📄 Mind the Shift: Using Delta SSL Embeddings to Enhance Child ASR
#语音识别 #自监督学习 #低资源 #特征融合
✅ 7.0/10 | 前25% | #语音识别 | #自监督学习 | #低资源 #特征融合
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zilai Wang(University of California, Los Angeles, Department of Electrical and Computer Engineering)
- 通讯作者:未说明
- 作者列表:Zilai Wang(UCLA电气与计算机工程系),Natarajan Balaji Shankar(UCLA电气与计算机工程系),Kaiyuan Zhang(UCLA电气与计算机工程系),Zihan Wang(UCLA电气与计算机工程系),Abeer Alwan(UCLA电气与计算机工程系)
💡 毒舌点评
亮点:论文巧妙地将“任务向量”从模型参数空间平移到表示空间,定义了易于计算的“Delta嵌入”,并证实其在低资源场景下能有效补充不同SSL模型的特征,思路新颖且有效。短板:所有实验仅在一个儿童语音数据集上验证,虽然取得了SOTA,但方法的通用性(如对成人语音、其他低资源任务)未得到充分探讨,结论的推广性存疑。
🔗 开源详情
- 代码:论文提供了GitHub仓库链接:https://github.com/Zilai-WANG/Delta-Embedding-Fusion。
- 模型权重:未提及公开的微调或Delta嵌入模型权重。
- 数据集:MyST语料库为第三方数据集,需另行申请获取。
- Demo:未提及。
- 复现材料:论文给出了主要的融合方法(拼接、加权、交叉注意力)的数学定义、MoE门控公式、CCA使用方法以及实验评估协议(MyST数据集划分、筛选标准),但未提供具体的超参数设置(如学习率、批大小)。
- 论文中引用的开源项目:使用了Hugging Face上的预训练模型(Wav2Vec2-Large, HuBERT-Large, WavLM-Large),以及可能依赖的PyTorch、Transformers库等(未在文中明确列出)。
📌 核心摘要
