📄 Multimodal Self-Attention Network with Temporal Alignment for Audio-Visual Emotion Recognition
#语音情感识别 #多模态模型 #跨模态 #音视频
🔥 8.0/10 | 前25% | #语音情感识别 | #多模态模型 | #跨模态 #音视频
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Inyong Koo(韩国科学技术院 电气工程学院)
- 通讯作者:未说明
- 作者列表:Inyong Koo(韩国科学技术院 电气工程学院)、Yeeun Seong(韩国科学技术院 绿色增长与可持续发展研究生院)、Minseok Son(韩国科学技术院 电气工程学院)、Jaehyuk Jang(韩国科学技术院 电气工程学院)、Changick Kim(韩国科学技术院 电气工程学院)
💡 毒舌点评
本文巧妙地将多模态融合中的“帧率错位”这一棘手工程问题,转化为位置编码设计问题(TaRoPE)并辅以一个显式的跨时间匹配损失(CTM),思路清晰且有效;但实验仅在CREMA-D和RAVDESS这两个规模相对有限且场景较“干净”的数据集上验证,其泛化能力至更复杂、更“野生”的场景尚待考察。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开发布的模型权重。
- 数据集:使用了CREMA-D和RAVDESS公开数据集,论文中提供了获取指引(参考文献[14][15])。
- Demo:未提及在线演示。
- 复现材料:论文详细给出了优化器、学习率、batch size、epoch数、损失函数权重(λ_ctm)以及关键模型维度(d_model, d_emb)等超参数,为复现提供了较好的基础。
- 论文中引用的开源项目:论文依赖并提到了两个主要开源工具/模型:xlsr-Wav2Vec 2.0 [16](用于音频特征提取)和OpenFace [18](用于视频AU特征提取)。
- 整体开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:现有的音视频情感识别(AVER)方法在融合多模态特征时,常忽略音频与视频信号固有的帧率差异(如50FPS vs 30FPS),导致时间上对齐的特征未能同步,影响细粒度情感线索的捕捉和跨模态融合效果。
- 方法核心:提出一个基于Transformer的统一框架,其核心是“时间对齐”。具体包括:a) TaRoPE:一种改进的旋转位置编码,通过为不同模态设置与其帧率相关的旋转角度,隐式地在注意力计算中同步异步的音频-视频序列;b) CTM损失:一种跨时间匹配损失,利用时间高斯亲和度显式地鼓励在物理时间上邻近的音频和视频帧拥有相似的表示。
