📄 MSCT: Differential Cross-Modal Attention for Deepfake Detection
#音频深度伪造检测 #注意力机制 #音视频 #多模态模型
✅ 6.5/10 | 前10% | #音频深度伪造检测 | #注意力机制 | #音视频 #多模态模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -1.0 | 置信度 高
👥 作者与机构
- 第一作者:Fangda Wei(北京理工大学)
- 通讯作者:Shenghui Zhao(北京理工大学,有星号标记)
- 作者列表:Fangda Wei(北京理工大学),Miao Liu(北京理工大学),Yingxue Wang(中国电子技术标准化研究院),Jing Wang(北京理工大学),Shenghui Zhao(北京理工大学),Nan Li(中国电子技术标准化研究院)
💡 毒舌点评
论文提出的“差分跨模态注意力”(DCA)模块设计巧妙,其通过注意力矩阵相减来增强模型对伪造内容敏感性的思路,确实指出了传统注意力机制在伪造检测任务中可能存在的目标冲突问题,是一个不错的洞察。然而,如此强调性能提升的论文,却在开源复现信息上“一毛不拔”,连基础的代码仓库或超参数都不公开,这无异于在沙滩上画出宏伟蓝图却不提供任何工具,对推动整个领域的可复现进步毫无贡献。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用公开数据集FakeAVCeleb,但论文中未说明获取方式(通常可公开获取)。
- Demo:未提供在线演示。
- 复现材料:未提供详细的训练配置、超参数、检查点或附录说明。
- 论文中引用的开源项目:引用了DLIB(用于人脸检测)、Res2Net、CBAM、Wavelet Convolution等工具或模型,但未说明是否基于其开源代码。
- 总体开源计划:论文中未提及任何开源计划。
📌 核心摘要
- 要解决的问题:现有音频-视觉深度伪造检测方法主要依赖跨模态对齐,但传统的跨模态注意力机制可能与对齐损失目标冲突(对伪造内容不敏感),且缺乏有效的多尺度时间特征提取。
- 方法核心:提出多尺度跨模态Transformer编码器(MSCT),包含两个核心模块:差分跨模态注意力(DCA) 和 多尺度自注意力(MSSA)。DCA通过计算自注意力矩阵与跨模态注意力矩阵的差值,增强对伪造线索的关注。MSSA使用不同尺度的卷积处理Key矩阵,以整合相邻嵌入的多尺度时间信息。
