📄 Multilingual Supervised Pretraining with Lm-Assisted Decoding for Visual Speech Recognition
#语音识别 #预训练 #多语言 #低资源 #迁移学习
✅ 6.5/10 | 前50% | #语音识别 | #预训练 | #多语言 #低资源
学术质量 4.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Mengyang Yu(教育部民族语言智能分析与安全治理重点实验室,中央民族大学)
- 通讯作者:Yue Zhao(教育部民族语言智能分析与安全治理重点实验室,中央民族大学)
- 作者列表:Mengyang Yu(教育部民族语言智能分析与安全治理重点实验室,中央民族大学)、Yue Zhao(教育部民族语言智能分析与安全治理重点实验室,中央民族大学)、Haizhou Li(香港中文大学深圳)
💡 毒舌点评
本文系统性地探索了如何将多语言预训练范式从ASR迁移到低资源VSR任务(藏语),并提供了详实的渐进冻结和预训练顺序的消融实验,这是其扎实之处。然而,其核心创新是将现有的“预训练+微调+LM解码”框架在VSR上复现一遍,缺乏对视觉语言建模更本质的突破,且在普通话上的对比结果(7.6% CER)已被更强的基线(如LipSound2的3.9%)大幅超越,显示其方法的上限可能有限。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:论文中收集的57小时藏语数据集未提及公开获取方式。
- Demo:未提及在线演示。
- 复现材料:论文提供了一些训练细节(如优化器、数据增强、模型组件),但缺少关键超参数(如具体beam size、LM的层数和维度细节),复现信息不完全充分。
- 论文中引用的开源项目:引用了RetinaFace、FAN、SentencePiece等开源工具/模型。
- 总结:论文中未提及任何开源计划。
📌 核心摘要
- 解决的问题:视觉语音识别(VSR)面临目标语言(特别是藏语这类低资源语言)标注数据稀缺以及同音字歧义两大挑战。
- 方法核心:提出一个包含多语言监督预训练与语言模型(LM)辅助解码的VSR流程。首先在高资源语言(英语、葡萄牙语、法语、普通话)上进行序列化预训练,学习语言无关的视素(viseme)表征;然后在目标藏语数据上全量微调;解码时融合外部LM以减少歧义。
- 创新之处:(1)通过渐进冻结实验,验证了视觉前端更倾向于学习语言无关特征,而编码器和解码器更具语言特异性,为多语言预训练提供了理论依据;(2)系统探索了多种辅助语言预训练顺序对最终藏语识别性能的影响;(3)将LM融合有效地应用于VSR解码环节。
