📄 Mitigating Data Replication in Text-to-Audio Generative Diffusion Models Through Anti-Memorization Guidance
#音频生成 #扩散模型 #音频安全
✅ 7.5/10 | 前25% | #音频生成 | #扩散模型 | #音频安全
学术质量 7.5/7 | 选题价值 2.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Francisco Messina(米兰理工大学,电子、信息与生物工程系)
- 通讯作者:未说明
- 作者列表:Francisco Messina(米兰理工大学,电子、信息与生物工程系)、Francesca Ronchini(米兰理工大学,电子、信息与生物工程系)、Luca Comanducci(米兰理工大学,电子、信息与生物工程系)、Paolo Bestagini(米兰理工大学,电子、信息与生物工程系)、Fabio Antonacci(米兰理工大学,电子、信息与生物工程系)
💡 毒舌点评
这篇论文的亮点在于其明确的现实关切和扎实的工程实现:首次系统性地将反记忆化指导框架引入音频生成领域,并通过详尽的消融实验证明了其有效性,为解决AIGC的版权困境提供了即插即用的思路。然而,其短板也十分明显:核心方法(AMG)并非原创,只是适配和应用,且实验仅限于单一模型(Stable Audio Open)和相对基础的指标,缺乏与更前沿的音频生成系统(如AudioLDM 2、MusicLM)的对比,说服力打了折扣。
🔗 开源详情
- 代码:提供代码仓库链接:https://polimi-ispl.github.io/anti-memorization-tta/
- 模型权重:使用了开源的Stable Audio Open模型,论文中明确提到“Stable Audio Open [17], which provides publicly available checkpoints”。
- 数据集:评估使用了Stable Audio Open 1.0数据集中的6000个音轨,该数据集是公开的(来源Freesound和FMA)。论文未提供单独的数据集下载链接,但指向了原始来源。
- Demo:论文中未提及在线演示。
- 复现材料:提供了评估所用的60个样本的选择方法(基于聚类)、所有实验的超参数设置(s0, c1, c2, c3, λt调度等)。由于是推理时方法,无需训练细节。
- 论文中引用的开源项目:Stable Audio Open [17], CLAPlaion [21], MERT [26], Freesound [22], FMA [23]。
📌 核心摘要
- 要解决什么问题:文本到音频扩散模型在推理时可能无意中生成与训练数据高度相似甚至完全复制的音频片段,引发数据记忆化问题,对版权和知识产权构成威胁。
- 方法核心是什么:采用反记忆化指导(AMG)框架,在推理时的去噪过程中监测生成内容与训练集的相似度。当相似度超过阈值时,通过三种策略引导生成过程远离记忆化样本:减少过于具体的提示词影响(Despecification Guidance)、将重复的提示词作为负面条件(Caption Deduplication Guidance)、以及主动在嵌入空间中远离最近邻(Dissimilarity Guidance)。
- 与已有方法相比新在哪里:这是首次将AMG框架应用于音频生成模型的缓解数据记忆化研究。与需要重训练或修改提示词的方法相比,AMG是一种纯推理时的后处理方案,无需重新训练模型,具有即插即用的优势。
- 主要实验结果如何:
- 定量结果(消融实验,见Table 1):与无缓解策略的基线(Mean Similarity CLAP: 0.69)相比,完整AMG方法(Full AMG)将平均相似度显著降低至0.40(CLAPlaion)和0.89(MERT)。其中,差异性指导(gsim)单独作用效果最强。
