📄 Mispronunciation Detection and Diagnosis Without Model Training: A Retrieval-Based Approach
#语音评估 #检索增强 #预训练 #零样本 #语音大模型
🔥 8.0/10 | 前25% | #语音评估 | #检索增强 | #预训练 #零样本
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Huu Tuong Tu(河内科技大学,VNPT AI/VNPT集团)
- 通讯作者:Nguyen Thi Thu Trang(河内科技大学)
- 作者列表:Huu Tuong Tu(河内科技大学,VNPT AI/VNPT集团)、Ha Viet Khanh(河内科技大学)、Tran Tien Dat(河内科技大学)、Vu Huan(国家经济大学)、Thien Van Luong(国家经济大学)、Nguyen Tien Cuong(VNPT AI/VNPT集团)、Nguyen Thi Thu Trang(河内科技大学)
💡 毒舌点评
亮点:论文巧妙地将“检索”这一思想从生成领域迁移到了评估任务,构建音素嵌入池替代了复杂的模型训练,思路清新且在FRR等关键指标上效果显著,证明了预训练模型蕴含的语音知识足以支持细粒度的发音诊断。短板:作为一篇强调“无训练”的方法,其在大规模真实场景下的鲁棒性存疑,且论文承认的高插入错误率(PER高达104%)暴露出检索式方法在序列生成上的固有短板,这与其说是一个“特性”,不如说是一个待解决的“问题”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:使用了公开的预训练模型
facebook/hubert-large-ls960-ft、facebook/data2vec-audio-large-960h、facebook/wav2vec2-large-960h-lv60。本文提出的方法本身不包含可训练的模型权重,其核心“模型”是构建好的音素嵌入池。 - 数据集:使用公开的L2-ARCTIC数据集,论文中未提供直接获取链接。
- Demo:未提供。
- 复现材料:论文给出了主要超参数(池大小500,阈值0.7,top-k=10)和池化策略(mid-frame),但未提供数据预处理、池构建、检索和评估的完整代码或详细步骤。
- 论文中引用的开源项目:引用了Hugging Face上的HuBERT、Data2vec、Wav2vec2模型。
- 总结:论文中未提及开源计划。复现需自行处理数据集、实现检索逻辑并复用公开的预训练模型。
📌 核心摘要
- 问题:传统的发音错误检测与诊断(MDD)系统通常需要训练或微调专门的声学模型(如音素识别器),过程复杂且依赖大量标注数据。
- 方法核心:提出了一种基于检索的免训练框架(PER-MDD)。首先,利用预训练的HuBERT模型,为训练集中的每个音素片段提取其中心帧的嵌入向量,构建一个“音素嵌入池”。在推理时,对测试语音的每一帧提取嵌入,在池中通过余弦相似度检索最相似的k个候选音素,通过投票和阈值筛选确定预测的音素,最后与标准音素序列对齐以检测错误。
