📄 Mitigating Attention Sinks and Massive Activations in Audio-Visual Speech Recognition with LLMs
#语音识别 #语音大模型 #多模态模型 #音视频 #预训练
✅ 7.0/10 | 前25% | #语音识别 | #语音大模型 | #多模态模型 #音视频
学术质量 7.0/7 | 选题价值 6.0/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Anand(不列颠哥伦比亚大学)
- 通讯作者:未说明
- 作者列表:Anand(不列颠哥伦比亚大学,加拿大)、Umberto Cappellazzo(伦敦帝国学院,英国)、Stavros Petridis(伦敦帝国学院,英国)、Maja Pantic(伦敦帝国学院,英国)
💡 毒舌点评
亮点在于从现象观察到机理分析(余弦相似度对齐)再到解决方法(去相关损失)形成了一个完整闭环,且控制旋转实验的验证相当漂亮。短板则是实验仅在单一的Llama 3.2-3B模型和有限的设置下进行,对于“该现象是否普遍存在于所有音视频LLM”以及“去相关损失是否会对模型其他能力产生副作用”这两个关键问题,论文缺乏更深入的探讨。
🔗 开源详情
- 代码:论文中未提及提供本研究的代码仓库链接。
- 模型权重:未提及公开微调后的模型权重。
- 数据集:未提及本研究使用的具体数据集及其获取方式。
- Demo:未提及提供在线演示。
- 复现材料:未提供详细的训练配置、检查点或附录说明。论文提到实验细节可参考[8],但自身贡献部分的复现信息缺失。
- 论文中引用的开源项目:
- [8] Llama-AVSR:作为基础架构和实验细节的参考。
- [17] LoRA:作为参数高效微调方法。
