📄 MixGAN-based Non-blind Bandwidth Extension for Audio Codec
#音频增强 #生成对抗网络 #音频编解码器 #非盲 #实时处理
🔥 8.0/10 | 前25% | #音频增强 | #生成对抗网络 | #音频编解码器 #非盲
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Hao Guo(华为中央媒体技术研究院,清华大学深圳国际研究生院)
- 通讯作者:Wenbo Ding(清华大学深圳国际研究生院,邮箱:ding.wenbo@sz.tsinghua.edu.cn)
- 作者列表:Hao Guo(华为中央媒体技术研究院,清华大学深圳国际研究生院)、BingYin Xia(华为中央媒体技术研究院)、Xiao-Ping Zhang(清华大学深圳国际研究生院)、Wenbo Ding(清华大学深圳国际研究生院)
💡 毒舌点评
本文首次将非盲AI带宽扩展(BWE)方案系统性地落地到音频编解码器框架中,并通过MixGAN创新性地解决了GAN训练在频谱扩展任务上易崩溃的难题,工程导向明确且效果显著。然而,论文对核心侧信息模型(side model)的“AI-based”部分描述过于简略(仅提到5个ConvM和1个MLP),且训练数据集描述模糊(“130小时以中文歌曲为主”),这给工作通用性的评估和完整复现埋下了隐患。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未提及公开数据集或获取方式。
- Demo:未提及。
- 复现材料:论文提供了详细的模型结构、训练策略(三阶段)、关键超参数(学习率、Batch size等)和训练硬件信息,但缺乏最终的训练细节和配置文件。
- 论文中引用的开源项目:论文引用了以下开源项目作为对比或依赖:
- HiFi-GAN+ 的复现代码:https://github.com/brentspell/hifi-gan-bwe
- NU-Wave2 的官方实现:https://github.com/maum-ai/nuwave2
