📄 MIDI-LLaMA: An Instruction-Following Multimodal LLM for Symbolic Music Understanding
#音乐理解 #多模态模型 #大语言模型 #指令微调
✅ 7.5/10 | 前10% | #音乐理解 | #多模态模型 | #大语言模型 #指令微调
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Meng Yang(SensiLab, Monash University, Australia)
- 通讯作者:未说明
- 作者列表:Meng Yang(SensiLab, Monash University, Australia)、Jon McCormack(SensiLab, Monash University, Australia)、Maria Teresa Llano(University of Sussex, Brighton, United Kingdom)、Wanchao Su(SensiLab, Monash University, Australia)、Chao Lei(School of Computing and Information Systems, The University of Melbourne, Australia)
💡 毒舌点评
亮点:这篇工作精准地切中了音乐AI领域的一个关键缺口——如何让大语言模型真正“读懂”结构化的MIDI数据,而非将其降级为文本片段,其提出的自动化标注管道也极具实用价值。短板:评估完全依赖于单一的古典钢琴数据集(GiantMIDI-Piano),模型在流行、爵士、电子音乐或复杂多声部管弦乐MIDI上的表现是个未知数,这大大限制了其宣称的“通用”价值。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:论文构建的符号音乐-文本数据集(基于GiantMIDI-Piano)未提及是否公开及获取方式。GiantMIDI-Piano本身是一个公开数据集,但需申请使用。
- Demo:未提供在线演示。
- 复现材料:论文给出了模型架构、两阶段训练流程、主要超参数(学习率、批次大小、LoRA秩等)和训练硬件,但��提供详细的配置文件、代码或检查点。完整的GPT-4o标注提示词也未公开。
- 引用的开源项目:论文中引用了开源项目/工具,包括:MusicBERT (MIDI编码器), Llama-3-8B (语言模型), music21 (特征提取), GPT-4o (用于数据标注)。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:现有的多模态大语言模型在音乐理解上主要针对音频信号,而作为音乐结构基础表征的符号音乐(如MIDI)尚未被作为独立模态有效整合到大模型中。此前,研究者常将MIDI转换为ABC记谱等文本表示,但这会损失节奏、复调等关键细节,限制了理解的深度。
