📄 Mind Your [m]S, Cross Your [t]S: a Large-Scale Phonetic Analysis of Speech Reproduction in Modern Speech Generators
#语音伪造检测 #音位分析 #语音合成 #模型比较
✅ 7.0/10 | 前25% | #语音伪造检测 | #音位分析 | #语音合成 #模型比较
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Boo Fullwood(佐治亚理工学院 ECE & School of Cybersecurity and Privacy)
- 通讯作者:未说明
- 作者列表:Boo Fullwood(佐治亚理工学院 ECE & School of Cybersecurity and Privacy)、Fabian Monrose(佐治亚理工学院 ECE & School of Cybersecurity and Privacy)
💡 毒舌点评
本文如同一份详尽的“现代语音合成器体检报告”,首次对如此多种类的生成器进行了大规模“病理学”扫描,发现了鼻音和阻塞音这个普遍存在的“病灶”,并精准定位问题主要出在“文本到频谱”的环节,为后续“治疗”(改进生成器或设计更精准的检测器)提供了清晰的诊断书。其短板在于只开出了“诊断书”,却没有附上“药方”或“手术指南”——即基于这些发现提出具体的、新的检测算法或生成器改进方案,且复现门槛较高。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的LJSpeech和VCTK语料库,但论文未提供其生成的合成语音数据集。
- Demo:未提及。
- 复现材料:未提供训练细节、配置、检查点或详细附录说明。分析方法描述足够,但执行所需资源和具体操作细节缺失。
- 论文中引用的开源项目:明确引用了Montreal Forced Aligner (MFA) 作为强制对齐工具。此外,评估的生成器(如HiFi-GAN, VITS, YourTTS等)大多是公开的开源项目,但论文未列出具体依赖链接。
- 论文中未提及开源计划。
📌 核心摘要
- 要解决的问题:现代高质量语音生成器的具体失效模式(即无法准确再现哪些语音特征)尚不清楚,这限制了基于语音内在特征的深伪检测器的优化。