本文针对儿童自动语音识别(ASR)因数据稀缺和领域失配导致的性能瓶颈,提出了一种新颖的特征融合方法。核心思想是:不同自监督学习(SSL)模型在微调后,其表示空间相对于预训练版本会产生偏移,这种偏移本身(即“Delta嵌入”)编码了宝贵的、特定于下游任务的信息。方法将微调后一个SSL模型(如WavLM)的嵌入,与另一个SSL模型(如Wav2Vec2.0)的Delta嵌入进行融合。实验在MyST儿童语料库上进行,覆盖了从1小时到133小时的不同训练数据规模。结果表明,采用简单的拼接融合策略效果最佳;在极具挑战性的1小时数据设置下,融合Delta HuBERT嵌入相比融合微调嵌入实现了10%的相对词错��(WER)降低,融合Delta W2V2实现了4.4%的降低。最优组合(WavLM + Delta W2V2)在完整数据集上达到了9.64%的WER,创下了SSL模型在MyST语料库上的新SOTA。该工作的意义在于为低资源语音识别提供了一种简单有效的多模型融合新范式。主要局限性是验证范围单一,缺乏在其他数据集上的泛化实验。
🏗️ 模型架构
本文并非提出一个新的端到端ASR模型架构,而是提出了一种特征融合框架,用于增强现有SSL模型在儿童ASR任务上的表示。其核心流程如下:
输入与特征提取:输入16kHz语音波形。使用三个预训练SSL编码器(Wav2Vec2.0, HuBERT, WavLM)提取表示。这些模型共享相似的宏观架构:一个卷积特征编码器(将波形转换为帧级潜在表示,步长20ms,感受野约25ms)和一个24层的Transformer编码器(隐藏维度1024)。
微调与Delta嵌入生成:
- 在ASR数据集(如MyST)上,为每个预训练SSL模型顶部添加一个字符级CTC损失层,并进行微调。
- 对于选定的“参考模型”(论文中为WavLM),使用其微调后最后一层Transformer的输出作为
E_ft。 - 对于“辅助模型”(HuBERT或Wav2Vec2.0),计算其Delta嵌入
∆E = E_ft - E_pt,即微调后最后一层的输出减去预训练版本相同层的输出。这代表了微调引入的任务特定表示偏移。
特征融合:将参考模型的微调嵌入
E_ft与辅助模型的Delta嵌入∆E进行融合。论文评估了三种融合策略:- 拼接(Concat):沿特征维度拼接,
Z = [E_ft; ∆E]。这是效果最好的策略。 - 加权组合(Weighted):凸组合,
Z = λE_ft + (1-λ)∆E。 - 交叉注意力(X-Attn):以
E_ft为查询,∆E为键值进行多头注意力,然后与E_ft残差连接并归一化。