- 总体开源情况:论文本身未提及任何开源计划,但对复现有一定的指导意义。
📌 核心摘要
- 问题:现有的AI带宽扩展(BWE)方法很少考虑集成到实际音频编解码器时面临的约束,如比特流兼容性、处理延迟和解码失真。
- 方法:本文提出了首个面向音频编解码器的非盲AI-BWE框架。该框架在编码端提取少量比特的侧信息(包括频带包络和侧特征),在解码端以低延迟帧处理方式(2048样本,43ms)利用该信息引导从低频重建高频。核心创新是提出了MixGAN框架(通过线性插值混合真实与生成帧来训练判别器)和三阶段训练策略(单帧预热、单帧对抗、重叠优化)。
- 创新点:1) 首个解决编解码器实际约束的非盲AI-BWE方案;2) MixGAN稳定了对抗训练,提升了重建保真度;3) 模型对量化失真具有固有鲁棒性。
- 实验:在8kHz->24kHz的BWE任务上,与多种AI方法(HiFi-GAN+, NU-Wave2)和标准方法(EVS)对比。在语音和音频测试集上,所提方法(Non-blind BWE)取得了最佳的MUSHRA主观评分(语音84.44,音频84.28)和最低的LSD客观指标(语音0.846,音频0.663)。同时,其浮点运算量(FLOPs)和实时因子(RTF)远低于其他AI基线,计算效率高。
| 方案 | 语音 MUSHRA↑ | 语音 LSD↓ | 音频 MUSHRA↑ | 音频 LSD↓ |
|---|---|---|---|---|
| 解码LF (基准) | 55.25 | 1.418 | 46.75 | 3.055 |
| HiFi-GAN+ | 54.84 | 1.561 | 40.63 | 1.686 |
| NU-Wave2 | 59.72 | 1.664 | 48.44 | 2.161 |
| EVS (规则) | 77.44 | 0.980 | 76.72 | 1.051 |
| Blind BWE | 74.66 | 1.077 | 74.56 | 0.840 |
| Non-blind BWE (Vanilla) | 69.52 | 0.915 | 66.32 | 0.725 |
