📄 MirrorTalk: Forging Personalized Avatars Via Disentangled Style and Hierarchical Motion Control
#语音合成 #扩散模型 #个性化生成 #多模态 #视频生成
✅ 7.0/10 | 前25% | #语音合成 | #扩散模型 | #个性化生成 #多模态
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Renjie Lu(1平安科技(深圳)有限公司, 2中国科学技术大学)
- 通讯作者:Jianzong Wang(1平安科技(深圳)有限公司), Shangfei Wang(2中国科学技术大学)
- 作者列表:Renjie Lu(平安科技、中国科学技术大学), Xulong Zhang(平安科技), Xiaoyang Qu(平安科技), Jianzong Wang(平安科技), Shangfei Wang(中国科学技术大学)
💡 毒舌点评
这篇论文的亮点在于明确指出了现有方法“风格与语义纠缠”的痛点,并设计了精巧的两阶段解耦训练和分层调制机制来解决,实验上也取得了不错的指标提升。短板在于论文中部分关键训练细节(如优化器、学习率调度、硬件配置)语焉不详,且核心代码与模型完全未开源,极大地限制了其可复现性和社区验证的价值。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开数据集(VoxCeleb2, HDTF, CREMA-D),但论文本身未提供新的数据集。
- Demo:未提及。
- 复现材料:未提供详细的超参数配置、训练脚本、检查点或附录说明。
- 引用的开源项目:论文引用并基于以下开源工作:FLAME (3DMM模型)、SMIRK (表情预测)、MICA (形状估计)、3DDFA (姿态估计)、Wav2Lip (运动专家预训练模型)、PIRenderer (神经渲染器)、DiT (扩散模型架构)。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:现有的音频驱动说话脸生成方法存在“说话风格”与“语义内容”在面部运动中纠缠的问题,导致将一个人的风格迁移到新的语音内容时,唇形同步精度下降,面部运动不自然。
- 方法核心:提出MirrorTalk,一个基于条件扩散模型的生成框架。其核心是 语义解耦风格编码器 和 分层调制策略。
- 创新点:1) SDSE通过两阶段训练,从参考视频中提取与语义内容无关的纯粹说话风格表示;2) 在扩散模型的去噪过程中,采用空间-时间分层调制策略,根据面部区域(上/下脸)和去噪时间步,动态平衡音频和风格特征的贡献。
- 实验结果:在CREMA-D和HDTF数据集上,MirrorTalk在唇形同步(M-LMD, Syncconf)和个性化保持(StyleSim)上均优于Wav2Lip、SadTalker、Echomimic等基线方法。例如,在HDTF上StyleSim达到0.958,远超基线的最高值0.866。
- 实际意义:能够生成既准确同步音频,又高度还原目标说话人独特面部动态和表情的个性化数字人视频。
- 主要局限性:1) 对“风格”的定义和解耦依赖于3DMM参数,可能无法捕捉所有微表情;2) 论文中未提供详细的训练配置,如优化器、学习率、batch size等;3) 代码和模型未开源,限制了复现和应用。
🏗️ 模型架构
MirrorTalk的整体流程分为两个主要部分:风格编码和运动合成。
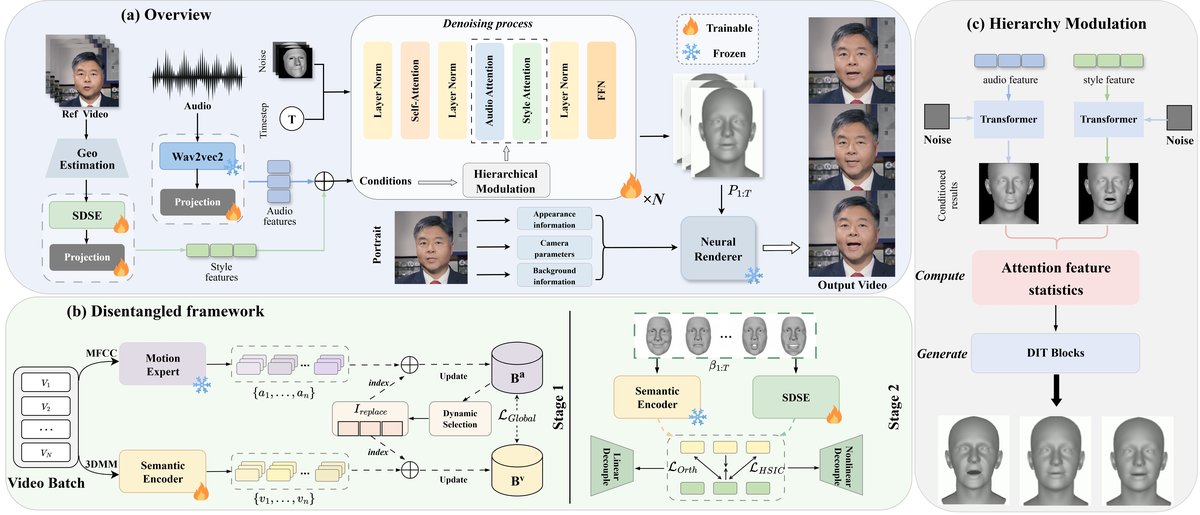
- 输入与预处理:输入为目标说话人的一段参考视频 \(V_i\) 和任意语音音频。首先使用3DMM模型(FLAME)从参考视频中提取面部参数序列 \(P_{1:T} = \{\alpha_t, \beta_t, \theta_t\}\)(形状、表情、姿态)。
- 语义解耦风格编码器:
- 输入:参考视频的表情参数序列 \(\beta_{1:T}\)。
- 骨干网络:一个Transformer编码器,通过自注意力池化将序列表示聚合为一个整体风格嵌入 \(s\)。
- 训练策略(两阶段):
