📄 Modeling Both Intra- And Inter-Utterance Variability for Conversational Emotion Recognition
#语音情感识别 #图神经网络 #大语言模型 #多模态模型 #零样本
✅ 6.5/10 | 前25% | #语音情感识别 | #图神经网络 | #大语言模型 #多模态模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yumeng Fu(哈尔滨工业大学计算机科学与技术学院)
- 通讯作者:Bingquan Liu(哈尔滨工业大学计算机科学与技术学院)
- 作者列表:Yumeng Fu¹, Shouduo Shang¹, Junjie Wu², Meishan Zhang³, Bingquan Liu¹* ¹ 哈尔滨工业大学计算机科学与技术学院,哈尔滨,中国 ² 苏州大学计算机科学与技术学院,苏州,中国 ³ 哈尔滨工业大学计算机科学与技术学院,深圳,中国
💡 毒舌点评
亮点在于其将语音的“动态”信息(内部变异性和结构关系)显式编码为图,并设计适配器注入LLM,这比简单地将音频特征拼接或文本化要更精巧。短板是语音特征提取严重依赖另一个闭源或大型商用大模型(Qwen2-Audio),而非端到端学习,这在实用性和可复现性上打了折扣,且论文对提取的语音特征本身的准确性和鲁棒性缺乏验证。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开训练好的MM-VLN模型权重。
- 数据集:使用了公开的IEMOCAP和MELD数据集,论文未说明如何获取或处理,但数据集本身是公开的。
- Demo:未提供在线演示。
- 复现材料:提供了主要的实验设置(数据集、基础模型、LoRA、部分超参数),但关键细节如损失函数、图GAT的隐藏层维度、适配器的具体结构参数、完整的训练配置等缺失,完整复现存在困难。
- 论文中引用的开源项目:主要引用了LoRA、RoBERTa、BLIP-2等作为方法组件或灵感来源。核心依赖的预训练模型包括Llama3-8B、Qwen2.5-7B、Qwen2-Audio-7B-Instruct、RoBERTa和DSM话语解析模型,但这些均为第三方模型,并非本文开源。
📌 核心摘要
- 问题:现有基于LLM的对话情绪识别(ERC)方法主要关注文本,忽略了语音中丰富的声学特征(如音调、语速)以及对话本身的结构信息。
- 方法:提出多模态变异性学习网络(MM-VLN)。首先,利用一个大语言模型(Qwen2-Audio-7B-Instruct)提取每句话的内部语音变异性(音调、语速等)。其次,使用话语解析模型获取对话的句间依赖结构。然后,将语音变异性信息作为节点、对话结构作为边构建图,使用图注意力网络(GAT)进行编码。最后,通过一个跨注意力适配器将GAT的输出投影为“图令牌”,与文本嵌入拼接后输入LLM(Llama3-8B/Qwen2.5-7B)进行情绪预测。
- 创新点:首次将对话的语音结构信息(内部变异性和句间关系)通过图神经网络显式建模,并通过适配器无缝对接到LLM的表示空间,作为辅助任务增强情绪理解。
- 实验结果:在IEMOCAP和MELD两个数据集上,MM-VLN(使用Llama3-8B)分别达到了72.05%和70.58%的加权F1分数,相比强基线(使用SpeechCueLLM提取的语音描述进行微调)提升了1.84%和3.15%。消融实验表明,去除内部或句间语音变异性都会导致性能下降,证明两者互补。在零样本场景下,加入语音变异性信息也能提升多个LLM的性能。