- 方法核心:提出MIDI-LLaMA,一个用于符号音乐理解的指令跟随多模态大模型。其架构冻结了预训练的音乐编码器MusicBERT和语言模型Llama-3-8B,通过一个可训练的投影层将MIDI的嵌入向量映射为“音乐标记”,与文本嵌入拼接后共同输入LLM。训练分为两阶段:特征对齐(仅训练投影层)和指令微调(用LoRA微调LLM)。
- 新在何处:这是首个将符号音乐(MIDI)作为与文本并列的独立模态,与大语言模型进行端到端对齐的工作。同时,为解决训练数据稀缺问题,设计了一个结合GPT-4o元数据挖掘和人工验证的可扩展标注管道,构建了首个专注于古典钢琴的符号音乐-文本数据集。
- 主要实验结果:在音乐字幕生成任务上,MIDI-LLaMA在所有自动评估指标(BLEU, METEOR, ROUGE-L, BERTScore)上均显著优于将MIDI转为ABC记谱的文本基线ABC-LLaMA。例如,在Music Captioning任务中,MIDI-LLaMA的BLEU-4达到0.2566,而ABC-LLaMA为0.1592。人类评估进一步证实,MIDI-LLaMA在音乐理解准确度(63 vs. 25票)、情感识别(60 vs. 26票)和整体偏好(58 vs. 22票)上明显胜出。关键结果表格:
模型 任务 BLEU-4 (↑) METEOR (↑) ROUGE-L (↑) BERTScore (↑) Question Answering LLaMA-3-8B 0.0004 0.0101 0.0113 0.6077 LLaMA-3-70B 0.0032 0.0211 0.0153 0.4408 ABC-LLaMA 0.2352 0.2792 0.5395 0.8529 MIDI-LLaMA 0.2001 0.2344 0.5486 0.9519 Music Captioning LLaMA-3-8B 0.0467 0.1826 0.1412 0.8335 LLaMA-3-70B 0.0519 0.1910 0.1415 0.8409 ABC-LLaMA 0.1592 0.2919 0.2607 0.8536 MIDI-LLaMA 0.2566 0.3797 0.4265 0.9142 - 实际意义:证明了将符号音乐作为独立模态整合到大语言模型中的可行性和优势,为精细化的音乐分析、交互式作曲辅助、音乐教育等应用打开了新思路,也为未来融合符号与音频模态的多模态音乐系统奠定了基础。
- 主要局限性:评估数据集局限于古典钢琴音乐(GiantMIDI-Piano),模型的泛化能力(如对流行音乐、复杂乐队编曲MIDI的处理)尚未可知;方法严重依赖高质量的符号音乐-文本配对数据,而此类数据构建成本较高。
🏗️ 模型架构
 MIDI-LLaMA的架构遵循经典的“编码器-投影-LLM”多模态范式,核心流程如下:
MIDI-LLaMA的架构遵循经典的“编码器-投影-LLM”多模态范式,核心流程如下:
- 输入:一段MIDI文件(符号音乐)和一段自然语言问题/指令。
- MIDI编码:MIDI文件首先被转换为OctupleMIDI事件序列(包含音高、时长、力度、小节等8个维度的信息)。该序列被输入到冻结的MusicBERT编码器中,提取每个“音符事件”的隐藏状态。