- [28] AV-HuBERT:作为视频编码器。
- [29] Whisper:作为音频编码器。
- [31] LLaMA 3:作为基础LLM。
- 论文中未提及本研究的开源计划。
📌 核心摘要
本文首次研究了音视频语音识别(AVSR)大型语言模型(LLM)中存在的“注意力沉降”和“大规模激活”现象。论文发现,在微调过程中,除BOS token外,一些语义信息弱的中间token也会成为注意力沉降点,并且与BOS token在隐层空间中具有高余弦相似度,这导致了特征索引相同的大规模激活。基于此发现,作者提出了一种简单的去相关损失,通过惩罚BOS与其他token的余弦相似度来缓解这些问题。实验表明,该方法在Llama-AVSR模型上,在高音频-视频特征下采样率下能有效降低词错率(WER),例如在AVSR(16,5)设置下WER从4.15降至3.72。该方法的贡献在于为理解多模态LLM内部机制提供了新视角,并提供了一种轻量、有效的训练技巧以提升模型在压缩场景下的鲁棒性。局限性在于实验验证的LLM模型较为单一。
主要实验结果(摘自表1与表2):
| 任务 | 压缩率 | 基线WER(%) | 本方法WER(%) | 改进(∆) |
|---|---|---|---|---|
| ASR | (32) | 12.92 | 11.50 | +1.42 |
| VSR | (5) | 45.19 | 34.08 | +11.11 |
| AVSR | (16,5) | 4.15 | 3.72 | +0.43 |
| 任务 | 压缩率 | 基线WER(%) | ACT方法WER(%) | 本方法WER(%) |
|---|---|---|---|---|
| ASR | (32) | 12.92 | 12.81 | 11.50 |
