📄 Multi-Channel Speech Enhancement for Cocktail Party Speech Emotion Recognition
#语音情感识别 #语音增强 #波束成形 #多通道 #预训练
✅ 7.5/10 | 前25% | #语音情感识别 | #波束成形 | #语音增强 #多通道
学术质量 6.0/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Youjun Chen(香港中文大学)
- 通讯作者:Xunying Liu(香港中文大学)、Xurong Xie(中国科学院软件研究所)
- 作者列表:Youjun Chen(香港中文大学)、Guinan Li(香港中文大学)、Mengzhe Geng(加拿大国家研究委员会)、Xurong Xie(中国科学院软件研究所)、Shujie Hu(香港中文大学)、Huimeng Wang(香港中文大学)、Haoning Xu(香港中文大学)、Chengxi Deng(香港中文大学)、Jiajun Deng(香港中文大学)、Zhaoqing Li(香港中文大学)、Mingyu Cui(香港中文大学)、Xunying Liu(香港中文大学)
💡 毒舌点评
亮点:这篇论文最大的优点在于系统性和实证性,它没有追求单一模块的惊人指标,而是扎实地构建并验证了一个从信号处理到深度学习表示的完整流水线,明确证明了“多通道前端”对于下游复杂感知任务(情感识别)的不可替代的增益。短板:其核心前端模块(DNN-WPE+MVDR)是已有技术的成熟组合,创新更多体现在系统集成与任务迁移上,且所有实验均基于模拟的鸡尾酒会数据,与真实部署场景可能仍存在“模拟与现实”的差距,论文对此的讨论有限。
🔗 开源详情
- 代码:论文中未提及开源代码仓库链接。仅提供了一个展示系统效果的Demo网页(https://SEUJames23.github.io/MCSE-ER/)。
- 模型权重:未提及是否公开预训练或微调后的模型权重。
- 数据集:实验基于公开的IEMOCAP和MSP-FACE数据集,但多通道混合语音的模拟数据本身未提及是否公开。
- Demo:提供在线演示,链接为 https://SEUJames23.github.io/MCSE-ER/。
- 复现材料:论文描述了实验设置(如数据集划分、系统配置引用[13]),但未提供详细的超参数、代码或配置文件。核心模拟细节需参考引用文献[13, 14]。
- 论文中引用的开源项目/模型:引用了Real-ESRGAN(人脸超分)、HuBERT(音频自监督模型)、ViT(视觉Transformer)和WavLM(音频自监督模型)等预训练模型或工具。
- 总结:论文在开源与复现信息方面做得不充分。它证明了方法的有效性,但未提供足够的材料让同行便捷地复现其全部结果。
📌 核心摘要
- 要解决什么问题:在“鸡尾酒会”等复杂声学场景中,由于存在重叠语音、背景噪声和混响,现有的单通道语音情感识别(ER)系统性能严重下降。
- 方法核心是什么:提出一个两阶段的多通道语音增强与情感识别系统。第一阶段,使用一个集成DNN-WPE去混响和基于掩码的MVDR波束成形的流水线作为前端,从多通道混合语音中提取目标说话人语音。第二阶段,使用基于预训练HuBERT和ViT的音频/视觉编码器作为后端,进行情感识别。论文设计了纯音频、早期融合和晚期融合三种音视频ER解码器。
