📄 Multi-Task Learning For Speech Quality Assessment Using ASR-Derived Entropy Features
#语音质量评估 #多任务学习 #预训练 #语音增强 #鲁棒性
✅ 7.5/10 | 前25% | #语音质量评估 | #多任务学习 | #预训练 #语音增强
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Tri Dung Do(Viettel AI, Viettel Group; University of Engineering and Technology – Vietnam National University, Hanoi)
- 通讯作者:Van Hai Do(Thuyloi University)
- 作者列表:Tri Dung Do(Viettel AI, Viettel Group; University of Engineering and Technology – Vietnam National University, Hanoi), Bao Thang Ta(Viettel AI, Viettel Group; Hanoi University of Science and Technology), Van Hai Do(Viettel AI, Viettel Group; Thuyloi University)
💡 毒舌点评
亮点在于将ASR模型输出的不确定性(熵)作为一个新颖且可量化信号,与语音质量评估任务进行关联,并通过多任务学习框架显式地利用这一信号,思路巧妙。短板是,尽管在NISQA数据集上取得了改进,但论文未与更多当前先进的无参考评估方法(如基于自监督模型或特定Transformer架构的方法)进行直接、充分的对比,说服力稍显不足;另外,对熵特征的物理意义及其与具体失真类型关系的分析深度有限。
🔗 开源详情
- 代码:论文中明确提到“The code is available upon request”,但未提供公开的代码仓库链接。
- 模型权重:论文中未提及是否公开预训练或微调后的模型权重。
- 数据集:使用公开的NISQA语料库,论文中提及其获取方式(引用[1])。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文提供了较详细的模型架构、训练策略(优化器、学习率、轮数、动态权重算法)和部分超参数设置,但缺失batch size、Dropout率、具体硬件等细节。
- 论文中引用的开源项目/模型:主要依赖Wav2Vec2-Base模型(在LibriSpeech上预训练),并引用了NISQA语料库。
📌 核心摘要
问题:本文旨在解决无参考语音质量评估(Non-reference SQA)问题,即无需干净参考语音即可预测语音的感知质量(如MOS分数)。
方法核心:提出了一种新颖的多任务学习框架。该框架利用一个预训练ASR模型(Wav2Vec2)作为特征提取器,其输出帧级熵被观察到与语音质量负相关(噪声语音在89.25%的帧上熵值更高)。模型同时执行两个任务:预测整体MOS分数和预测帧级熵序列。通过动态调整任务权重,训练初期侧重于学习熵特征,后期侧重于MOS预测。
创新点:与现有方法主要依赖复杂模型架构(如Transformer、Conformer)或直接使用熵作为静态特征不同,本文创新性地将“学习预测熵”作为辅助任务,以引导共享编码器学习对不确定性敏感的表征,从而提升主任务(MOS预测)的性能。训练后可移除熵预测分支,保持推理效率。
实验结果:在NISQA数据集上的实验表明,所提出的多任务方法在平均性能上优于单任务基线和将熵作为简单输入特征的方法。具体而言,多任务方法的平均PCC(皮尔逊相关系数)为0.784,RMSE(均方根误差)为0.655,相比单任务基线(PCC 0.761, RMSE 0.690)有显著提升(见表1)。