| Non-blind BWE (Proposed) | 84.44 | 0.846 | 84.28 | 0.663 |
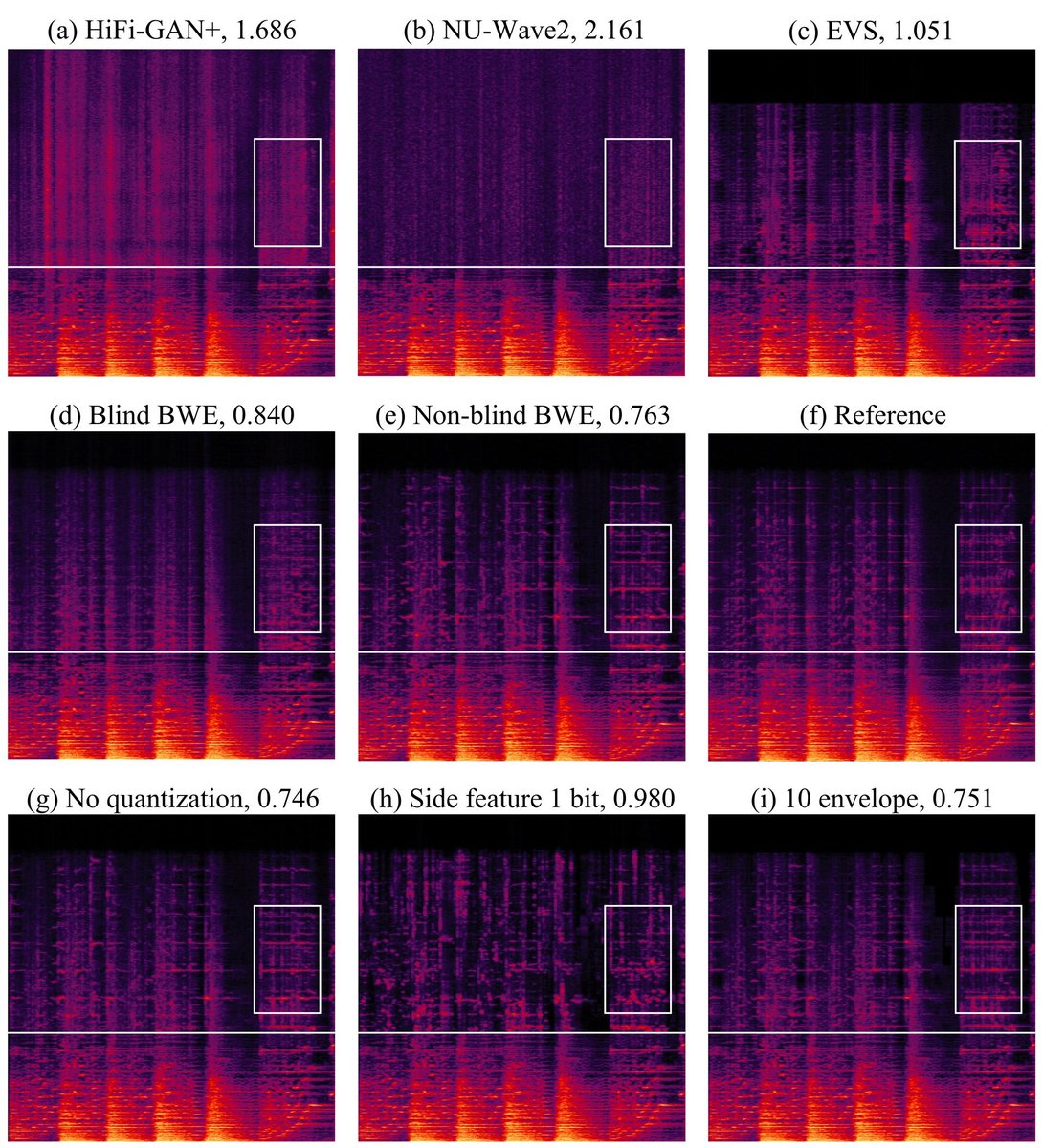 (图4显示,在复杂频谱结构的交响乐片段中,所提方法(e)能准确恢复谐波细节,而HiFi-GAN+(a)和NU-Wave2(b)表现较差。)
(图4显示,在复杂频谱结构的交响乐片段中,所提方法(e)能准确恢复谐波细节,而HiFi-GAN+(a)和NU-Wave2(b)表现较差。)
- 意义:为在低比特率通信系统中实现高质量、低延迟的通用音频编解码器提供了新的技术路径,特别是在蓝牙耳机、无线通话等场景中具有直接应用潜力。
- 局限性:训练数据集规模(130小时)和多样性描述不足(以中文歌曲为主),可能影响模型在所有类型音频上的泛化能力。侧信息的AI模型结构描述过于简略,未公开代码和详细数据集信息,限制了可复现性。
🏗️ 模型架构
本文提出了一个完整的GAN-based非盲BWE框架,专为音频编解码器设计。其输入输出和核心组件如下:
整体流程(见图1):编码器从每帧(2048样本,0.043秒)音频中提取侧信息并量化;解码器接收解码后的低频(LF)帧和侧信息,由非盲BWE模型生成高频(HF)帧;最后通过重叠相加(overlap-add)和包络调整模块重建全带音频。该设计确保了理论延迟仅为半帧(约22ms),与核心编解码器延迟叠加不增加额外负担。
侧信息模型(Side Model)(图2中左侧部分):输出包含频带包络和侧特征。
- 频带包络:规则部分,将HF频谱分为多个子带,存储每个子带的平均幅度。
- 侧特征:AI部分,旨在捕获谐波结构、精细频谱细节等难以规则表达的信息。模型包含5个ConvM模块和一个2层感知机。侧信息最终通过Sigmoid映射到(0,1)区间,进行简单的标量均匀量化(每个侧特征3比特,包络4比特,共34比特/帧)。
非盲BWE模型(图2右侧):主体为U-Net-like架构,功能是将LF频谱映射到HF频谱。
- LF特征提取:逐层压缩频谱维度,提取多尺度特征。