- 实际意义:为多模态大语言模型如何有效整合非文本模态的结构化信息提供了新思路,有望提升人机交互中的情感理解能力。
- 主要局限性:语音特征提取依赖外部大模型,引入额外计算开销和潜在误差;图结构依赖预训练的话语解析模型,其准确性会影响最终效果;论文未公开代码,且损失函数等细节缺失。
🏗️ 模型架构
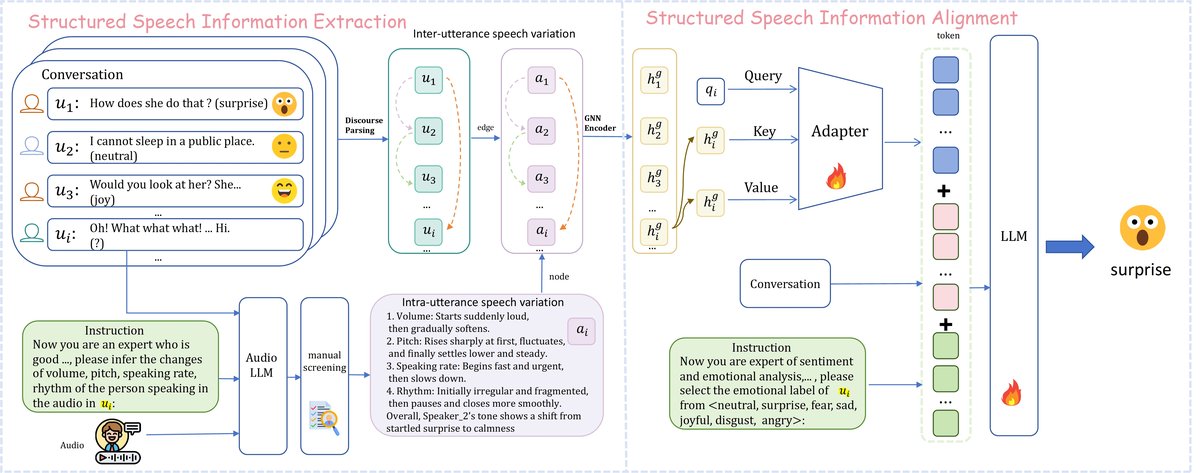
模型MM-VLN的整体架构如图1所示,主要包含以下几个核心组件:
- 输入:对话序列,包含文本(t₁…tn)和音频(a₁…an)模态。
- 结构化语音信息提取:
- 内部语音变异性(节点特征):对于每个话语的音频aᵢ,使用提示工程将其输入到预训练的大语言模型Qwen2-Audio-7B-Instruct中,要���模型输出对该话语语音特征(音量、音调、语速、节奏)的文本描述。然后,用RoBERTa编码这段文本描述,得到该话语的向量表示hᵢ,作为图节点特征。
- 句间结构关系(边信息):使用预训练的话语解析模型(DSM)对整个对话进行推理,得到话语间的依赖关系(如父子关系),构成图的边集合E。
- 图神经网络编码器:
- 将对话建模为一个有向图G=(V, E),其中V是话语节点集(特征为hᵢ),E是依赖边集。
采用图注意力网络(GAT)作为编码器。GAT通过注意力机制聚合邻居节点的信息,计算公式为:
hg_i = σ(∑_{j∈N(i)} αij W * hj),其中αij是注意力权重。这能动态学习不同邻接话语的重要性,捕获细粒度的句间关系。 - GAT的输出H是一个矩阵,包含了融合了图结构信息的话语表示。
- 将对话建模为一个有向图G=(V, E),其中V是话语节点集(特征为hᵢ),E是依赖边集。
采用图注意力网络(GAT)作为编码器。GAT通过注意力机制聚合邻居节点的信息,计算公式为:
- 模态对齐适配器:
- 为了将GAT输出的图表示H与LLM的表示空间对齐,设计了一个轻量级适配器。
- 适配器是一个单层跨注意力网络,灵感来自BLIP-2。它使用一组可学习的“查询”向量Q(维度
p×dg,p为图令牌数量)去查询GAT输出的“键”和“值”H,得到对齐后的图表示Xg = CrossAttn(q=Q, k=H, v=H)。
- LLM解码器:
- 将适配器输出的
Xg(p×dg)通过线性层投影到LLM的嵌入维度,得到“图令牌”Xa(p×dllm)。 - 将原始文本经过LLM编码器得到的文本嵌入
Xt(nt×dllm)与Xa进行拼接。 - 拼接后的序列表示
[Xa, Xt]被输入到冻结的或参数高效的LLM(如Llama3-8B)中,进行情绪预测。
- 将适配器输出的
架构图总结:该框架的核心思想是将“听觉感受”(语音变异性)和“上下文关系”(对话结构)先分别提取并融合为一个结构化的图表示,然后通过一个巧妙的适配器将其转换为LLM能理解的“语言令牌”,从而让LLM在进行情绪推理时能够同时“看到”文本、“理解”语音的细微动态并“感知”对话的结构流向。
💡 核心创新点
- 提出融合内部与句间语音变异性的图框架:首次明确区分并联合建模对话语音的两个维度信息——单句内部的声学动态(如音调起伏)和句间通过语音表现出的情绪延续或转折(如连续高音调)。这比以往简单地使用静态音频特征或忽略句间语音关系更符合真实对话的情感演变。
- 设计“图令牌”注入机制实现结构信息对齐:将图神经网络编码的复杂非欧几里得结构信息,通过一个基于跨注意力的适配器,转换为LLM输入序列中的特殊令牌(Graph Token)。这种方法避免了直接修改LLM内部结构,提供了模块化、灵活的融合方式,为多模态大模型整合结构化信息提供了新思路。