模型/方法 TEST FOR TEST LIVETALK TEST P501 VAL LIVE VAL SIM 平均 Single-task (baseline) RMSE: 0.623, PCC: 0.741 RMSE: 0.868, PCC: 0.702 RMSE: 0.747, PCC: 0.804 RMSE: 0.436, PCC: 0.833 RMSE: 0.774, PCC: 0.725 RMSE: 0.690, PCC: 0.761 Single-task + Entropy feat. RMSE: 0.613, PCC: 0.752 RMSE: 0.855, PCC: 0.703 RMSE: 0.799, PCC: 0.793 RMSE: 0.455, PCC: 0.831 RMSE: 0.783, PCC: 0.710 RMSE: 0.701, PCC: 0.758 Multi-task (our method) RMSE: 0.631, PCC: 0.739 RMSE: 0.791, PCC: 0.748 RMSE: 0.732, PCC: 0.839 RMSE: 0.422, PCC: 0.807 RMSE: 0.697, PCC: 0.786 RMSE: 0.655, PCC: 0.784 实际意义:为无参考语音质量评估提供了新的视角和有效方法,证明了利用ASR模型内在不确定性信息的价值。该方法在推理时高效,有望应用于实时语音通信监控、语音合成系统评估等场景。
局限性:主要验证仅在一个数据集(NISQA)上进行;使用的预训练ASR模型单一(Wav2Vec2-Base),未探索其他模型的影响;未深入分析熵特征与具体语音失真类型(如噪声、回声、断续)之间的细粒度关系。
🏗️ 模型架构
本文提出的模型架构如图2所示,由两个主要模块构成:预训练ASR模块和多任务学习模块。
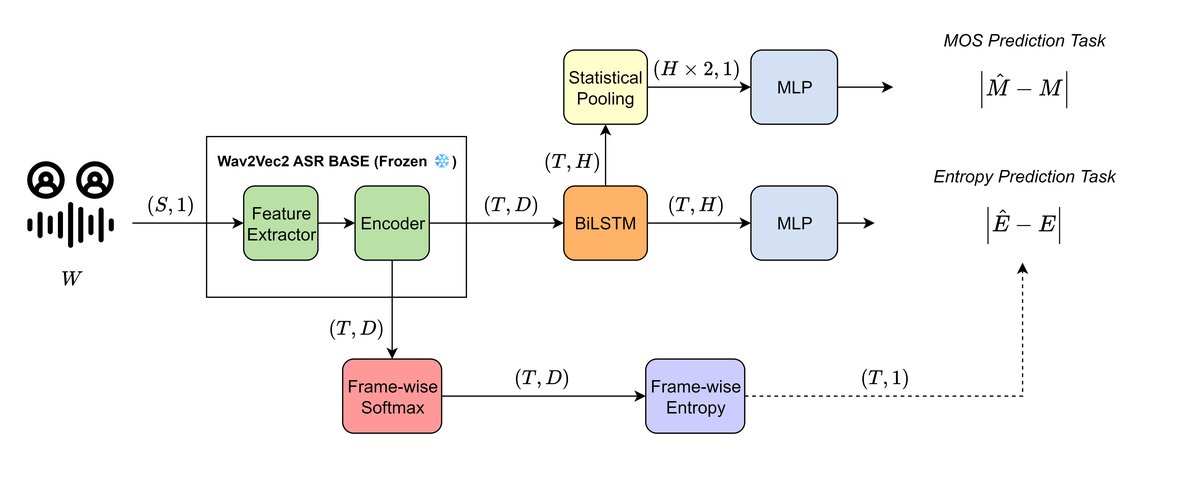
预训练ASR模块:使用固定的Wav2Vec2-Base模型(在960小时LibriSpeech数据上预训练并微调)。该模块作为特征提取器,接收原始语音波形,输出形状为
(T, D)的帧级嵌入序列(T为帧数,D为嵌入维度,Base模型D=768)。论文中明确指出不对此模块进行微调。多任务学习模块:
- 共享编码器 (Shared BiLSTM):接收来自ASR模块的嵌入序列
(T, D),通过一个双向LSTM(BiLSTM)进行处理,建模时序依赖,输出隐藏表示序列(T, H),其中H=512。 MOS预测头:对BiLSTM的输出(T, H)进行统计池化(计算均值和标准差),将结果拼接为一个固定长度向量(维度2H),然后通过一个两层MLP(含ReLU和Dropout),最终输出一个标量,即预测的MOS分数ŷ_m。 - 熵预测头:直接接收BiLSTM的输出
(T, H),通过另一个独立的两层MLP,预测与输入帧数相同的帧级熵序列ŷ_e = {Ê₁, Ê₂, ..., Ê_T}。
- 共享编码器 (Shared BiLSTM):接收来自ASR模块的嵌入序列
数据流与交互:输入语音波形 → ASR编码器(固定) → 帧级嵌入 → BiLSTM(共享) → 隐藏表示 → 分别送入两个任务特定的MLP头,分别预测整体MOS和帧级熵序列。训练时,两个损失函数加权求和;推理时,熵预测分支被移除,仅保留MOS预测路径,因此不增加额外计算开销。
关键设计选择:
- 使用冻结的预训练ASR模型:旨在利用其在大规模语音数据上学到的通用表征,特别是其对语音不确定性的敏感性。
- 动态任务权重:训练初期权重侧重于熵预测(w0=0.9),旨在让共享编码器优先学习捕捉不确定性特征;后期权重线性平滑过渡到侧重MOS预测。这被假设有助于模型先打好表征基础,再优化最终目标。