- 创新点:与之前仅依赖帧级注意力或忽略帧率问题的融合方法相比,本文首次系统性地在Transformer架构中,通过改进位置编码和引入辅助损失,直接且显式地建模和解决了多模态间的帧率不匹配问题,实现了更精准的时间对齐。
- 实验结果:在CREMA-D和RAVDESS两个基准数据集上,该方法分别取得了89.49%和89.25%的准确率,超越了所有近期强基线方法,树立了新的SOTA。消融实验表明,统一的多模态自注意力(MSA)块比堆叠的单模态/跨模态注意力更高效,且TaRoPE和CTM损失均带来了显著且一致的性能提升。
- 实际意义:该工作通过提升音视频情感识别的准确性,对改善人机交互体验(如智能客服、虚拟助手)和情感智能分析具有积极意义。其提出的时间对齐思路对其他需要融合异步多模态信号的任务(如语音-动作识别)也有启发。
- 主要局限性:1) 实验仅在受控实验室环境下录制的数据集上进行,对复杂真实场景的鲁棒性未知;2) 视频特征依赖于预计算的AU特征,可能无法充分利用原始视频中的高级视觉信息;3) 论文未提供代码和模型权重。
🏗️ 模型架构
 如图1所示,整体框架是一个端到端的Transformer编码器,用于音视频情感分类。其完整流程如下:
如图1所示,整体框架是一个端到端的Transformer编码器,用于音视频情感分类。其完整流程如下:
- 特征提取:
- 音频流:原始音频(16kHz)通过预训练的xlsr-Wav2Vec 2.0编码器,提取1024维帧级嵌入。由于内部320倍下采样,其有效帧率为ηa = 50 FPS。
- 视频流:视频帧通过OpenFace库提取35维面部动作单元(AU)特征描述符,其帧率为ηv = 30 FPS。
- 投影与对齐准备:音频和视频特征分别通过线性层投影到d_model=512维的共享嵌入空间,形成序列 Fa 和 Fv。
- 统一Transformer编码器:
- 两个模态的Token序列在序列维度上拼接,形成一个统一的Token序列。
- 该序列输入一个包含两层多头自注意力(MHA)的Transformer编码器。核心创新点TaRoPE被集成在每个MHA层中。它为来自不同模态的查询(Q)和键(K)向量应用不同的旋转角度:音频Token的旋转角度基于其索引n乘以θa,视频Token的旋转角度基于其索引m乘以θv = (ηa/ηv) * θa。通过这种角度调制,使得在计算注意力分数时,两个模态的Token位置被隐式地映射到一个统一的、以音频帧率(50 FPS)为基准的时间轴上,从而实现时间对齐。
- 输出与分类:Transformer编码器的输出经过时间平均池化,得到整个语音段(utterance)的表示,最后通过一个softmax分类器预测情感标签。