- 与已有方法相比新在哪里:与传统跨模态注意力相比,DCA能更好地适配基于对齐损失的伪造检测任务;与标准自注意力相比,MSSA提供了更丰富的时间尺度感知能力,弥补了帧级特征提取的不足。
- 主要实验结果:在FakeAVCeleb数据集上,该方法取得了98.75%的准确率(ACC) 和 98.83%的AUC,显著优于表1中列出的所有基线方法,包括ACC为94.05%的MRDF-CE和96.30%的BusterX。消融实验(表2)表明,DCA模块(+1.25% ACC)比MSSA模块(+0.25% ACC)带来更大的性能增益。T-SNE可视化(图5)显示,本方法能更好地区分类别。
- 实际意义:提升了音视频深度伪造检测的准确性和鲁棒性,为多媒体内容安全提供了更强大的技术工具。
- 主要局限性:实验仅在单一数据集FakeAVCeleb上进行,缺乏跨数据集泛化性验证;未提供代码和详细复现参数,可复现性极差;与最新方法BusterX的对比缺少AUC指标。
🏗️ 模型架构
本文提出的多尺度跨模态Transformer编码器(MSCT)框架如图2所示,包含单模态特征提取和多模态特征融合两大模块。
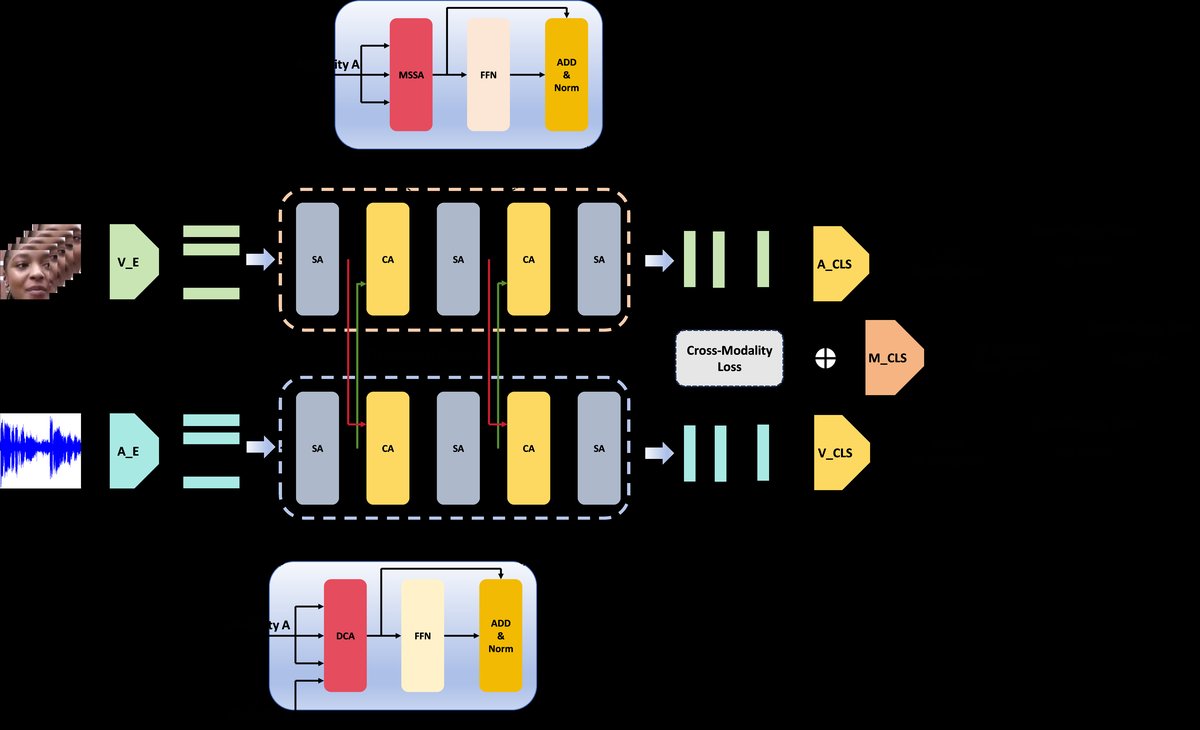
- 预编码器:分别对音频(A_E)和视觉(V_E)输入进行处理。音频输入经过线性投影层;视觉输入使用集成了小波卷积和CBAM的改进版Res2Net,以提取多尺度视觉特征。
- Transformer编码器:核心融合模块,包含6个Transformer块。每个块内集成本文提出的两个核心注意力模块:
- 多尺度自注意力(MSSA):用于提取单模态内部的多尺度时间特征。
- 差分跨模态注意力(DCA):用于融合来自两个模态的特征。以模态A为例,其结构如图3所示。
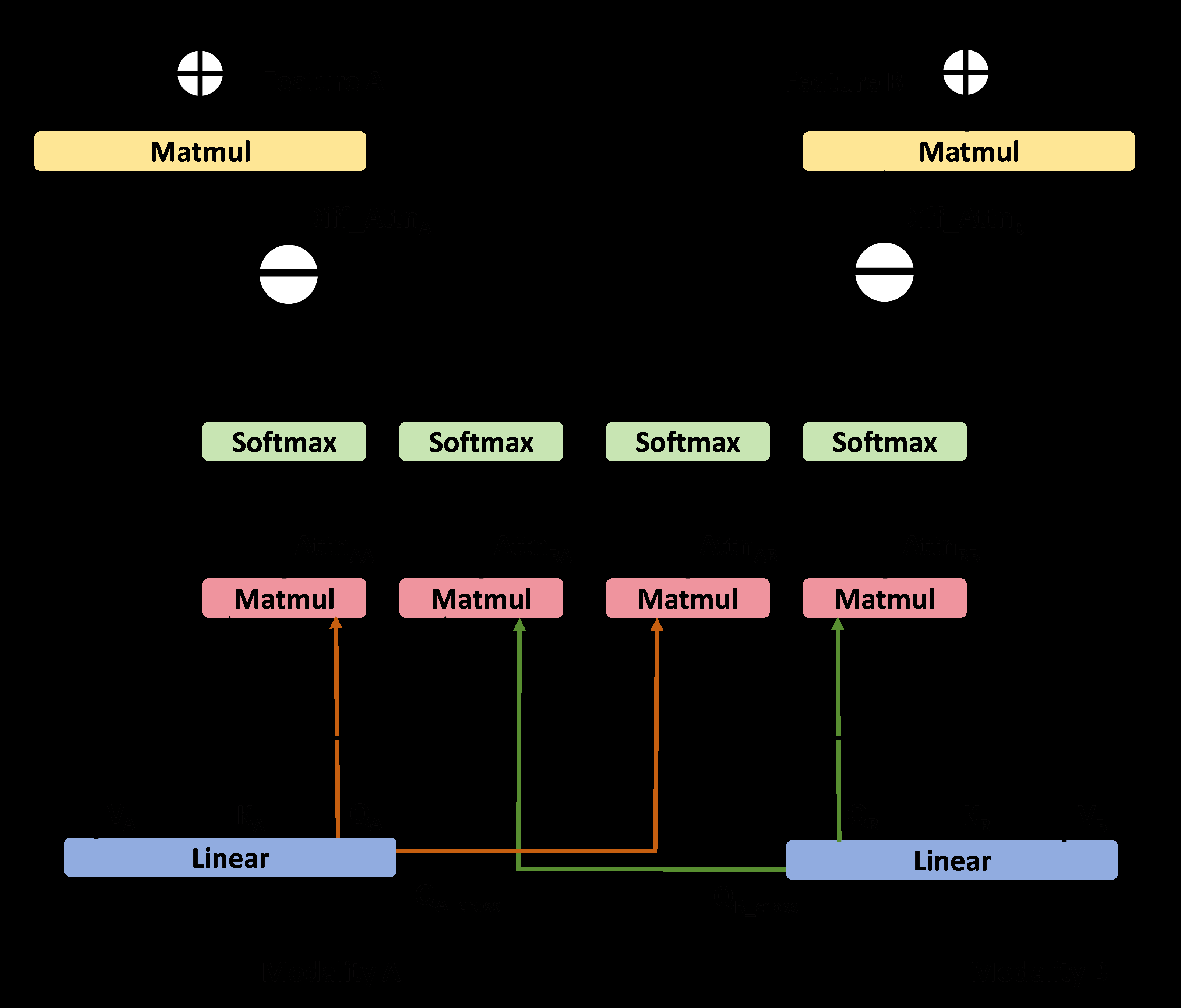 DCA模块接收来自模态B的查询(Q_B^cross)和模态A的键(K_A���、值(V_A)。它首先计算传统的跨模态注意力矩阵Attn_BA = Q_B^cross K_A^T,以及模态A的自注意力矩阵Attn_AA = Q_A K_A^T。然后,计算二者的差值作为最终的注意力矩阵Diff_Attn_A = Attn_AA - Attn_BA。最后,用此差值注意力矩阵与V_A相乘得到输出。其设计动机是:对于伪造视频,跨模态对齐损失会强烈约束Attn_BA,而Attn_AA不受影响,因此差值Diff_Attn_A会被放大,从而增强模型对伪造线索的敏感度。