- 方法核心:对23种现代语音生成器配置(涵盖纯声码器、文本到语音、端到端系统、语音克隆模型)在单说话人(LJSpeech)和多说话人(VCTK,110位说话人)数据集上生成的语音进行大规模音位分析。通过强制对齐提取音位,计算多种声学特征(如基频、频谱质心、过零率等)的分布,并与真实语音分布进行统计比较(KS检验,Wasserstein距离)。
- 与已有方法相比新在哪里:这是首个针对现代、多样化架构的大规模音位分析。超越了先前仅研究少量旧模型或特定音位类(如擦音)的工作,系统性地覆盖了多种音位类,并首次发现鼻音是生成器的普遍弱点。同时,将错误模式与生成器架构(TTS阶段 vs. 声码器阶段)和检测器的注意力机制进行了关联分析。
- 主要实验结果:
- 所有测试模型都能准确再现基频(F0)特征。
- 主要错误集中在阻塞音(如[t])和鼻音(如[m]),表现为频谱特征(如过零率、谐波噪声比)的分布偏移。
- 纯声码器(从真实梅尔谱合成波形)的错误极小;而文本到语音(TTS)系统是主要错误来源,其错误主要发生在将文本转换为梅尔谱的阶段。
- 在多说话人设置下,语音克隆(VC)模型的表现显著优于同等的文本到语音模型,例如FreeVC在除频谱倾斜外的所有特征上都接近零错误。
- 现代深伪检测器(AST)的注意力区域与高错误音位类(如擦音、鼻音)大致对齐,但并未充分利用所有错误显著的音位类(如塞擦音的注意力远低于擦音),且在单说话人场景下过度依赖非语音(静音)区域。
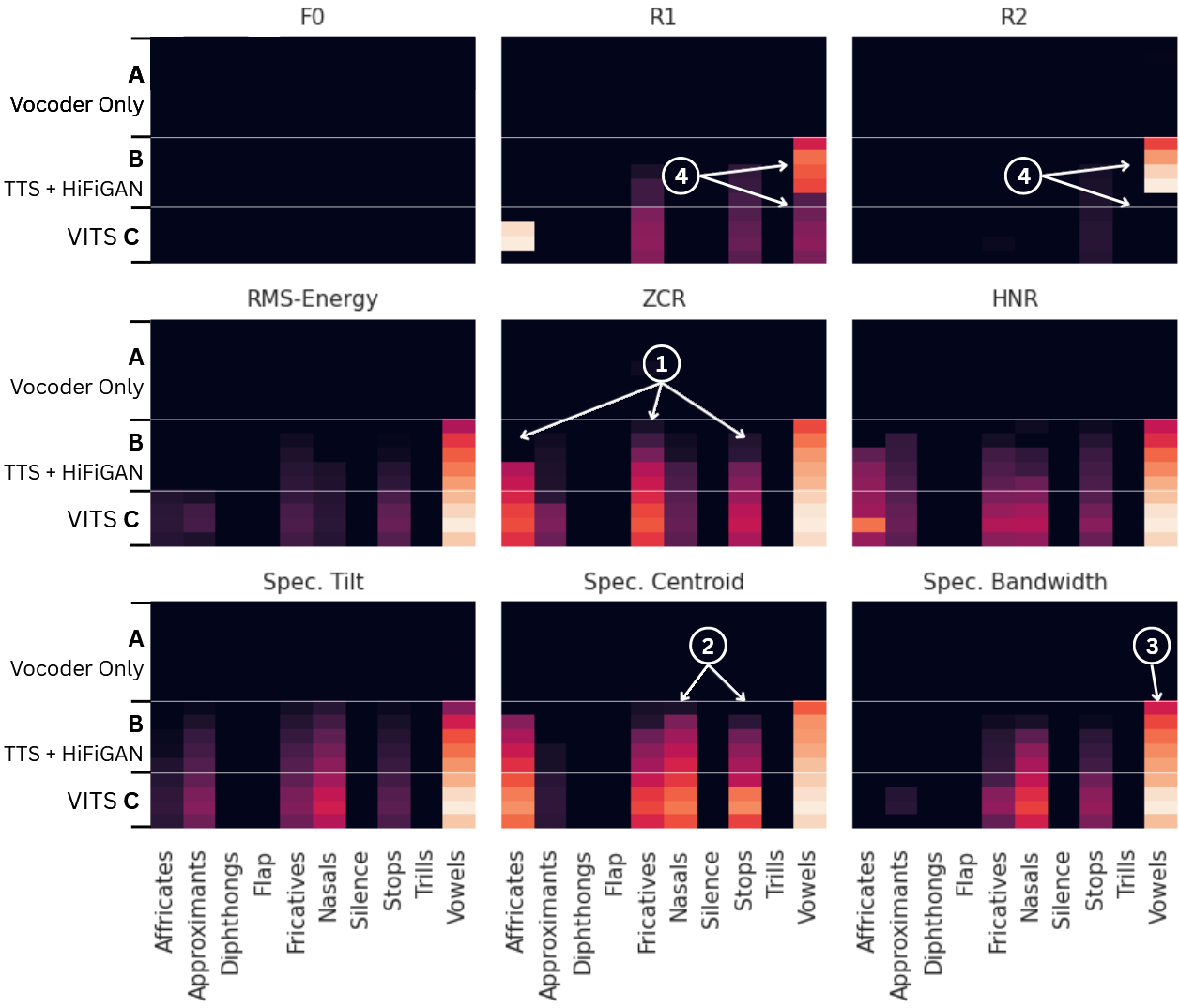 图1:单说话人(a)和多说话人(b)数据集上,各生成器样本与真实语音的特征分布差异(Wasserstein距离)。颜色越亮表示差异越大。可以看到阻塞音、鼻音和部分元音区域差异明显。
图1:单说话人(a)和多说话人(b)数据集上,各生成器样本与真实语音的特征分布差异(Wasserstein距离)。颜色越亮表示差异越大。可以看到阻塞音、鼻音和部分元音区域差异明显。
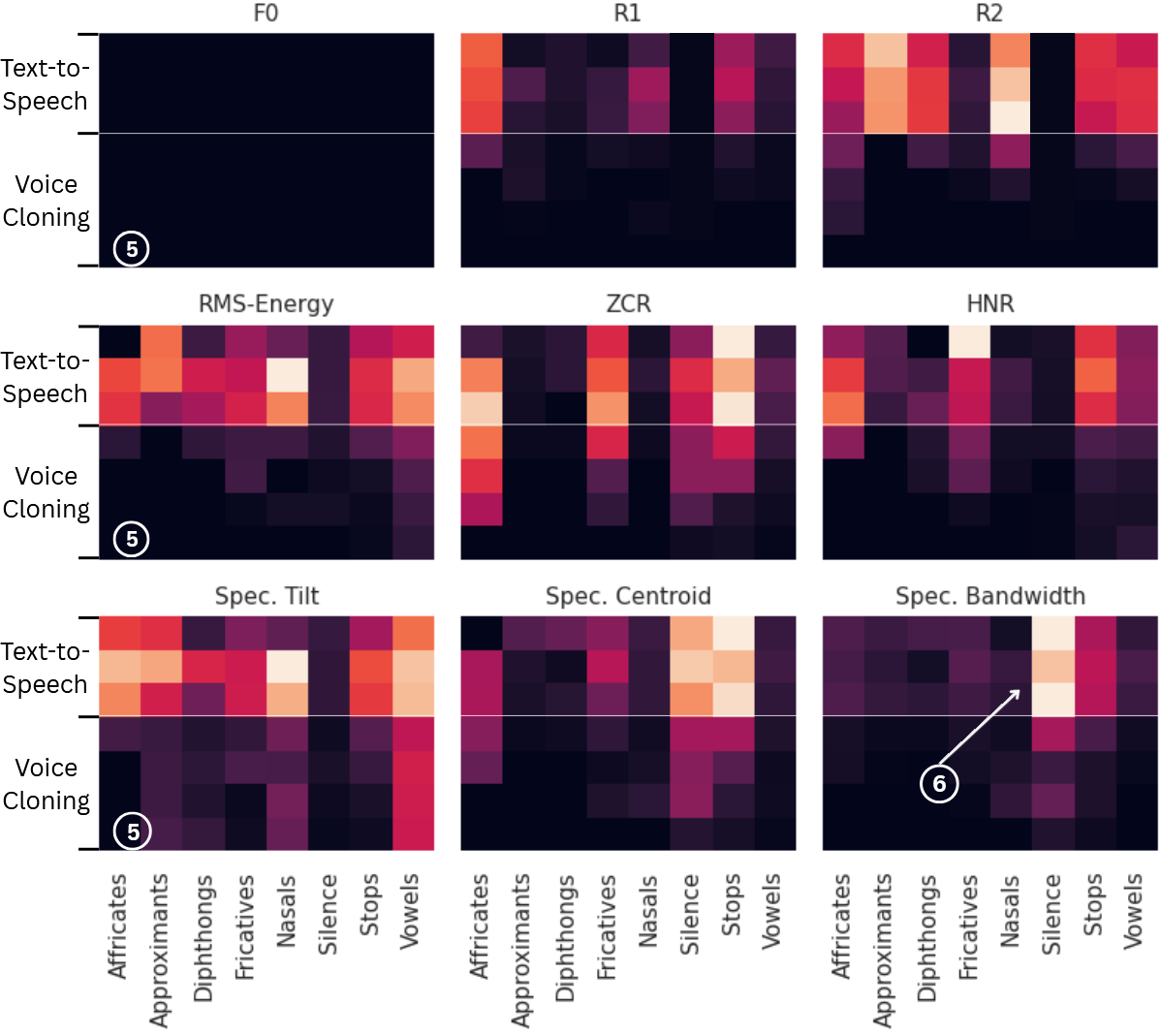 图2:检测器注意力与特征分布距离的对齐情况。检测器对擦音、鼻音、塞音的注意力较高,但对塞擦音的注意力相对其错误率而言不足。在单说话人组,静音区获得了最高注意力,尽管其分布错误很低。
图2:检测器注意力与特征分布距离的对齐情况。检测器对擦音、鼻音、塞音的注意力较高,但对塞擦音的注意力相对其错误率而言不足。在单说话人组,静音区获得了最高注意力,尽管其分布错误很低。