- HF频谱重建:逐层扩展频谱维度,结合提取的LF特征和侧特征生成HF频谱。在多尺度上,HF特征与LF特征进行拼接,生成多粒度特征。模型仅输出HF频谱,而非全带,这是与先前方法的关键区别。
MixGAN框架:这是训练稳定性的核心。
- 创新点:判别器接收的是BWE生成帧和真实帧的线性插值混合帧(权重随机),并被训练预测该插值权重。生成器(BWE模型)的目标是让判别器为其生成帧打分为1。
- 优势:判别器评估的是从“完全生成”到“完全真实”的连续过程,其评分标准可随生成器性能提升而平滑演进,避免了传统GAN中判别器过快过拟合或训练崩溃的问题。
三阶段训练策略(图3):
- 阶段一:单帧预热训练。仅用重建损失(波形MAE + 多尺度频谱幅度MAE)优化BWE模型,使其能恢复粗略的HF包络。
- 阶段二:单帧对抗训练。引入MixGAN判别器(包含多个Mix波形判别器和Mix STFT判别器),加入对抗损失和特征损失,优化模型恢复细节的能力。
- 阶段三:重叠优化阶段。将BWE帧加窗重叠形成片段,计算损失,解决前两阶段因忽略重叠区域相位一致性而导致的帧间不连续和频谱模糊问题。
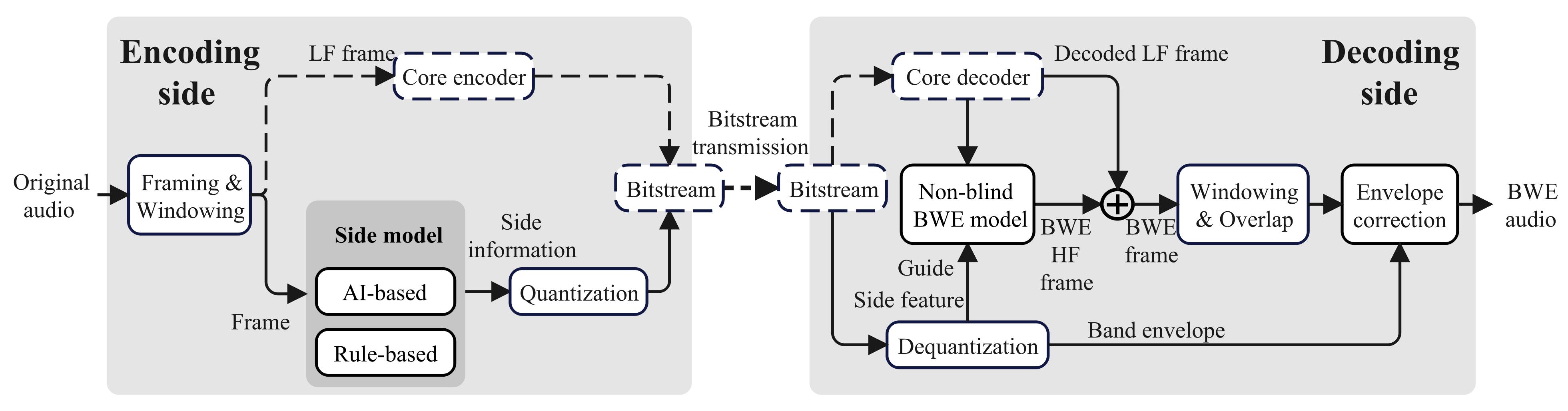 (图1展示了从编码器提取侧信息,到解码器利用LF帧和侧信息生成HF帧,再到重叠加与包络调整的全流程。)
(图1展示了从编码器提取侧信息,到解码器利用LF帧和侧信息生成HF帧,再到重叠加与包络调整的全流程。)
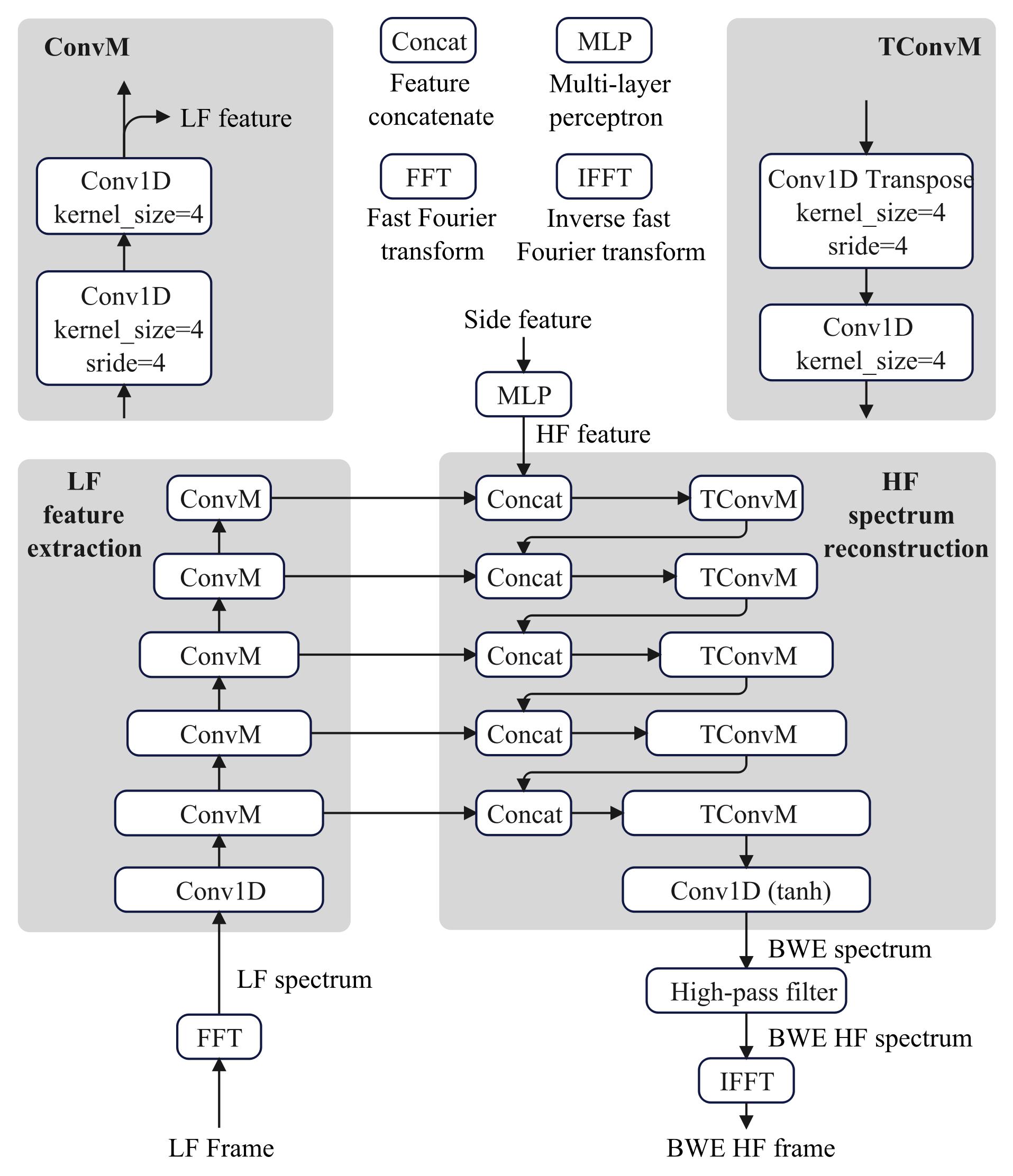 (图2左侧简略展示了侧信息模型(侧特征提取),右侧详细展示了基于U-Net的非盲BWE模型结构,包括LF特征提取路径、HF重建路径以及多尺度特征拼接。)
(图2左侧简略展示了侧信息模型(侧特征提取),右侧详细展示了基于U-Net的非盲BWE模型结构,包括LF特征提取路径、HF重建路径以及多尺度特征拼接。)
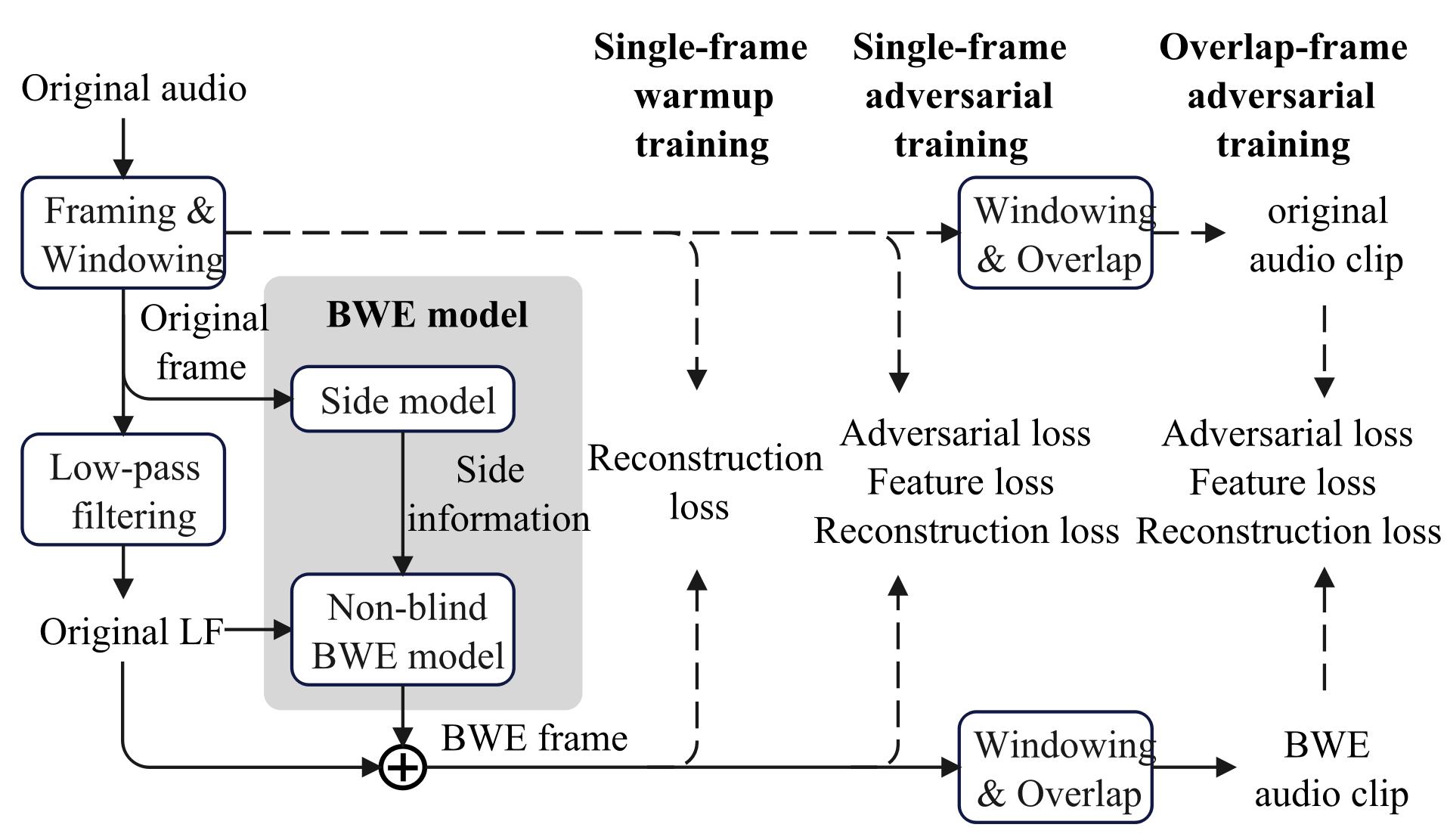 (图3清晰地勾勒出从单帧预热、单帧对抗到重叠优化的三个训练阶段,以及各阶段使用的损失函数。)