- 熵的显式预测:与直接拼接熵特征作为输入(Single-task + Entropy)不同,本文让模型主动学习预测熵,被认为能引导模型学习更鲁棒、对噪声更敏感的内部表示。
💡 核心创新点
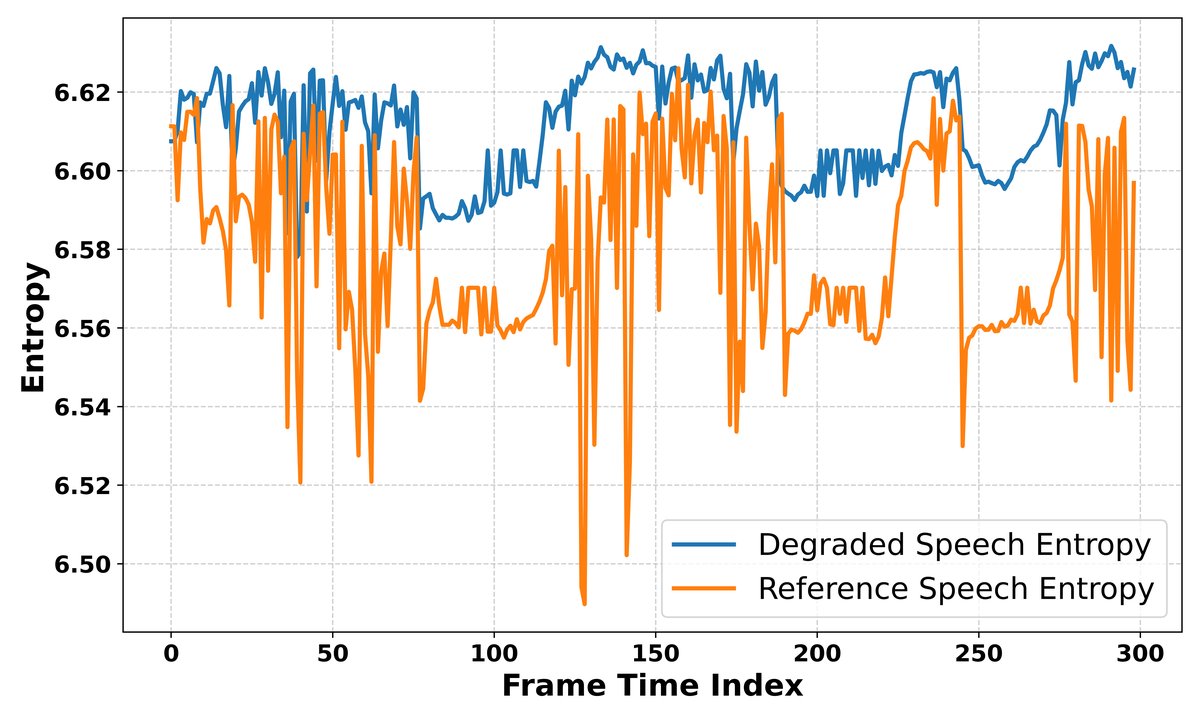
提出并验证ASR熵与语音质量的相关性:这是本文的基石假设。通过实证分析(公式1),证明在89.25%的帧上,噪声语音的ASR编码器输出熵高于对应干净语音(图1)。这为利用ASR不确定性评估质量提供了理论依据。
设计熵引导的多任务学习框架:这是方法论的核心创新。不是简单地将熵作为静态特征输入,而是设计了一个辅助任务——“预测帧级熵”。这个辅助任务充当一个强正则化信号,迫使共享的BiLSTM编码器学习能够区分不同质量语音的、对不确定性敏感的表征,从而提升主任务(MOS预测)的性能。
动态任务加权策略:创新的训练策略。通过在训练过程中动态调整两个任务的损失权重,实现了从“学习特征(熵)”到“应用特征(预测MOS)”的平滑过渡,避免了固定权重可能导致的任务冲突或学习效率低下问题。
高效的推理部署设计:一个关键且实用的创新点是,训练完成的模型在推理阶段可以完全移除熵预测分支。这使得模型在获得性能提升的同时,保持了与单任务基线相同的计算效率,为实际部署扫清了障碍。
🔬 细节详述
- 训练数据:使用NISQA语料库。具体包括:训练集(10,000模拟样本 + 1,020实时样本),验证集(2,500模拟样本 + 200实时样本),测试集(TEST FOR: 240样本, TEST LIVETALK: 232样本, TEST P501: 240样本)。数据预处理和增强细节论文中未提及。
- 损失函数:采用均方误差(MSE) 作为两个任务的损失函数。总损失为加权和:
L_total = λ_m · MSE(ŷ_m, y_m) + λ_e · MSE(ŷ_e, y_e)。其中λ_m + λ_e = 1,权重通过公式(6-8)进行线性插值动态调整,初始熵权重w0 = 0.9。 - 训练策略:
- 优化器:Adam。
- 学习率:0.001。
- 训练轮数:50 epochs。
- 动态权重:熵任务权重
λ_e从0.9线性衰减至0,MOS任务权重λ_m相应从0.1增加至1。 - 训练步数、warmup、batch size论文中未说明。
- 关键超参数:
- 预训练ASR模型:Wav2Vec2-Base(95M参数)。
- 共享BiLSTM隐藏维度:H = 512。
- 任务特定MLP头:2个全连接层,使用ReLU激活和Dropout正则化。具体Dropout率未说明。
- 训练硬件:论文中未提及GPU型号、数量及训练时长。
- 推理细节:推理时直接移除熵预测分支,仅运行ASR编码器、BiLSTM和MOS预测头。解码策略、温度、beam size等不适用于此回归任务。
- 正则化或稳定训练技巧:除了MLP中的Dropout,论文未提及其他正则化技巧(如权重衰减、梯度裁剪)。
📊 实验结果
本文在NISQA语料库的多个子集上评估了MOS预测性能,主要指标为Pearson相关系数(PCC,↑)和均方根误差(RMSE,↓)。
主要对比实验结果(表1):
| 模型/方法 | TEST FOR | TEST LIVETALK | TEST P501 | VAL LIVE | VAL SIM | 平均 |
|---|---|---|---|---|---|---|
| Single-task (baseline) | RMSE: 0.623, PCC: 0.741 | RMSE: 0.868, PCC: 0.702 | RMSE: 0.747, PCC: 0.804 | RMSE: 0.436, PCC: 0.833 | RMSE: 0.774, PCC: 0.725 | RMSE: 0.690, PCC: 0.761 |