- 实际意义:为语音合成技术改进提供了明确方向(需重点提升阻塞音和鼻音的频谱再现能力),并为深伪检测器指明了优化路径(应更关注特定音位类的语音特征,而非非语音伪影),有助于构建更鲁棒的检测系统。
- 主要局限性:研究聚焦于分析和诊断,未提出新的检测或生成模型。分析依赖于特定特征选择和音位对齐工具。结论基于英文语音,对其他语言适用性未验证。未公开分析代码、生成器细节或合成数据。
🏗️ 模型架构
本文的核心“模型”并非一个单一的神经网络架构,而是一个大规模、系统性的语音生成器评估与分析框架。其流程如下:
生成器矩阵构建:
- 构建了两个实验组:单说话人组(基于LJSpeech)和多说话人组(基于VCTK)。
- 单说话人组细分为三个子群,以隔离不同架构组件的影响:
- A子群(纯声码器):包含7种声码器(如HiFi-GAN, MelGAN),直接接收来自真实语音的梅尔谱进行波形合成,作为基线。
- B子群(TTS系统):包含6种TTS模型(如Tacotron2, VITS),生成梅尔谱后,统一使用A子群中选定的HiFi-GAN作为声码器进行合成。
- C子群(训练评估):固定使用VITS模型和HiFi-GAN声码器,仅改变训练语料(LJSpeech, Blizzard, SAM, VCTK),以区分架构效应与训练效应。
- 多说话人组:包含3个多说话人端到端TTS模型(如YourTTS, XTTS)和3个语音克隆模型(如OpenVoice, FreeVC),均使用VCTK数据集。
- 共评估23种配置,每个配置生成约1000个样本。
音位分析流水线:
- 输入:真实语音或合成语音的音频波形及其转录文本。
- 对齐:使用Montreal强制对齐器(MFA)将音频与文本进行强制对齐,输出每个音位的精确起止时间戳。
- 特征提取:对对齐后的每个音位片段,计算表1中列出的多种声学特征(RMS能量、F0、R1/R2、过零率、频谱质心、带宽、倾斜度、谐波噪声比)。
- 分布构建:将每个音位特征的所有计算值聚集,分别为真实语音和每个生成器构建该音位-特征对的经验概率分布。
- 统计比较:
- 对两两分布(真实 vs. 生成器A中的某音位-特征)进行两样本Kolmogorov-Smirnov检验(带Bonferroni校正,α=0.01),判断是否存在显著分布偏移。
- 对显著偏移的分布,计算Wasserstein距离量化偏移程度;不显著则记为0。
- 输出:生成一张热力图(如图1),展示每个生成器-音位-特征组合的Wasserstein距离,直观显示错误模式。
检测器分析:
- 在上述两个数据集上分别训练一个音频频谱图转换器(AST) 模型进行深伪检测。
