📄 MR-FlowDPO: Multi-Reward Direct Preference Optimization for Flow-Matching Text-to-Music Generation
#音乐生成 #流匹配 #强化学习 #自监督学习 #模型评估
✅ 7.5/10 | 前25% | #音乐生成 | #流匹配 | #强化学习 #自监督学习
学术质量 7.0/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Alon Ziv(FAIR Team, Meta MSL & The Hebrew University of Jerusalem)
- 通讯作者:未说明
- 作者列表:Alon Ziv(FAIR Team, Meta MSL & The Hebrew University of Jerusalem), Sanyuan Chen(FAIR Team, Meta MSL), Andros Tjandra(FAIR Team, Meta MSL), Yossi Adi(FAIR Team, Meta MSL & The Hebrew University of Jerusalem), Wei-Ning Hsu(FAIR Team, Meta MSL), Bowen Shi(FAIR Team, Meta MSL)
💡 毒舌点评
亮点:该工作的核心亮点在于其系统性思维,将单一、模糊的“人类偏好”拆解为文本对齐、制作质量、语义一致性三个可量化的奖励维度,并设计了“强支配对”的配对策略来解决多目标优化中的样本构建难题,这一框架对后续所有基于偏好优化的生成模型都有参考价值。短板:论文在核心生成模型的架构细节上着墨极少,只说明了是Flow-Matching模型,但并未深入描述其具体结构,使得分析停留在“偏好优化外挂”的层面;此外,所用的制作质量预测器和语义一致性评估器本身都依赖于外部预训练模型,这可能会限制该方法在缺乏这些基础模型的场景下的直接应用。
🔗 开源详情
- 代码:提供。论文明确给出了GitHub仓库链接:
https://github.com/lonzi/mrflow_dpo/。 - 模型权重:未提及。
- 数据集:使用了Shutterstock和Pond5的授权数据,未提及是否公开或如何获取。评估使用了公开的MusicCaps。
- Demo:提供。论文给出了在线演示页面:
https://lonzi.github.io/mr_flowdpo_demopage。 - 复现材料:论文提供了关键的训练超参数(学习率、批量大小、优化器设置、DPO轮次等)和数据构建流程。未提供预训练的奖励模型(CLAP、Aesthetics预测器、HuBERT)的具体版本或权重链接。
- 论文中引用的开源项目:CLAP模型(
lukewys/laion_clap), librosa(用于BPM估计),参考模型MelodyFlow(可能基于开源代码)。
📌 核心摘要
- 要解决的问题:音乐生成模型难以与主观、多变的人类偏好对齐,传统单目标优化方法在文本对齐、音频质量和音乐性(如节奏稳定性)之间难以兼顾。
- 方法核心:提出MR-FlowDPO,一个用于微调Flow-Matching文本到音乐生成模型的多奖励直接偏好优化框架。其核心包括:(1) 设计并整合文本对齐(CLAP)、制作质量(Aesthetics预测器)和语义一致性(自训练HuBERT)三个奖励函数;(2) 提出“多奖励强支配”偏好数据对构建算法,确保正样本在所有奖励维度上均优于负样本;(3) 引入奖励提示机制,将奖励值信息融入文本输入。