- 新在哪里:首次将检索增强生成(RAG)的范式应用于MDD任务,避免了任何音素级模型的训练,完全依赖一个预训练的、通用的ASR模型(HuBERT)和一个检索过程。
- 主要实验结果:在L2-ARCTIC数据集上,PER-MDD在MDD的核心指标上表现优异:错误拒绝率(FRR)为4.43%(最低),F1分数为69.60%(最高),检测准确率(DA)为91.57%。与强基线MDDGCN相比,F1提升了约13个百分点。消融实验证明了HuBERT模型、中间帧池化策略和适度的检索池大小(500条语料)的有效性。
- 实际意义:为CAPT系统提供了一种更简单、轻量、易于部署的MDD方案,降低了构建发音诊断系统的门槛。
- 主要局限性:该方法会产生较多的插入错误,导致语音识别的词错误率(PER)远高于基线方法(104.08% vs ~17%),虽然论文认为这对MDD影响不大,但这仍然是其技术路线的一个明显缺陷。此外,性能依赖于检索池的质量和大小,对新领域或新说话人的泛化能力有待验证。
🏗️ 模型架构
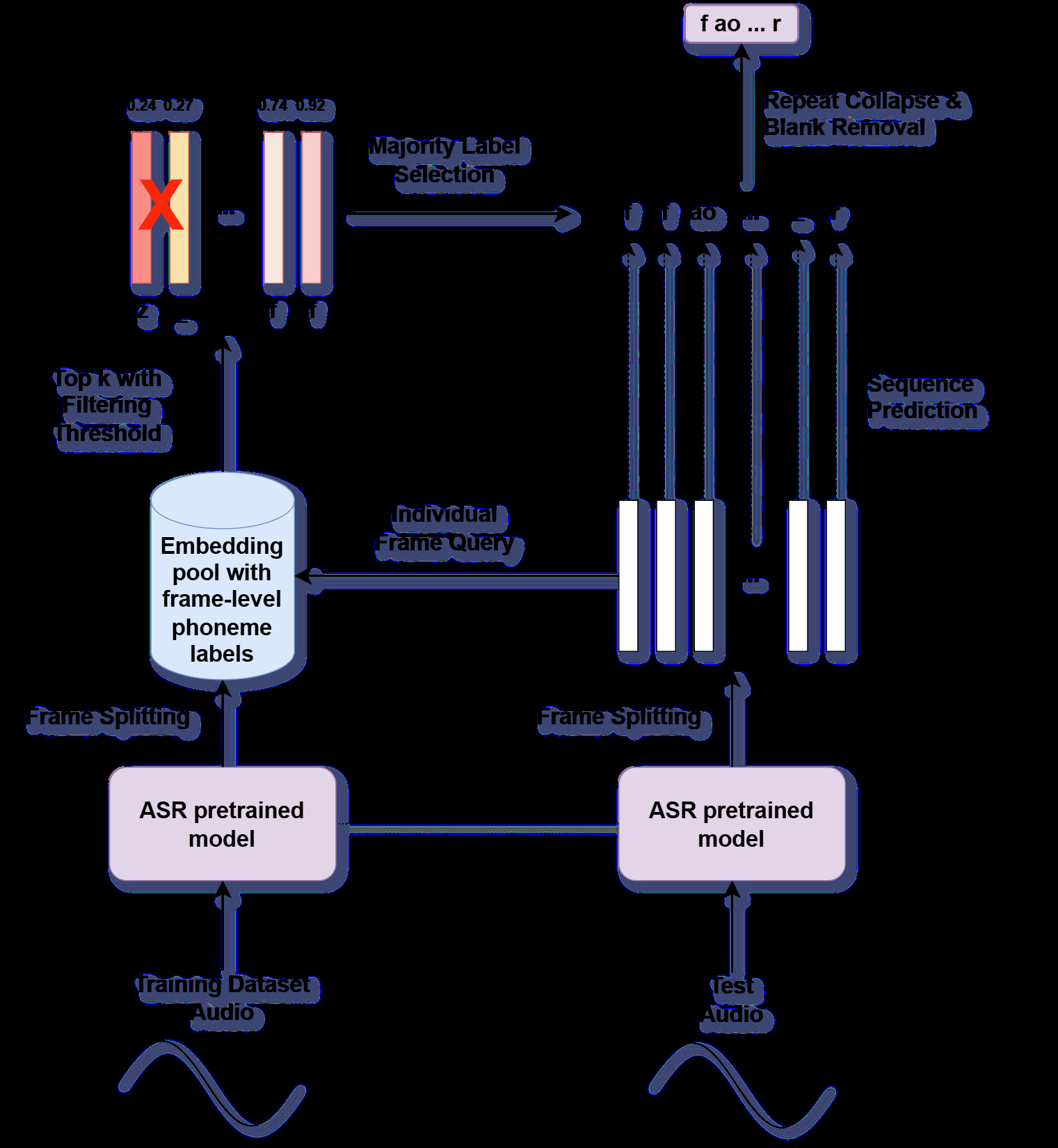 该模型(PER-MDD)的整体架构是一个两阶段的检索流水线:
该模型(PER-MDD)的整体架构是一个两阶段的检索流水线:
- 音素嵌入池构建阶段(离线):
- 输入:带音素级时间对齐标注的训练语音数据集。
- 处理:使用预训练的HuBERT模型作为声学编码器,为每帧音频生成一个高维嵌入向量。根据时间对齐信息,为每个音素片段(span)选择其中间帧的嵌入向量作为该音素的代表,并记录其对应的音素标签。
- 输出:构建一个音素嵌入池
P,它是一个包含大量(embedding, phoneme_label)对的数据库。
- 检索与预测阶段(在线):
- 输入:待测试的语音(用户朗读指定文本的音频)。
- 处理:
- 同样使用HuBERT对测试语音逐帧提取嵌入,得到查询向量序列
{q_t}。 - 对于每一个查询向量
q_t,在音素嵌入池P中进行最近邻检索(基于余弦相似度),找出Top-k个最相似的向量及其对应的音素标签。 - 对检索到的k个音素标签进行投票,并应用一个相似度阈值过滤,将得票最高的音素作为该帧的预测标签
ŷ_t。 - 对预测的帧级标签序列进行后处理:合并连续重复的标签、移除空白符,得到最终的预测音素序列
Ŷ。
- 同样使用HuBERT对测试语音逐帧提取嵌入,得到查询向量序列
- 输出:预测的音素序列
Ŷ。
- 诊断阶段:将预测音素序列
Ŷ与标准文本对应的规范音素序列进行对齐,从而识别出错误拒绝(FR,正确被误判为错误)、错误接受(FA,错误被误判为正确)等情况,计算各项MDD指标。
关键设计选择与动机:
- 检索替代训练:动机是避免为每个目标语言或每种口音训练和维护一个专门的音素识别模型。利用通用预训练模型(如HuBERT)已学到的丰富语音表示。
- 中间帧池化:论文消融实验表明,使用音素片段的中间帧比使用全部帧或平均帧效果更好,且能大幅减小池体积,提高检索效率。