- 特征聚合:对MusicBERT输出的隐藏状态进行时间平均池化,得到一个固定维度(M维)的片段级向量,这代表了整段音乐的语义特征。
- 跨模态投影:一个可训练的投影层(线性层) 将M维的音乐嵌入映射为LLM隐藏空间维度T。这一步骤生成的向量被视作“音乐标记(musical tokens)”。
- 嵌入拼接与LLM生成:将“音乐标记”与问题文本的“文本标记”在序列维度上拼接,共同作为前缀输入到冻结的Llama-3-8B语言模型中。LLM基于这些混合信息,自回归地生成答案文本。 关键设计选择与动机:
- 冻结编码器和LLM,仅训练投影层/适配器:这是一种高效且稳定的多模态对齐策略(源自LLaVA),能在较少计算资源下,将预训练好的强大单模态模型快速适配到新的多模态任务上。
- 选择MusicBERT:作为专为符号音乐预训练的模型,其表征已蕴含了节奏、和声、曲式等丰富音乐结构信息,是理想的符号音乐编码器。
- 时间平均池化:将变长的事件序列转化为固定长度的向量,便于与文本嵌入对齐,虽然可能损失部分时序细节,但简化了模型并满足了对整体语义理解的需求。
💡 核心创新点
- 首个符号音乐-文本指令跟随多模态模型:开创性地将MIDI作为独立的、非文本的模态,与大语言模型进行端到端对齐。这超越了以往将MIDI转为文本(如ABC记谱)或仅关注音频音乐的范式,能够更完整地捕捉符号音乐的结构化信息。
- 可扩展的符号音乐-文本数据构建管道:针对符号音乐-文本配对数据稀缺的痛点,设计了“网络信息检索 -> GPT-4o元数据提取 -> 人工验证”的自动化标注流程。该流程不仅提高了效率,其产出的细粒度标签(风格、情感、创作背景等)也支持了更深入的音乐理解任务。
- 通过对比实验证明符号嵌入的优越性:在没有现成基线的情况下,严谨地构建了ABC-LLaMA作为文本基线(控制变量为MIDI的表示形式)。定量和定性评估一致证明,使用MusicBERT的符号嵌入比使用文本化的ABC记谱能显著提升模型的音乐理解、情感识别和生成质量。
🔬 细节详述
- 训练数据:
- 数据集:基于GiantMIDI-Piano数据集(10,855个古典钢琴MIDI文件),通过标注管道筛选出9,803个有效标注的曲目。
- 预处理:使用music21工具提取每个MIDI文件的基础特征(速度、调号、拍号),并将其融入标注标签中。
- 数据增强:为每个较长的曲目,从不同位置(如开头、中间、结尾)切分三个非重叠的20秒片段,共生成29,409个片段。
- 指令数据生成:利用GPT-4o为每个标注标签(如流派、情感)生成相应的问答对,最终构建了约230万条问答对,用于指令微调。
- 损失函数:论文中未明确提及,但根据指令微调的通用做法,以及“next-token cross-entropy”的描述,可推断为标准的下一token预测交叉熵损失。
- 训练策略:
- 两阶段训练:
- 对齐阶段:冻结MusicBERT和Llama-3-8B,仅用指令数据训练投影层。
- 指令微调阶段:冻结MusicBERT,使用LoRA(秩=8)微调Llama-3-8B,并继续更新投影层。