| AVSR | (16,5) | 4.15 | 4.08 | 3.72 |
(注:表1显示,在低压缩率下性能提升微小,高压缩率下改善显著,尤其VSR任务。表2表明本方法优于现有的注意力校准(ACT)方法。)
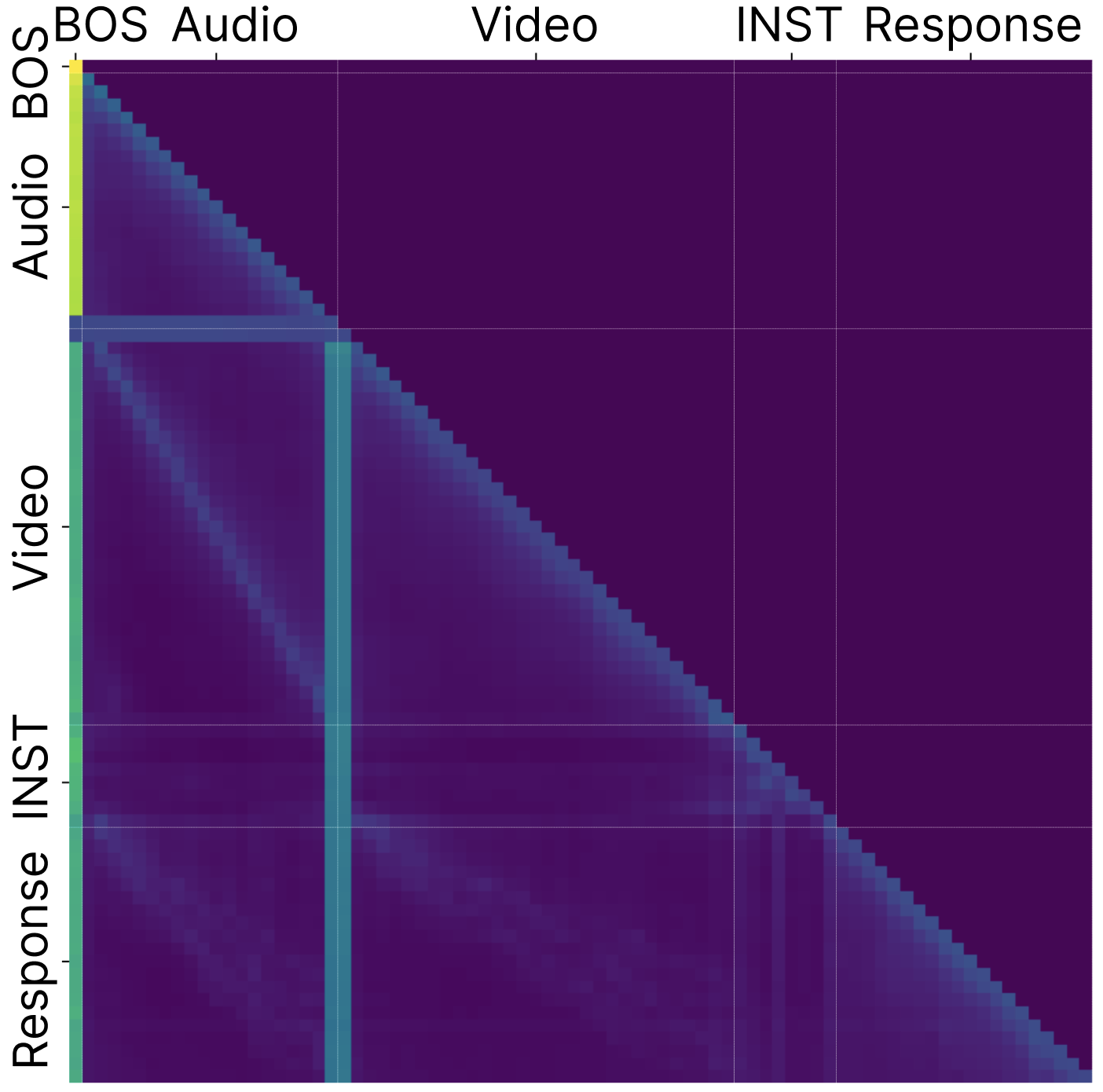 图1 (a-c) 显示了在ASR、VSR和AVSR任务中,BOS token和部分中间token(如索引20、21)存在异常高的注意力分数(颜色更深)。图(d)展示了在Llama-AVSR (16,5)模型第5层,这些沉降token的某些特征维度激活值(z轴)远超其他token。
图1 (a-c) 显示了在ASR、VSR和AVSR任务中,BOS token和部分中间token(如索引20、21)存在异常高的注意力分数(颜色更深)。图(d)展示了在Llama-AVSR (16,5)模型第5层,这些沉降token的某些特征维度激活值(z轴)远超其他token。
🏗️ 模型架构
论文分析的对象是 Llama-AVSR 架构。其整体流程如下:
- 输入编码:
- 音频路径:使用预训练的 Whisper 编码器将原始音频转换为音频嵌入序列。
- 视频路径:使用预训练的 AV-HuBERT 编码器将视频(唇部区域)转换为视频嵌入序列。
- 压缩与投影:
- 为了降低计算成本,对高维且时序密集的音频和视频嵌入进行时间维度上的平均池化下采样,压缩率记为(a, v),例如AVSR(16,5)表示音频下采样16倍,视频下采样5倍。
- 压缩后的音频/视频token通过轻量线性投影器映射到LLM的嵌入空间。
- LLM生成:
- 将投影后的音频token
Xaud、视频tokenXvid和指令提示Xinst进行拼接,输入到一个预训练的LLM(如Llama 3.2-3B)。 - LLM以自回归方式生成转录文本