- 主要实验结果:在藏语数据集上,多语言预训练将音节错误率(SER)从基线的45.7%降至43.7%,加入LM融合后进一步大幅降至32.0%。在普通话数据集上,该框架取得了7.6%的字错误率(CER)。关键对比结果见下表:
| 方法 | LM | 藏语 SER (%) | 普通话 CER (%) |
|---|---|---|---|
| VSRML [4] | 是 | – | 8.0 |
| LipSound2 [18] | 否 | – | 3.9 |
| Ours (No LM) | 否 | 43.7 | 10.6 |
| Ours (with LM) | 是 | 32.0 | 7.6 |
- 实际意义:为低资源语言的视觉语音识别提供了一种有效的技术方案,证明了通过复用高资源语言知识可以缓解数据稀缺问题。
- 主要局限性:方法依赖于预训练语言的顺序选择,其迁移效果有上限(如普通话CER未达SOTA);收集的藏语数据集规模仍相对有限(57小时),且未开源;整体创新更多是现有技术的组合应用。
🏗️ 模型架构
该论文采用了一个标准的端到端VSR架构,主要由三个组件构成,其数据流与交互如下:
- 视觉前端(Visual Front-end):使用 3D-stem ResNet-18。输入是经过预处理的视频帧序列(96×96灰度图,25fps),负责提取唇部的时空视觉特征。选择ResNet-18是为了在控制模型复杂度的前提下验证多语言迁移的有效性。
- 编码器(Encoder):采用 Conformer 模块。它接收来自视觉前端的特征序列,结合了卷积神经网络的局部特征建模和Transformer的全局自注意力机制,进行更强大的时序上下文建模。
- 解码器(Decoder):使用 Transformer 解码器。基于编码器的输出和目标文本序列,通过自注意力和交叉注意力机制生成词元概率分布。
训练时采用 CTC/Attention混合损失(公式1),权重α在验证集上调整。推理时,解码分数由注意力解码分数、CTC分数和外部LM分数加权融合(公式2)。
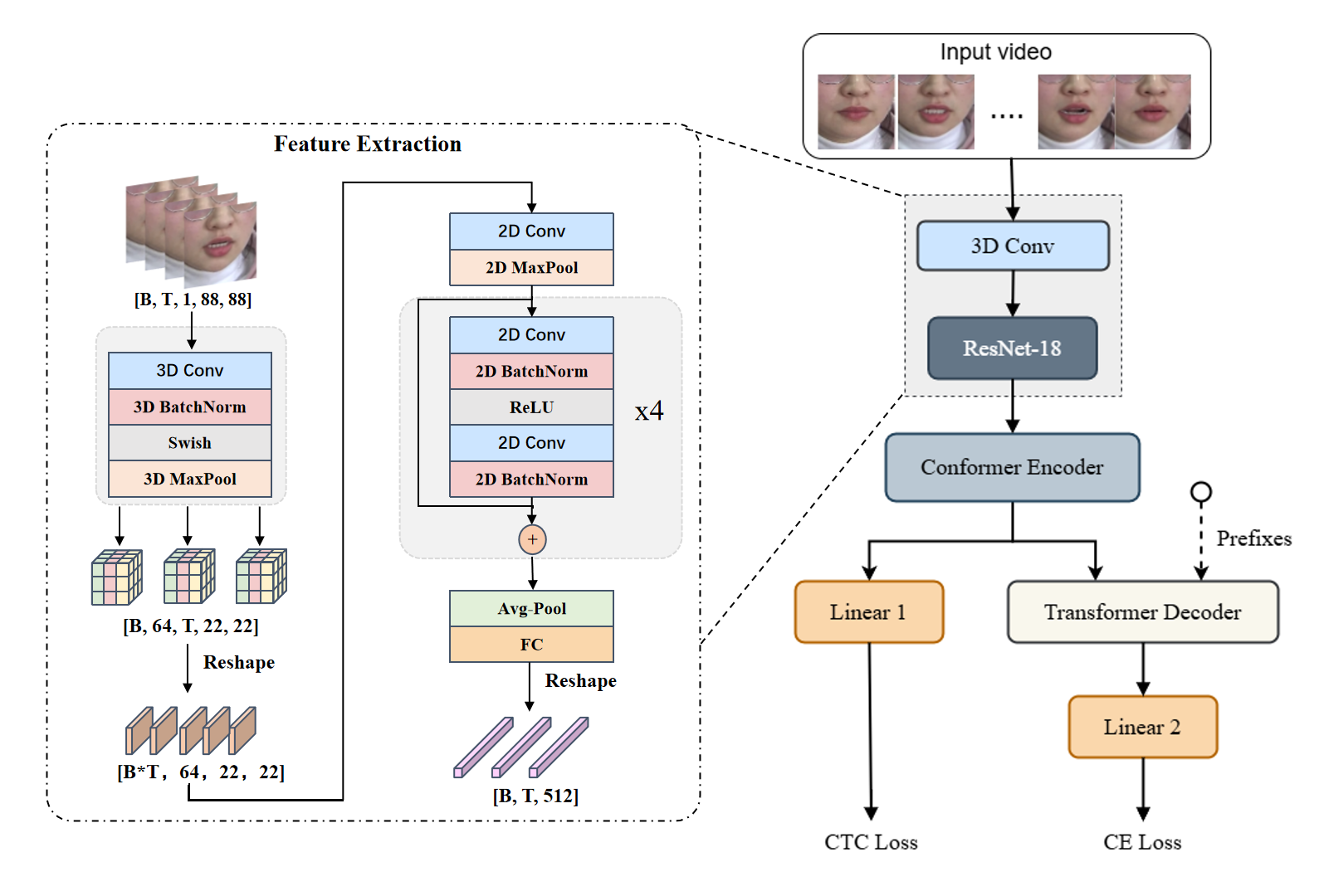 图1展示了整体架构。左侧是处理视频序列的3D-Stem ResNet-18视觉前端,中间是Conformer编码器,右侧是Transformer解码器。训练时,CTC和Attention的损失共同作用于编码器输出和解码器输出。
图1展示了整体架构。左侧是处理视频序列的3D-Stem ResNet-18视觉前端,中间是Conformer编码器,右侧是Transformer解码器。训练时,CTC和Attention的损失共同作用于编码器输出和解码器输出。
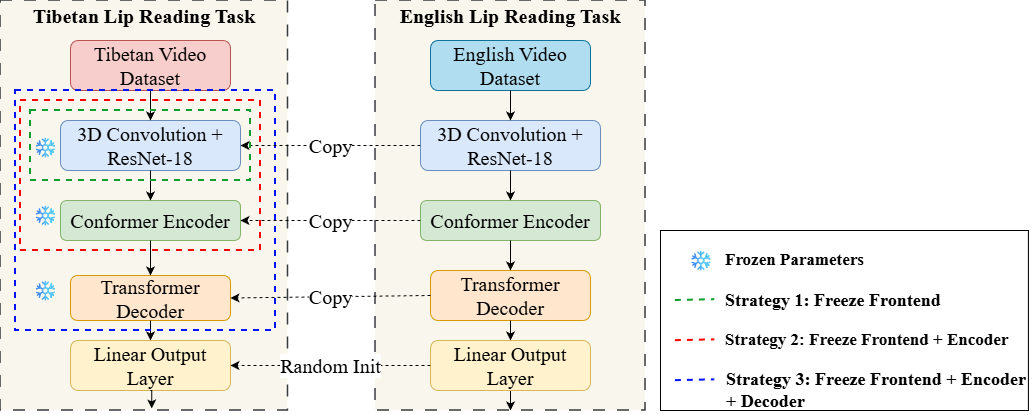 图2说明了用于分析跨语言迁移能力的渐进冻结策略。模型被分为前端、编码器、解码器三个部分,实验中逐步冻结这些部分,以观察其对性能的影响。