- 与已有方法的对比:区别于先前仅优化单一文本对齐奖励的方法,该工作首次在Flow-Matching音乐生成中实现多维度奖励的联合优化。相较于TangoFlux等工作,其引入了专门的语义一致性奖励来解决节奏不稳定问题,并提出了更严谨的偏好数据配对策略。
- 主要实验结果:在MusicCaps基准上,MR-FLOWDPO-1B模型将节奏稳定性指标BPM标准差从基线的9.09降至6.11;在人类评估中,相对于强基线MelodyFlow-1B,在整体偏好、音频质量和音乐性上均取得显著胜率(如整体偏好胜率+16.67%,音频质量+43.26%)。关键消融实验证明,三个奖励轴缺一不可,且强支配配对策略和奖励提示机制均对性能有显著提升。
- 实际意义:为音乐生成乃至更广泛的音频内容生成领域提供了一套可扩展的偏好对齐范式,能够系统性地提升生成内容的多方面品质,减少“对齐税”。
- 主要局限性:生成模型本身的架构创新有限;评估高度依赖预训练的奖励模型,其本身的偏见和局限性会被引入;论文未深入探讨该方法在更长时长(如完整歌曲)生成任务上的适用性。
🏗️ 模型架构
MR-FlowDPO是一个针对Flow-Matching模型的微调框架,而非一个端到端的新模型。其整体流程如下:
- 参考模型(Reference Model):作为起点的预训练Flow-Matching文本到音乐生成模型(如论文中使用的Flow-400M或MelodyFlow-1B)。
- 奖励模块(Reward Modules):
- 文本奖励(Text Reward):使用在音乐数据上训练的CLAP模型,计算生成音频与文本描述的余弦相似度,衡量文本对齐程度。
- 制作质量奖励(Production Quality Reward):使用一个预训练的回归Transformer模型(Meta AudioBox Aesthetics),预测音频的美学分数(1-10分),评估清晰度、动态等声学特性。
- 语义一致性奖励(Semantic Consistency Reward):这是论文的核心创新组件。它使用一个在目标音乐数据上重新训练的HuBERT模型。对于生成的音频X,首先进行无掩码前向传播得到各层特征;然后计算第n层特征与聚类中心的相似度概率;最终得分是所有时间步上最可能token概率对数的平均值。该分数作为音乐序列合理性和节奏稳定性的代理指标。
- 偏好数据构建与DPO训练:利用上述三个奖励,通过“多奖励强支配”算法从参考模型生成的样本池中挑选出成对的偏好数据(Xw, Xl, Y),其中Xw在所有三个奖励上均强于Xl。然后,使用这些数据对Flow-Matching模型进行DPO微调。损失函数是DPO-diffusion损失的变体,优化目标是最大化正样本向量场预测的似然,同时最小化负样本的似然。
- 奖励提示(Reward Prompting):在DPO训练时,将正样本的奖励值作为自然语言字符串前置到文本描述Y中,一同作为模型输入。在推理时,则将训练集中奖励值的99百分位数作为理想奖励值,同样提示给模型,引导其生成高质量输出。
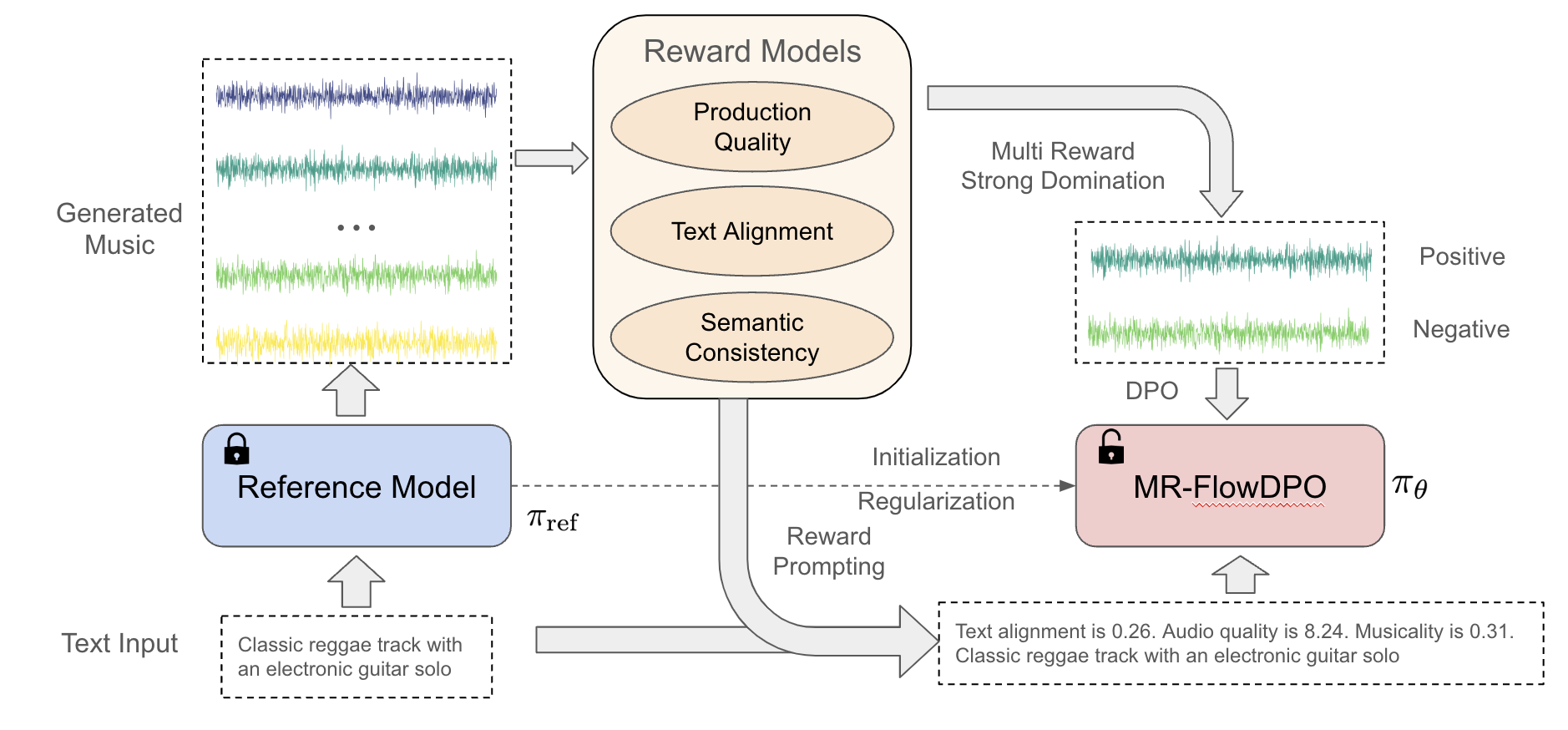 图1说明:展示了MR-FlowDPO的工作流程。首先,参考模型(Ref Model)根据文本提示(Text Prompt)生成多个音乐样本。然后,每个样本经过三个奖励模块(如制作质量预测器)进行打分。接着,根据这些分数,通过配对策略(Pairing)挑选出偏好对(Preference pairs)。最后,使用这些偏好对,通过DPO损失函数对参考模型进行微调,得到MR-FlowDPO模型。图中特别标注了奖励提示机制(Reward Prompting)。
