📄 Multimodal Fusion-Based IPCLIP Network for Mixed Reality Surgical Assistance
#多模态模型 #数据增强 #跨模态 #工业应用 #少样本
✅ 6.5/10 | 前50% | #多模态模型 | #数据增强 | #跨模态 #工业应用
学术质量 6.0/7 | 选题价值 2.0/2 | 复现加成 -1.5 | 置信度 中
👥 作者与机构
- 第一作者:Jiahui Sun(济南大学信息科学与工程学院)
- 通讯作者:Tao Xu*(济南大学信息科学与工程学院)
- 作者列表:Jiahui Sun(济南大学信息科学与工程学院)、Tao Xu*(济南大学信息科学与工程学院)、Xiaohui Yang(济南大学信息科学与工程学院)、Tongzhen Si(济南大学信息科学与工程学院)、Xiaoli Liu(济南大学信息科学与工程学院)
💡 毒舌点评
论文在工程集成上做得扎实,成功将一个多模态识别模型与机器人控制、MR显示结合成一个可演示的手术辅助系统,这种端到端的应用思维值得肯定。但所谓的“改进CLIP网络”更像是搭建积木,核心的融合模块与视觉Token裁剪方案缺乏理论深度和新颖性,且关键代码、模型、数据集均未开源,让其创新性打了折扣,也给复现研究设置了高墙。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:ARHands数据集为作者自建,论文未提供公开获取方式。
- Demo:论文展示了系统部署,但未提供在线演示链接。
- 复现材料:给出了部分训练超参数(学习率、batch size、优化器)和数据集划分比例,但缺失训练步数、数据增强细节、完整模型配置等关键信息。
- 论文中引用的开源项目:主要依赖CLIP(作为预训练基础模型)和YOLOv8(用于目标检测,非论文核心模型的一部分)。
📌 核心摘要
- 问题:在混合现实(MR)手术辅助中,需要准确理解医生的多模态指令(如语音、手势),但现有方法在特征融合效率、推理速度和对罕见场景的适应性上存在挑战。
- 方法核心:提出IPCLIP框架,基于CLIP模型,集成了一个结合CNN与Transformer的多模态自适应融合模块(MFF);采用视觉Token裁剪策略进行模型轻量化;并利用DeepSeek生成领域知识库来增强数据,提升少样本场景下的推理能力。
- 创新之处:将针对视觉Token的轻量化策略引入多模态融合模块以加速推理;提出利用大语言模型(DeepSeek)生成并扩展领域特定知识库来增强模型鲁棒性和泛化能力。
- 主要实验结果:在自建的ARHands数据集上,完整模型(CLIP-1)取得91.46% 的准确率。加入视觉Token裁剪后(Lightweight 5),准确率进一步提升至92.22%,同时FLOPs和推理时间降低。在严重图像与文本双重退化下,模型仍能保持83.54% 的准确率,显示了良好的鲁棒性。
- 实际意义:该框架已成功部署到基于Kinova机械臂和HoloLens2的MR手术辅助原型系统中,实现了语音/手势指令控制机械臂抓取和传递手术器械,验证了其在复杂临床环境中的应用潜力。
- 主要局限性:创新性有限,多为已有技术的组合优化;实验仅在自建的、规模相对有限的数据集上进行;未公开代码、模型和数据集,可复现性差;论文部分章节(如第3节公式)表述略显简略。
🏗️ 模型架构
IPCLIP的整体框架(图2)由双模态编码器(DME)、多模态特征融合模块(MFF)和分类头组成。
