📄 Multi-Layer Attentive Probing Improves Transfer of Audio Representations for Bioacoustics
#生物声学 #自监督学习 #迁移学习 #基准测试 #模型评估
✅ 7.5/10 | 前25% | #生物声学 | #自监督学习 #迁移学习 | #自监督学习 #迁移学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文按作者列表排序,未明确标注第一作者)
- 通讯作者:未说明(论文未明确标注通讯作者)
- 作者列表:Marius Miron, David Robinson, Masato Hagiwara, Titouan Parcollet, Jules Cauzinille, Gagan Narula, Milad Alizadeh, Ellen Gilsenan-McMahon, Sara Keen, Emmanuel Chemla, Benjamin Hoffman, Maddie Cusimano, Diane Kim, Felix Effenberger, Jane K. Lawton, Aza Raskin, Olivier Pietquin, Matthieu Geist (均来自Earth Species Project)
💡 毒舌点评
论文系统性地揭示了在生物声学任务中,简单的线性探针会系统性低估优秀编码器的能力,这为改进该领域的模型评估标准提供了有力证据。然而,研究主要集中在对已有模型的“再评估”,而非提出新的编码器或解决更具挑战性的任务,创新维度略显单一。
🔗 开源详情
- 代码:提供了Python库的开源链接:https://github.com/earthspecies/avex。
- 模型权重:论文中未提及是否公开其评估所用的所有基座模型的检查点权重。
- 数据集:评估所用的BEANs和BirdSet是公开基准数据集,论文未提及自己发布新数据。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文提供了实验的核心方法描述(如适配器设计、探针头结构、训练策略概要),但部分细节(如具体超参数值、数据增强方法、硬件配置)未在正文完全列出,可能包含在开源库中。
- 引用的开源项目/模型:论文明确使用了以下开源或公开模型:BEATs, EAT, BirdAVES (AVES), EfficientNet, NatureBEATs。这些模型本身是公开可用的。
📌 核心摘要
