📄 Mixture-of-Experts Framework for Field-of-View Enhanced Signal-Dependent Binauralization of Moving Talkers
#空间音频 #波束成形 #信号处理 #移动声源跟踪
✅ 6.5/10 | 前50% | #空间音频 | #波束成形 #信号处理 | #波束成形 #信号处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Manan Mittal(Stony Brook University, Meta Reality Labs Research)
- 通讯作者:未说明
- 作者列表:Manan Mittal(Stony Brook University, Meta Reality Labs Research)、Thomas Deppisch(Chalmers University of Technology, Meta Reality Labs Research)、Joseph Forrer(Meta Reality Labs Research)、Chris Le Sueur(Meta Reality Labs Research)、Zamir Ben-Hur(Meta Reality Labs Research)、David Lou Alon(Meta Reality Labs Research)、Daniel D.E. Wong(Meta Reality Labs Research)
💡 毒舌点评
这篇论文巧妙地将混合专家模型应用于双耳渲染,实现了无需显式声源定位的动态跟踪与增强,思路颇具启发性。然而,其在真实世界的实验规模较小、对比基线相对传统,且全文未提供任何开源代码或复现细节,大大削弱了其作为方法论贡献的可验证性和可复用性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:实验中使用了公开的EARS数据集[16]进行语音信号的录制,但论文未说明数据集的具体使用方式或是否公开预处理后的实验数据。
- Demo:未提及。
- 复现材料:论文未提供详细的超参数配置、训练脚本或附录说明。