TaRoPE的工作原理:标准RoPE通过旋转位置编码将绝对位置信息转化为相对位置信息。TaRoPE的改进在于,它认识到不同模态的“单位Token”对应不同的实际时间间隔。因此,通过调整旋转角度的频率(θ),使得旋转操作本身携带了模态的时间尺度信息。当计算音频Token和视频Token之间的注意力分数时,这种角度调制确保了“位置距离”在物理时间上是可比的。
CTM损失的作用:在Transformer编码器之前,音频和视频特征被投影到一个L2归一化的d_emb=128维空间。CTM损失计算这个空间中,音频和视频帧之间基于特征相似度(s_ij)和基于时间高斯亲和度(g_ij)的分布之间的交叉熵。其目标是,如果两个音频和视频帧在物理时间上接近(g_ij大),那么它们的特征表示也应该相似(s_ij大)。这作为一个显式的监督信号,引导模型学习时间上对齐的多模态表示。
💡 核心创新点
- 时序对齐旋转位置编码(TaRoPE):
- 是什么:一种针对多模态Transformer的位置编码方法,为不同帧率的模态分配不同的旋转频率。
- 局限:传统位置编码(正弦、可学习、原生RoPE)为所有模态使用相同的编码,忽略了它们采样率不同的事实,导致跨模态注意力计算时时间步长无法对应。
- 如何起作用:通过设置 θ_video = (音频帧率/视频帧率) * θ_audio,在旋转操作中隐式缩放了视频的位置编码,使得音频和视频的Token序列在注意力机制中对齐到同一个虚拟时间轴。
- 收益:消融实验(表3)显示,TaRoPE在不加CTM损失的情况下就能将准确率从RoPE的87.76%提升至88.95%,证明了其在隐式时间对齐上的有效性。
- 跨时间匹配损失(CTM Loss):
- 是什么:一个显式的辅助损失函数,利用时间高斯亲和度作为监督信号,强制时间上接近的音频-视频帧特征相似。
- 局限:仅靠Transformer的自注意力进行跨模态融合,缺乏对齐的显式监督,模型可能学到错误或不稳定的对齐关系。
- 如何起作用:构建以时间差为基础的软目标分布(q),与基于特征相似度的预测分布(p)计算双向交叉熵损失。这鼓励模型学习一种跨模态表示空间,其中时间连续性得以保持。
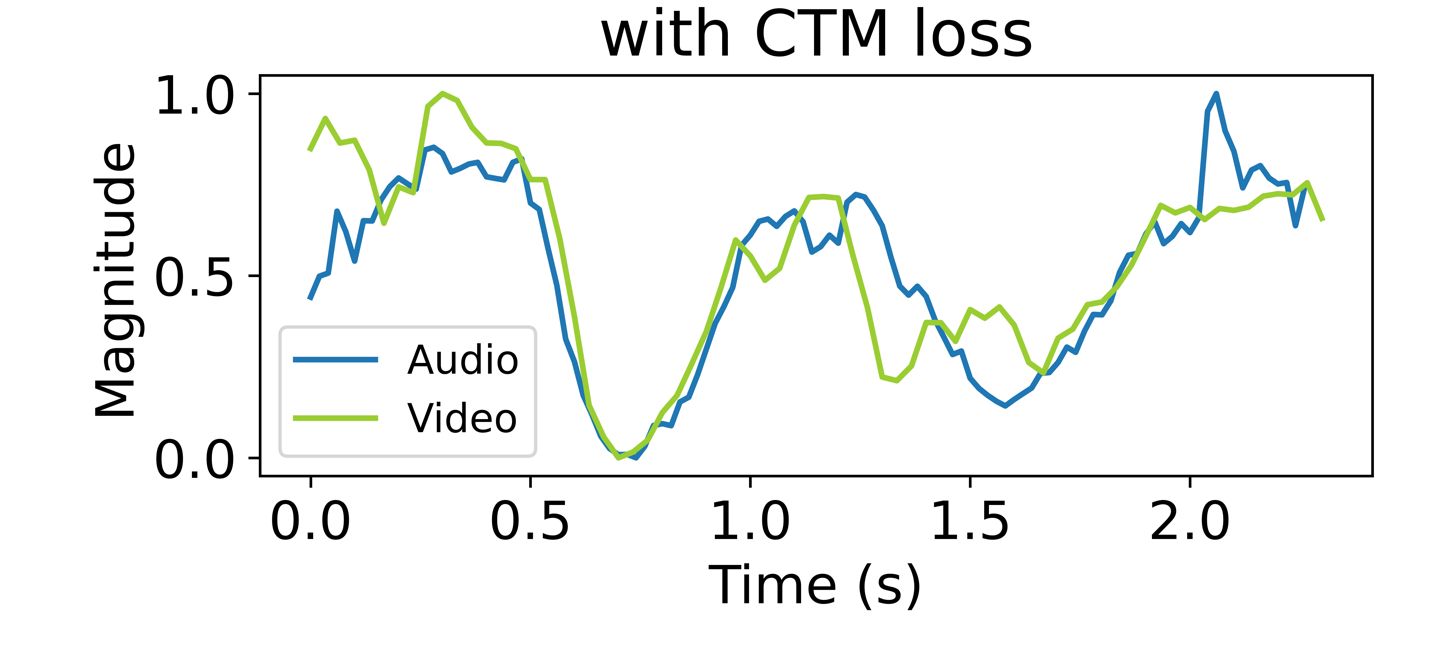
- 收益:表3显示,在任何位置编码基础上加入CTM损失都能带来0.5%-1.3%的准确率提升,证实了其作为补充对齐目标的价值。图3进一步从特征动态和导数符号一致性方面,直观展示了CTM损失能增强跨模态的时间同步性。
- 多模态自注意力(MSA)融合架构:
- 是什么:将音频和视频Token放入同一个Transformer块中,使用统一的自注意力机制进行处理。
- 局限:先前方法常使用分别的模态内自注意力(ISA)或模态间交叉注意力(ICA),或两者的堆叠,这可能导致建模效率低下或依赖顺序。
- 如何起作用:MSA在单个注意力层内同时捕获模态内(音频-音频、视频-视频)和模态间(音频-视频)的依赖关系。