(图3清晰地勾勒出从单帧预热、单帧对抗到重叠优化的三个训练阶段,以及各阶段使用的损失函数。)
💡 核心创新点
- 首个面向音频编解码器的非盲AI-BWE方案:以往AI-BWE研究多集中于模型本身,忽略了编解码器集成的具体约束(低延迟、比特兼容、抗量化)。本文首次系统性地解决了这些问题,提出了一个完整的、可落地的框架。
- MixGAN训练框架:针对BWE任务中GAN训练易崩溃、判别器无法持续提供有效梯度的问题,提出了基于插值混合帧的判别器设计。这使得训练过程更稳定,生成器能够持续优化以生成更逼真的高频细节。
- 仅输出HF频谱的非盲模型:与多数直接生成全带信号的BWE模型不同,该模型仅生成HF部分,并与解码后的LF进行重叠加。这种设计更符合编解码器“LF由核心编解码器保证,HF由BWE增强”的逻辑,也降低了模型复杂度。
- 固有的量化鲁棒性:实验证明,即使使用极简的标量均匀量化方案对侧信息进行后处理(甚至在测试阶段引入),性能损失也极小。这表明所学侧特征是弱耦合的,模型本身对量化失真具有鲁棒性,大大简化了与实际编解码器比特流的集成。
🔬 细节详述
- 训练数据:一个130小时的48kHz单声道音频数据集。主要构成:中文歌曲,少量器乐和英文歌曲。论文未说明具体来源、预处理和数据增强方法。
- 损失函数:
- 单帧预热阶段:重建损失 = 波形MAE(采样率24kHz,48kHz) + 频谱幅度MAE(帧长256,512,1024,2048)。
- 单帧对抗阶段:对抗损失(来自MixGAN判别器) + 特征损失(判别器中间层特征的MAE)。
- 重叠优化阶段:基于重叠加后音频片段的损失(具体公式未详细说明)。
- 训练策略:
- 优化器:Adam。
- 学习率:预热阶段BWE模型为
5e-4;对抗阶段BWE模型为5e-6,判别器为1e-3。 - Batch size:32。
- 训练轮次比:对抗阶段,BWE模型训练与判别器训练的epoch比例为10:1。
- 调度策略:未提及学习率衰减或调度策略。
- 关键超参数:
- 帧长:2048样本。
- 重叠长度:1024样本(50%重叠,余弦窗)。
- 侧信息:10个侧特征(每个3比特) + 1个包络(4比特) = 34比特/帧。