- 论文中引用的开源项目:论文在实验部分提到了使用 pyroomacoustics [15] 进行房间仿真。
📌 核心摘要
- 要解决什么问题:本文旨在解决在移动声源场景下,如何动态地调整双耳音频渲染的“视野”,以增强或抑制特定方向的声音,同时保持自然的双耳线索(如ITD和ILD)。传统方法通常需要先进行显式的到达方向估计,计算复杂且可能引入误差。
- 方法核心是什么:核心是提出一个基于混合专家模型的框架。系统将多个不同方向对应的双耳滤波器(“专家”)的输出,通过一个基于残差能量的在线凸优化算法(指数加权)进行自适应加权组合,从而隐式地跟踪并增强主导声源。
- 与已有方法相比新在哪里:不同于传统COMPASS-BSM或方向性BSM依赖显式DOA估计来分解直接和混响声,本文方法通过最小化麦克风信号的残差来在线评估各方向滤波器的性能,并动态混合最优的几个。这使得模型能更好地处理连续运动的声源,且与阵列几何无关。
- 主要实验结果如何:在模拟(pyroomacoustics,RT60≈200ms)和真实世界实验中,使用4麦克风阵列记录移动说话人。结果显示,该方法的残差能量最小值能准确跟踪说话人运动轨迹(图3),并且其生成的双耳信号在ITD和ILD误差上与传统BSM方法相当(图4),验证了其有效性。
- 实际意义是什么:该框架为AR/VR设备(如智能眼镜)提供了灵活、实时的空间音频处理能力,支持语音聚焦、噪声抑制、世界锁定音频等应用,且不依赖特定麦克风阵列配置。
- 主要局限性是什么:实验部分相对简单,仅测试了单一移动说话人场景,未涉及复杂多说话人或强噪声环境;缺乏与最新、更先进的自适应波束成形或深度学习方法的直接对比;未提供代码和详细复现信息。
🏗️ 模型架构
该系统是一个端到端的信号处理流水线,其架构如图1所示。
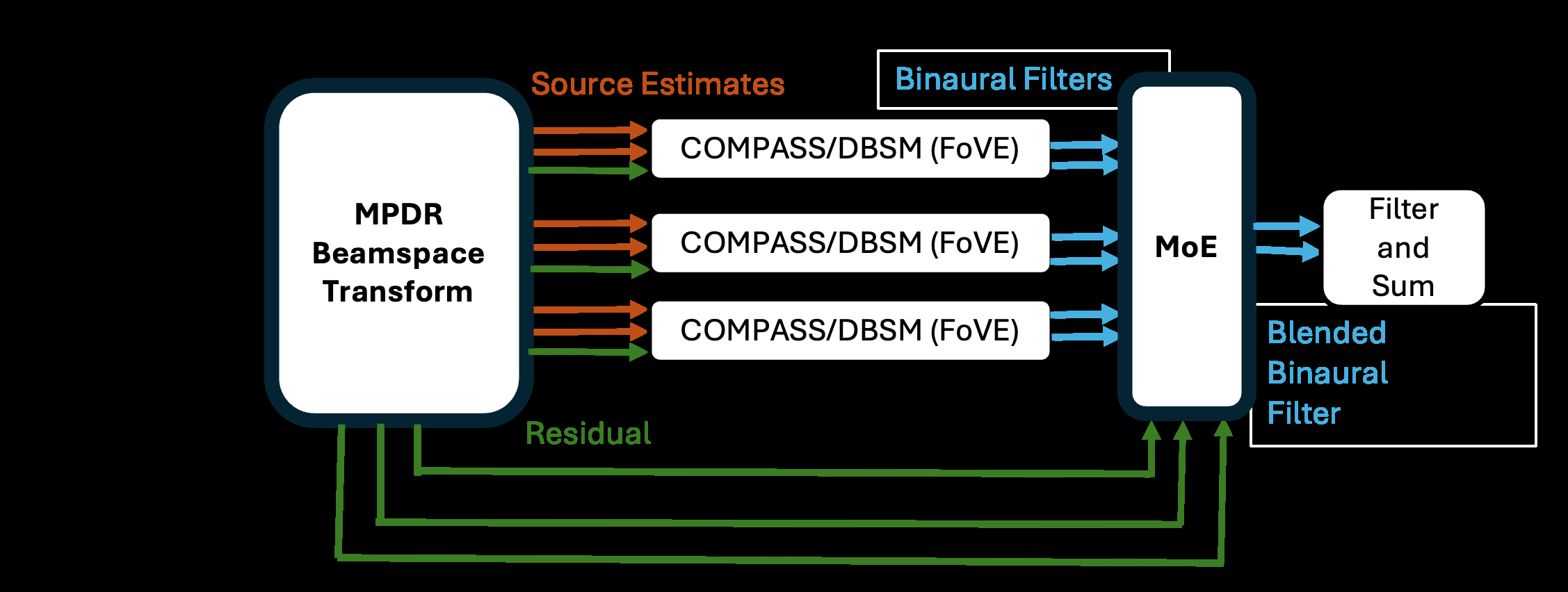
输入输出流程:
- 输入:来自
Nm个麦克风的阵列信号x[t, f](STFT域)。 - 输出:双耳渲染信号
p[t, f],包含左耳和右耳两个声道。
主要组件与数据流:
- 波束空间变换:首先将多通道麦克风信号变换到一组预定义的候选方向