| Single-task + Entropy feat. | RMSE: 0.613, PCC: 0.752 | RMSE: 0.855, PCC: 0.703 | RMSE: 0.799, PCC: 0.793 | RMSE: 0.455, PCC: 0.831 | RMSE: 0.783, PCC: 0.710 | RMSE: 0.701, PCC: 0.758 |
| Multi-task (our method) | RMSE: 0.631, PCC: 0.739 | RMSE: 0.791, PCC: 0.748 | RMSE: 0.732, PCC: 0.839 | RMSE: 0.422, PCC: 0.807 | RMSE: 0.697, PCC: 0.786 | RMSE: 0.655, PCC: 0.784* |
关键结论与数字:
- 熵信息的价值:简单地将熵作为输入特征(Single-task + Entropy)在TEST FOR数据集上达到了最佳性能(PCC: 0.752),优于基线(0.741)和多任务方法(0.739),但在其他数据集上效果不稳定,甚至平均性能低于基线。 多任务学习的优势:本文提出的多任务方法(Multi-task)在大部分数据集(TEST LIVETALK, TEST P501, VAL SIM) 上均取得了显著最佳性能(标记为)。尤其在TEST LIVETALK(PCC 0.748 vs 0.702,提升约6.6%)和VAL SIM(PCC 0.786 vs 0.725,提升约8.4%)上优势明显。
- 平均性能:在平均指标上,多任务方法(PCC 0.784, RMSE 0.655)显著优于单任务基线(PCC 0.761, RMSE 0.690)和熵特征拼接方法(PCC 0.758, RMSE 0.701)。论文指出,多任务方法的改进在统计上显著(p < 0.05)。
- 效率:论文强调,尽管多任务方法在训练时更复杂,但推理速度与单任务基线相同,因为熵预测分支在测试时被移除。
实验不足:论文未提供与ICASSP、INTERSPEECH上其他最先进无参考SOTA方法(例如基于Conformer、专门设计的SSL模型微调方法)的直接对比数字,仅与论文自己设计的基线进行比较。消融实验也较简单,主要对比了直接使用熵特征与多任务学习两种方式。
⚖️ 评分理由
学术质量:6.0/7
- 创新性(良好):将ASR不确定性(熵)与语音质量评估通过多任务学习框架显式关联,思路新颖且合理。动态权重策略和推理时移除辅助分支的设计体现了工程巧思。
- 技术正确性(良好):方法实现基于成熟的模型组件(Wav2Vec2, BiLSTM, MLP),损失函数和训练策略设计合理,实验部分支持其假设。
- 实验充分性(中等):在标准数据集NISQA上进行了对比实验,并提供了统计显著性检验。但对比基线过于单一(仅与自己设计的单任务版本对比),未与领域内其他代表性方法进行比较,削弱了结果的普遍说服力。消融研究不够深入。
- 证据可信度(良好):实验设置清晰,结果表格详细,关键数据点均有呈现。
选题价值:1.5/2
- 前沿性与影响(中等偏上):语音质量评估是语音领域的基础任务,本文提供了一种新的、计算高效的无参考评估思路,具有理论价值和一定的应用前景(如实时监控、系统优化)。
- 潜在应用与读者相关性(中等):对于从事语音通信、语音合成、语音识别系统开发的工程师和研究人员有参考价值,能启发他们利用现有ASR模型的副产物来评估系统输出质量。
开源与复现加成:0.3/1
- 论文声称“The code is available upon request”,表明有代码但未公开链接。
- 详细给出了模型架构、关键超参数(如BiLSTM维度、MLP层数、优化器、学习率、训练轮数、动态权重公式)和训练策略。
- 未提供模型权重、详细的超参数搜索过程、具体的训练硬件信息。
- 复现的难度中等,关键信息基本具备,但部分细节(如MLP Dropout率、batch size)缺失。