图1说明:展示了MR-FlowDPO的工作流程。首先,参考模型(Ref Model)根据文本提示(Text Prompt)生成多个音乐样本。然后,每个样本经过三个奖励模块(如制作质量预测器)进行打分。接着,根据这些分数,通过配对策略(Pairing)挑选出偏好对(Preference pairs)。最后,使用这些偏好对,通过DPO损失函数对参考模型进行微调,得到MR-FlowDPO模型。图中特别标注了奖励提示机制(Reward Prompting)。
💡 核心创新点
- 多奖励维度对齐框架:首次在音乐生成中系统地整合并优化文本对齐、制作质量和语义一致性三个关键维度,超越了以往仅关注单一指标的工作。这更全面地刻画了“好音乐”的标准。
- 基于自监督表示的语义一致性奖励:提出了一种新颖的、无需人工标注的奖励函数。它利用在音乐数据上重新训练的HuBERT模型,通过计算其离散token序列的似然来量化生成音乐的内在连贯性和节奏稳定性,有效解决了基线模型节奏混乱的问题(BPM-std显著下降)。
- 多奖励强支配配对策略(MRSD):为平衡多个可能冲突的奖励目标,设计了严格的偏好对选择算法。它要求正样本不仅在某个主要奖励上远超负样本,还要在其他所有次要奖励上也超过一定阈值,从而确保每个偏好对都提供了清晰、无歧义的优化信号,使模型能均衡地提升所有维度。
- 奖励提示机制:将奖励评分信息作为条件输入给生成模型。在训练时使用真实正样本的奖励,在推理时使用理想化的高分,这相当于为模型提供了一个明确的“优化目标指示器”,引导模型生成符合预期高奖励分布的音乐。
🔬 细节详述
- 训练数据:
- 预训练数据:遵循先前工作设置,使用来自Shutterstock和Pond5的授权音乐数据集,约2万小时音乐,以及额外的2.5万和37.5万条纯乐器音轨。采样率为32kHz,配有文本描述。
- DPO数据:随机采样20K文本提示,每个提示用参考模型生成k=16个样本,构成样本池。对每个奖励轴,通过MRSD算法筛选出R=30K个三元组(Xw, Xl, Y),总计90K个三元组。
- 评估数据:公开基准MusicCaps(5.5K样本,10秒)用于目标评估;从中筛选100样本进行人工评估;另使用1K条未见过的专有高质量纯器乐测试集进行消融研究。
- 损失函数:采用基于Flow-Matching的DPO损失(公式2)。该损失鼓励模型在时间步t上,对于正样本zw,其预测向量场与目标向量场的误差小于负样本zl的误差,误差大小由参考模型的误差进行基准化。
- 训练策略:
- 优化器:AdamW, β1=0.9, β2=0.999, ϵ=1e-8, 权重衰减1e-2。
- 学习率:峰值1e-6,线性预热1000步,然后线性衰减。
- 批大小:32。
- 训练轮数:10个DPO轮次。
- DPO温度:β=2000。
- 关键超参数:
- 生成样本池参数:N=20K提示, k=16样本/提示。
- 强支配阈值:主奖励使用95百分位差值,次奖励使用中位数差值。
- 语义一致性奖励的HuBERT温度τ:未说明具体数值。
- BPM稳定性评估窗口:3.33秒。
- 训练硬件:论文中未提及GPU/TPU型号、数量及训练时长。
- 推理细节:推理时,将训练集奖励值的99百分位(对应极高质量)作为奖励提示文本,与用户输入的文本描述拼接后,输入微调后的模型生成音乐。未提及解码策略、温度等更多细节。
- 正则化:未明确提及除DPO本身隐含的正则化外的额外技巧。
📊 实验结果