q = 1, …, Q上,为每个方向q生成一个波束信号(论文中未详述具体变换方法,但图1中显示为Beamspace Transform)。 - 专家滤波器池:对于每个候选方向
q,预先设计一个信号相关双耳滤波器c_q[f](可以是COM、d-BSM或本文提出的FoVE变体)。该滤波器假设声源来自方向q,并应用到麦克风信号X上,得到一个双耳估计p_q[t, f](公式12)。每个方向q对应一个“专家”。 - 混合权重计算:这是核心创新模块。对于每个方向
q和每个时频点,计算瞬时损失l_q[t, f](公式16,为残差r_q的能量)。通过递归更新累积损失L_q[t, f](公式17),然后根据指数加权公式(公式14)计算混合权重α_q[t, f]。权重α_q反映了方向q的滤波器c_q的当前性能(损失低则权重大)。 - 自适应混合:将所有专家的输出
p_q用权重α_q进行加权求和,得到最终的双耳输出p(公式13)。等价于先混合所有专家滤波器得到一个时变的混合滤波器c_MoE[t, f](公式18),再应用到麦克风信号上(公式19)。 - 视野增强控制:在生成专家滤波器
c_q时,可以引入视野控制策略(增益控制或失真控制),修改HRTF或失真权重,从而在混合前就对目标方向进行了增强(图2显示了其效果)。
关键设计选择:
- 隐式定位:放弃显式DOA估计,利用最小化麦克风域残差这一客观准则来隐式判断哪个方向的假设更优。动机是避免DOA估计的计算量和错误传播。
- 在线自适应:使用指数加权的在线凸优化算法更新权重,使得模型能够跟踪连续运动的声源,即使每个专家滤波器是时不变的。
- 模块化与灵活性:框架中的“专家”滤波器可以替换为任何BSM变体(如COM、d-BSM)及其带视野控制的版本,框架本身保持不变。
💡 核心创新点
- 将混合专家模型引入双耳渲染:首次将在线学习中的混合专家框架应用于空间音频的双耳信号匹配问题,通过动态组合多个空间滤波器来实现鲁棒的渲染,而非单一滤波器。
- 基于残差的隐式方向跟踪:提出利用各方向滤波器产生的麦克风信号残差能量作为性能指标,隐式地、在线地评估并选择主导声源方向。这摆脱了传统方法对显式DOA估计的依赖,可能更适用于动态、非平稳场景。
- 视野增强与混合专家框架的无缝集成:证明了其提出的视野增强控制策略(公式22,23-26)可以自然地嵌入到混合专家框架中,只需为每个方向设计相应的FoVE滤波器作为专家即可,扩展了系统的功能性。