- 与已有方法相比新在哪里:a) 首次系统性地将完整的多通道去混响与分离前端应用于鸡尾酒会场景的ER任务,弥补了以往研究多聚焦于单通道或仅关注分离的不足;b) 全面评估了该前端对音频-only和音频-视觉ER系统的影响,而前人工作主要评估音频-only系统;c) 通过详细的消融研究,证实了前端中去混响和分离组件各自的重要性;d) 探索了该前端的零样本跨数据集泛化能力。
- 主要实验结果如何:在基于IEMOCAP数据集构建的模拟混合语音上,所提MCSE前端显著优于各种单通道基线。例如,在音频-only ER任务中,加权准确率(WA)比最优单通道基线(WavLM+SE-ER微调)高出9.5%绝对值(相对17.1%)。在音视频ER任务(早期融合)中,WA比相应基线高出3.4%绝对值。同时,在SRMR, PESQ, STOI等语音质量指标上也有一致提升。在零样本跨域评估(应用IEMOCAP训练的前端到MSP-FACE数据)中也观察到显著提升。
关键实验结果表格(音频-only ER on IEMOCAP)
| ID | 系统 | SE前端 | ER后端 | SRMR↑ | PESQ↑ | STOI↑ | WA%↑ | UA%↑ | F1%↑ |
|---|---|---|---|---|---|---|---|---|---|
| 1 | WavLM + ER微调 | 单通道 | WavLM | 未提供 | 未提供 | 未提供 | 54.3 | 55.6 | 55.1 |
| 2 | WavLM + SE-ER微调 | 单通道 | WavLM | 2.91 | 1.18 | 0.51 | 55.7 | 57.7 | 56.8 |
| 3 | CMGAN + HuBERT | 单通道 | HuBERT | 3.65 | 1.27 | 0.60 | 56.5 | 58.3 | 57.7 |
| 4 | 微调CMGAN + HuBERT | 单通道 | HuBERT | 3.88 | 1.42 | 0.64 | 57.1 | 58.0 | 57.6 |
| 5 | MCSE + HuBERT (本文) | 多通道 | HuBERT | 6.69 | 2.82 | 0.76 | 65.2 | 66.2 | 65.9 |
注:MCSE系统在所有指标上均显著优于单通道基线(、†表示统计显著性)。*
关键实验结果表格(音视频 ER Early-Fusion on IEMOCAP)
| ID | 系统 | SE前端 | ER后端 | SRMR↑ | PESQ↑ | STOI↑ | WA%↑ | UA%↑ | F1%↑ |
|---|---|---|---|---|---|---|---|---|---|
| 6 | WavLM + ER微调 | 单通道 | WavLM+ViT | 未提供 | 未提供 | 未提供 | 73.5 | 74.8 | 74.4 |
| 7 | WavLM + SE-ER微调 | 单通道 | WavLM+ViT | 2.91 | 1.18 | 0.51 | 74.9 | 75.6 | 75.3 |
| 8 | CMGAN + HuBERT | 单通道 | HuBERT+ViT | 3.65 | 1.27 | 0.60 | 75.2 | 75.9 | 75.7 |