- 要解决什么问题: 当前生物声学领域的基准测试普遍采用固定、低容量的“探针头”(如最后一层输出的线性层)来评估不同音频编码器的性能,这可能导致评估结果有偏差,无法准确反映编码器的真实质量。
- 方法核心是什么: 系统性地比较了多种探针策略(最后一层探针 vs. 多层探针)和探针头类型(线性探针 vs. 注意力探针)在不同音频编码器(自监督SSL和监督SL模型)和两个生物声学基准(BEANs, BirdSet)上的表现。引入了适配器模块来处理不同层输出维度不一致的问题。
- 与已有方法相比新在哪里: 相较于以往工作仅用线性探针评估最后一层,本文首次在生物声学领域全面研究了多层探针和注意力探针的有效性,并适配了处理异构层输出的适配器模块。这借鉴了语音领域的评测思想,但针对生物声学任务和模型特性进行了适配。
- 主要实验结果如何: 关键发现包括:a) 多层探针一致性优于单层探针:对于所有模型,使用所有层的加权融合比仅使用最后一层效果更好,在BEANs分类/检测任务上平均提升约0.08精度,在BirdSet上提升约0.03 mAP。b) 注意力探针对自监督Transformer模型效果显著:注意力探针能更好地利用SSL模型(如BEATs, EAT, BirdAVES)学习到的时序依赖关系,性能提升明显。c) 监督模型与鸟类数据高度相关:通过分析学习到的层权重,发现SL模型的权重更集中在专用于鸟类分类的高层,而SSL模型的权重分布更均匀。
- 实际意义是什么: 本研究建议生物声学社区更新其基准测试标准,采用更强大、更灵活的探针策略(如多层注意力探针)来更公平地评估和比较不同的音频基础模型,从而推动该领域模型性能的真实提升。
- 主要局限性是什么: 研究的计算开销较大(需提取多层特征);对部分CNN模型(如EfficientNet)的分析不如Transformer模型深入;未与最新发表的一些强大模型(如Perch 2.0)进行直接性能对比。
🏗️ 模型架构
本文研究的核心是探针(Probe)架构,而非一个全新的编码器模型。其目的是评估已有的预训练音频编码器(Base Model)。探针架构主要涉及两种策略和两种头类型:
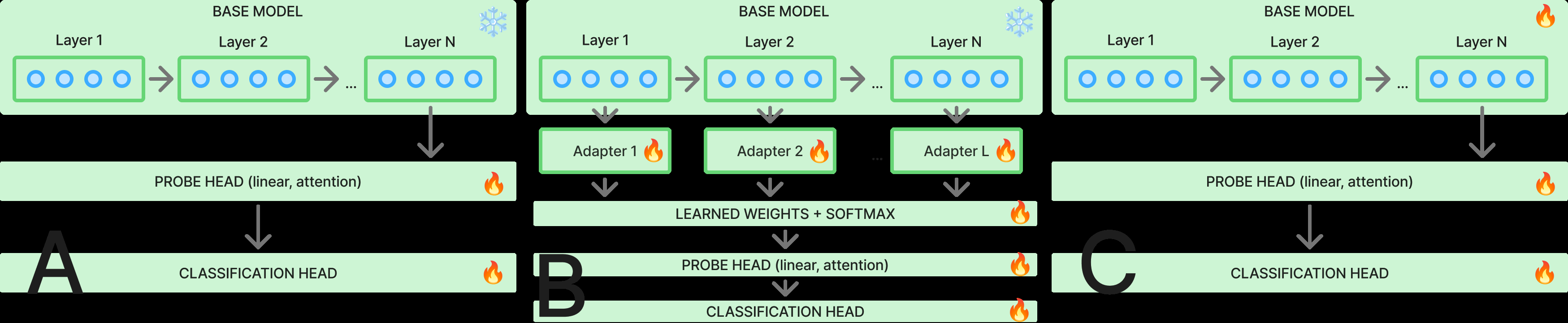
- A. 最后一层探针 (Last-layer probing):预训练编码器的所有参数(frozen)保持不变,仅在最后一层输出(
hL)之上添加一个可训练的探针头gϕ进行分类。这是传统做法。 - B. 多层探针 (All-layer probing):这是本文的核心改进。它从编码器的所有块(Block)中提取隐藏表示