- 定性结果:图1(频谱图)显示,经AMG生成的音频在时频结构上与原训练音频明显不同。图2(结构相似性矩阵)表明,应用AMG后,生成音频与训练音频的逐帧高相似度区域从对角线偏移。图3(t-SNE可视化)显示,应用AMG的生成样本在嵌入空间中与原始训练数据分布分离,更加分散。
- 音频质量与提示遵循度:消融实验显示,在降低相似度的同时,提示遵循度(CLAPScore)从基线的0.32下降至Full AMG的0.14,存在权衡。但值得注意的是,FAD(Fréchet Audio Distance)指标反而从基线的4.27(CLAPlaion)改善至2.57,表明生成音频的多样性可能增加,更接近整体数据分布。
- 实际意义是什么:为构建更负责任、更合规的文本到音频生成系统提供了一种有效的、无需重训练的推理时工具,有助于缓解生成式AI的版权风险。
- 主要局限性是什么:方法的核心组件并非原创;实验仅在单一的开源模型和数据集上进行,泛化性有待验证;在降低记忆化的同时,可能会牺牲一部分提示遵循度;框架的计算开销(需要计算相似度和梯度)尚未详细讨论。
🏗️ 模型架构
论文研究的对象是潜在扩散模型(Latent Diffusion Model, LDM),其架构分为两个部分:编码器-解码器对和扩散模型本身。本文的贡献不在于设计新架构,而是提出一种适用于现有架构的推理时干预框架。
基础生成模型架构(Stable Audio Open):
- 输入:文本提示
y。 - 核心组件:
- 编码器 E 和 解码器 D:将原始音频信号
x映射到潜在空间z = E(x),并能将潜在向量解码回音频x = D(z)。 - 噪声预测网络
ϵθ:通常是一个基于Transformer的U-Net,在潜在空间中工作。它学习在给定时间步t和带噪声的潜在向量zt的条件下,预测添加的噪声ϵ。
- 编码器 E 和 解码器 D:将原始音频信号
- 流程:前向过程向潜在向量
z0添加噪声直至zT;反向过程则从zT开始,由ϵθ预测噪声并逐步去除,最终生成清晰的潜在向量,再解码为音频。
- 输入:文本提示
反记忆化指导(AMG)框架(本文核心):
- 定位:这不是一个独立的模型,而是一个叠加在标准推理流程之上的干预模块。
- 核心逻辑:在每一步去噪时,先尝试从当前噪声潜在向量
zt恢复出一个临时的音频样本ˆx。计算该样本与训练集样本在CLAP嵌入空间中的最近邻ν,并计算相似度σt。如果σt超过预设阈值λt,则生成一个组合的引导向量g = gspe + gdup + gsim,并将其加到噪声预测ˆϵ上,从而将生成方向“推离”记忆化的样本。 - 三种引导策略:
- Despecification Guidance (
gspe):计算方式类似于Classifier-Free Guidance (CFG),但符号相反。它通过降低条件(文本提示)的引导强度s1来实现,且s1的值动态依赖于当前相似度σt。目的是削弱过于具体的提示词导致的复制。 - Caption Deduplication Guidance (
gdup):将最近邻样本ν的文本描述yν作为“负面提示”,通过类似的反向CFG操作−s2(ϵθ(zt, yν) − ϵθ(zt)),引导生成远离由重复标题产生的内容。其强度s2也受σt和s1的约束。 - Dissimilarity Guidance (
gsim):通过计算相似度σt相对于当前音频表示xt的梯度,并沿梯度反方向移动,从而最小化与最近邻的相似度。其公式为gsim = c3 √(1−αt) ∇xt σt。
- Despecification Guidance (
💡 核心创新点
- 首次将反记忆化指导框架引入音频领域:将原本用于图像生成的AMG思想适配到音频潜在扩散模型中,填补了音频生成模型在推理时缓解数据记忆化方法上的空白。
