📄 Mitigating Intra-Speaker Variability in Diarization with Style-Controllable Speech Augmentation
#说话人日志 #数据增强 #语音合成 #流匹配
✅ 7.0/10 | 前25% | #说话人日志 | #数据增强 | #语音合成 #流匹配
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Miseul Kim(延世大学电气与电子工程系)
- 通讯作者:未说明(论文未明确标注通讯作者)
- 作者列表:Miseul Kim(延世大学电气与电子工程系)、Soo Jin Park(高通技术有限公司)、Kyungguen Byun(高通技术有限公司)、Hyeon-Kyeong Shin(高通技术有限公司)、Sunkuk Moon(高通技术有限公司)、Shuhua Zhang(高通技术有限公司)、Erik Visser(高通技术有限公司)
💡 毒舌点评
亮点:论文巧妙地将“用TTS生成多样风格语音”这一生成任务,嫁接到“解决聚类分裂问题”这一理解任务上,思路清晰且具有实用价值,可视化结果(图4)直观地展示了增强样本如何弥合聚类鸿沟。短板:创新更多是系统层面的巧妙组合而非底层模型突破,且实验设置(对AMI数据集进行人为截断以凸显问题)虽然有效,但也侧面说明该方法在未经“处理”的长对话自然数据上的普适性有待进一步验证,与端到端SOTA的缺席对比是重大遗憾。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:评估数据集(Concatenated emotional corpus, Truncated AMI corpus)是作者基于公开数据集(ESD, AMI)构建的,论文未说明是否公开构建脚本或处理后的数据。训练数据LibriTTS-R是公开的。
- Demo:未提及在线演示。
- 复现材料:论文提供了部分实现细节(如训练步数、学习率、特征维度),但缺少完整的配置文件、训练日志、预训练检查点或更详尽的超参数列表。
- 论文中引用的开源项目:GST[11], Vevo[12], ECAPA-TDNN[4], BigVGAN[14], 谱聚类工具[15], dscore评分工具[1]。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
解决什么问题:说话人日志系统常因同一说话人因情绪、健康状况等产生的内在语音风格差异(说话人内变异性),而将同一人的语音片段错误聚类为不同说话人(分裂错误)。
方法核心:提出一个两阶段框架,利用一个风格可控的语音生成模型进行数据增强。第一阶段(内容风格建模)使用GST学习无监督的风格表征;第二阶段(声学建模)使用条件流匹配生成目标说话人的语音,保持身份但变化风格。