DCA模块接收来自模态B的查询(Q_B^cross)和模态A的键(K_A���、值(V_A)。它首先计算传统的跨模态注意力矩阵Attn_BA = Q_B^cross K_A^T,以及模态A的自注意力矩阵Attn_AA = Q_A K_A^T。然后,计算二者的差值作为最终的注意力矩阵Diff_Attn_A = Attn_AA - Attn_BA。最后,用此差值注意力矩阵与V_A相乘得到输出。其设计动机是:对于伪造视频,跨模态对齐损失会强烈约束Attn_BA,而Attn_AA不受影响,因此差值Diff_Attn_A会被放大,从而增强模型对伪造线索的敏感度。
- 多尺度自注意力(MSSA):如图4所示。它接收Q, K, V,将K沿着注意力头维度分割成四部分,每部分用不同尺度的2D卷积处理(以捕获不同时间尺度的邻近信息),然后拼接并与Q相乘生成注意力矩阵,最后与V相乘得到输出。
图4:多尺度自注意力(MSSA)模块]
- 分类器:将两个模态Transformer输出的分类token(z_cls)拼接后,输入分类头进行最终的二分类(真/假)预测。
数据流:输入音频和视频序列 -> 预编码器提取单模态特征 -> 特征序列送入6层Transformer块,每层依次进行MSSA(单模态)和DCA(跨模态)操作 -> 每个模态输出分类token -> 拼接 -> 分类器输出预测概率。
💡 核心创新点
- 差分跨模态注意力(DCA):这是本文最主要的创新。它是什么:通过计算自注意力矩阵与跨模态注意力矩阵的差值来生成新的注意力权重。之前方法的局限:传统跨模态注意力在配合跨模态对齐损失时,可能削弱模型对伪造区域的关注。如何起作用:利用差值操作,使得伪造视频中被对齐损失强烈约束的跨模态注意力被抵消,而自注意力部分得以凸显,从而引导模型聚焦于伪造痕迹。收益:带来了最显著的性能提升(消融实验证明),使模型更适配伪造检测任务。
- 多尺度自注意力(MSSA):它是什么:通过多尺度卷积处理K矩阵,使每个嵌入能自适应地聚合邻近时间尺度的信息。之前方法的局限:标准自注意力缺乏显式的多尺度时间建模能力,帧级特征提取可能遗漏上下文信息。如何起作用:卷积核的不同感受野捕捉不同时间跨度的依赖关系,增强了表示的丰富性和灵活性。收益:提供了补充的性能增益,增强了模型的时间感知能力。