Y。
- 将投影后的音频token
- 微调:整个模型(主要是投影器和LLM)通过LoRA进行参数高效微调。
内部动态分析(核心): 论文聚焦于LLM内部的Transformer解码器块,每个块包含多头自注意力(MHSA) 和多层感知机(MLP)。分析重点是:
- 注意力沉降:计算每个token从所有其他token获得的平均注意力分数(公式5),发现BOS和部分中间token(如特殊标记
<audio>、</audio>)的注意力分数异常高。 - 大规模激活:定义了“大规模激活特征集”
Θl_i(公式6),发现该集合仅存在于沉降token上,且在不同沉降token间完全相同。 - 根源分析:通过计算沉降token与BOS token隐层状态的余弦相似度(公式7),发现中间沉降token与BOS高度方向对齐,从而解释了为何它们会吸引相同注意力并激活相同特征维度。
- 验证实验:通过控制旋转(公式8,9)改变token的隐层方向,直接证明了方向对齐是产生注意力沉降和大规模激活的充分条件。
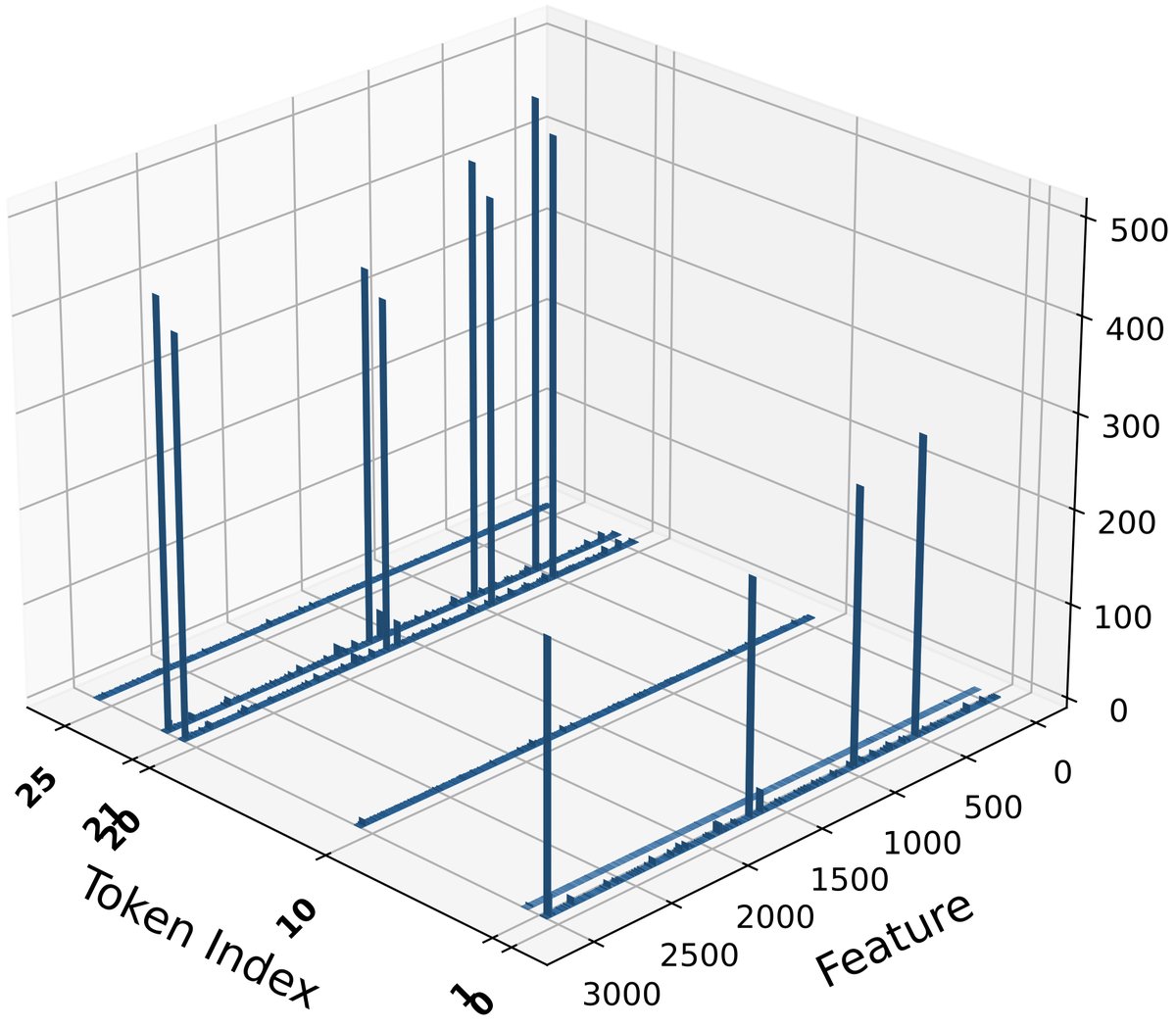 图2(a)显示中间注意力沉降从第2层之后开始出现。图2(b)通过分解第2层组件的贡献,证明大规模激活源自MLP模块。
图2(a)显示中间注意力沉降从第2层之后开始出现。图2(b)通过分解第2层组件的贡献,证明大规模激活源自MLP模块。
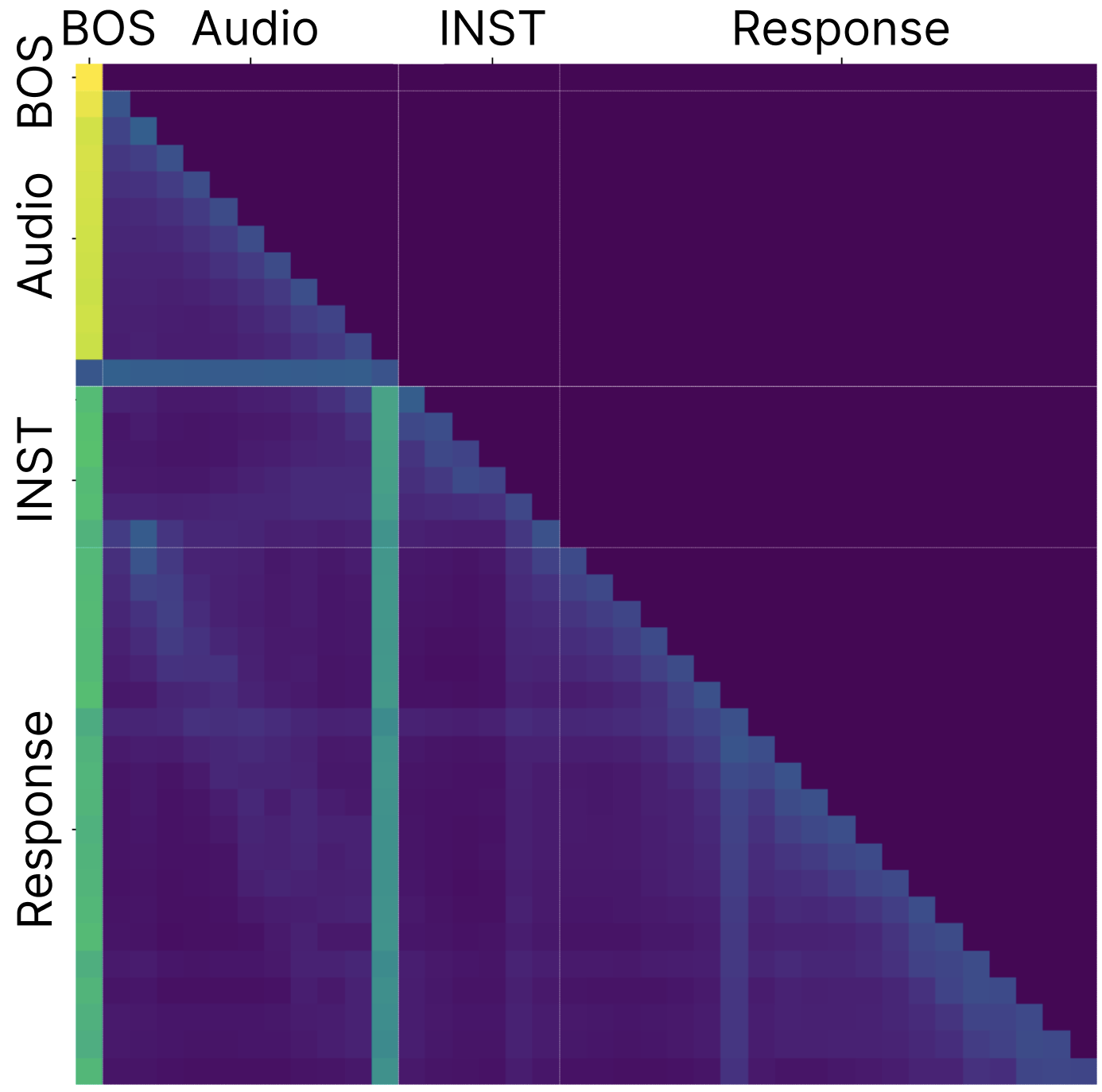 图3(a)显示中间沉降token与BOS token的余弦相似度从第2层起就很高,而非沉降token则很低。图3(b)的成对余弦相似度热力图显示,沉降token(索引0, 20, 21)彼此高度相似,而与其他token正交。