- 利用大语言模型进行特征工程与零样本验证:创新地使用一个语音大模型(Qwen2-Audio)作为“特征提取器”,将连续的语音信号转化为结构化的文本描述,这既利用了LLM的强大感知能力,又使得特征具有可解释性。同时,在零样本场景下验证了该特征的通用性,证明了其价值超越了特定数据集的微调。
🔬 细节详述
- 训练数据:使用IEMOCAP和MELD两个公开的对话情绪识别数据集。
- IEMOCAP:包含约12小时的音视频对话数据,标注有6种情绪(兴奋、沮丧、悲伤、中立、愤怒、快乐)。
- MELD:来自电视剧《老友记》,包含约55小时的音视频数据,标注有7种情绪(中立、惊喜、恐惧、悲伤、快乐、厌恶、愤怒)。
- 预处理:未详细说明。数据增强:未说明。
- 损失函数:论文中未明确说明使用的损失函数。根据任务(分类)和基线(LLM微调),通常使用交叉熵损失,但具体公式和是否加权未提及。
- 训练策略:
- 基础模型:Llama3-8B 和 Qwen2.5-7B。
- 参数高效微调:采用LoRA进行微调。
- 学习率:
2e-4。 - 批大小(Batch Size):
8。 - 训练轮数/步数:未说明。
- 优化器、Warmup、调度策略:均未说明。
- 图令牌数量(p):
50。
- 关键超参数:论文提及了学习率、批大小和图令牌数量。GAT的隐藏维度
dgat、适配器中的查询向量维度dg、LLM嵌入维度dllm等未具体给出数值。 - 训练硬件:2×80GB NVIDIA A800 GPUs。
- 推理细节:未说明解码策略、温度、beam size等具体推理参数。
- 正则化或稳定训练技巧:除了LoRA外,未提及使用Dropout、权重衰减等其他技巧。
📊 实验结果
表1:主要对比实验结果
| 方法 | 模态 | IEMOCAP (w-F1) | MELD (w-F1) |
|---|---|---|---|
| 非LLM方法 | |||
| DialogueRNN | T,A,V | 62.75 | 57.95 |
| MMGCN | T,A,V | 66.25 | 58.41 |
| DialogueTRM | T,A,V | 68.20 | 63.80 |
| UniMSE | T,A,V | 70.66 | 65.51 |
| M3Net† | T,A,V | 69.12 | 67.05 |
| MultiEMO† | T,A,V | 71.58 | 66.53 |
| HAUCL | T,A,V | 70.27 | 66.72 |
| DQ-Former | T,A,V | 71.76 | 64.70 |
| LLM方法 | |||
| InstructERC | T | 71.39 | 69.15 |
| DialogueLLM† | T,V | 71.91 | 67.96 |
| SpeechCueLLM† | T,A | 71.43 | 67.82 |
| Baseline (Qwen2.5-7B) | T,A | 70.01 | 66.95 |
| MM-VLN (Qwen2.5-7B) | T,A | 71.33 | 69.42 |
| Baseline (Llama3-8B) | T,A | 70.21 | 67.43 |
| MM-VLN (Llama3-8B) | T,A | 72.05 | 70.58 |
