有显著差异,表明模型对不同音乐纹理有区分性表示。(c)和(d)显示在六个不同时间记号(time signature)下,第一个码本使用的代码几乎相同,而最后一个码本的代码分布差异较大,表明早期码本捕捉跨时间记号的共性信息,深层码本则捕捉更具体的信息。
图2(对应论文中图2)展示了MuseTok-Small模型在不同条件下的Top-50最常用代码分布。(a)和(b)显示在第一个和最后一个码本(d=1, d=8)中,单声部(mono.)、合唱(chora.)和多声部(poly.)三组音乐使用的代码集合有显著差异,表明模型对不同音乐纹理有区分性表示。(c)和(d)显示在六个不同时间记号(time signature)下,第一个码本使用的代码几乎相同,而最后一个码本的代码分布差异较大,表明早期码本捕捉跨时间记号的共性信息,深层码本则捕捉更具体的信息。
音乐生成结果(表2): 在客观指标上,MuseTok在色度相似度和律动相似度上均优于REMI和AMT基线,表明其在和声与节奏续写上的优势。主观听测中,MuseTok在“结构”和“发展”方面与REMI持平或略优,但在“音高”和“和声”方面得分较低,表明其生成的旋律可能存在更多走调音符。
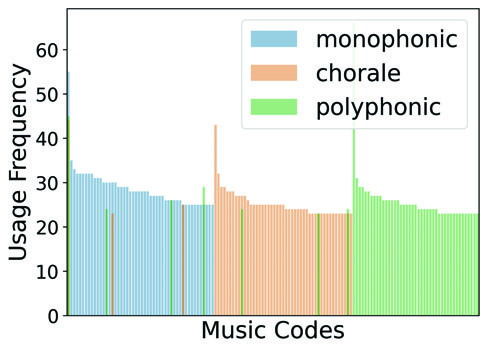 图3(对应论文中图3)展示了代码嵌入在音高移位(key transposition)下的余弦相似度分析。横轴是半音移位量,纵轴是原始样本与移位样本代码嵌入的余弦相似度。不同颜色的线代表不同深度的码本(d=1到d=8)。结果显示:1)第一个码本(d=1)的嵌入在各种移位下保持高度相似(>70%),而更深码本的相似度下降,表明早期码本主要编码移不变信息(如节奏、相对旋律轮廓),深层码本编码绝对音高信息。2)相似度峰值出现在±4(大三度)和±5(纯四度)半音处,与这些音程在音乐中的常见性相符。
图3(对应论文中图3)展示了代码嵌入在音高移位(key transposition)下的余弦相似度分析。横轴是半音移位量,纵轴是原始样本与移位样本代码嵌入的余弦相似度。不同颜色的线代表不同深度的码本(d=1到d=8)。结果显示:1)第一个码本(d=1)的嵌入在各种移位下保持高度相似(>70%),而更深码本的相似度下降,表明早期码本主要编码移不变信息(如节奏、相对旋律轮廓),深层码本编码绝对音高信息。2)相似度峰值出现在±4(大三度)和±5(纯四度)半音处,与这些音程在音乐中的常见性相符。
语义理解结果(表3): MuseTok在情感识别和和弦识别任务上大幅超越所有基线,展现了其捕捉歌曲级情感语义和和声信息的强大能力。然而,在旋律提取任务上,MuseTok(81.92%)表现最差,落后专用模型(如PianoBART 92.62%)超过10个百分点,这与其生成时“音高”表现不佳的发现相互印证。
⚖️ 评分理由
- 学术质量:6.0/7 - 创新性较强,提出了通用框架并进行了多任务验证;技术路线正确,RQ-VAE的应用合理;实验充分,涵盖了重建、生成和多个理解任务,并提供了深入的定性分析(如代码使用频率、嵌入相似度);证据可信,有消融实验支持关键设计选择。主要扣分点在于旋律提取任务表现不佳,暴露了模型在细粒度音乐结构建模上的短板。
- 选题价值:1.5/2 - 选题具有前沿性,符号音乐的通用表示学习是当前热点;潜在影响较大,有望统一音乐AI的不同任务范式;实际应用空间明确,可用于音乐生成、检索、理解等;与音频/音乐领域读者高度相关。但符号音乐本身相对于语音、自然音频处理仍是相对小众的子领域。
- 开源与复现加成:0.8/1 - 论文提供了完整的代码仓库(GitHub)和在线演示网站(项目主页),公开了模型检查点;数据集信息明确;训练细节(超参数、硬件、优化器)描述详尽;使用了公开的基准数据集和评估指标。复现难度较低。