hl。由于不同块(尤其是CNN和Transformer之间)输出的维度(d1, d2, d3)可能不同,需要先通过适配器 (Adapter)Aψl将它们投影到统一的格式(Tmax, Fmax)。- 适配器是一个两步操作:先通过线性层将特征维度
d2投影到Fmax,再通过插值将序列长度(时间维度)d1对齐到Tmax。 - 所有适配后的层表示
ĥl通过可学习的层权重αl(由softmax归一化的w得到)进行加权求和,得到融合表示h。 - 最终,这个融合表示
h被送入探针头gϕ进行分类。这种策略允许模型利用所有层的信息,且权重αl可解释。
- 适配器是一个两步操作:先通过线性层将特征维度
- C. 全微调 (Fully fine-tuning):作为性能上界参考,解冻编码器所有参数与探针头一起训练。
探针头类型:
- 线性探针 (Linear Probe):将编码器输出在时间维度上平均池化,得到一个全局特征向量,然后通过一个线性层进行分类。容量低,捕获全局信息。
- 注意力探针 (Attention Probe):容量更高。为每个时间步学习注意力权重,对特征进行加权,然后通过残差连接、层归一化和Dropout,最后接分类层。它能更好地建模时间依赖关系。
💡 核心创新点
- 在生物声学领域系统引入并验证多层探针策略:此前该领域普遍只使用最后一层探针。本文实验证明,多层探针(加权融合所有层输出)能一致性提升分类和检测任务的性能,揭示了当前基准可能低估编码器质量的问题。
- 验证注意力探针对自监督Transformer模型的增益:针对自监督学习(SSL)的Transformer编码器(如BEATs, EAT),使用注意力探针能显著优于线性探针,因为能更好地利用SSL模型在预训练中学习到的丰富时序模式。
- 设计处理异构层输出的适配器模块:为了将CNN(如EfficientNet)和Transformer编码器的多层输出统一起来,引入了包含线性投影和序列插值的适配器,使得多层探针策略具有通用性。
- 通过分析层权重获得可解释性:多层探针学习到的层权重
αl可被可视化(如图3),揭示了监督模型(SL)在特定任务(如鸟类分类)上更依赖高层特征,而自监督模型(SSL)的特征利用更分散,为理解模型行为提供了洞察。 - 提出面向生物声学实践的探针选择指南:基于实验,论文给出了明确建议:对于非鸟类分类任务应使用多层探针;如果基座模型是SSL Transformer,则应搭配注意力探针。
🔬 细节详述
- 训练数据:
- 基准数据集:使用 BEANs 和 BirdSet。BEANs包含多种动物(蝙蝠、鸟类、狗、海洋哺乳动物、蚊子)的分类和检测任务。BirdSet专注于鸟类物种检测,并区分训练集(干净,焦点物种)和测试集(嘈杂,多物种)。