| 9 | 微调CMGAN + HuBERT | 单通道 | HuBERT+ViT | 3.88 | 1.42 | 0.64 | 75.5 | 76.1 | 75.9 |
| 10 | MCSE + HuBERT (本文) | 多通道 | HuBERT+ViT | 6.69 | 2.82 | 0.76 | 78.3 | 79.5 | 79.2 |
注:MCSE系统同样取得最优性能(‡、◦表示统计显著性)。
消融研究(IEMOCAP,音频-only)
| ID | 系统 | SRMR | PESQ | STOI | WA% | UA% | F1% |
|---|---|---|---|---|---|---|---|
| 1 | MCSE-ER (完整) | 6.69 | 2.82 | 0.76 | 65.2 | 66.2 | 65.9 |
| 2 | w/o 去混响 | 5.52 | 2.56 | 0.70 | 63.2 | 63.9 | 64.0 |
| 3 | w/o 分离 | 5.83 | 1.73 | 0.66 | 56.6 | 57.2 | 56.8 |
| 4 | w/o 去混响 & 分离 | 3.16 | 1.16 | 0.48 | 52.5 | 54.2 | 53.2 |
注:移除任一组件(特别是分离)都会导致性能显著下降,证明了完整前端的重要性。
- 实际意义是什么:为在车载、医院等真实复杂声场中部署鲁棒的情感识别系统提供了一种可行的技术方案,强调了多麦克风阵列硬件与先进信号处理前端在实际应用中的关键作用。
- 主要局限性是什么:a) 所有实验均在模拟的混合语音数据上进行,虽然论文解释了原因,但模拟数据与真实世界的声学条件可能存在差异;b) 前端(MCSE)与后端(ER)采用分离的两阶段训练,未能实现全局联合优化;c) 提供的Demo为离线处理,未讨论实时性等部署约束。
🏗️ 模型架构
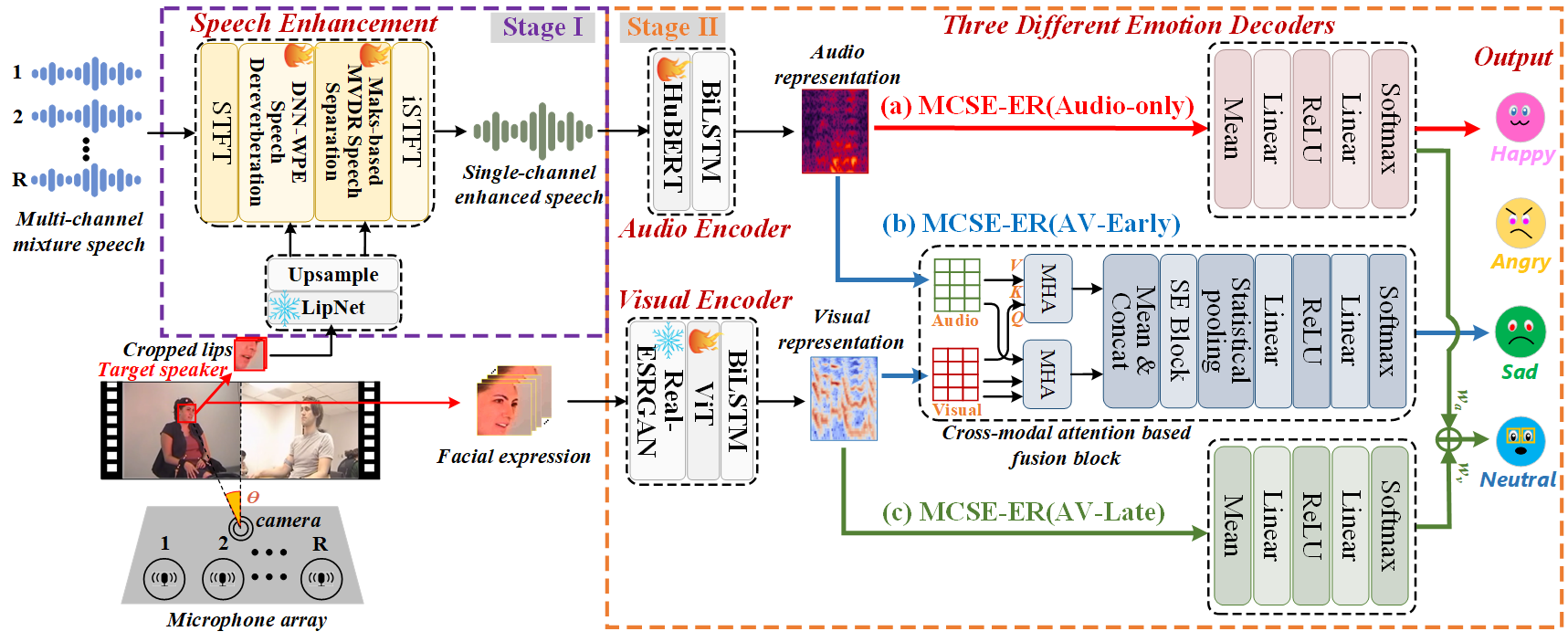
如图1所示,整个系统由多通道语音增强前端和情感识别后端两大部分串联构成。
多通道语音增强前端(MCSE Front-end, 浅黄色区域):
- 输入:R通道的混合语音谱向量 x(t, f),包含目标语音、干扰语音、噪声和混响。
- 第一阶段:DNN-WPE去混响:对多通道混响语音进行处理。通过一个由DNN预测的时频掩码来估计语音功率,并迭代计算WPE滤波器W_WPE(f)。最终,通过从原始语音中减去由滤波器和延迟语音估计出的混响分量,得到去混响后的多通道语音谱向量d̂(t, f)。公式(1)-(3)描述了该过程。
- 第二阶段:基于掩码的MVDR波束成形:对去混响后的信号进行空间滤波,分离出目标说话人语音。首先,利用DNN预测的掩码估计目标语音和噪声的功率谱密度矩阵。然后,根据MVDR准则计算最优波束成形滤波器W_MVDR(f),该滤波器在最小化残余噪声功率的同时,保证目标语音信号不失真。最终,通过将滤波器应用于去混响语音,得到单通道的增强语音谱Ŝ(t, f)。公式(4)-(5)描述了该过程。
- 设计动机:采用“先去混响,后分离”的流水线设计,是因为混响会严重影响后续波束成形的性能。这种两阶段处理能更彻底地清除不同类型的干扰。