- 使用多尺度遮挡(Multiscale Occlusion) 技术分析检测器的注意力:系统性地遮挡频谱图的不同时间区域,观察检测器置信度的下降,从而定位对分类重要的区域,并将这些区域映射回底层音位,计算每个音位类的平均重要性(注意力)得分(如图2)。
架构图:论文未提供单一的模型架构图,但图1和图2是本分析框架的关键输出可视化。
💡 核心创新点
- 首次大规模、多样化的现代生成器音位分析:突破了以往研究仅针对少量旧模型或单一音位类的限制,覆盖了23种当代前沿架构(包括声码器、TTS、语音克隆),系统性地揭示了现代技术的普遍弱点和差异。
- 发现新的关键错误模式:确认了阻塞音(如塞音)仍然是难题,但首次大规模证实鼻音(如[m])是生成器的另一普遍弱点,这一模式在先前工作中未被发现或强调,丰富了对生成器失效模式的理解。
- 精确定位错误来源:通过子群消融实验(如A、B、C子群对比),清晰地证明大多数语音再现错误源于文本到梅尔谱的转换阶段(TTS阶段),而非最终的声码器波形生成阶段。同时发现声码器重训练对错误模式影响不大。
- 揭示架构类型对准确性的显著影响:在多说话人设置下,证明了语音克隆(VC)模型在音位再现准确性上显著优���同等条件下的文本到语音(TTS)模型,这为选择生成架构提供了重要依据。
- 链接生成错误与检测器注意力:创新性地将生成器的音位级错误模式与基于AST的检测器注意力进行关联分析,发现检测器并未充分利用所有错误显著的音位类(如塞擦音),且可能过度依赖非语音区域,指明了检测器优化的具体方向。
🔬 细节详述
- 训练数据:
- 真实语料:单说话人组使用LJSpeech语料库(单一女性说话人)。多说话人组使用VCTK语料库(110位英语说话人)。
- 合成数据:每个生成器配置生成约1000个样本。具体生成数量未说明是否所有配置完全一致。多说话人组中,语音克隆模型使用随机选定的VCTK说话人p311的音频作为参考。
- 损失函数:未说明。本文是分析工作,不涉及训练新模型。
- 训练策略:未说明。论文评估的是已公开的、训练好的模型。
- 关键超参数:未说明。论文未提供所评估生成器的具体训练超参数。
- 训练硬件:未说明。
- 推理细节:未说明。论文未提供生成样本时的采样参数(如温度、top-k等)。
- 正则化或稳定训练技巧:未说明。
- 分析工具:明确使用了Montreal强制对齐器(MFA) 进行音位对齐。特征提取基于标准音频处理方法(如librosa库,论文未明确提及但通常如此)。统计检验使用KS检验和Wasserstein距离。