- 输入:图像和文本。图像经由CLIP的ViT-B/32图像编码器,文本经由CLIP的文本编码器,分别得到视觉特征
Fi和文本特征Ft。 - 多模态特征融合模块(MFF)(图3):
- 跨模态拼接与投影:将
Fi和Ft在通道维度拼接,通过一个线性层(Wp,bp)进行投影对齐,得到Fp。 - 局部特征提取:
Fp通过包含批归一化和激活函数的卷积层,捕捉细粒度的局部空间特征。 - 全局上下文建模:将局部特征输入到一个Transformer编码器中,通过自注意力机制建模模态间的长距离依赖关系。使用了残差连接(公式3)以避免信息丢失。
- 特征精炼:Transformer的输出再次经过卷积和全局平均池化,生成紧凑的判别性特征向量。
- 跨模态拼接与投影:将
- 分类与输出:精炼后的特征通过全连接层进行分类,使用交叉熵损失(公式4)进行优化,输出手势类别。
- 轻量化:在MFF的Transformer模块内部,根据实验在浅层(如第3层)按一定比例(如50%)裁剪掉冗余的视觉Token,以降低计算量、加速推理(图4)。
💡 核心创新点
- 多模态自适应融合模块(MFF):设计了一个结合CNN(局部感知)和Transformer(全局建模)的混合融合架构,旨在克服传统融合方法信息交互不充分的问题。
- 基于LLM的领域知识库增强:利用DeepSeek模型,从专家标注数据中生成语义一致且多样的文本指令,构建三模态对齐(图像-文本-指令)的知识库,以增强模型在少样本、长尾场景下的泛化能力(图1)。
- 面向融合模块的视觉Token裁剪:首次将视觉Token轻量化策略应用于多模态融合模块的Transformer中,通过实验确定最佳裁剪层和比例,在保持甚至略微提升精度的同时,显著降低计算开销和推理时间。
🔬 细节详述
- 训练数据:数据集名为ARHands,是论文作者自建的MR手术手势数据集,包含7个类别,每类约1000张图像,尺寸为224×224像素,均经过人工标注,按8:2划分训练集和验证集。未说明具体的预处理和训练时的数据增强策略(除了使用DeepSeek增强生成的文本数据)。
- 损失函数:标准的交叉熵损失(公式4)。
- 训练策略:学习率0.001,批大小32,使用Adam优化器。未说明训练总轮数、学习率调度策略。
- 关键超参数:基于CLIP的ViT-B/32作为编码器;MFF中投影层维度为512×1024。
- 训练硬件:NVIDIA GeForce RTX 3090 GPU,使用Python和PyTorch。未说明具体训练时长。
- 推理细节:推理在MR辅助机器人臂系统中实时运行,输入来自HoloLens 2和D435i相机捕捉的语音和手势。未说明具体的解码策略、温度等。
- 正则化:MFF模块中使用了批归一化(Batch Normalization)。未说明其他正则化技巧。
📊 实验结果
主要在自建的ARHands数据集上进行验证。
表1. 不同模型配置在ARHands数据集上的性能对比
| Number | 模型结构配置 | 准确率(%) | F1(%) |
|---|---|---|---|
| 1 | CLIP-1(完整IPCLIP) | 91.46 | 91.78 |
| 2 | CLIP-2(无DeepSeek增强) | 85.89 | 86.54 |
| 3 | CLIP-3(无MFF,仅特征拼接) | 88.34 | 88.38 |
| 4 | BLIP | 62.41 | 62.82 |
| 5 | ViLT | 82.76 | 83.13 |