- 提出三种针对性的引导策略组合:通过“去特异性”、“标题去重”和“差异性”三个维度,分别针对用户提示过于详细、训练数据标题重复以及生成结果与训练样本整体相似这三个主要记忆化来源进行干预。
- 基于内容嵌入的动态监控与干预机制:利用CLAP模型提取音频的语义嵌入来计算相似度,使监控和干预基于内容的语义相似性,而非简单的波形匹配,对时移等变换更具鲁棒性。干预阈值和强度可根据当前生成的相似度动态调整。
🔬 细节详述
- 训练数据:使用 Stable Audio Open 1.0 数据集中的6000个音轨进行评估,来源为Freesound和FMA,包含音乐和音效,采样率44.1kHz。为了选择最可能触发记忆化的样本,使用CLAPlaion融合嵌入对6000个样本进行k-NN聚类,并从每个聚类最密集的区域选取一个样本,共得到60个评估样本。论文中未说明训练集本身的完整预处理流程(因为评估是使用预训练模型进行的)。
- 损失函数:基础LDM使用标准的噪声预测损失
L = E[||ϵt − ϵθ(zt, t)||²]。AMG框架本身不引入新的训练损失,只在推理时修改噪声预测。 - 训练策略:论文中未说明 Stable Audio Open 模型的训练策略、学习率、batch size等细节。AMG是纯推理时方法,无需训练。
- 关键超参数:
- 推理步数:100步。
- CFG尺度
s0:7。 - AMG阈值调度
λt:抛物线调度,从0.4到0.5。 - 引导系数:
c1 = c2 = s0 - 1 = 6;c3 = 1000(通过经验调优)。
- 训练硬件:论文中未提及。
- 推理细节:使用标准DDPM/DDIM采样过程,但在每一步(公式6)会根据相似度条件决定是否施加AMG引导。
- 正则化或稳定训练技巧:论文中未提及基础模型的训练技巧。对于AMG,通过
min(·)和max(·)函数(公式10, 12)来约束引导强度,防止过度偏离原始提示或产生负值。
📊 实验结果
本文的实验主要围绕以下几点展开:定性可视化、相似度分析、消融研究、提示遵循度与音频质量评估。
表1:引导策略消融研究
| 引导策略 | Mean Similarity ↓ | Prompt Adherence ↑ | FAD ↓ | KAD ↓ | MAD ↓ | |
|---|---|---|---|---|---|---|
| CLAPlaion | MERT | CLAPlaion | CLAPlaion | MERT | CLAPlaion | |
| Baseline (无引导) | 0.69 | 0.95 | 0.32 | 4.27 (0.17) | 17.20 (4.22) | 4.22 |
| gspe | 0.69 | 0.95 | 0.32 | 4.15 (0.16) | 16.91 (3.65) | 3.65 |
| gdup | 0.64 | 0.93 | 0.27 | 3.94 (0.16) | 17.13 (4.36) | 4.36 |
| gsim | 0.41 | 0.90 | 0.20 | 3.55 (0.15) | 18.24 (3.50) | 3.50 |
| gspe + gdup | 0.62 | 0.93 | 0.25 | 3.29 (0.15) | 17.67 (3.10) | 3.10 |
| gspe + gsim | 0.43 | 0.90 | 0.19 | 2.93 (0.15) | 17.61 (3.12) | 3.12 |
| gdup + gsim | 0.41 | 0.89 | 0.16 | 2.84 (0.15) | 17.72 (3.11) | 3.11 |
| Full AMG (全部引导) | 0.40 | 0.89 | 0.14 | 2.57 (0.15) | 18.27 (2.74) | 2.74 |