- 收益:消融实验(表2)表明,两个MSA层的配置(88.95%)以更少的参数(6.83M vs 12.61M)取得了比ISA+ICA、ICA+ISA等堆叠方案更好的效果,体现了其建模效率和能力。
🔬 细节详述
- 训练数据:
- CREMA-D:7,442个短句片段,91位演员,6种基本情感。使用论文[19]提供的说话人独立划分。
- RAVDESS:1,440个语音段,24位专业演员,8种情感。采用论文[2]中的说话人独立5折交叉验证。
- 数据增强:论文中未提及具体的数据增强策略。
- 损失函数:总损失为
L_total = L_cls + λ_ctm * L_ctm。其中L_cls是标准的交叉熵分类损失;L_ctm是双向的跨时间匹配损失(公式9-11);λ_ctm = 0.5是损失权重。 - 训练策略:
- 优化器:AdamW
- 初始学习率:5e-5
- 学习率调度:线性衰减至0
- Batch size:4
- 训练轮数(Epochs):50
- 关键超参数:
- Transformer编码器维度 d_model = 512
- 投影后的嵌入维度 d_emb = 128
- TaRoPE中的基础频率(论文未给出具体值,但通过θa和θv的关系隐含)
- CTM损失高斯带宽 σ = 0.5
- CTM损失温度 τ = 0.07
- CTM损失权重 λ_ctm = 0.5
- 训练硬件:论文中未说明GPU型号、数量及训练时长。
- 推理细节:论文中未提及推理时的解码策略(如束搜索等),对于分类任务,通常直接取softmax输出的最大值作为预测。
- 正则化:除了CTM损失作为隐式正则化外,未提及其他如Dropout等技术细节。
📊 实验结果
论文在CREMA-D和RAVDESS两个数据集上进行了性能比较和消融研究。
- 与当前最佳方法的比较
| 方法 | 年份 | CREMA-D准确率(%) | RAVDESS准确率(%) |
|---|---|---|---|
| TA-AVN [4] | 2021 | 84.00 | 78.70 |
| Mocanu et al. [8] | 2023 | 84.57 | 87.85 |
| Lei et al. [3] | 2023 | 85.06 | - |
| HiCMAE [9] | 2024 | 84.91 | 87.96 |
| ATTSF-Net [12] | 2025 | - | 88.67 |
| 本文方法 | 2025 | 89.49 | 89.25 |
结论:本文方法在两个数据集上均取得了最优性能。在CREMA-D上,相比之前最佳方法(85.06%)提升了4.43个百分点;在RAVDESS上,相比ATTSF-Net(88.67%)提升了0.58个百分点。
- 融合策略消融研究(CREMA-D数据集)