- 优化器与调度:使用AdamW优化器。最大学习率5e-4,线性预热比例0.03,随后进行余弦衰减。批次大小为16。
- 两阶段训练:
- 训练硬件:两张NVIDIA A6000 GPU。
- 推理细节:论文未具体说明解码策略(如beam search或采样)、温度等参数。
- 关键超参数:LLM为Llama-3-8B;MIDI编码器为MusicBERT;投影层为线性层;LoRA秩为8。
📊 实验结果
主要Benchmark与结果: 论文评估了两个任务:问答和音乐字幕生成。基线包括原始LLaMA-3-8B/70B(零样本)和ABC-LLaMA。评估指标为BLEU-4, METEOR, ROUGE-L, BERTScore。具体数值见上文核心摘要中的表格。 与最强基线对比:
- 问答任务:MIDI-LLaMA在语义对齐性更强的指标(ROUGE-L: 0.5486 vs. 0.5395, BERTScore: 0.9519 vs. 0.8529)上超越了ABC-LLaMA,但在表面词汇匹配指标(BLEU, METEOR)上略低,说明其生成答案更注重语义而非精确短语匹配。
- 音乐字幕生成任务:MIDI-LLaMA在所有四个指标上均大幅领先ABC-LLaMA,尤其BLEU-4(0.2566 vs. 0.1592)和ROUGE-L(0.4265 vs. 0.2607),显示出其生成的描述在内容覆盖和词汇匹配上都更优秀。
消融实验:论文未进行传统意义上的消融(如去掉某个模块),但通过对比ABC-LLaMA和MIDI-LLaMA,实质上对“符号音乐的表示形式”这一关键变量进行了消融,证明了使用原始MIDI嵌入的优越性。
人类评估:对100个片段进行盲测比较,结果如下图所示。MIDI-LLaMA在“音乐理解准确性”、“音乐情感理解”和“创造力”维度获得明显优势,而“文本流畅度”两者接近。
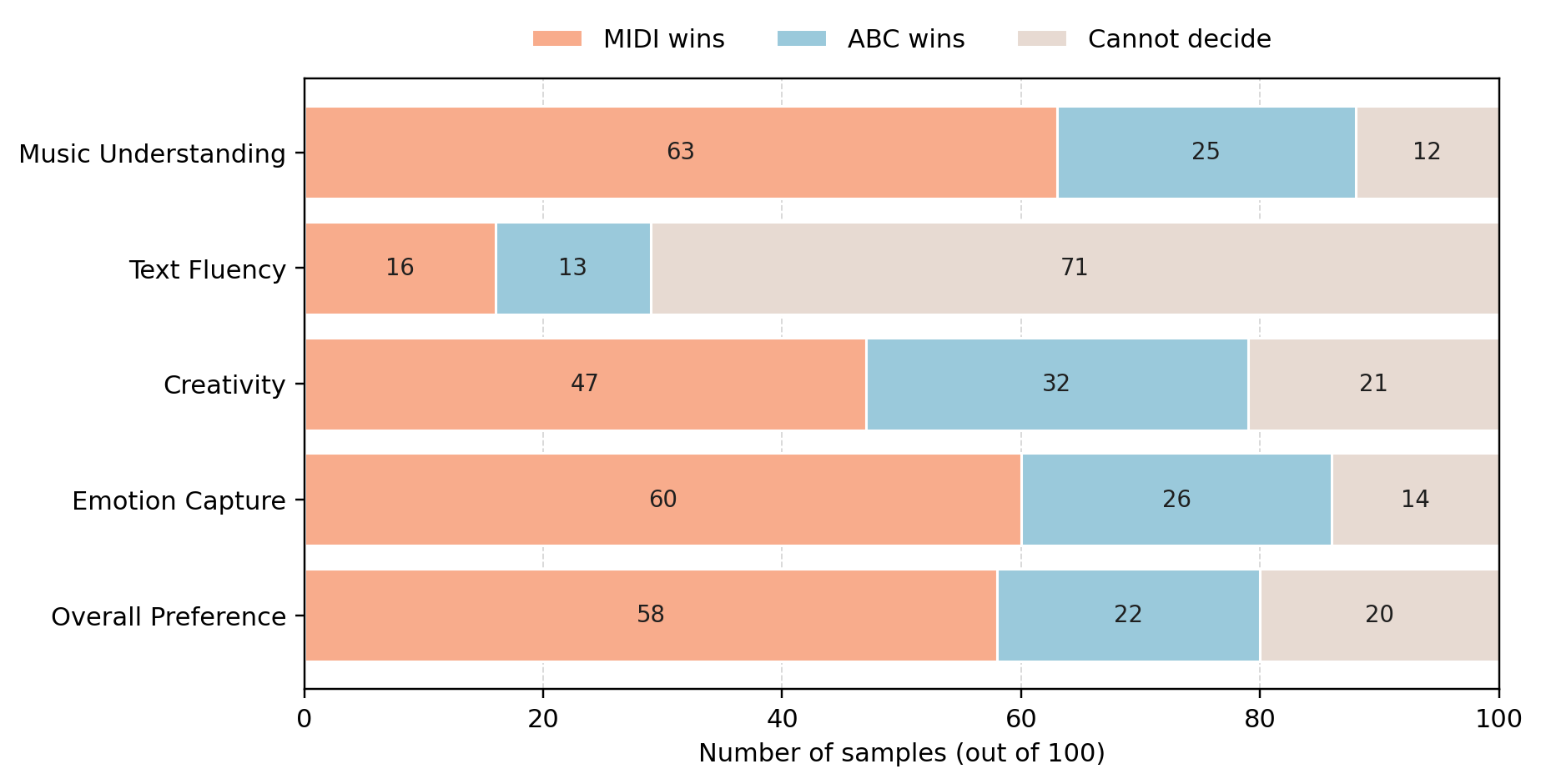 图2结论:人类评估表明,MIDI-LLaMA生成的音乐字幕在反映音乐内容、捕捉情感和创意方面更受青睐。
图2结论:人类评估表明,MIDI-LLaMA生成的音乐字幕在反映音乐内容、捕捉情感和创意方面更受青睐。
⚖️ 评分理由
- 学术质量:6.0/7:论文在创新性上表现突出,首次开辟了符号音乐多模态大模型这一方向。技术实现上正确采用了经过验证的多模态对齐范式(LLaVA)和组件(MusicBERT, LoRA)。实验设计相当充分,构建了公平的基线(ABC-LLaMA),并进行了自动指标和人类评估。主要扣分点在于其核心方法是现有范式的成功适配而非底层创新,且实验范围受限于单一数据集。
- 选题价值:1.5/2:前沿性高,填补了多模态大模型在音乐领域的重要空白(符号表示)。潜在影响大,有望推动音乐信息检索、创作辅助、音乐教育等领域的进步。应用空间集中在以符号音乐为核心的垂直场景,与广泛的音频/语音处理相关性中等。
- 开源与复现加成:0.0/1:论文未提供代码仓库、模型权重或完整的训练配置。虽然提供了模型架构和训练流程的描述,但关键数据处理(标注管道的完整提示)、模型细节未完全公开,且依赖的数据集需额外申请,因此复现门槛较高,无法给予加分。