📄 Modeling Inter-Segment Relationships in Speech for Dementia Detection with Audio Spectrogram Transformers and Graph Attention Networks
#语音生物标志物 #音频大模型 #图神经网络 #预训练 #音频分类
✅ 7.0/10 | 前25% | #语音生物标志物 | #图神经网络 | #音频大模型 #预训练
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Raphael Anaadumba (University of Massachusetts Lowell, Richard A. Miner School of Computer and Information Sciences)
- 通讯作者:Raphael Anaadumba (根据“Corresponding author”标注)
- 作者列表:Raphael Anaadumba (University of Massachusetts Lowell), Nazim A. Belabbaci (University of Massachusetts Lowell), Anton Kovalev (University of Massachusetts Lowell), Mohammad Arif Ul Alam (University of Massachusetts Lowell)
💡 毒舌点评
本文巧妙地将图注意力网络引入语音病理分析,首次明确建模“语音段”间的图状关系以捕捉话语结构异常,这一视角确实比简单池化或纯序列模型更贴近临床认知,并在MCI检测上取得了亮眼提升。然而,实验规模局限于两个英语数据集,且未开源代码,使得这一新颖方法在更广泛场景下的有效性和可复现性大打折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:使用了公开的预训练AST模型(MIT/ast-finetuned-audioset-10-10-0.4593),但本文训练的GAT部分权重未提及公开。
- 数据集:使用的DementiaBank Pitt Corpus和TAUKADIAL数据集为公开数据集,论文提供了访问方向(但未提供直接链接)。
- Demo:未提及。
- 复现材料:论文给出了主要超参数(学习率、权重衰减、k值、窗口大小)、硬件信息和评估协议(10折交叉验证),但缺乏代码、完整的训练日志、配置文件等关键复现材料。
- 论文中引用的开源项目:主要依赖预训练模型AST和图注意力网络(GAT)的经典实现,未引用特定工具库。框架使用PyTorch和PyTorch Geometric。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 本文旨在解决基于语音的痴呆症自动检测中,现有方法普遍忽略话语层面段间依赖关系的问题。这些复杂的图状关系被认为是认知障碍的早期标志,尤其是在局部声学特征尚未明显退化的轻度认知障碍(MCI)阶段。
- 方法核心是提出一个AST+GAT框架:首先将音频分割为重叠窗口,用预训练的AST提取每个窗口的声谱图嵌入并拼接韵律特征;然后构建一个同时包含时间邻接边和基于嵌入相似度的k近邻边的图;最后使用图注意力网络处理该图,学习一个整体的表征用于分类或回归。
- 与已有方法相比,新在显式地将语音片段视为图节点,并使用GAT来捕捉片段间的非序列化关系,而不仅仅是依赖AST自身的全局池化或顺序注意力机制。
- 主要实验结果:在DementiaBank Pitt Corpus(痴呆症检测)和TAUKADIAL(MCI检测)数据集上,AST+GAT相比AST-only基线,分类准确率分别提升了9.7%(70.8% → 80.5%)和30.5%(51.3% → 81.8%)。在MMSE预测回归任务上,RMSE分别降低了7%和38%。消融实验证明时间骨架和k近邻边都对性能有贡献。
- 实际意义:该方法为早期、无创的痴呆症筛查提供了一种有潜力的自动化工具,尤其适用于远程医疗和资源有限的场景。其强调的“话语结构异常早于声学退化”的发现,对理解认知障碍的语音生物标志物有启发意义。
- 主要局限性:研究仅限于两个英语语言数据集,且任务类型单一(图片描述/流畅度)。模型依赖固定的分割参数和k值,未探索其最优性。缺乏前瞻性、多中心的外部验证。未提供开源代码,限制了复现和扩展。