表1. 目标评估(在MusicCaps上)
| 方法 | Aes ↑ | EA ↑ | CLAP ↑ | BPM-std ↓ | FAD ↓ |
|---|---|---|---|---|---|
| MusicGen | 7.17 | 6.72 | 0.29 | 7.60 | 4.69 |
| MelodyFlow-1B | 7.13 | 6.69 | 0.29 | 8.01 | 4.96 |
| AudioLDM2 | 7.10 | 5.88 | 0.30 | 7.66 | 5.14 |
| Flow-400M (参考模型) | 7.08 | 6.50 | 0.29 | 9.09 | 2.70 |
| Flow-400M+RP | 8.25 | 7.08 | 0.27 | 8.67 | 8.73 |
| OnlySFT | 6.91 | 6.13 | 0.30 | 10.14 | 3.38 |
| MR-FLOWDPO-400M | 8.10 | 7.18 | 0.28 | 7.57 | 6.47 |
| MR-FLOWDPO-1B | 8.26 | 7.72 | 0.27 | 6.11 | 11.26 |
| 结论:MR-FlowDPO在音频制作质量(Aes)和内容享受度(EA)上显著超越基线。其节奏稳定性(BPM-std)是所有方法中最低的,证实了语义一致性奖励的有效性。但FAD分数较高,表明其整体音频特征分布与真实数据存在差异。 |
表2. 人工评估净胜率(%)
| 模型比较 | 整体偏好(OP) | 音频质量(AQ) | 文本对齐(TA) | 音乐性(M) |
|---|---|---|---|---|
| Ours-400M vs. Flow-400M | 25.02±12.00 | 12.46±12.40 | 24.10±11.60 | 20.37±12.30 |
| Ours-400M vs. MusicGen | 2.23±11.70 | 17.09±10.30 | -2.88±10.20 | 2.65±11.30 |
| Ours-400M vs. AudioLDM2 | 36.67±10.70 | 56.72±7.70 | 15.04±10.60 | 32.66±11.20 |
| Ours-1B vs. MelodyFlow | 16.67±10.00 | 43.26±10.50 | 1.88±9.30 | 17.00±10.30 |
| 结论:MR-FlowDPO-400M在所有指标上大幅超越其参考模型Flow-400M。MR-FlowDPO-1B在音频质量和音乐性上显著优于强大的基线MelodyFlow-1B,但在文本对齐上与之持平。 |
 图2说明:展示了MR-FLOWDPO-1B相对于MelodyFlow-1B在四个评估维度上的净胜率。在音频质量(~43%)和音乐性(~17%)上优势明显,在整体偏好上也获得正胜率(~17%),文本对齐上略有优势但置信区间包含零,表明两者相当。
图2说明:展示了MR-FLOWDPO-1B相对于MelodyFlow-1B在四个评估维度上的净胜率。在音频质量(~43%)和音乐性(~17%)上优势明显,在整体偏好上也获得正胜率(~17%),文本对齐上略有优势但置信区间包含零,表明两者相当。
表3. 消融研究:奖励构成与边际阈值影响(在内部测试集上) 奖励构成:
| 方法 | Aes ↑ | EA ↑ | CLAP ↑ | BPM ↓ | FAD ↓ |
|---|---|---|---|---|---|
| Ref | 7.58 | 6.90 | 0.33 | 7.77 | 0.78 |