- 针对任务的注意力机制设计:将注意力机制的设计与下游任务(伪造检测)的具体损失函数和目标紧密结合,而非简单套用通用模块。这体现了方法设计的针对性和目的性。
🔬 细节详述
- 训练数据:在FakeAVCeleb数据集上进行评估。该数据集包含500个真实视频和超过20,000个伪造视频,分为RARV、FARV、RAFV、FAFV四类。数据划分保持1:1:1:1的比例。预处理使用DLIB检测人脸关键区域并裁剪作为输入。
- 损失函数:总损失L = λ_a_ce L_a_ce + λ_v_ce L_v_ce + λ_av_ce L_av_ce + λ_c L_c。其中:
- L_ce:标准交叉熵损失,用于单模态和多模态分类。
- L_c:跨模态对齐损失(公式3)。对于真实样本(y^n_av=1),最大化音频和视频输出嵌入的余弦相似度dn;对于伪造样本(y^n_av=1),通过max(0, dn)惩罚相似度。未说明具体的权重超参数λ_a_ce, λ_v_ce, λ_av_ce, λ_c的取值。
- 训练策略:使用Adam优化器训练200个epoch。未说明学习率、batch size、学习率调度策略、warmup等关键细节。
- 关键超参数:Transformer模块包含6个Transformer块。未说明隐藏维度C、注意力头数h、多尺度卷积的具体核大小等。
- 训练硬件:论文中未提及训练所使用的GPU/TPU型号、数量或训练时长。
- 推理细节:论文中未提及推理阶段的特殊设置,如解码策略、温度等。
- 正则化技巧:除了损失函数中的模态特定正则化(L_ce)外,论文中未明确提及其他如Dropout、权重衰减等技巧。
📊 实验结果
主要对比结果(来自Table 1):
| 方法 | ACC ↑ | AUC ↑ |
|---|---|---|
| VFD [12] | 81.52 | 86.11 |
| MDS [8] | 82.80 | 86.50 |
| AVOID-DF [13] | 83.70 | 89.20 |
| MRDF-CE [6] | 94.05 | 92.43 |
| BusterX [14] | 96.30 | - |
| Ours | 98.75 | 98.83 |