- 提供理论保障(遗憾界):为所提出的指数加权算法提供了标准的遗憾界(公式21),从在线凸优化角度证明了该混合方案在长期运行下,其性能渐近趋近于事后选择的最优单个专家,保证了算法的理论合理性。
🔬 细节详述
- 训练数据:论文未提及训练数据。本文方法是基于信号处理的,不需要传统的“训练”过程。专家滤波器的设计基于对声场模型的假设和信号统计量。
- 损失函数:瞬时损失
l_q[t, f]定义为麦克风残差向量的范数平方和(公式16),即Σ_m ||X[t,f] - A_q[f] * ĝ_s_q[t,f]||^2。这是一个凸损失函数。 - 训练策略:不适用。系统是在线自适应的。关键参数是学习率
η(公式14),其值影响权重更新的敏感度。论文未提供η的具体选择依据或典型值。 - 关键超参数:候选方向数量
Q;学习率η;视野控制参数γ(增益控制)和δ(失真控制);正则化参数ε(公式4)。这些超参数的具体值或选择范围在论文中未详细说明。 - 训练硬件:不适用。
- 推理细节:系统以帧为单位进行处理(基于STFT)。推理是逐帧递归计算累积损失和更新权重,无需迭代优化,可实时进行。
- 正则化或稳定训练技巧:公式4和公式11中提到了使用小正则化参数
ε和噪声协方差R_n来确保数值稳定性。
📊 实验结果
主要结果:
- 模拟实验:在8x8x5米房间(RT60≈200ms)中,使用4麦克风阵列。一个说话人以约2米/秒的速度从阵列前方开始逆时针移动。图3(上)显示了各方向滤波器的残差能量最小值随时间的变化,能清晰地跟踪说话人的角度运动轨迹(从0°变化到约180°)。对应的混合权重
α_q也随时间平滑变化,始终集中在当前说话人方向附近的滤波器上。 - 真实世界实验:使用4麦克风头戴式阵列,重现上述移动场景。图3(下)同样展示了残差能量最小值对说话人轨迹的跟踪,证明了方法在真实环境下的有效性。
- 双耳线索准确性:图4展示了不同方向(图中网格方向)的滤波器在渲染时产生的双耳线索误差(ITD和ILD误差)。结果显示,所提方法(MoE)在动态跟踪过程中,其平均误差水平与传统BSM方法(Signal-independent BSM)相当,并未因动态混合而显著恶化,验证了其在保持双耳线索一致性方面的有效性。