| 融合模块 | 参数量 | 准确率(%) |
|---|---|---|
| Concat. | - | 85.71 |
| ISA + ISA | 12.61M | 87.98 |
| ICA + ICA | - | 87.49 |
| ISA + ICA | - | 87.71 |
| ICA + ISA | - | 88.31 |
| MSA + MSA (Ours) | 6.83M | 88.95 |
 结论:图2直观展示了不同的融合策略。统一的多模态自注意力(MSA)方案(图2c)以更少的参数取得了最佳效果,证明了在共享编码器中联合建模模态内和模态间依赖的优越性。
结论:图2直观展示了不同的融合策略。统一的多模态自注意力(MSA)方案(图2c)以更少的参数取得了最佳效果,证明了在共享编码器中联合建模模态内和模态间依赖的优越性。
- 位置编码与CTM损失消融研究(CREMA-D数据集)
| 位置编码 | 无L_ctm准确率(%) | 有L_ctm准确率(%) |
|---|---|---|
| Sinusoidal | 88.09 | 88.79 |
| Learnable | 87.44 | 88.79 |
| RoPE | 87.76 | 89.00 |
| TaRoPE | 88.95 | 89.49 |
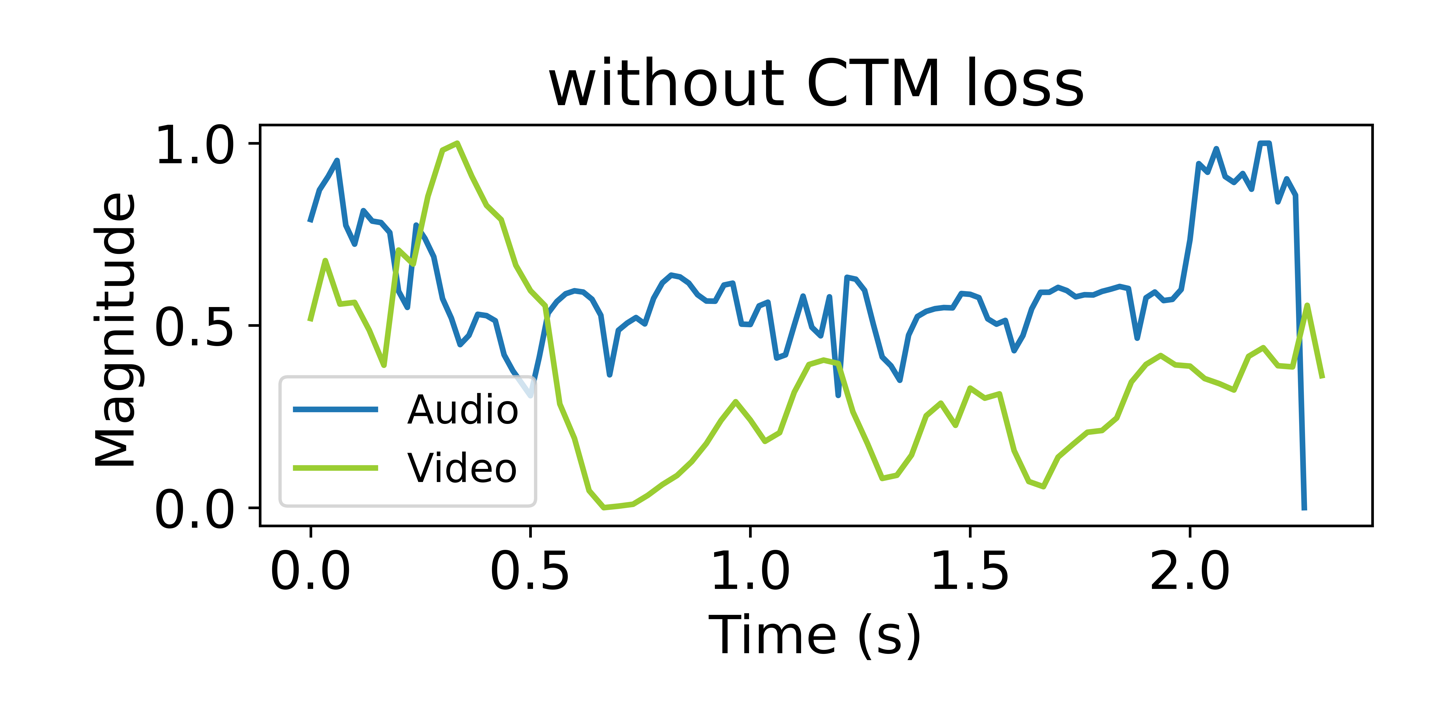 结论:表3表明,TaRoPE作为位置编码基础时性能最优,且加入CTM损失后达到最高分。图3(a)展示了一个具体样本,加入CTM损失后,音频和视频特征幅值的曲线在时间轴上更加同步。图3(b)的导数符号一致性分布图则表明,CTM损失使测试集上更多样本的跨模态动态趋势保持一致。
结论:表3表明,TaRoPE作为位置编码基础时性能最优,且加入CTM损失后达到最高分。图3(a)展示了一个具体样本,加入CTM损失后,音频和视频特征幅值的曲线在时间轴上更加同步。图3(b)的导数符号一致性分布图则表明,CTM损失使测试集上更多样本的跨模态动态趋势保持一致。
⚖️ 评分理由
- 学术质量:6.5/7。论文技术方案完整且逻辑自洽,创新点(TaRoPE, CTM)针对明确问题且设计巧妙。实验部分在标准benchmark上进行了充分的对比和消融,结果可信,支撑了结论。未给满分是因为创新属于“优化与改进”范畴,而非基础原理的突破。
- 选题价值:1.5/2。音视频情感识别是情感计算领域的重要任务,有明确的应用场景。论文聚焦于“时间对齐”这一关键但常被忽略的技术瓶颈,具有较好的理论和实用价值。得分1.5是因为该任务相对垂直,受众面不如通用语音识别或生成模型广泛。
- 开源与复现加成:0/1。论文提供了详细的训练超参数和设置,这是积极的一面。但根据当前信息,未提及代码、预训练模型或标准化复现包的发布计划,因此无法给予加分。