- 预训练数据:各基座模型的预训练数据详见表1。SSL模型主要在AudioSet、语音语料或鸟叫声(Xeno-Canto)上预训练。SL模型在生物声学和通用音频数据上进行监督训练或后训练。
- 预处理与增强:论文中未明确提及具体的音频预处理和数据增强细节。
- 损失函数:
- 单分类任务(物种/个体识别):使用标准交叉熵损失。
- 多分类/检测任务(声音事件检测):使用二元交叉熵(BCE)损失,允许每个样本有多个正标签。
- 训练策略:
- 训练轮数:50个epoch(为控制实验成本,少于先前工作使用的900 epoch)。
- 学习率:0.0001。
- 优化器:AdamW。
- 调度策略:引入了余弦学习率调度器,前5个epoch为warmup阶段。
- 训练方式:在线生成嵌入(而非预计算存储),以节省磁盘空间。
- 关键超参数:
- 探针层选择:由于计算限制,仅提取每个块(Block)最后一层的嵌入。BEATs/BirdAVES提取11层,EAT提取10层(使用注意力输出层),EfficientNet提取15层。
- 适配器维度:
Tmax和Fmax被设置为所有层中最大的序列长度和特征维度,以统一输出。对于Transformer,层维度相同则不需要适配器;对于CNN(EfficientNet),因维度差异大,适配器参数量较大。 - 模型参数量:详见表1。例如,BEATs基础模型冻结参数为90.35M,其多层注意力探针可训练参数为2.40M。
- 训练硬件:论文中未提及具体的GPU/TPU型号、数量和训练时长。
- 推理细节:论文中未提及。
- 正则化:注意力探针头中使用了Dropout层。
📊 实验结果
论文在两个基准上,对多种基座模型和六种“探针配置(层策略)+ 探针头类型”组合进行了评估。主要结果汇总见图2。
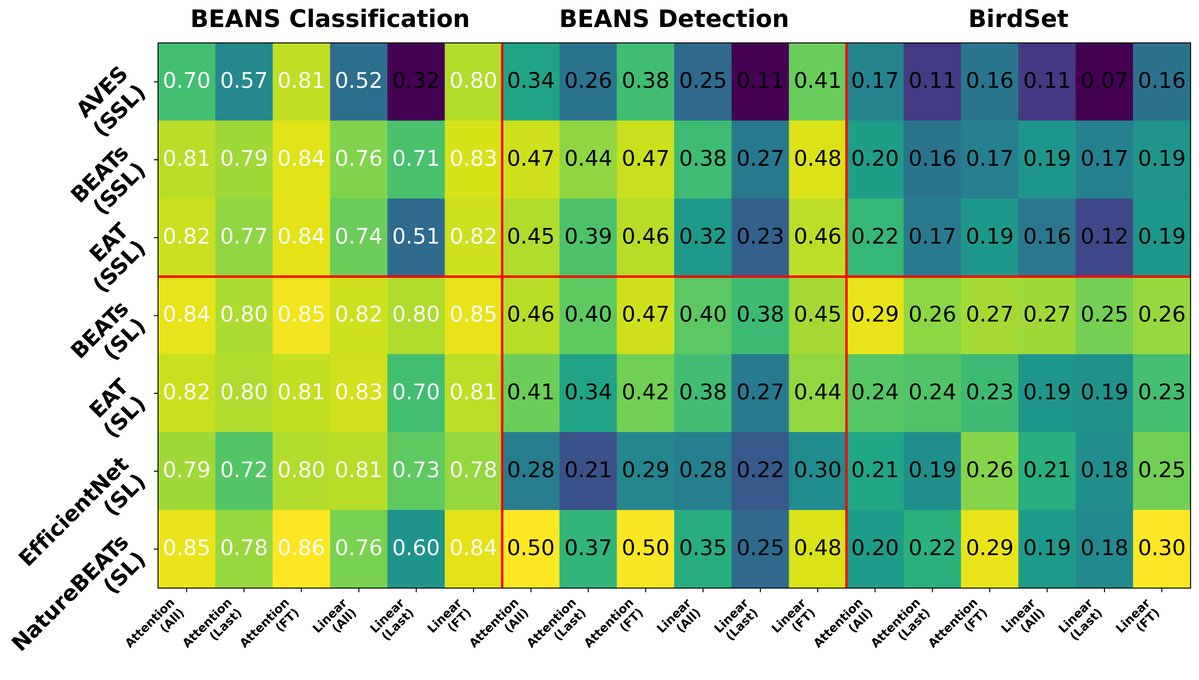 图2说明:该图展示了基座模型在BEANs分类(Top-1准确率)、BEANs检测(mAP)和BirdSet(mAP)三个评估指标下,六种探针组合的性能。关键结论是:对于几乎所有模型,使用所有层(“All”)的性能优于仅使用最后一层(“Last”),且注意力探针(Attention)通常优于线性探针(Linear),这一优势在SSL模型上尤为明显。
图2说明:该图展示了基座模型在BEANs分类(Top-1准确率)、BEANs检测(mAP)和BirdSet(mAP)三个评估指标下,六种探针组合的性能。关键结论是:对于几乎所有模型,使用所有层(“All”)的性能优于仅使用最后一层(“Last”),且注意力探针(Attention)通常优于线性探针(Linear),这一优势在SSL模型上尤为明显。