- 拼接(Concat):沿特征维度拼接,
解码:移除融合模型顶部的原始CTC层,训练一个新的线性CTC头用于字符预测。
论文中未提供架构图。
💡 核心创新点
- 将“任务向量”概念扩展到表示空间:借鉴了模型合并中参数差异(task vector)编码任务知识的观点,首次提出将其应用于表示层面,定义“Delta嵌入”作为融合单元。这为理解模型微调和利用多模型互补性提供了新视角。
- 提出针对异构SSL模型的Delta嵌入融合策略:不同于以往融合多个预训练模型或微调模型,本文专注于融合一个模型的微调表示与另一个模型的表示偏移(Delta)。这在理论上更能凸显和利用任务特定信息。
- 系统评估并验证Delta嵌合在低资源儿童ASR中的有效性:通过在MyST数据集不同数据量下的详尽实验,证明了Delta嵌入融合(尤其是拼接策略)在极低资源(1h)场景下相比基线方法有显著提升,并达到了新的SOTA水平。
🔬 细节详述
- 训练数据:MyST儿童语料库,约240小时转录对话语音(3-5年级儿童)。经筛选后使用133小时训练,21小时开发,25小时测试。另构建了1小时、5小时、10小时的低资源子集。
- 损失函数:字符级CTC损失,用于最终的ASR训练。
- 训练策略:论文未详细说明微调及融合模型训练的具体超参数(如学习率、优化器、batch size、训练轮数等)。仅提及遵循了参考文献[2]的协议。
- 关键超参数:所用SSL模型为Large级别(Wav2Vec2-Large, HuBERT-Large, WavLM-Large),具有24层Transformer和1024隐藏维度。融合在模型最后一层进行。
- 训练硬件:未说明。
- 推理细节:未提及解码策略(如beam search)的具体细节。
- 正则化或稳定训练技巧:未说明。在交叉注意力融合策略中,提到了在低资源情况下可能过拟合。
📊 实验结果
主要Benchmark:MyST儿童语音语料库,评估指标为词错率(WER,%)。
表1:不同融合方法与数据量的WER对比(WavLM作为参考模型)
| 参考模型 | Delta嵌入来源 | 融合方法 | WER (Full) | WER (10h) | WER (5h) | WER (1h) |
|---|---|---|---|---|---|---|
| WavLM | ∆HuBERT | 加权 | 9.79 | 11.70 | 13.65 | 23.86 |