- 阶段一:训练一个语义编码器,使其从视觉表情参数 \(\beta_{1:T}\) 中提取的特征 \(v_i\) 与从音频中提取的语义特征 \(a_i\)(由预训练的“运动专家”模型提供)对齐。使用记忆库和基于全局结构损失的监督。
- 阶段二:冻结语义编码器,训练SDSE以提取与语义解耦的风格嵌入 \(s\)。损失函数包括解耦损失(正交化+HSIC)和三元组损失。
- 运动合成(扩散模型):
- 条件输入:音频特征 \(c_a\)(如MFCC)和SDSE提取的风格特征 \(c_s\)。
- 生成模型:一个扩散Transformer(DiT)。训练目标是预测噪声 \(\epsilon\)。
- 分层调制机制:这是核心创新。在去噪过程的每一步 \(t\),将面部划分为上脸 \(r_u\) 和下脸 \(r_l\) 两个区域。
- 对于每个区域,计算音频条件交叉注意力输出 \(Z_a\) 和风格条件交叉注意力输出 \(Z_s\) 与合并特征 \(Z\) 的余弦相似度 \(P_a, P_s\)。
- 计算一个自适应因子 \(D(r,t) = \sigma(P_a - P_s)\),衡量音频相对风格的主导程度。
- 根据区域先验(下脸重音频,上脸重风格),通过公式 (9) 对 \(Z_a\) 和 \(Z_s\) 进行加权调制,生成区域感知的条件特征 \(Z'(r,t)\)。
- 渲染:将生成的运动序列 \(P_{1:T}\) 和目标肖像图像输入神经渲染器,输出最终视频帧。
💡 核心创新点
- 语义解耦风格编码器:通过两阶段训练,显式地将说话风格(如发音习惯、表情动态)从与语音内容相关的语义信息中分离出来。这解决了以往方法中风格表示被参考视频语音内容污染的问题,使得风格可迁移到任意新语音。
- 空间-时间分层调制策略:认识到面部不同区域(上脸表情 vs. 下脸唇动)受音频和风格的影响程度不同,且这种影响在扩散过程的不同去噪阶段动态变化。该策略通过自适应因子 \(D(r,t)\),在空间和时间维度上精细地平衡双条件信息,同时保证唇形精度和表情真实性。
- 基于3DMM参数的解耦表示学习:直接在3DMM表情参数 \(\beta_t\) 上进行建模和解耦,提供了一种中间表示,比直接操作像素更结构化,有利于运动建模。
🔬 细节详述
- 训练数据:使用了VoxCeleb2(约6112个说话人,100万+语句)、HDTF(16小时高清视频)和CREMA-D(91个说话人,情感数据)的混合数据集。预处理为25fps,裁剪至512×512。
- 损失函数:
- 语义编码器损失:全局结构损失 \(L_{global}\) (公式3),最小化视觉-语义空间与音频-语义空间中样本对余弦相似度的差异。
- SDSE损失:\(L_{total} = L_{decouple} + L_{triple}\)。其中 \(L_{decouple}\) (公式4) 包含正交化约束和HSIC正则化项,确保风格与语义独立;\(L_{triple}\) (公式5) 为三元组损失,增强风格表示的判别性。
- 扩散模型损失:标准去噪分数匹配损失 \(L_{denoising}\) (公式6)。
- 训练策略:论文未明确说明优化器、学习率、warmup、batch size、训练步数等具体细节。
- 关键超参数:SDSE的损失权重 \(\lambda_{orth}, \lambda_{hsic}\) 未说明。三元组损失的间隔 \(\delta\) 未说明。
- 训练硬件:论文中未提及。
- 推理细节:采用基于DiT的扩散模型,具体采样步数和策略(如DDPM, DDIM)未详细说明。最终由神经渲染器(引用的PIRenderer)生成图像。
- 其他技巧:对3DMM参数使用了Savitzky–Golay平滑滤波器以提高运动平滑性。
📊 实验结果
主要对比实验在CREMA-D和HDTF两个数据集上进行,指标包括视觉质量(SSIM↑, FID↓)、唇形同步(M-LMD↓, Syncconf↑)、个性化保持(F-LMD↓, StyleSim↑)。
表1. 与现有方法在CREMA-D和HDTF数据集上的定量比较
| 方法 | CREMA-D | HDTF | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM↑ | FID↓ | M-LMD↓ | F-LMD↓ | Syncconf↑ | StyleSim↑ | SSIM↑ | FID↓ | M-LMD↓ | F-LMD↓ | Syncconf↑ | StyleSim↑ | |