情感识别后端(ER Back-end, 灰色区域):
- 音频编码器:以MCSE前端输出的单通道增强语音作为输入,由预训练的HuBERT模型提取高维音频表示,再通过BiLSTM层进行降维并保持时序信息。
- 视觉编码器:处理目标说话人的面部视频。首先用Real-ESRGAN进行人脸增强,然后由预训练的ViT模型提取视觉特征,同样通过BiLSTM降维,使其维度与音频表示匹配。
- 情感解码器:论文设计了三种解码方式以评估前端对不同后端系统的影响。
- 纯音频系统(MCSE-ER(Audio-only),浅红色):直接使用音频表示进行分类。
- 早期融合音视频系统(MCSE-ER(AV-Early),浅蓝色):将音频和视觉表示输入到一个基于跨模态注意力的融合模块中。该模块包含多头注意力层、拼接、挤压激励(SE)块和统计池化层,生成联合的音视频表示进行分类。
- 晚期融合音视频系统(MCSE-ER(AV-Late),浅绿色):音频和视觉分支分别预测情感概率,通过可学习的权重w_a和w_v对两个概率加权求和,得到最终预测。
数据流与交互:MCSE前端依次完成去混响和分离,输出“干净”的单通道语音。该语音被送入音频编码器。同时,对应的视频被送入视觉编码器。根据选定的融合策略(早期/晚期),音视频特征在解码器中交互,最终输出情感类别预测。
💡 核心创新点
- 系统性地将完整多通道SE前端引入ER任务:针对“鸡尾酒会”这一极端场景,首次完整地将DNN-WPE去混响与MVDR波束成形分离流水线作为前端应用于语音情感识别。这超越了以往仅使用单通道方法或仅考虑分离(忽略混响)的局限,更贴近真实复杂声学环境。
- 全面评估多通道前端对音视频ER系统的影响:不仅评估了前端对音频-only ER的作用,还首次系统评估了其对包含视觉信息的ER系统(早期/晚期融合)的增益。实验表明,清晰的音频输入对多模态融合同样至关重要。
- 通过消融研究验证完整前端组件的必要性:通过严格的消融实验(表2),定量证明了去混响和分离两个组件对于最终情感识别性能的缺一不可性,为系统设计提供了实证依据。
- 探索零样本跨数据集泛化能力:在IEMOCAP数据集上训练MCSE前端,直接零样本应用于不同域、真实采集的MSP-FACE数据集进行ER评估,验证了所提前端的强泛化能力,这是许多类似研究缺失的一环。
🔬 细节详述
- 训练数据:
- 基础语料:使用IEMOCAP(单通道多模态)和MSP-FACE(真实世界噪声多模态)两个数据集。
- 数据模拟:由于缺乏真实的多通道鸡尾酒会ER数据,论文对上述语料的单通道干净语音进行模拟,构建训练/测试数据。为每条语料均匀采样信噪比(SNR)、信号干扰比(SIR)和混响时间(T60),生成包含噪声、重叠语音和混响的多通道混合语音。模拟的IEMOCAP数据包含11.06万条语音,共140小时。MSP-FACE数据包含训练集1.46万条,评估集8700条。
- 评估设置:采用5折交叉验证确保说话人独立性。MSP-FACE数据用于测试IEMOCAP训练模型的零样本性能。
- 损失函数:
- MCSE前端:在第一阶段独立训练时,以最大化SI-SNR(尺度不变信噪比)为目标进行优化。
- ER后端:在第二阶段微调整个系统时,以情感识别任务的损失(论文未明确说明具体函数,通常为交叉熵)为目标进行优化。
- 训练策略:
- 两阶段训练:第一阶段,冻结后端参数,单独训练MCSE前端以优化语音增强指标。第二阶段,冻结已训练好的MCSE前端参数,端到端微调整个ER后端(音频编码器、视觉编码器、融合模块、解码器)以进行情感分类。
- 优化器/超参数:论文中未提供具体的学习率、batch size、优化器类型等训练超参数。
- 关键超参数:
- 音频编码器(HuBERT)最后一层输出维度为1024。
- 视觉编码器(ViT)最后一层输出维度为768。
- BiLSTM层将两者维度均降至2×60。
- 早期融合模块使用6个头的多头注意力机制。
- 训练硬件:论文中未提及具体的GPU型号、数量或训练时长。
- 推理细节:论文中未提及解码策略、温度、beam size等具体推理设置。
- 正则化技巧:论文中未明确提及是否使用Dropout、权重衰减等正则化手段。
- 评估指标:ER性能使用加权准确率��WA)、未加权准确率(UA)和宏F1分数(F1)。语音增强质量使用SRMR、PESQ和STOI。统计显著性采用Paired Single-tailed T-test (p=0.05)。
📊 实验结果
(请参阅“核心摘要”部分已列出的两个关键结果表格及消融研究表格。)
总结与解读:
- 主导优势:在模拟的IEMOCAP鸡尾酒会数据上,所提出的多通道系统(MCSE+HuBERT)在所有指标上全面且显著地优于所有单通道基线(Sys. 1-4)。在纯音频任务中,WA提升绝对值最高达9.5%;在音视频早期融合任务中,WA提升最高达3.4%。这强有力地证明了多通道处理在复杂声学场景下的关键价值。
- 消融研究:表2清楚地表明,移除去混响或分离组件都会导致语音质量指标和ER指标的显著下降。其中,移除分离组件的影响远大于移除去混响组件,这可能说明在模拟的混合语音中,说话人重叠是比混响更严重的干扰源,但两者都不可或缺。
- 跨域泛化:在MSP-FACE数据集的零样本测试中(表1最后两列),IEMOCAP训练的MCSE前端(Sys. 5, 10)依然显著优于相应的单通道基线(Sys. 1, 7),证明了所学前端特征的泛化性。然而,绝对性能较IEMOCAP上有明显下降(例如,Sys. 10的WA从78.3%降至67.4%),这反映了域间差异的影响。
- 音视频融合优势:对比表1中的Sys. 5与Sys. 10(或Sys. 1与Sys. 6),加入视觉信息后,ER性能有巨大提升(WA提升超过13%),证实了音视频融合的有效性。同时,早期融合(Sys. 10)略优于晚期融合(Sys. 5)。
⚖️ 评分理由
- 学术质量:6.0/7:论文的技术路线清晰、扎实,实验设计全面且具有说服力。主要扣分在于创新性——前端核心是已有成熟技术的整合,后端是标准自监督模型的应用。但这属于优秀的系统集成和跨任务迁移研究,而非提出全新算法。
- 选题价值:2.0/2:选题精准对接了实际应用中的硬核痛点(复杂声场鲁棒ER),具有高研究价值和明确的应用前景。论文填补了多通道信号处理与情感识别交叉领域的重要空白。
- 开源与复现加成:0.5/1:论文提供了一个在线Demo(https://SEUJames23.github.io/MCSE-ER/)用于效果展示,这是加分项。然而,论文中未提及代码开源、模型权重发布或提供可复现的完整训练配置,因此对于学术社区和工业界来说,复现门槛仍然较高。