📊 实验结果
主要发现基于图1和图2的视觉分析及文中描述,论文未提供具体的数值结果表格。
单说话人组(图1a):
- 纯声码器(A子群):所有7种声码器(MelGAN系列, WaveGlow, Parallel WaveGAN, HiFi-GAN)的错误都非常小且低,Wasserstein距离整体很低。
- TTS系统(B、C子群):错误显著放大,且模式相似。阻塞音(如塞音、擦音)和鼻音在多个特征上(特别是过零率、频谱质心、谐波噪声比)显示强烈的分布偏移(亮色)。部分元音也显示较高误差。
- 架构 vs 训练:固定VITS-HiFi-GAN架构,仅改变训练语料(C子群),错误模式高度一致,说明错误主要源于架构而非训练。但端到端训练的VITS在共振峰(R1, R2)分散度误差上明显小于其他B子群架构。
多说话人组(图1b):
- 语音克隆(VC)模型:整体表现优异。特别是FreeVC在几乎所有特征和音位类上都接近零错误(深色),仅在频谱倾斜上与其他VC模型持平。OpenVoice V2也表现良好。
- 端到端TTS模型(YourTTS, XTTS):错误分布更广泛,在阻塞音、鼻音以及非语音(静音)区域均显示较高误差(亮色���。静音区误差在单说话人组中不明显。
检测器注意力(图2):
- 注意力与音位错误大致对齐:擦音、鼻音、塞音获得最高注意力。
- 不一致处:塞擦音的注意力(擦音的42%)远低于其相似的错误率;单说话人组中,静音区获得最高注意力(比擦音高23%),尽管其分布错误极低;在单说话人组,元音错误显著但获得的注意力最小。
⚖️ 评分理由
- 学术质量:6.0/7。论文在研究方法上严谨全面,实验规模空前,分析层次清晰(从生成器组件到检测器注意力),结论有充分的实验数据支持(通过可视化呈现)。其主要贡献是系统性地揭示现象和模式,而非提出解决这些现象的新算法,因此在“创新性”上略有局限。技术正确性高,证据可信。
- 选题价值:1.5/2。选题切中语音合成和深伪检测领域的核心痛点——理解生成模型的缺陷。研究结果对社区具有直接的指导意义,可以帮助优化生成模型和检测模型,应用空间明确。属于前沿领域的基础性实证研究。
- 开源与复现加成:-0.5/1。论文详细描述了分析流程和评估指标,但未开源任何代码、模型、数据集或具体的生成配置。读者若想完全复现其大规模分析,需要自行寻找、配置并运行所有23种生成模型,准备相应数据集,实现特征提取和统计分析流程,复现成本极高。