- Top-k检索与阈值过滤:结合投票和阈值,旨在提高预测的鲁棒性,避免因个别不相似的噪声检索结果导致误判。
💡 核心创新点
- 免训练的检索式MDD框架:这是最核心的创新。传统MDD需要训练音素识别或评分模型,而本文方法仅需构建一个检索池,推理时直接进行相似性匹配。这简化了部署流程,降低了计算和数据需求。
- 将预训练ASR模型作为“检索引擎”:创新性地将HuBERT等模型的角色从传统的“序列生成器”转变为“向量编码器”,其生成的嵌入直接用于在固定池中进行检索,验证了预训练语音表示在细粒度发音评估任务上的有效性。
- 基于帧级检索的音素级诊断:不同于直接输出整句音素序列的方法,本方法通过帧级检索和后处理来得到音素序列,使得诊断可以定位到具体的音素错误(如替换、遗漏),粒度更细。
- 引入RAG思想解决语音评估问题:将自然语言处理中成熟的检索增强生成思想,跨领域迁移到语音评估任务中,开辟了新的方法思路。
🔬 细节详述
- 训练数据:使用公开的L2-ARCTIC数据集。训练集由12位非英语母语说话人的语音构成,但用于构建检索池的仅从中随机采样了500条音频文件。测试集由另外6位说话人的语音构成。
- 损失函数:未说明。因为本文方法无需训练模型,所以没有定义任务损失函数。
- 训练策略:不涉及传统意义上的模型训练。唯一“训练”过程是构建音素嵌入池:对选定的500条训练音频,用HuBERT提取帧嵌入,并根据时间对齐信息选取中间帧嵌入和标签。未说明构建此池的具体硬件耗时。
- 关键超参数:
- ASR模型:HuBERT-Large(
facebook/hubert-large-ls960-ft),Data2vec-Large,Wav2vec2-Large。 - 嵌入池大小(Pool Size):默认500条语料的中间帧嵌入。消融实验测试了100, 200, 500, 1800(全部训练集)。
- 检索Top-k:默认10。消融实验测试了5, 6, 7, 8, 9, 10。
- 相似度阈值(τ):默认0.7。消融实验测试了0.6, 0.7, 0.8, 0.9。
- 池化策略:默认
Mid-frame(中间帧)。消融实验对比了All(所有帧)和Mean(平均帧)。
- ASR模型:HuBERT-Large(
- 训练硬件:未说明。
- 推理细节:解码策略为检索+投票+后处理。无温度、beam size等参数。非流式处理。
- 正则化或稳定训练技巧:不适用,因为没有训练过程。相似度阈值和Top-k的选择起到了类似正则化的作用,平衡了精度与召回。
📊 实验结果
主要的实验对比结果如下表所示:
表1:与基线模型的性能对比
| 模型 | FRR↓ | FAR↓ | DER↓ | PRE↑ | REC↑ | F1↑ | DA↑ | PER↓ | COR↑ |
|---|---|---|---|---|---|---|---|---|---|
| PHN-M2 [17] | 6.33 | 45.37 | 25.12 | 64.51 | 54.63 | 59.16 | 86.88 | 17.12 | - |
| L1-MultiMDD [11] | 4.60 | - | - | - | - | 57.40 | - | 12.55 | - |