关键定量发现(基于图2描述):
- 多层探针优势:
- 对于Transformer模型,在BEANs分类/检测任务上,多层探针相比单层探针平均提升约0.08精度/ mAP。
- 在BirdSet上,提升约为0.03 mAP。
- 对于CNN模型(EfficientNet),在BEANs上提升约0.09,在BirdSet上提升约0.02。
- 注意力探针优势:
- 注意力探针相比线性探针,对SSL模型(BEATs-SSL, EAT-SSL, BirdAVES)和部分SL模型(NatureBEATs)有显著提升。对EfficientNet(CNN)则无明显帮助。
- 全微调上界:全微调(Fully FT)提供了最佳性能,尤其对于SSL模型,但参数更新代价高昂。
层权重分析(图3):
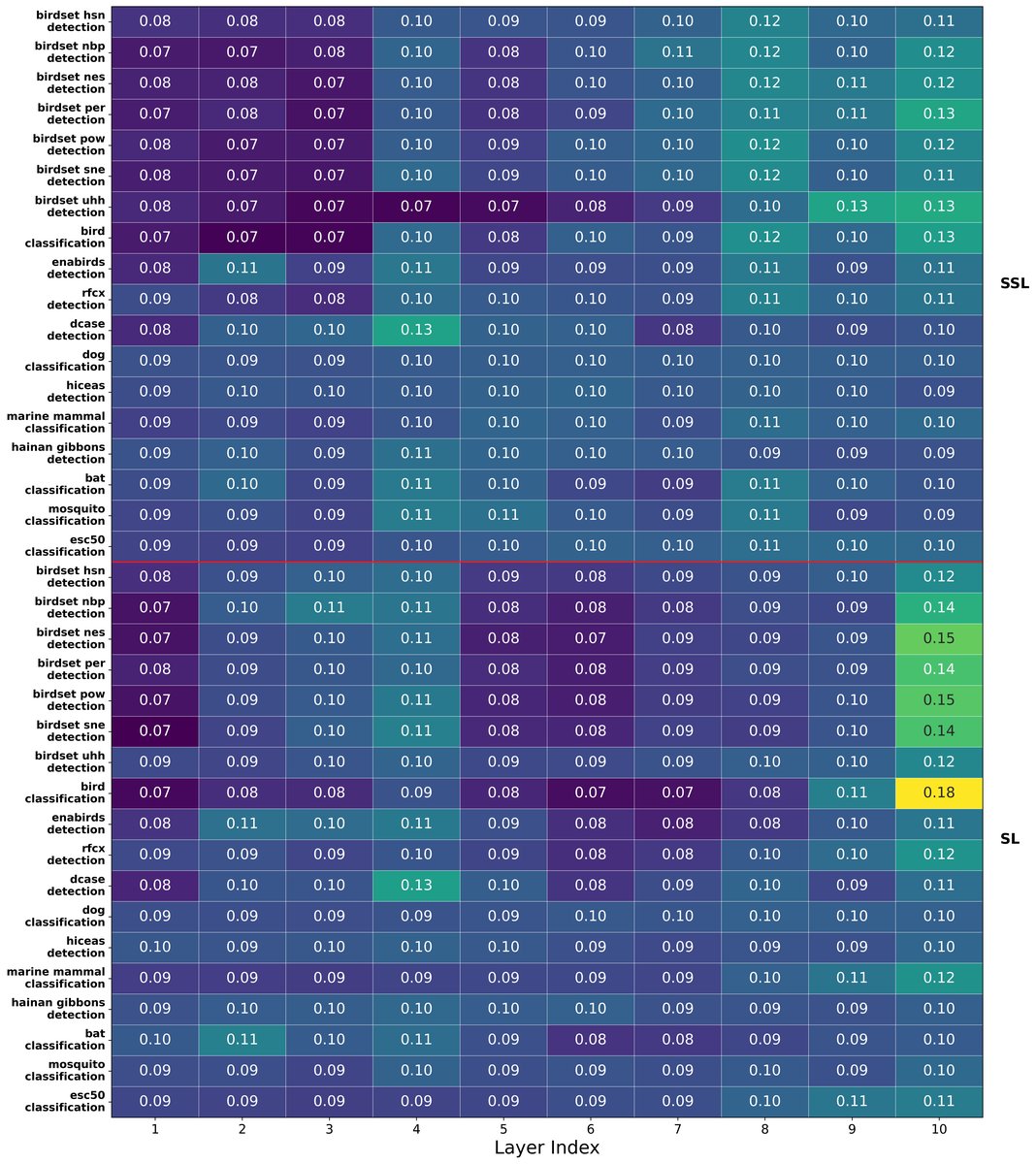 图3说明:该图对比了SSL模型与SL模型在BEANs和BirdSet各数据集上,多层探针学习到的权重(αl)分布。结论显示:鸟类数据集上,SL模型更依赖高层(上部),SSL模型更依赖中层;在混合或哺乳类数据集上,知识分布更均匀。
图3说明:该图对比了SSL模型与SL模型在BEANs和BirdSet各数据集上,多层探针学习到的权重(αl)分布。结论显示:鸟类数据集上,SL模型更依赖高层(上部),SSL模型更依赖中层;在混合或哺乳类数据集上,知识分布更均匀。
论文未明确提供各具体数据集-模型-探针组合的精确数值表格,但通过图2给出了直观的性能对比和趋势结论。 论文也提到其“Linear (Last)”结果略低于先前工作,主要因为训练epoch更少且采用��线生成特征的方式。
⚖️ 评分理由
- 学术质量:5.5/7 - 论文进行了一项系统、严谨的方法学研究,实验设计合理,对比全面(多模型、多策略、多任务),得出了清晰且有指导意义的结论(多层、注意力探针的优势)。创新在于将语音领域的评估思想适配到生物声学并进行了扩展(适配器设计、权重分析),但核心探针技术并非全新,原创性中等。实验充分,证据可信。
- 选题价值:1.5/2 - 针对生物声学领域一个关键但易被忽视的问题(基准测试的公平性)展开,直接关系到如何正确评估和推动该领域的AI模型发展。选题精准、实际意义明确,对生物声学和更广泛的音频表示学习社区都有参考价值。
- 开源与复现加成:0.5/1 - 论文明确声明代码开源(提供了GitHub链接),这是重要的加分项。然而,论文正文未提供详细的超参数列表、训练脚本配置或预训练模型权重,复现所需的完整信息仍需查阅开源库,因此加成有限。