🏗️ 模型架构
模型架构如图1所示,整体分为三个阶段:音频编码、图构建和图分类。
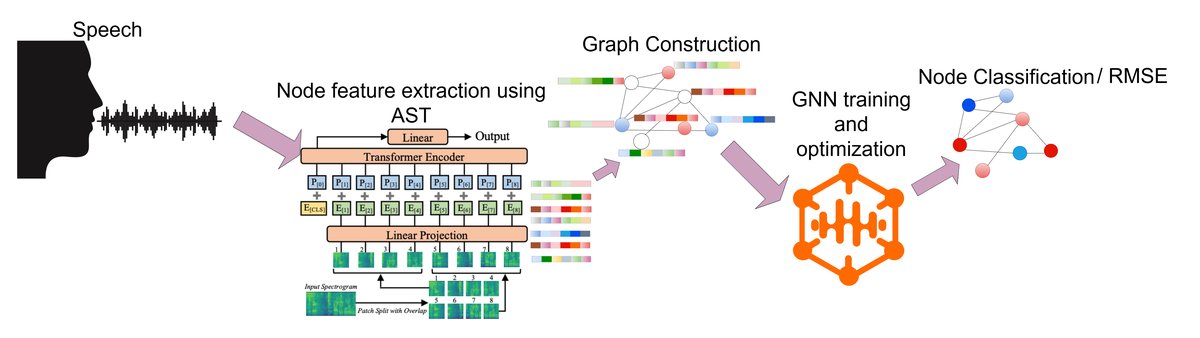
音频分割与节点特征提取:输入一段完整的自发语音。首先将其分割为
Nw个重叠的10秒窗口(窗口步长5秒)。每个窗口wi送入一个预训练的音频频谱图Transformer(AST,具体为ast-finetuned-audioset-10-10-0.4593),移除其分类头,对最终隐藏状态进行全局平均池化,得到一个768维的谱时序嵌入ei。同时,从整个录音中提取一个共享的5维声调特征向量s(包含时长、RMS能量、平均停顿时长、停顿频率、语音静默比)。将每个窗口的AST嵌入ei与这个全局声调特征s拼接,形成773维的节点特征向量xi。因此,一段语音被表示为一个包含Nw个节点的序列。关系图构建:基于
Nw个节点的特征表示,构建一个图G=(V, E)。节点集V对应所有窗口。边集E由两种连接构成:- 时间邻接边:将每个节点
i与其后继节点i+1连接,形成一条“时间骨架”,以保留话语的叙事流和时间顺序。 - 特征相似性边:计算所有节点AST嵌入
ei之间的余弦相似度。对于每个节点i,将其与相似度最高的k(本文设为3)个其他节点连接,形成k近邻(k-NN)图。这允许模型连接时间上相距遥远但声学特征相似的语音片段。
- 时间邻接边:将每个节点
图注意力网络分类:构建好的图
G被送入一个两层的图注意力网络(GAT)。第一层GAT包含4个注意力头,用于计算多头注意力系数,融合邻居节点的信息。其输出送入第二层单头GAT进行特征细化。之后,对所有更新后的节点特征进行全局平均池化,得到一个固定维度的图级嵌入向量。该向量最后通过一个多层感知机(MLP)进行最终分类(痴呆/正常)或回归(预测MMSE分数)。
关键设计选择与动机:
- AST+韵律拼接:使用强大的预训练AST捕捉局部谱时序特征,拼接全局韵律特征以补充宏观的、已知的声学生物标志物信息。
- 混合图结构:单纯的时间边可能无法捕获话题回溯等非线性依赖;单纯的k-NN边可能破坏叙事流。混合图旨在同时建模这两种关键的话语依赖关系。
- 轻量GAT:在庞大的AST编码器(86.19M参数)之上,仅添加0.47M参数(~0.5%开销)的GAT层,以极低的计算成本实现关系建模能力的增强。
💡 核心创新点
- 显式建模语音段间图状关系:这是本文最核心的创新。它突破了将语音视为独立窗口序列或进行全局池化的常规思路,首次在痴呆症检测任务中,将语音片段作为节点,构建图结构来显式刻画片段间的依赖关系(包括时序和声学相似性),以更贴近话语层面的认知过程建模。
- 双通道关系图构建策略:提出了一种结合时间邻接边(保证叙事结构)和声学相似性k-NN边(捕捉话题一致性)的混合图构建方法。消融实验证明,两者缺一不可,共同构成了有效的关系建模基础。
- 轻量级GAT与强大预训练模型的集成:将参数量极小的GAT模块无缝集成到强大的预训练AST模型之上,在几乎不增加计算负担的前提下,赋予了模型捕捉高阶关系的能力,实现了性能上的显著提升。
- 对早期认知障碍(MCI)检测的有效性验证:实验证明,该关系建模方法在TAUKADIAL数据集(针对MCI)上的提升幅度(+30.5%准确率)远大于在Pitt Corpus(针对更晚期的AD)上的提升(+9.7%),从实证角度支持了“话语结构异常是MCI更敏感标志”的临床假说。
🔬 细节详述
- 训练数据:
- 数据集:DementiaBank Pitt Corpus(552样本,AD vs 控制)和TAUKADIAL-24英文子集(186样本,MCI vs 控制)。
- 预处理:将音频分割为10秒窗口,步长5秒。提取AST嵌入和5维声调特征。论文未详细说明音频预处理(如归一化、降噪)的具体步骤。
- 数据增强:未提及。
- 损失函数:分类任务使用带标签平滑(ϵ=0.1)的加权交叉熵损失。回归任务未具体说明损失函数,但提到评估MMSE预测。
- 训练策略:
- 优化器:AdamW,学习率
3e-4,权重衰减5e-4。 - 超参数:GAT第一层4个注意力头。k-NN的
k=3。 - 训练轮数:未明确说明总轮数,但采用了早停策略,基于验证集F1分数。
- 批大小:未说明。
- 优化器:AdamW,学习率
- 关键超参数:AST主干参数量86.19M;添加的GAT参数量0.47M;节点特征维度773。
- 训练硬件:NVIDIA A100 GPU。