| Wav2Lip | 0.725 | 32.461 | 3.025 | 3.476 | 4.384 | 0.826 | 0.618 | 38.744 | 4.121 | 4.040 | 3.762 | 0.841 |
| SadTalker | 0.762 | 15.135 | 4.143 | 2.804 | 2.676 | 0.851 | 0.664 | 20.514 | 3.559 | 2.926 | 2.232 | 0.862 |
| Echomimic | 0.912 | 28.506 | 4.006 | 2.612 | 3.461 | 0.852 | 0.879 | 31.243 | 3.681 | 2.851 | 2.689 | 0.866 |
| V-Express | 0.708 | 18.074 | 4.906 | 4.868 | 2.130 | 0.834 | 0.651 | 24.061 | 5.706 | 5.001 | 1.593 | 0.845 |
| Ours | 0.917 | 16.293 | 2.771 | 1.824 | 4.106 | 0.937 | 0.890 | 21.682 | 2.481 | 2.122 | 3.811 | 0.958 |
| Ground Truth | 1.000 | 0.000 | 0.000 | 0.000 | 4.531 | 0.942 | 1.000 | 0.000 | 0.000 | 0.000 | 3.962 | 0.969 |
关键结论:MirrorTalk(Ours)在几乎所有指标上都取得了最佳或次佳结果。特别是在个性化保持(StyleSim和F-LMD)和唇形同步(M-LMD)上优势明显,验证了其解耦编码和分层调制策略的有效性。
表2. 消融研究
| 消融设置 | M-LMD↓ | F-LMD↓ | Syncconf↑ | StyleSim↑ |
|---|---|---|---|---|
| w/o Memory Bank | 3.074 | 2.426 | 3.473 | 0.869 |
| w/o Dis-Module | 3.687 | 2.581 | 2.805 | 0.837 |
| w/o Ltriple | 2.933 | 2.734 | 3.724 | 0.901 |
| w/o H-Scales | 3.281 | 2.401 | 3.059 | 0.911 |
| Ours(Full Model) | 2.503 | 2.265 | 3.843 | 0.938 |
关键结论:移除任何核心模块都会导致性能下降。其中,移除解耦模块(Dis-Module)导致所有指标全面严重下降,证明了显式解耦的必要性。移除分层调制(H-Scales)主要影响唇形同步精度。移除三元组损失主要影响风格判别性(StyleSim)。
 图2展示了定性比较。可以看出,与AniTalker(表情僵硬)、SadTalker和Echomimic(上脸区域不够自然)以及V-Express(风格保持不足)相比,MirrorTalk生成的动画在唇形准确性和表情自然度上达到了更好的平衡,更好地保留了说话人的风格。
图2展示了定性比较。可以看出,与AniTalker(表情僵硬)、SadTalker和Echomimic(上脸区域不够自然)以及V-Express(风格保持不足)相比,MirrorTalk生成的动画在唇形准确性和表情自然度上达到了更好的平衡,更好地保留了说话人的风格。
⚖️ 评分理由
- 学术质量:5.5/7:论文动机明确,提出了针对性的解决方案(解耦+分层调制),方法设计有新意。实验对比了多个有代表性的基线,指标选择合理,结果具有说服力。扣分点在于部分训练细节缺失,以及风格编码器在超长视频或多人场景下的泛化能力未探讨。
- 选题价值:1.5/2:个性化数字人生成是当前内容生成领域的热点方向,具有明确的虚拟偶像、视频会议、数字分身等应用价值,对相关从业者有参考意义。
- 开源与复现加成:0/1:论文未提供代码、模型权重、详细训练配置等关键复现材料,因此该项加成为0。