- 主要发现:MM-VLN(Llama3-8B)在两个数据集上均取得了最佳性能,超越了之前基于LLM的SOTA方法SpeechCueLLM(+0.62% on IEMOCAP, +2.76% on MELD)。与自身的基线(Baseline,即仅用SpeechCueLLM描述微调LLM)相比,提升显著(+1.84% on IEMOCAP, +3.15% on MELD),且p值<0.005。
表2:消融实验结果(IEMOCAP和MELD)
| 模型变体 | IEMOCAP | MELD | ||
|---|---|---|---|---|
| Acc. | w-F1 | Acc. | w-F1 | |
| MM-VLN (完整) | 71.90 | 72.05 | 71.88 | 70.58 |
| 去除句间变异性 (w/o inter) | 71.35 | 71.38 | 68.53 | 68.21 |
| 去除内部变异性 (w/o intra) | 71.47 | 71.55 | 69.01 | 69.06 |
| 去除两者 (w/o inter+intra) | 70.43 | 70.50 | 68.24 | 67.70 |
| 使用GCN替代GAT | 71.78 | 71.90 | 71.65 | 70.30 |
- 消融分析:移除任何一种语音变异性都会导致性能下降,证明其互补性。同时移除两者后性能下降最明显,说明联合建模的必要性。使用GCN替代GAT性能略有下降,表明注意力机制在对话图建模中更有效。
表3:零样本场景实验结果(IEMOCAP)
| 模型 | 零样本 (Acc. / w-F1) | 零样本+音频 (Acc. / w-F1) |
|---|---|---|
| GPT-4o-mini | 53.72 / 51.39 | 54.25 / 53.21 |
| Gemini | 55.63 / 55.10 | 56.01 / 56.03 |
| Qwen-2.5-72B | 56.07 / 54.77 | 59.23 / 58.01 |
| Phi-4-14B | 55.21 / 53.20 | 56.31 / 55.96 |
- 零样本分析:在零样本设置下,为LLM提供提取的语音变异性文本描述(“+音频”)相比纯文本输入,能一致性提升所有测试LLM的情绪识别性能,证明了该特征的泛化价值。
表4:长距离依赖分析
| 数据集 | 长距离依赖占比 | 引入结构信息后准确率提升 |
|---|---|---|
| IEMOCAP | 36.60% | 31.5% → 50.2% |
| MELD | 4.32% | 26.3% → 45.1% |
- 长距离依赖分析:论文统计了对话中依赖非相邻话语的比率。引入结构语音信息后,模型对这些需要长程上下文的情绪预测准确率有大幅提升,尤其是在长距离依赖比例高的IEMOCAP数据集上。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个逻辑清晰、有创新性的框架,实验设计较为全面,包括了主实验、消融实验、零样本和长程依赖分析,结果也支持其主张。主要扣分项在于:1) 核心语音特征提取依赖另一个大型LLM,而非端到端学习,这降低了方法的自主性和可复现性;2) 技术细节报告不够完整(如损失函数、完整超参),影响透明度。
- 选题价值:1.5/2:对话情绪识别是重要且活跃的方向,论文关注语音结构信息与大模型的结合,具有较好的前沿性和应用潜力。扣分点在于其依赖特定外部模型的方案在实际部署中可能面临成本和稳定性挑战。
- 开源与复现加成:0.0/1:论文未提供任何代码、模型权重或详细训练脚本。虽然参考了多个开源工具(如LoRA, RoBERTa),但其核心框架(图构建、适配器训练)的复现需要读者自行实现,门槛较高。