| 注:Mean Similarity, Prompt Adherence, KAD, MAD 的第一列为基于CLAPlaion的计算结果,第二列(若存在)为基于MERT的计算结果。FAD第一列为基于CLAPlaion的计算结果,括号内为基于MERT的结果。↓表示越低越好,↑表示越高越好。 |
关键结论:
- 降低记忆化最有效的是
gsim(差异性引导),单独使用即可将Mean Similarity (CLAPlaion) 从0.69降至0.41。 - 所有策略组合使用(Full AMG)效果最好,将Mean Similarity降至最低(0.40)。
- 存在权衡:随着记忆化缓解,Prompt Adherence(提示遵循度)普遍下降,Full AMG模式下从0.32降至0.14。
- 一个反直觉的发现:衡量生成音频与真实数据分布差异的FAD指标在应用AMG后反而���善(降低),Full AMG模式下从4.27降至2.57。论文推测这是因为基线的“记忆化”产生了重复、单调的输出,而AMG鼓励了更多样性,从而更接近多样化的参考数据分布。
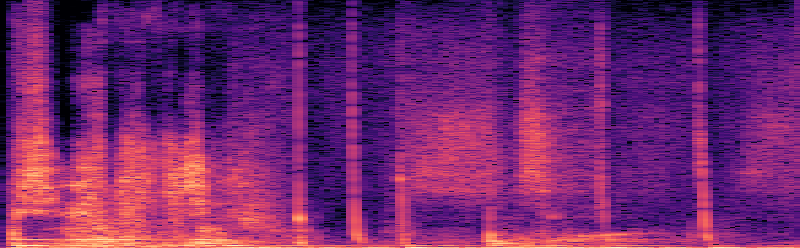 图1显示: (a)是原始训练音频的频谱图;(b)是使用相同提示但未应用AMG生成的音频,其时频结构与(a)高度相似;(c)是应用AMG后生成的音频,其时频结构与(a)有显著差异,表明记忆化被缓解。
图1显示: (a)是原始训练音频的频谱图;(b)是使用相同提示但未应用AMG生成的音频,其时频结构与(a)高度相似;(c)是应用AMG后生成的音频,其时频结构与(a)有显著差异,表明记忆化被缓解。
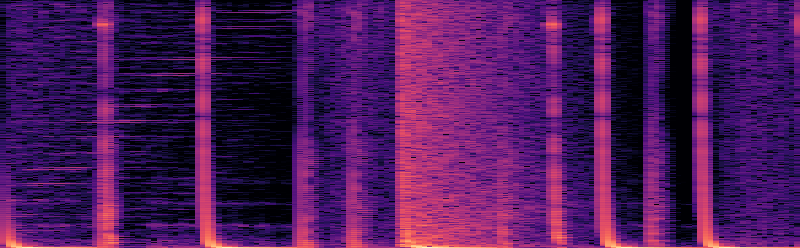 图2显示:矩阵的每个元素表示生成音频段与训练音频段的相似度。(a)未应用AMG,高相似度区域集中在对角线,表明存在逐段的复制。(b)应用AMG后,高相似度区域偏离对角线,表明生成内容与训练内容在时间结构上已不同。
图2显示:矩阵的每个元素表示生成音频段与训练音频段的相似度。(a)未应用AMG,高相似度区域集中在对角线,表明存在逐段的复制。(b)应用AMG后,高相似度区域偏离对角线,表明生成内容与训练内容在时间结构上已不同。
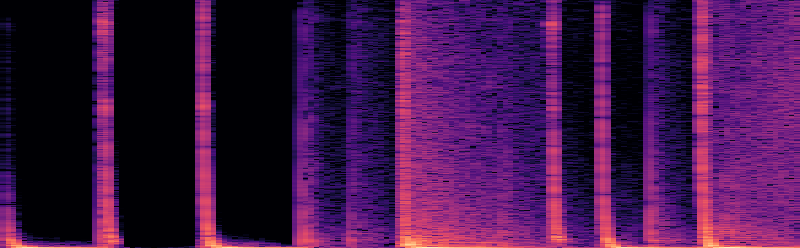 图3显示:将数据集样本、未经缓解的生成样本(Memorization)和经AMG缓解的生成样本(Full AMG)的嵌入进行可视化。(a)使用CLAPlaion嵌入,(b)使用MERT嵌入。在两种嵌入空间中,未经缓解的生成样本都与训练数据簇紧密聚集,而应用AMG的生成样本则分布更为分散,远离训练数据簇。
图3显示:将数据集样本、未经缓解的生成样本(Memorization)和经AMG缓解的生成样本(Full AMG)的嵌入进行可视化。(a)使用CLAPlaion嵌入,(b)使用MERT嵌入。在两种嵌入空间中,未经缓解的生成样本都与训练数据簇紧密聚集,而应用AMG的生成样本则分布更为分散,远离训练数据簇。
⚖️ 评分理由
- 学术质量:6.5/7:论文问题定位准确,方法适配得当,实验设计全面(包括定性、定量和消融),数据呈现清晰。创新性虽为应用层面,但具有实用价值。技术细节描述基本完整,部分训练细节缺失但对推理方法影响有限。结论基于充分证据。
- 选题价值:2.0/2:选题紧扣生成式AI的伦理与法律痛点,具有强烈的现实需求和技术前沿性。对于推动音频生成技术的负责任发展有明确意义,与广大AI研究者和开发者高度相关。
- 开源与复现加成:0.0/1:提供了核心代码仓库、开源模型和评估数据集链接,并给出了关键超参数。这是一个良好的开源实践,但未提供超出预期的复现材料(如预计算的嵌入、完整的配置文件等),因此给予中性加成。