表格:论文未提供包含具体数值的对比表格。所有结果主要通过图表(图3,图4)及其描述性文字呈现。
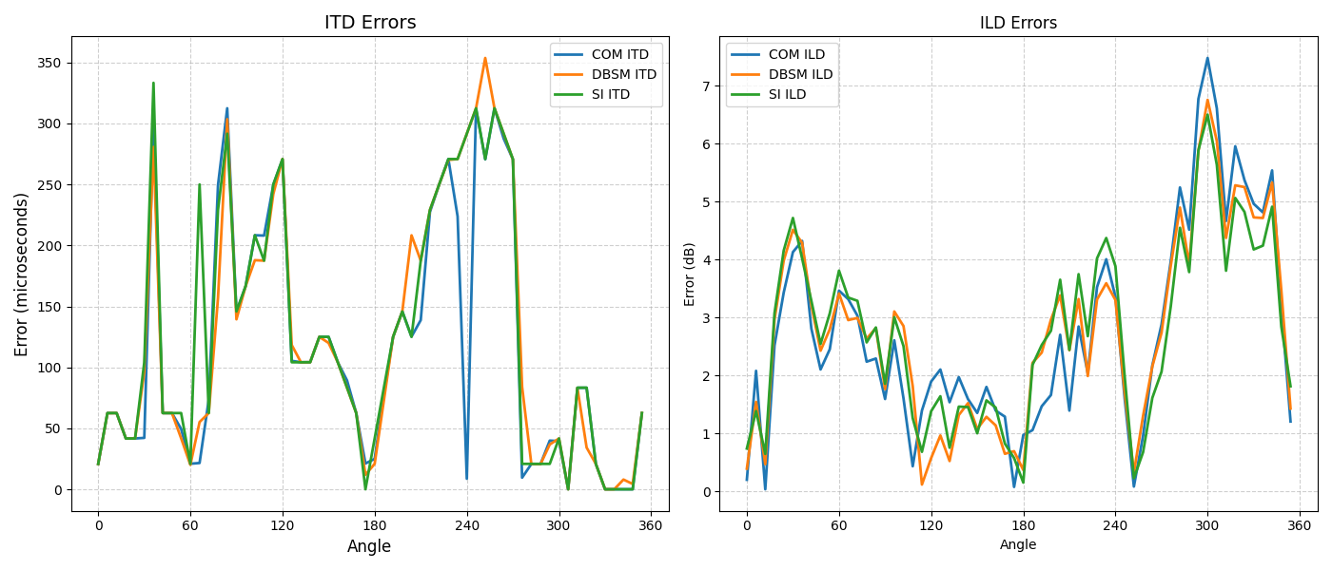 图3:模拟(上)与实测(下)中,残差能量最小值随时间的变化(对应声源角度)及相应的波束混合权重热力图。显示了算法对连续移动声源的准确跟踪和自适应混合能力。
图3:模拟(上)与实测(下)中,残差能量最小值随时间的变化(对应声源角度)及相应的波束混合权重热力图。显示了算法对连续移动声源的准确跟踪和自适应混合能力。
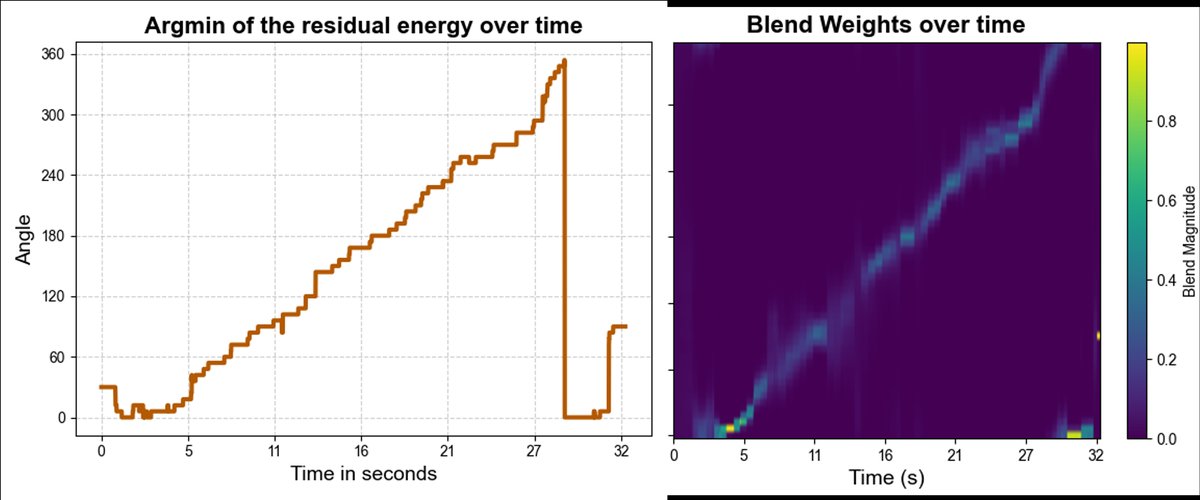 图4:各候选方向滤波器渲染信号的平均ITD和ILD误差随时间的变化。结果表明,所提方法能保持与基准BSM方法相当的双耳线索精度。
图4:各候选方向滤波器渲染信号的平均ITD和ILD误差随时间的变化。结果表明,所提方法能保持与基准BSM方法相当的双耳线索精度。
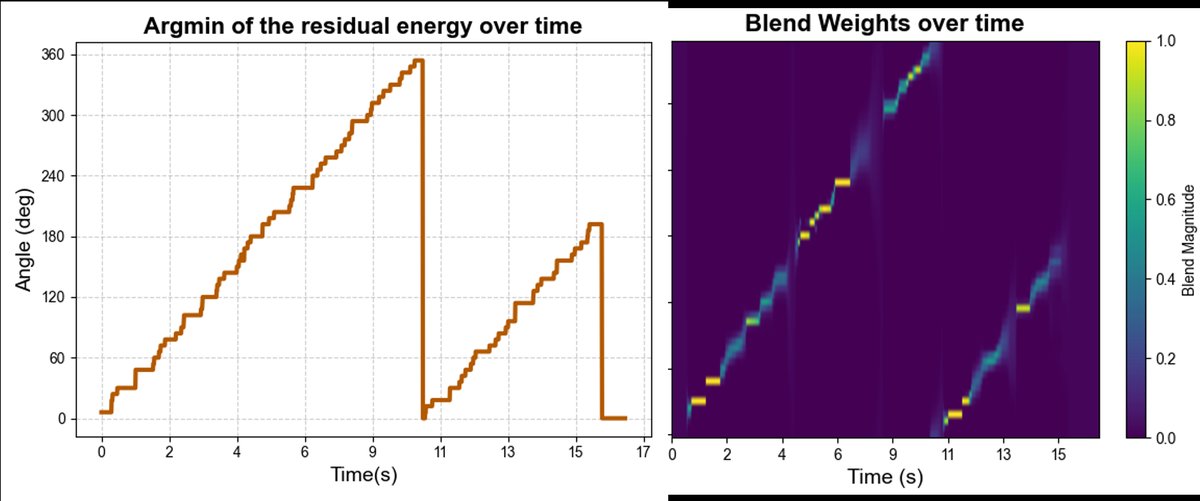 图2:以正前方为中心、增益为FoV的方向依赖增益图。左图展示固定δ下改变γ的效果,右图展示固定γ下改变δ的效果。直观显示了视野增强的控制能力。
图2:以正前方为中心、增益为FoV的方向依赖增益图。左图展示固定δ下改变γ的效果,右图展示固定γ下改变δ的效果。直观显示了视野增强的控制能力。
⚖️ 评分理由
- 学术质量:5.5/7 - 创新点明确,将混合专家在线学习应用于双耳渲染,思路新颖。技术原理清晰,并提供了理论遗憾界。但实验部分不够深入:仅测试了单一声源移动的简单场景,缺乏在多说话人、混响、噪声等复杂条件下的鲁棒性分析;没有与最新的、先进的自适应波束成形或基于深度学习的方法进行定量对比;所有结果缺乏具体的数值比较表格。
- 选题价值:1.5/2 - 空间音频和AR/VR是当前热点,解决移动场景下的动态视野增强问题具有明确的应用价值和前沿性。论文目标清晰,实用导向强。
- 开源与复现加成:-0.5/1 - 论文未提供任何开源代码、预训练模型、数据集链接或详尽的复现参数(如学习率
η、方向网格Q的具体设置)。作为一篇方法论工作,这严重影响了其可复现性和后续研究者的跟进效率。