新在哪里:将先进的语音合成技术(结合GST与流匹配)专门用于说话人日志的数据增强。生成模型输出与原始音频的说话人嵌入混合,用于增强后续聚类的鲁棒性,该流程可即插即用,无需重训核心聚类模型。
主要实验结果:
- 在模拟情感语音数据集上,应用增强后,说话人日志错误率(DER)从10.71%降至5.48%,降幅49%,说话人计数更准确(平均3.06→2.76)。图4的t-SNE可视化显示,增强样本帮助合并了原本分裂的聚类。
- 在截断的AMI真实对话数据集上,增强对短语音(15秒、30秒)效果显著,DER分别降低22%和35%;对长语音(>60秒)无显著提升也无负面影响(图5)。
- 关键表格(来自Table 1):
方法 DER (%) Miss (%) FA (%) Conf (%) 估计说话人数 无增强 10.71 0.00 0.00 10.70 3.06 有增强 5.48 0.00 0.00 5.48 2.76 实际意义:为处理真实场景中(如会议、访谈)说话人语音风格多变导致的日志错误提供了一种实用的数据增强解决方案,能提升现有模块化系统的鲁棒性。
主要局限性:方法依赖初始聚类的质量和文本转录;生成的语音质量可能引入新噪声;与当前端到端(EEND等)SOTA说话人日志模型的集成与效果未探索。
🏗️ 模型架构
本文提出的框架是一个系统级流程,而非一个单一端到端模型。其核心是其中的“风格可控数据增强模型”。
整体流程(见图3):
- 初始聚类:对输入音频提取说话人嵌入(ECAPA-TDNN),进行谱聚类,得到初步的说话人分组。
- 风格可控数据增强:使用上述生成模型,为每个初步聚类的说话人生成大量风格多样但身份不变的语音样本。
- 重聚类:将原始音频和增强音频的���话人嵌入混合,进行第二次谱聚类,得到最终结果。
风格可控数据增强模型架构(见图2):这是一个两阶段的TTS系统。
- 第一阶段:内容风格建模(自回归Transformer编码器)
- 输入:文本转录序列和风格嵌入。
- 功能:生成内容风格标记(联合编码语言内容和韵律风格的隐表征)。
- 关键组件:
- 参考编码器:从参考语音的梅尔频谱图中提取全局嵌入。
- 风格标记层:由10个可训练标记组成。通过多头注意力机制计算全局嵌入(查询)与各标记(键和值)的相似度,得到注意力权重,其加权和即为最终的风格嵌入。
- 风格嵌入与文本标记嵌入拼接,输入到自回归Transformer中。
- 训练:自监督学习(下一个标记预测)。在推理时,通过操纵注意力权重(改变风格嵌入)来获得多样化的风格输出。
- 第二阶段:声学建模(条件流匹配Transformer)