| +TR (仅文本) | 7.80 | 7.21 | 0.38 | 8.40 | 1.04 |
| +TR+AR | 8.33 | 7.47 | 0.35 | 8.06 | 1.99 |
| +TR+AR+SR (完整) | 8.26 | 7.55 | 0.37 | 6.00 | 1.76 |
| 结论:加入语义一致性奖励(SR)后,BPM标准差从8.06锐减至6.00,且美学和CLAP分数保持高位,证明了三奖励协同的有效性。仅用文本奖励优化会导致节奏变差。 |
奖励边际阈值(百分位数):
| 百分位 | Aes ↑ | EA ↑ | CLAP ↑ |
|---|---|---|---|
| 25 | 7.95 | 7.32 | 0.36 |
| 50 | 7.99 | 7.27 | 0.36 |
| 75 | 8.03 | 7.21 | 0.36 |
| 95 | 8.07 | 7.42 | 0.38 |
| 结论:选择更大的奖励边际(如95百分位)能带来更高的美学和CLAP分数。 |
表4. 消融���究:奖励提示与MRSD策略 奖励提示:
| 方法 | Aes ↑ | EA ↑ | CLAP ↑ | BPM ↓ | FAD ↓ |
|---|---|---|---|---|---|
| Ref | 7.58 | 6.90 | 0.33 | 7.77 | 0.78 |
| MR-FLOWDPO w/o Prompting | 8.20 | 7.21 | 0.35 | 7.30 | 2.10 |
| MR-FLOWDPO (完整) | 8.26 | 7.55 | 0.37 | 6.00 | 1.76 |
| 结论:奖励提示机制在所有指标上均有提升,尤其显著改善了节奏稳定性(BPM)和美学分数。 |
MRSD策略:
| 方法 | Aes ↑ | EA ↑ | CLAP ↑ | BPM ↓ | FAD ↓ |
|---|---|---|---|---|---|
| Ref | 7.58 | 6.90 | 0.33 | 7.77 | 0.78 |
| MR-FLOWDPO w/o MRSD | 7.99 | 7.43 | 0.37 | 6.84 | 0.76 |
| MR-FLOWDPO (完整) | 8.26 | 7.55 | 0.37 | 6.00 | 1.76 |
| 结论:MRSD策略进一步提升了美学分数和节奏稳定性,表明严格的偏好对选择能带来更均衡、更好的优化效果。 |
⚖️ 评分理由
- 学术质量(6.5/7):创新性体现在将多目标优化系统性地引入音乐生成偏好对齐,并提出了针对性的奖励函数和数据构建算法。技术实现正确,基于成熟的Flow-Matching和DPO框架。实验设计全面,包括与多个强基线的对比、详尽的消融研究以及客观指标与人工评估的双重验证,证据链条完整可信。扣分点在于生成模型本身的架构创新不足,且部分关键训练硬件信息缺失。
- 选题价值(2.0/2):选题直击音乐生成从“能用”到“好用”的核心瓶颈——人类偏好对齐。提出的多维度评估和优化思路具有前瞻性,其方法论可迁移至语音合成、音频生成等其他领域。代码开源,Demo直观,应用潜力大。
- 开源与复现加成(0.5/1):提供了代码仓库(
https://github.com/lonzi/mrflow_dpo/)和详细的Demo页面(https://lonzi.github.io/mr_flowdpo_demopage),包含了复现所需的主要代码和配置信息。但未开源模型权重、完整训练数据集和详细的训练硬件环境配置,因此无法给予满分。