图3(a)显示中间沉降token与BOS token的余弦相似度从第2层起就很高,而非沉降token则很低。图3(b)的成对余弦相似度热力图显示,沉降token(索引0, 20, 21)彼此高度相似,而与其他token正交。
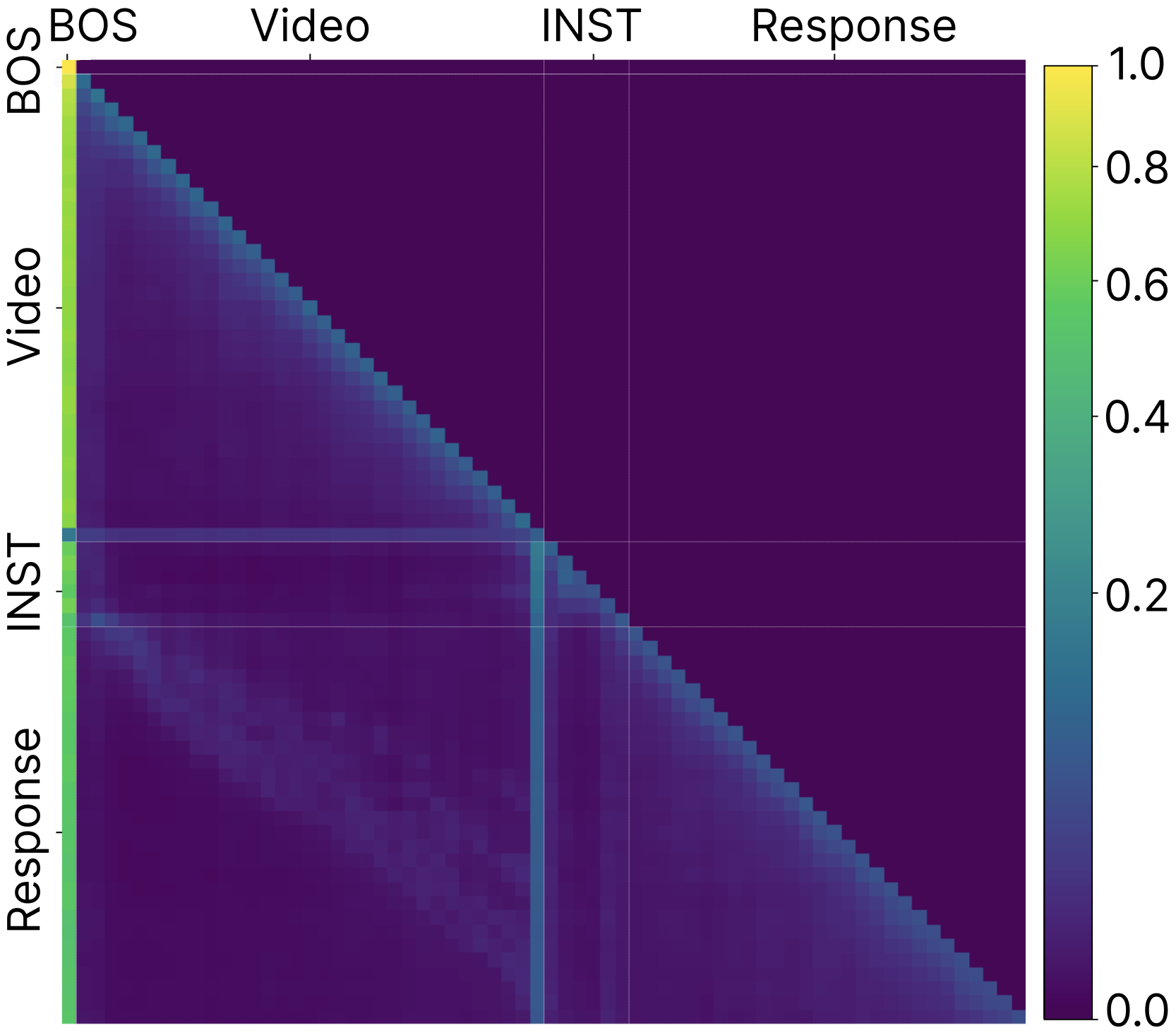 图4(a,b)显示,将沉降token的方向旋转至与非沉降token一致后,其沉降和大规模激活现象消失。图4(c,d)显示,将一个非沉降token旋转至与BOS方向一致后,该token立刻出现了沉降和大规模激活现象。
图4(a,b)显示,将沉降token的方向旋转至与非沉降token一致后,其沉降和大规模激活现象消失。图4(c,d)显示,将一个非沉降token旋转至与BOS方向一致后,该token立刻出现了沉降和大规模激活现象。
💡 核心创新点
- 首次在多模态语音识别LLM中系统分析“注意力沉降”与“大规模激活”:此前研究集中于NLP和视觉领域,本文将分析拓展到音频-视觉语音识别(AVSR、ASR、VSR),填补了该领域对LLM内部机制理解的空白。
- 揭示中间沉降token的成因及其与BOS的方向对齐关系:发现微调产生的中间沉降token并非随机出现,而是其隐层表示与BOS token在方向上高度相似(高余弦相似度),这一发现统一解释了注意力沉降和大规模激活两种现象的共现。
- 提出轻量有效的“去相关损失”以缓解上述问题:不同于需要修改架构或仅在推理时调整的方法(如Softmax-off-by-one, ACT),本文提出的损失函数可无缝集成到LoRA微调中,无额外推理开销,并能同时缓解注意力沉降和大规模激活。
- 通过控制旋转实验证明因果关系:通过人工操纵token的隐层表示方向,直接证明了“与BOS方向对齐”是导致注意力沉降和大规模激活的充分条件,增强了分析的说服力。