- MixGAN判别器集:包含2个Mix波形判别器(采样率24kHz,48kHz,7层1D CNN)和3个Mix STFT判别器(帧长128,256,512,5层2D CNN)。
- 训练硬件:2张NVIDIA Tesla V100 GPU。训练时长未提及。
- 推理细节:推理时,BWE模型以43ms为单位处理帧,生成HF帧,与解码后的LF帧进行重叠加和包络调整。实时因子(RTF)仅为0.020(在V100上),表明其实时性极佳。
- 正则化/稳定技巧:三阶段训练策略本身是稳定训练的核心技巧;对抗训练中BWE模型与判别器的训练轮次比(10:1)也是一种稳定训练的策略。
📊 实验结果
实验设置:
- 任务:8kHz -> 24kHz (16kHz -> 48kHz) 的BWE。
- 输入:由EVS编解码器(32kbps SWB模式)解码后的LF信号。
- 测试集:包含8个语音样本(英、中、法、韩)和8个音频样本(歌曲、电子音乐、交响乐等)。
- 评估方法:MUSHRA主观测试(7位专家)和LSD客观指标。
主要结果:
- 整体性能:所提Non-blind BWE在语音和音频测试集上均取得了最佳的MUSHRA分数和最低的LSD分数,显著优于所有基线。
| 方案 | 语音 MUSHRA↑ | 语音 LSD↓ | 音频 MUSHRA↑ | 音频 LSD↓ |
|---|---|---|---|---|
| 解码LF (基准) | 55.25 | 1.418 | 46.75 | 3.055 |
| HiFi-GAN+ | 54.84 | 1.561 | 40.63 | 1.686 |
| NU-Wave2 | 59.72 | 1.664 | 48.44 | 2.161 |
| EVS (规则) | 77.44 | 0.980 | 76.72 | 1.051 |
| Blind BWE | 74.66 | 1.077 | 74.56 | 0.840 |
| Non-blind BWE (Vanilla) | 69.52 | 0.915 | 66.32 | 0.725 |