| w2v2-XLSR [8] | 5.70 | 41.80 | 29.28 | 62.86 | 58.20 | 60.44 | - | 16.20 | - |
| Joint-Align [18] | - | - | - | 77.12 | 53.31 | 63.04 | - | - | - |
| MDDGCN [9] | 9.18 | 38.03 | 25.24 | 51.90 | 61.97 | 56.49 | - | - | - |
| MVmulti-MTseq [13] | - | - | - | 61.43 | 59.23 | 60.31 | - | 14.13 | - |
| PER-MDD (Ours) | 4.43 | 32.44 | 37.77 | 71.78 | 67.56 | 69.60 | 91.57 | 104.08 | 90.42 |
- 关键结论:PER-MDD在MDD任务上表现突出。FRR(错误拒绝率)最低(4.43%),意味着它很少将正确的发音判错;F1分数最高(69.60%),相较于最强基线(如Joint-Align的63.04%)有显著提升;检测准确率DA也达到91.57%。然而,其语音识别的词错误率PER非常高(104.08%),论文指出这主要是插入错误导致,对MDD指标影响较小。
表2:消融实验结果 论文提供了详细的消融实验(Table 3),验证了各组件影响:
- ASR模型:HuBERT(F1=69.60)优于Data2vec(63.93)和Wav2vec2(69.17)。
- Top-k:k=10(F1=69.60)是一个较好的平衡点,k过小(5)F1提升但PER升高。
- 池大小:池越大,PER越低,MDD指标整体提升。使用全部1800条语料时,FRR降至3.04%,但计算成本也最高。
- 阈值:无阈值或阈值0.6/0.7时,F1接近。阈值过高(0.9)会导致F1急剧下降(49.27%),因为过于严格的过滤会漏掉正确候选。
- 池化策略:中间帧策略(Mid)在F1和FRR上均优于平均帧(Mean)和全帧(All)策略,且池体积更小。
图1:模型流程示意图(已在上方模型架构部分引用)
此图清晰地展示了PER-MDD的两阶段流程:左侧为离线构建音素嵌入池(使用HuBERT和带对齐的训练数据),右侧为在线检索预测过程(对测试音频提帧、检索、投票、后处理、对齐诊断)。
⚖️ 评分理由
- 学术质量:6.0/7 - 创新性突出,首次在MDD中引入检索框架,逻辑自洽。技术路线正确,基于成熟的预训练模型。实验设计全面,有充分的消融研究和与SOTA的对比,结果具有说服力。扣分点在于实验数据集较小,以及高插入错误率这一明显技术缺陷。
- 选题价值:1.5/2 - 紧扣语言学习中的发音评估痛点,提供了一种轻量级解决方案,前沿性强,应���价值明确。
- 开源与复现加成:0.5/1 - 论文使用了公开的预训练模型和数据集,且给出了核心超参数,有一定复现基础。但关键代码、构建检索池的脚本、评估脚本均未开源,导致完整复现存在较大障碍。