- 推理细节:未提及,推测使用与训练相同的窗口划分和特征提取流程。
- 正则化:使用了权重衰减、标签平滑和早停。未提及Dropout等。
- 评估方式:采用说话人不重叠的分层10折交叉验证,以确保评估的鲁棒性和对未见说话人的泛化能力。
📊 实验结果
主要对比结果(表2):
| 数据集 | 方法 | 准确率 (%) | F1 (%) | UAR (%) |
|---|---|---|---|---|
| TAUKADIAL (英文子集) | Whisper fine-tuned [8] | 80.6 | 69.5 | 73.5 |
| AST [6] | 76.0 | 71.0 | 62.7 | |
| XLSR-53 [11] | 74.2 | 62.9 | 53.7 | |
| XLS-R [9] | 79.5 | 72.1 | 60.5 | |
| AST+GAT (本文) | 81.8 | 77.9 | 73.8 | |
| Pitt Corpus | ADReSSO Baseline [15] | 75.0 | 71.0 | - |
| GCNN [27] | 73.6 | - | - | |
| Wav2Vec [14] | 64.8 | 50.4 | - | |
| AST+GAT (本文) | 80.5 | 79.9 | 75.5 |
关键消融实验结果(表3):
| 指标 | Pitt Corpus | TAUKADIAL | ||||
|---|---|---|---|---|---|---|
| AST-only | Temporal-only | Full AST+GAT | AST-only | Temporal-only | Full AST+GAT | |
| 准确率 | 0.708 | 0.743 | 0.805 | 0.513 | 0.805 | 0.818 |
| F1分数 | 0.659 | 0.731 | 0.799 | 0.435 | 0.758 | 0.779 |
| UAR | 0.569 | 0.709 | 0.755 | 0.563 | 0.746 | 0.738 |
| AUROC | 0.600 | 0.804 | 0.802 | 0.474 | 0.645 | 0.728 |
- 关键发现1:AST-only基线在TAUKADIAL(MCI检测)上性能极差(准确率51.3%),接近随机猜测,而加入时间边(Temporal-only)后飙升至80.5%,表明对于早期认知障碍,话语时序结构至关重要。
- 关键发现2:在Pitt Corpus(AD检测)上,时间边和k-NN边都有显著贡献(分别提升+3.5%和+6.2%),表明晚期痴呆患者在声学相似片段上也存在异常。
MMSE回归结果(表4):
| 数据集 | AST-only | AST+GAT | 改进 |
|---|---|---|---|
| TAUKADIAL (RMSE↓) | 1.73 | 1.08 | -0.65 (38%降低) |
| Pitt Corpus (RMSE↓) | 5.67 | 5.27 | -0.40 (7%降低) |
- 关键发现3:关系建模同样提升了认知评分预测的精度,在MCI数据集上改进尤为显著。
⚖️ 评分理由
学术质量:6.0/7
- 创新性:明确提出了将语音段图建模应用于痴呆症检测的新范式,思路新颖且有临床依据支撑。
- 技术正确性:模型设计合理,图构建策略有消融实验验证,训练与评估设置严谨(分层交叉验证、说话人隔离)。
- 实验充分性:对比了多个主流音频模型基线,进行了充分的消融研究,覆盖了分类与回归两个任务。
- 证据可信度:实验结果一致且显著,但结论的普适性受限于数据集规模与多样性。
选题价值:2.0/2
- 前沿性:处于医疗AI与语音信号处理交叉领域的前沿,探索用计算模型捕捉认知疾病的细微语音标志。
- 潜在影响:为开发低成本、可扩展的痴呆症早期筛查工具提供了有希望的技术路径。
- 应用空间:直接应用于远程医疗、健康监测APP等场景,具有明确的实用价值。
- 读者相关性:对于从事音频分析、医疗AI、生物标志物研究的读者极具参考价值。
开源与复现加成:-0.5/1
- 论文详细报告了关键实验设置和超参数,但未提供任何代码、模型或处理后的数据链接。
- 依赖公开数据集(DementiaBank, TAUKADIAL)和公开预训练模型(AST),部分降低了复现门槛。
- 然而,图构建的细节(如如何高效计算大规模k-NN)、特征提取与融合的完整代码缺失,显著增加了复现难度。