| Non-blind BWE (Proposed) | 84.44 | 0.846 | 84.28 | 0.663 |
- 模型复杂度:所提模型在计算效率上优势巨大。
| 方案 | 参数量 (Params) ↓ | 浮点运算量 (FLOPs) ↓ | 实时因子 (RTF) ↓ |
|---|---|---|---|
| HiFi-GAN+ | 1.1M | 51.3G | 0.207 |
| NU-Wave2 | 1.7M | 220G | 0.262 |
| Non-blind BWE | 2.8M | 4.2G | 0.020 |
- 消融分析:
- 侧信息的重要性:对比Blind BWE(无侧信息)和Non-blind BWE,后者在MUSHRA上提升近10分,尤其在复杂频谱音频上(如图4所示),证明侧信息对恢复精确谐波结构至关重要。
- MixGAN的有效性:对比Non-blind BWE (Vanilla)(使用传统GAN)和Proposed版本,MUSHRA在语音上提升约15分,证明MixGAN对训练稳定性和最终性能有决定性作用。
- 量化鲁棒性:对比“无量化”(352比特)和“侧特征1比特”(14比特)配置,性能下降轻微,证明了模型对简重量化方案的鲁棒性(图4中标注e, g, h)。
(图4以交响乐为例,直观展示了不同方法重建频谱的差异。可以看到所提方法(e)恢复了清晰的谐波(亮线),而其他方法存在模糊(HiFi-GAN+)、失败(NU-Wave2)或不准确(EVS)。图中LSD数字也印证了量化分析部分的结论。)
⚖️ 评分理由
- 学术质量:6.5/7:创新性高(首次解决编解码器约束的非盲AI-BWE,MixGAN设计),技术路线清晰正确,实验对比全面且说服力强。扣分点在于模型部分细���(Side Model)描述不足,以及未与部分最新的通用BWE模型进行对比。
- 选题价值:1.8/2:选题精准命中音频编解码领域的实际痛点和前沿方向,应用价值明确,对推动低比特率神经音频编解码有显著意义。
- 开源与复现加成:-0.5/1:论文提供了足够的方法论和超参数细节,但缺乏代码、预训练模型和详细的数据集信息,这构成了复现的重大障碍。