分析:本文方法在FakeAVCeleb数据集上取得了显著最优的性能,ACC比次优方法(BusterX)高出2.45个百分点,AUC比次优方法(MRDF-CE)高出6.4个百分点。
消融实验结果(来自Table 2):
| 模型 (注意力层) | ACC ↑ | AUC ↑ |
|---|---|---|
| CA + SA | 96.75 | 96.17 |
| CA + MSSA | 97.00 | 97.00 |
| DCA + SA | 98.00 | 98.00 |
| DCA + MSSA | 98.75 | 98.83 |
分析:
- 用DCA替换CA(DCA+SA)比用MSSA替换SA(CA+MSSA)带来了更大的性能提升(ACC +1.25% vs +0.25%),表明DCA是更关键的创新点。
- 两个模块结合(DCA+MSSA)取得了最佳性能,证明了模块间的互补性。
可视化结果:图5展示了不同模型配置下T-SNE的特征分布。
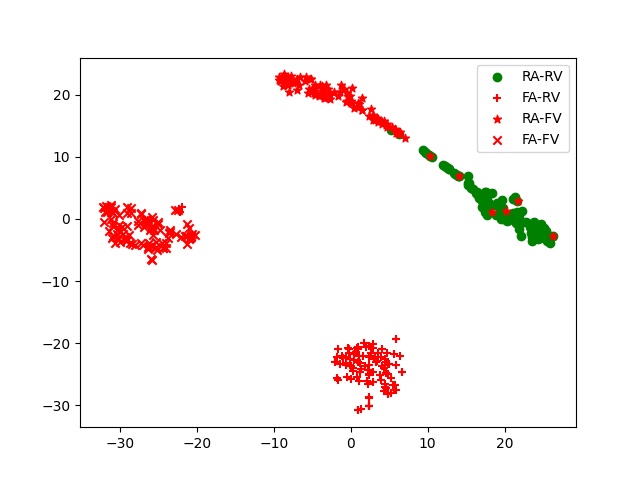 分析:基线模型(CA+SA)难以区分“真实音频-真实视频”(RA-RV)和“真实音频-伪造视频”(RA-FV)类别。而本文方法(DCA+MSSA)的特征分布中,不同类别分离度更高,特别是RA-RV和RA-FV之间的界限更清晰,直观验证了模型判别能力的提升。
分析:基线模型(CA+SA)难以区分“真实音频-真实视频”(RA-RV)和“真实音频-伪造视频”(RA-FV)类别。而本文方法(DCA+MSSA)的特征分布中,不同类别分离度更高,特别是RA-RV和RA-FV之间的界限更清晰,直观验证了模型判别能力的提升。
⚖️ 评分理由
- 学术质量:6.0/7。创新性体现在针对性设计了DCA和MSSA两个模块,思路清晰。技术正确性通过充分的消融实验得到验证。实验充分性方面,在标准数据集上进行了对比和消融,但缺乏跨数据集验证。证据可信度较高,结果提升显著。扣分主要原因:实验局限单一数据集;与最强基线对比不完整;大量关键复现信息缺失。
- 选题价值:1.5/2。选题紧扣深度伪造检测前沿,具有明确的现实意义和应用价值。音视频多模态检测是重要方向。扣分原因:任务领域相对垂直,对广大音频/语音处理读者的普适性价值中等。
- 开源与复现:-1.0/1。论文未提供代码、模型、数据、训练细节、超参数等任何可复现材料,完全无法被复现和验证,严重影响其学术贡献的可信度和社区价值。