🔬 细节详述
- 训练数据:论文中未提供具体数据集名称、规模、预处理细节。仅提及实验遵循了参考文献[8](Llama-AVSR)的训练细节和代码。
- 损失函数:
- 主要损失:标准的自回归交叉熵损失
LCE。 - 新增损失:去相关损失
Ldecorr(公式10),计算从第2层到倒数第2层中,所有非BOS token与BOS token隐层状态的余弦相似度平方的平均值。 - 总损失:
L = LCE + λ * Ldecorr。超参数λ从{10, 10^2, 10^4}中选择最佳值。
- 主要损失:标准的自回归交叉熵损失
- 训练策略:未提供学习率、warmup、batch size、优化器、训练步数等详细信息。
- 关键超参数:LLM基础模型为 Llama 3.2-3B。还测试了Llama 3.2-1B和Llama 2-7B并观察到相似趋势。视频编码器为AV-HuBERT,音频编码器为Whisper。
- 训练硬件:未提供GPU型号、数量、训练时长。
- 推理细节:未提及解码策略、温度、beam size等。
- 正则化/稳定技巧:提出的方法本身(去相关损失)可视为一种正则化,以提升模型在高压缩率下的稳定性。
📊 实验结果
主要Benchmark与结果:
- 数据集:未在论文主体中明确指出。根据实验设置描述,ASR和AVSR可能在LRS2数据集上,VSR可能在LRS3数据集上(因任务更具挑战性)。
- 指标:词错率(WER,%)。数值越低越好。
- 主要对比:
- 自身对比(表1):展示了应用去相关损失(Decorr.)后,在多个任务和压缩率下的WER改善。关键结论:在高压缩率(信息稀缺)下改善显著(如ASR(32)降低1.42,VSR(5)降低11.11),在低压缩率下改善微小。