图2说明了用于分析跨语言迁移能力的渐进冻结策略。模型被分为前端、编码器、解码器三个部分,实验中逐步冻结这些部分,以观察其对性能的影响。
💡 核心创新点
- 渐进冻结实验验证组件迁移性:通过系统性地冻结模型的不同部分(前端、编码器、解码器)并观察性能变化,实证发现视觉前端学习到的特征更具语言通用性(视素),而更高层的编码器和解码器则更依赖于具体语言。这为使用多语言数据预训练视觉前端提供了直接依据。
- 针对VSR的多语言监督预训练策略:不同于常见的自监督预训练,本文直接在多种有标签的高资源语言上进行监督预训练,旨在让模型学习到一个强大的、语言通用的唇部特征提取器。实验证明,合理的语言预训练顺序(如 En→Pt→Zh→Fr→Ti)能持续提升低资源目标语言(藏语)的性能。
- LM辅助解码应对VSR同音字问题:明确指出VSR中同音字(homophone)歧义是一个关键挑战,并将ASR中常用的外部语言模型浅融合技术引入VSR解码过程。实验显示,LM融合带来了显著的性能提升(藏语SER从43.7%降至32.0%)。
🔬 细节详述
- 训练数据:
- 预训练数据:英语(LRS2/3, AVSpeech, VoxCeleb2)、葡萄牙语和法语(Multilingual TEDx子集)、普通话(CMLR)。英语数据使用伪标签。
- 微调/评估数据:藏语数据集(57小时,25位说话人,手工校对转录)和普通话数据集(CMLR)。
- 预处理:RetinaFace人脸检测 + FAN关键点检测,裁剪96×96灰度唇部ROI。数据增强:随机裁剪到88×88、水平翻转(p=0.5)、时间掩码。
- 损失函数:标准的CTC/Attention混合损失(公式1),其中α是平衡系数。
- 训练策略:优化器AdamW(初始学习率1e-4),混合精度训练,梯度裁剪(5.0),早停。批大小由总帧数限制(训练1200帧/批,验证600帧/批)。解码时使用波束搜索。
- 关键超参数:模型骨干为ResNet-18(参数规模较小);SentencePiece分词器;CTC/Attention权重α、LM融合权重λ和β在验证集上选择。
- 训练硬件:4× NVIDIA RTX 4090 GPU。
- 推理细节:使用波束搜索结合浅融合(公式2),融合权重λ和β在验证集上调整。
- 语言模型:为藏语和普通话单独训练了Transformer LM和2层LSTM LM,使用领域内转录文本。
📊 实验结果
主要性能对比:
| 方法 | LM | 藏语 SER (%) | 普通话 CER (%) |
|---|---|---|---|
| LipCH-Net [27] | 否 | – | 34.1 |
| CSSMCM [22] | 否 | – | 32.5 |
| LIBS [28] | 否 | – | 31.3 |