- 输入:第一阶段生成的内容风格标记,以及来自参考语音的说话人嵌入(ECAPA-TDNN)。
- 功能:生成梅尔频谱图。
- 关键设计:与Vevo不同,本模型不依赖填充任务训练解码器(避免风格泄漏),而是直接使用说话人嵌入来明确注入目标身份。
- 解码:使用预训练的BigVGAN声码器将梅尔频谱图转换为原始波形。
架构图:
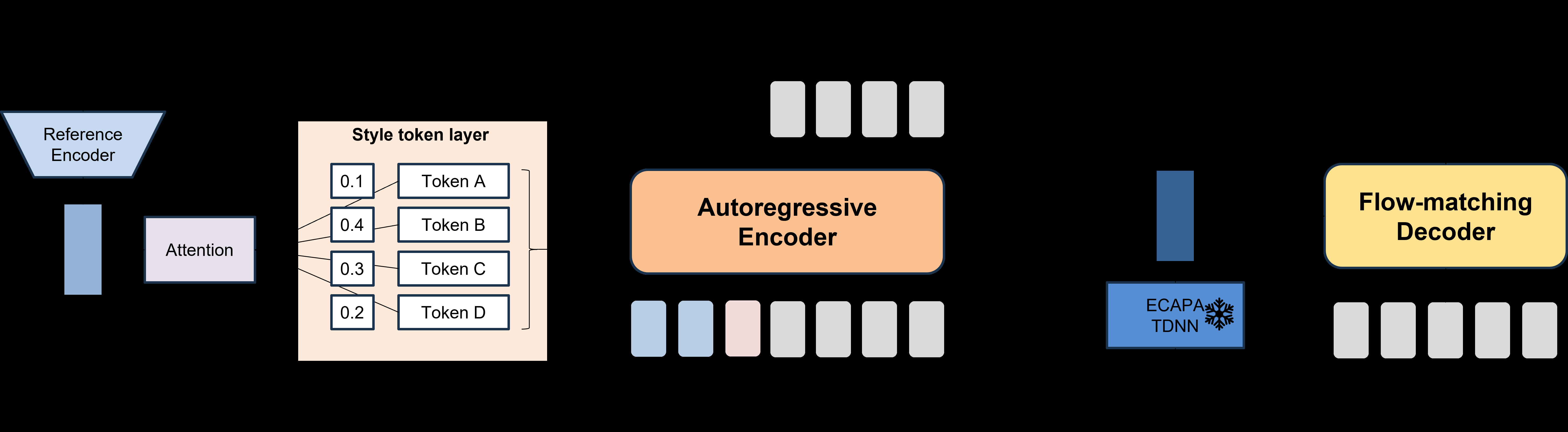 该图清晰地展示了两阶段结构。第一阶段(上方)从文本和风格嵌入生成内容风格标记;第二阶段(下方)以这些标记和说话人嵌入为条件,通过流匹配解码器生成梅尔频谱图。
该图清晰地展示了两阶段结构。第一阶段(上方)从文本和风格嵌入生成内容风格标记;第二阶段(下方)以这些标记和说话人嵌入为条件,通过流匹配解码器生成梅尔频谱图。
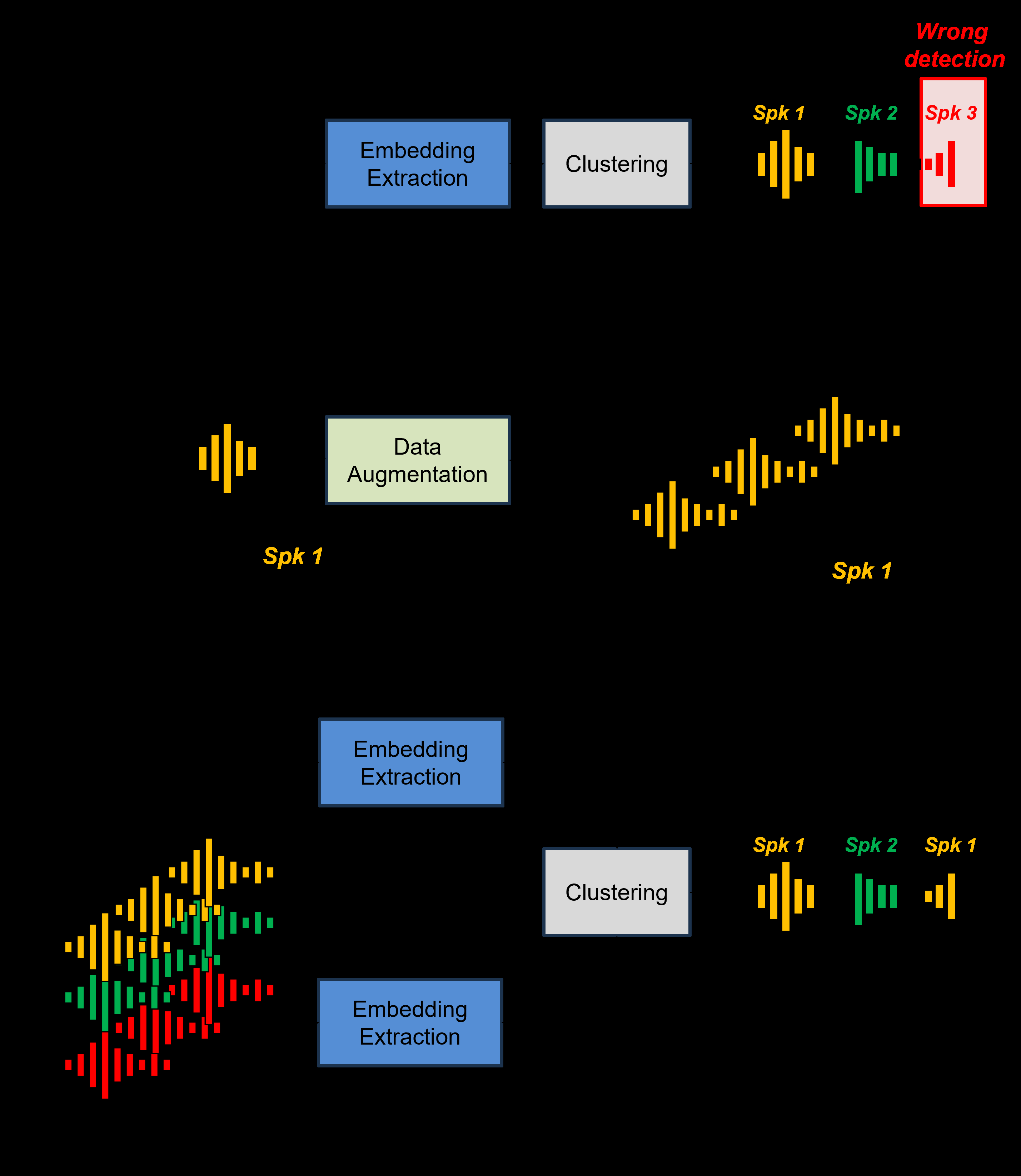 该图展示了完整的三阶段流程:初始聚类(a)-> 风格增强(b)-> 混合嵌入重聚类(c),直观体现了增强模型如何嵌入到整个系统中。
该图展示了完整的三阶段流程:初始聚类(a)-> 风格增强(b)-> 混合嵌入重聚类(c),直观体现了增强模型如何嵌入到整个系统中。
💡 核心创新点
- 将风格可控语音生成专门用于说话人日志增强:首次(据论文所称)系统性地将先进的、可控的TTS技术(结合GST与流匹配)应用于解决说话人日志中的说话人内变异性问题,为数据增强提供了新思路。
- 保持身份不变的风格多样性生成:改进了已有生成框架(如Vevo),通过使用ECAPA-TDNN说话人嵌入直接控制声学建模阶段,更干净地分离了“身份”与“风格”,确保生成样本身份一致。
- 嵌入混合与重聚类的即插即用策略:提出了一种不修改核心聚类模型的后处理方案。通过混合原始与增强嵌入并重新聚类,有效提升了聚类对风格变化的鲁棒性,具有良好的通用性潜力。
🔬 细节详述
- 训练数据:
- 生成模型训练:使用LibriTTS-R数据集的360小时train-clean子集训练,dev-clean子集验证。
- 评估数据:
- Concatenated emotional corpus:从ESD数据集构建,包含10个英文说话人,5种情绪,100个样本,每个样本约30秒-1分钟。
- Truncated AMI corpus:使用AMI语料库的MixHeadset子集,截取了15、30、60、120、240秒五种时长、恰好包含3个说话人的片段,每种时长100个样本。
- 损失函数:论文未说明具体的损失函数细节。自回归编码器使用下一个标记预测目标;条件流匹配解码器使用其标准的流匹配损失。
- 训练策略:
- 自回归编码器:训练550k步,批次大小4。
- 流匹配解码器:训练1M步,批次大小4。
- 优化器:Adam,学习率2e-4。
- 关键超参数:
- 音频特征:128维梅尔频谱图,窗宽80ms,帧移20ms。
- 推理扩散步数:32步。
- 风格标记数量:10个。
- 说话人嵌入提取:ECAPA-TDNN,1秒窗口,0.2秒帧移。
- 聚类阈值:初始聚类相似度阈值0.15,重聚类阈值0.12;增强样本筛选的说话人嵌入余弦相似度阈值0.4。
- 训练硬件:未说明。
- 推理细节:通过修改GST的注意力权重来控制风格多样性。生成语音后,使用ECAPA-TDNN重新提取嵌入。
- 正则化/稳定训练技巧:未提及除标准优化器外的特殊技巧。
📊 实验结果
主要Benchmark与结果: 论文主要在两个自建评估集上进行了对比实验(有无数据增强),而非公开的标准说话人日志排行榜。指标主要为DER(说话人日志错误率)及其分解(Miss, FA, Conf),由于使用了Oracle VAD,Miss和FA为0,DER主要由混淆(Conf)决定。
关键结果表格(同前文表格): 在Concatenated emotional corpus上,增强将DER从10.71%降至5.48%,绝对降低5.23%,相对降低49%。估计说话人数从3.06更接近真实值2.76(真实为2)。
不同条件下的细分结果: 图5展示了在Truncated AMI corpus上,不同语音长度下的性能。结果清晰显示:
- 对于短语音(15s, 30s),增强带来了显著的DER下降(分别约22%和35%的相对提升)。
- 对于长语音(>=60s),系统本身性能稳定,增强无明显改进也无害。
可视化证据: 图4的t-SNE图显示,在原始嵌入中(a),同一说话人的嵌入(方形或圆形标记)分散在多个聚类中(如方形对应紫色和粉色聚类)。引入增强嵌入(十字标记)并重聚类后(b),这些分散的嵌入被有效合并成两个清晰的说话人群。
⚖️ 评分理由
- 学术质量:6.0/7:论文正确识别并着手解决一个实际存在的技术痛点。方法设计有逻辑性,结合了两个成熟的模块(GST风格建模,流匹配生成)。实验在特定构建的、能凸显问题的评估集上取得了明确改善,并配有可视化佐证。主要扣分点在于:(1) 缺乏与当前端到端SOTA系统的直接对比,说服力受限;(2) 方法的新颖性更多体现在框架整合与问题导向的应用上,底层生成模型(改进的GST+流匹配)并非完全原创。
- 选题价值:1.0/2:问题本身(说话人内变异性)是说话人日志领域一个公认挑战,解决方案(利用生成模型增强)具有启发性和实用潜力。但研究方向相对聚焦和垂直,属于对现有系统进行鲁棒性增强的范畴,而非开辟新任务或范式。
- 开源与复现加成:0.0/1:论文未提供任何代码、模型或复现资源的链接。虽然引用了Vevo等开源工作,但作者的完整训练与推理流程未公开,极大地阻碍了研究社区的独立验证和快速复现。因此,此项不加分。