- 与先前方法对比(表2):将本方法与另一种缓解中间沉降的方法——注意力校准(ACT) 进行对比。在Llama-AVSR(16,5)和ASR(32)设置下,本方法性能显著优于ACT。关键结论:ACT仅带来边际提升,而本方法有效缓解了注意力沉降与大规模激活,带来了更大的WER收益。
消融实验/机理验证:
- 控制旋转实验(图4):这是关键的机理验证。它直接证明了:
- 将沉降token(索引20,21)的隐层方向旋转至非沉降token方向后,其注意力沉降和大规模激活现象消失(图4a,b)。
- 将非沉降token(索引10)的隐层方向旋转至BOS方向后,该token立刻涌现出注意力沉降和大规模激活现象(图4c,d)。
- 此实验强有力地支持了“方向对齐是根源”的论点。
不同条件下的结果:
- 任务维度:方法在ASR、VSR、AVSR三个任务上均有效,但在VSR(纯视觉语音识别)任务上提升最大。
- 压缩率维度:方法的效果与压缩率正相关,高压缩率下收益最大。
⚖️ 评分理由
- 学术质量:5.5/7:论文在分析深度和问题洞察上表现出色,控制旋转实验设计巧妙,逻辑严谨。所提方法直接针对发现的问题,简单有效。主要扣分点在于实验验证的广度(仅基于一种LLM)和深度(缺乏对损失权重λ影响的分析、未探讨方法对模型其他能力如长序列理解的潜在影响)不足,结论的普适性有待更多验证。
- 选题价值:1.5/2:研究LLM在多模态任务中的内部机制,对于提升模型性能、效率和可解释性具有重要理论和实践意义。去相关损失为解决高压缩率下性能下降问题提供了新思路。选题前沿,与当前“高效多模态LLM”热点高度相关。扣分点在于该发现目前仅针对语音识别任务,其更广泛的影响力尚未证明。
- 开源与复现加成:0.0/1:论文未提供本工作的代码、模型、数据集或详细超参数。虽然引用了基础项目[8],但完整复现仍存在障碍。