| CTCH [29] | 否 | – | 22.0 |
| VSRML [4] | 是 | – | 8.0 |
| LipSound2 [18] | 否 | – | 3.9 |
| Ours (No LM) | 否 | 43.7 | 10.6 |
| Ours (with LM) | 是 | 32.0 | 7.6 |
| 注:藏语任务指标为SER,普通话为CER。 |
关键消融实验:
渐进冻结策略影响(见图4及描述):
- 冻结视觉前端,性能小幅下降。
- 冻结编码器或解码器,性能大幅下降。
- 结论:前端更具语言通用性,后端更具语言特异性。
预训练语言顺序影响(无LM):
预训练序列 藏语 SER (%) En →Pt →Zh →Fr →Ti 44.3 En →Pt →Zh →Fr →Ti (最优) 43.7 En →Zh →Fr →Pt →Ti 46.4 En →Zh →Pt →Fr →Ti 44.5 En →Fr →Pt →Zh →Ti 44.0 En →Fr →Zh →Pt →Ti 54.0 En →Ti (仅英语预训练) 45.7 结论:语言顺序对迁移性能有显著影响,最优顺序比仅用英语预训练提升了2.0%的绝对值。 LM辅助解码影响:
解码策略 藏语 SER (%) 普通话 CER (%) No LM 43.7 10.6 + Transformer LM 32.0 8.6 + RNN LM 40.3 7.6 结论:LM融合大幅提升性能,Transformer LM在藏语上更优,RNN LM在普通话上更优。
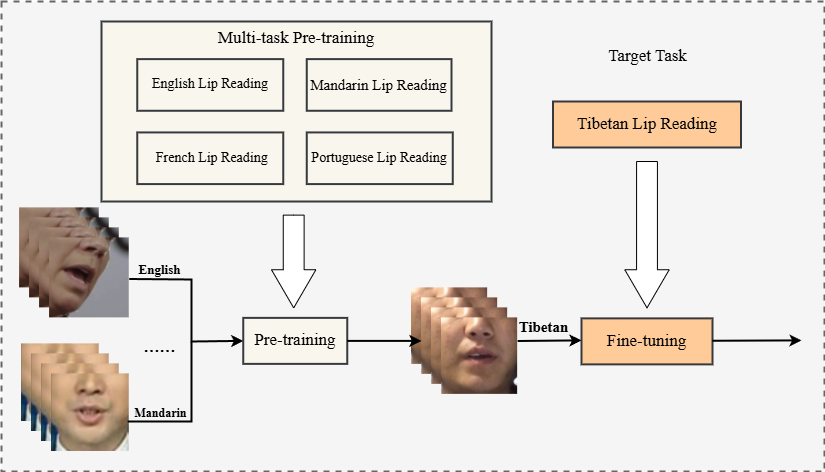 图4的图表直观展示了渐进冻结策略对藏语SER和普通话CER的影响。从左到右依次冻结更多模块,错误率呈现上升趋势,尤其是冻结编码器和解码器后上升显著,支持了“前端通用,后端专用”的结论。
图4的图表直观展示了渐进冻结策略对藏语SER和普通话CER的影响。从左到右依次冻结更多模块,错误率呈现上升趋势,尤其是冻结编码器和解码器后上升显著,支持了“前端通用,后端专用”的结论。
⚖️ 评分理由
- 学术质量:4.0/7:论文结构完整,技术路线清晰,实验设计合理且包含多个有启发性的消融研究。但核心创新是现有技术的组合应用(多语言预训练+LM解码),缺乏模型架构或学习范式上的根本性创新。实验中对比的基线方法并非最新SOTA(如普通话CER对比),削弱了结论的影响力。
- 选题价值:1.5/2:聚焦低资源语言VSR这一实际痛点,具有明确的应用场景(如少数民族语言信息化、辅助沟通)。将多语言学习和LM引入VSR是合理的研究方向,但该方向已非绝对前沿。
- 开源与复现加成:0.0/1:论文全文未提及代码、预训练模型或藏语数据集的开源计划,关键训练超参数(如beam size)也未给出,极大地限制了研究的可复现性和后续工作的借鉴。