| 6 | Flamingo | 65.74 | 65.92 |
表2. 不同模型轻量化配置(视觉Token裁剪)的性能
| 模型配置 | 裁剪位置 | Token裁剪比例 | 准确率(%) |
|---|---|---|---|
| 原始模型 | - | - | 91.46 |
| Lightweight 1 | 6 | 0.5 | 90.96 |
| Lightweight 2 | 6 | 0.75 | 91.38 |
| Lightweight 3 | 3 | 0.75 | 90.54 |
| Lightweight 4 | 8 | 0.75 | 90.11 |
| Lightweight 5 | 3 | 0.5 | 92.22 |
| Lightweight 6 | 8 | 0.5 | 91.89 |
表3. 模型鲁棒性评估结果
| 实验设置 | 图像(退化程度) | 文本(退化程度) | 准确率(%) | F1(%) | 精确率(%) | 召回率(%) |
|---|---|---|---|---|---|---|
| 原始实验 | - | - | 91.46 | 91.78 | 92.34 | 90.92 |
| 图像退化 | + | - | 90.15 | 90.50 | 91.27 | 90.01 |
| 图像退化 | ++ | - | 84.78 | 85.69 | 87.67 | 84.75 |
| 文本退化 | - | + | 90.47 | 90.11 | 90.85 | 90.87 |
| 文本退化 | - | ++ | 89.66 | 88.56 | 90.48 | 87.84 |
| 图像文本联合退化1 | + | + | 89.32 | 89.09 | 89.88 | 88.57 |
| 图像文本联合退化2 | ++ | ++ | 83.54 | 82.08 | 84.73 | 81.05 |
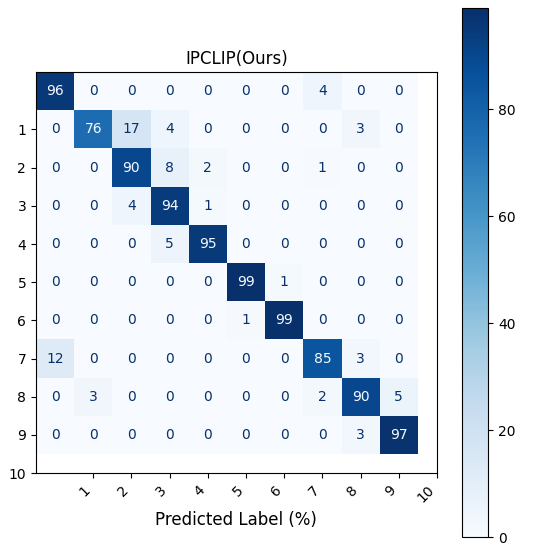 图6显示,Lightweight 5配置(第3层裁剪50%)在准确率略有提升的同时,FLOPs和推理时间相比原始模型有所降低,验证了轻量化策略的有效性。
图6显示,Lightweight 5配置(第3层裁剪50%)在准确率略有提升的同时,FLOPs和推理时间相比原始模型有所降低,验证了轻量化策略的有效性。
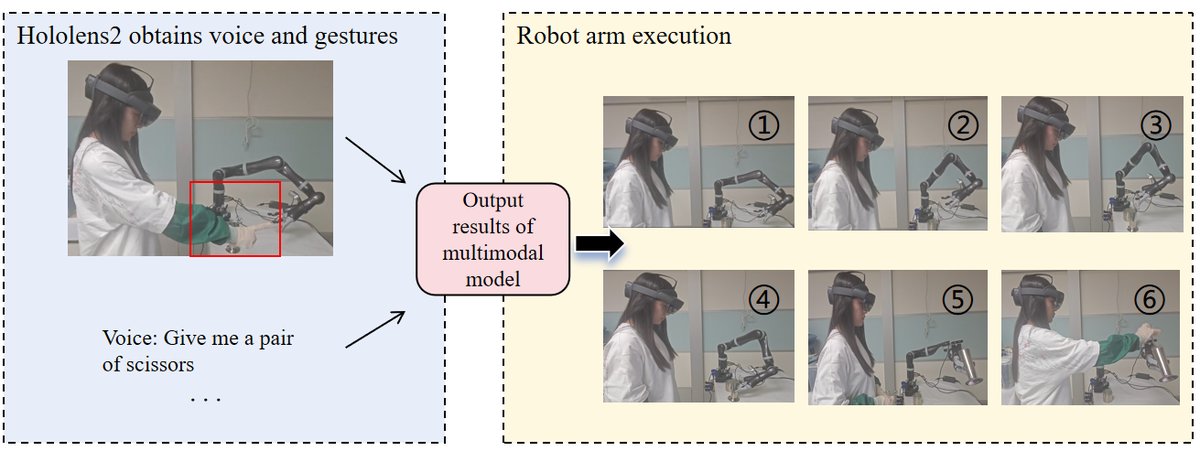 图7的混淆矩阵显示模型在所有7个手势类别上都具有较高的识别准确率,错误主要发生在少数类别间。
图7的混淆矩阵显示模型在所有7个手势类别上都具有较高的识别准确率,错误主要发生在少数类别间。
⚖️ 评分理由
- 学术质量:6.0/7:论文工作完整,包含了问题定义、方案设计、实验验证和系统部署。技术方案合理,实验包含了充分的消融实验(验证MFF和DeepSeek模块的作用)和鲁棒性测试,结果可信。但主要贡献在于对现有模块(CLIP, Transformer, Token裁剪)的应用和整合,核心算法创新有限。
- 选题价值:2.0/2:选题紧密贴合智能医疗和人机交互的前沿方向,将多模态感知、大语言模型知识增强与混合现实手术辅助相结合,具有明确的应用场景和潜在的社会经济效益。
- 开源与复现加成:-1.5/1:这是论文最主要的短板。尽管描述了数据集和部分实验设置,但未提供代码仓库、预训练模型、完整的数据集或详细的复现指南。这使得其他研究者难以验证其结果或在此基础上进行改进,极大地削弱了论文的学术贡献和实用价值。