| 交叉注意力 | 10.28 | 12.64 | 14.32 | 23.11 | ||
| 拼接 | 9.71 | 11.57 | 12.96 | 22.74 | ||
| WavLM | ∆W2V2 | 加权 | 9.75 | 11.73 | 14.77 | 23.42 |
| 交叉注意力 | 9.80 | 12.96 | 14.53 | 25.97 | ||
| 拼接 | 9.64 | 11.61 | 12.88 | 21.81 |
结论:拼接融合在所有数据量下一致最优。WavLM+∆W2V2在1小时设置下优势明显。
表2:Delta嵌入融合(拼接)与单模型微调的WER对比
| 模型 | Full | 10h | 5h | 1h |
|---|---|---|---|---|
| WavLM | 10.16 | 11.95 | 13.27 | 22.47 |
| HuBERT | 11.04 | 12.95 | 14.67 | 25.30 |
| W2V2 | 10.96 | 13.47 | 15.65 | 25.97 |
| WavLM + ∆HuBERT | 9.71 | 11.57 | 12.96* | 22.74 |
| WavLM + ∆W2V2 | 9.64 | 11.61 | 12.88 | 21.81 |
结论:所有融合配置(尤其是带∆W2V2)在统计上显著优于最强基线WavLM(p<0.05,标记为*)。WavLM+∆W2V2在1h上达到21.81%的新SOTA。
表3:Delta嵌入融合 vs. 微调嵌入融合的WER对比(拼接)
| 数据 | HuBERT | ∆HuBERT | W2V2 | ∆W2V2 |
|---|---|---|---|---|
| Full | 10.35 | 9.71* | 9.67 | 9.64 |
| 10h | 11.84 | 11.57* | 11.66 | 11.61 |
| 5h | 13.21 | 12.96* | 12.89 | 12.88 |
| 1h | 25.27 | 22.74 | 22.80 | 21.81 |
结论:使用Delta嵌入的融合在所有设置下均优于或持平使用完整微调嵌入的融合。在1h设置下,∆HuBERT相比HuBERT实现10%相对WER降低((25.27-22.74)/25.27),∆W2V2实现4.4%降低((22.80-21.81)/22.80)。
消融与可解释性分析:
- CCA分析(图1、图2):图1显示微调后表示与预训练表示的相似度随层深下降,且W2V2下降更剧烈。图2显示Delta嵌入与微调表示的相似度在顶层下降,其中∆W2V2下降更陡峭,表明其捕获了更强的任务特异性偏移。
- 跨域Delta嵌入分析(表4):在LibriSpeech(成人语音)上微调得到的Delta嵌入,在MyST(儿童语音)上效果虽不如域内Delta,但仍优于纯WavLM基线。
- MoE分析(表5):门控网络为微调嵌入和Delta嵌入分配了显著权重,证实了两者共同价值。WavLM+∆W2V2组合中微调嵌入的权重(0.65)低于WavLM+∆HuBERT(0.72),与更好的WER相关,表明W2V2的互补性更强。
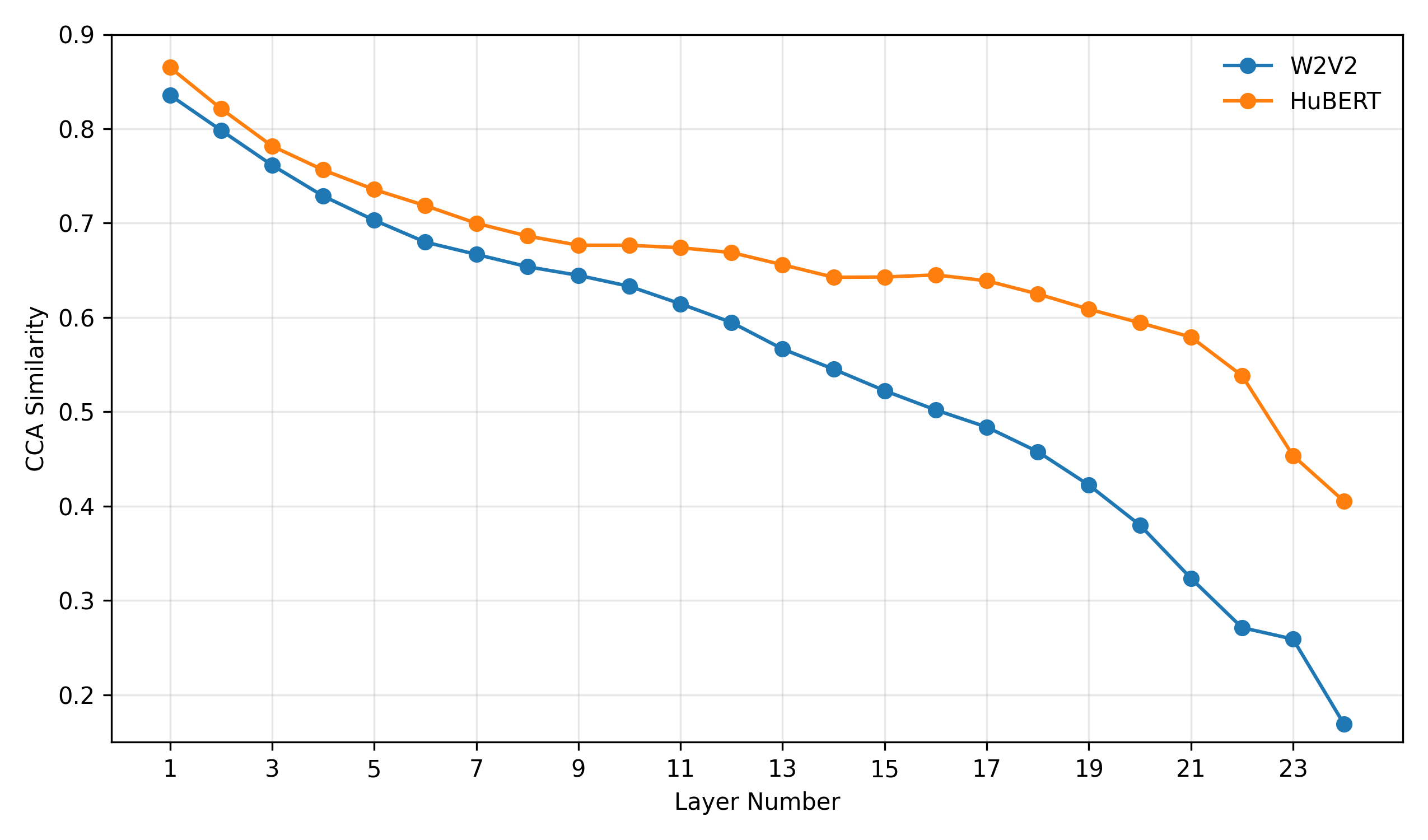 图1说明:对于HuBERT和Wav2Vec2.0,微调后的表示与其预训练版本的相似度(CCA)随着Transformer层加深而降低,证实微调主要影响上层表示。W2V2的下降更陡峭。
图1说明:对于HuBERT和Wav2Vec2.0,微调后的表示与其预训练版本的相似度(CCA)随着Transformer层加深而降低,证实微调主要影响上层表示。W2V2的下降更陡峭。
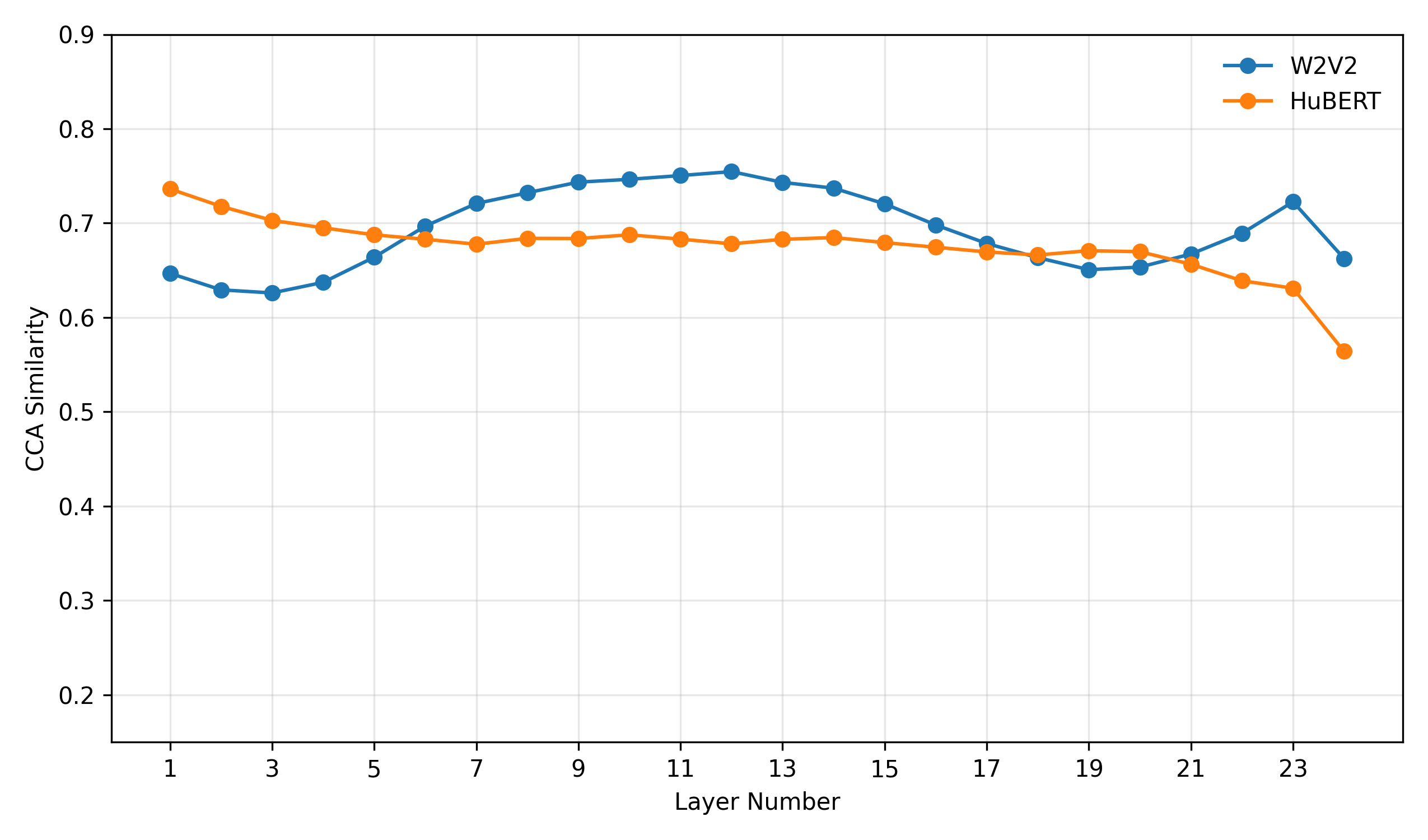 图2说明:Delta嵌入与微调表示的相似度在中间层保持稳定,在最后一层下降,表明Delta嵌入主要捕获了集中在高层的任务特定偏移。∆W2V2的下降更剧烈,对应其更强的互补性。
图2说明:Delta嵌入与微调表示的相似度在中间层保持稳定,在最后一层下降,表明Delta嵌入主要捕获了集中在高层的任务特定偏移。∆W2V2的下降更剧烈,对应其更强的互补性。
⚖️ 评分理由
- 学术质量:5.5/7。创新点明确,将Delta嵌入用于特征融合是一个新颖的视角。实验设计较为系统,包含了方法对比、数据规模消融和可解释性分析,结果可信。扣分点在于验证场景单一,未与强监督基线(如Whisper)对比,且关键训练细节缺失影响了复现的精确性。
- 选题价值:1.0/2。儿童ASR是语音技术中有意义且具挑战性的应用方向,论文针对该场景低资源的特性提出有效方法,对相关领域的研究者有参考价值。但应用场景相对狭窄。
- 开源与复现加成:0.5/1。提供了代码仓库链接,并给出了清晰的算法描述和实验设置,有利于复现。但未提供模型权重和完整的训练配置,降低了完全复现的便利性。