📄 MI-Fuse: Label Fusion for Unsupervised Domain Adaptation with Closed-Source Large Audio-Language Model
#语音情感识别 #领域适应 #知识蒸馏 #语音大模型 #零样本
🔥 8.0/10 | 前25% | #语音情感识别 | #领域适应 | #知识蒸馏 #语音大模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Hsiao-Ying Huang* (National Taiwan University, Taiwan)
- 第一作者:Yi-Cheng Lin (National Taiwan University, Taiwan) (注:论文标注Equal Contribution,故有两位共同第一作者)
- 通讯作者:未说明(论文中未明确标注通讯作者信息)
- 作者列表:Hsiao-Ying Huang (National Taiwan University, Taiwan)、Yi-Cheng Lin (National Taiwan University, Taiwan)、Hung-yi Lee (National Taiwan University, Taiwan)
💡 毒舌点评
本文巧妙地将闭源大模型(LALM)作为“黑盒教师”,与一个在源域训练的“白盒教师”(分类器)结合,并通过互信息加权融合,解决了无源适应中单教师信号不可靠的痛点,这种“双师协作”思路在受限场景下显得尤为务实。然而,框架的性能上限被严格绑定在特定闭源API的稳定性和成本上,这既是其现实意义,也构成了其最大的应用瓶颈。
🔗 开源详情
- 代码:论文中未提及代码仓库链接或开源计划。
- 模型权重:未提及学生模型或分类器教师权重的公开计划。使用的基础模型为Gemini 2.5 Flash(API访问)和WavLM Base+(Hugging Face上可公开获取,但非本文特定)。
- 数据集:使用的MSP-Podcast、IMPROV、IEMOCAP均为公开数据集,可通过其官方渠道获取,论文中提供了相关引用。
- Demo:未提供在线演示。
- 复现材料:论文给出了较为详细的优化器(AdamW)、学习率范围、batch size、正则化参数(dropout, L2)、EMA动量、损失函数权重等关键训练细节,具备一定的可复现性。
- 论文中引用的开源项目:主要引用了预训练模型WavLM Base+和优化器AdamW的实现。
📌 核心摘要
问题:本文研究在源数据不可用且强大的大型音频-语言模型(LALM)仅可通过API访问(闭源)的现实约束下,如何将学生模型适应到目标域,使其在语音情感识别(SER)任务上超越LALM本身。
方法核心:提出MI-Fuse,一个去噪标签融合框架。该框架将闭源LALM和一个在源域训练的SER分类器作为两个教师。通过对两个教师模型进行多次随机推理(MC-Dropout和温度采样)获取预测分布,并计算互信息来量化每个教师的不确定性。然后,根据不确定性(互信息的指数)对两个教师的平均预测分布进行加权融合,生成更可靠的伪标签来训练学生模型。同时引入多样性损失防止类别坍塌,并使用指数移动平均(EMA)更新分类器教师以稳定训练。
新意:与传统无源域适应(SFUDA)仅依赖单一源模型不同,本文首次形式化了使用闭源LALM API作为“源模型”的更难SFUDA场景,并提出了融合通用LALM知识与特定领域知识的去噪标签融合方法。
实验结果:在三个公开情感数据集(MSP-Podcast、IMPROV、IEMOCAP)的六种跨域迁移设置上,MI-Fuse平均未加权准确率达到58.38%,比最强基线(LALM SFUDA)高出3.9%,在所有设置中均表现优异或接近最佳。关键对比如下表所示:
方法 IMP→POD POD→IMP IEM→IMP IMP→IEM POD→IEM IEM→POD 平均 LALM SFUDA 60.59 56.74 51.75 48.40 51.27 58.12 54.48 LALM zero-shot 61.44 53.66 53.66 45.96 45.96 61.44 53.69 Source model SFUDA 41.34 56.74 51.48 53.75 53.85 48.90 51.01 SHOT 41.58 56.51 50.64 50.13 55.94 48.90 50.62 NRC 41.37 56.74 50.48 52.09 59.61 48.90 51.53 MI-Fuse (Ours) 61.92 57.48 54.87 59.09 57.07 59.85 58.38 实际意义:该方法为在无法获取源数据且依赖第三方闭源强大AI服务的现实条件下,部署高性能的情感感知语音系统提供了有效的技术路径。
主要局限性:1) 依赖LALM能输出有意义的概率预测,且受API成本、延迟和可用性限制;2) 假设跨数据集使用固定、一致的情绪标签体系,这在现实应用中不一定成立。
🏗️ 模型架构
MI-Fuse的架构核心是双教师-单学生框架,旨在生成更可靠的伪标签用于无监督域适应(图1)。
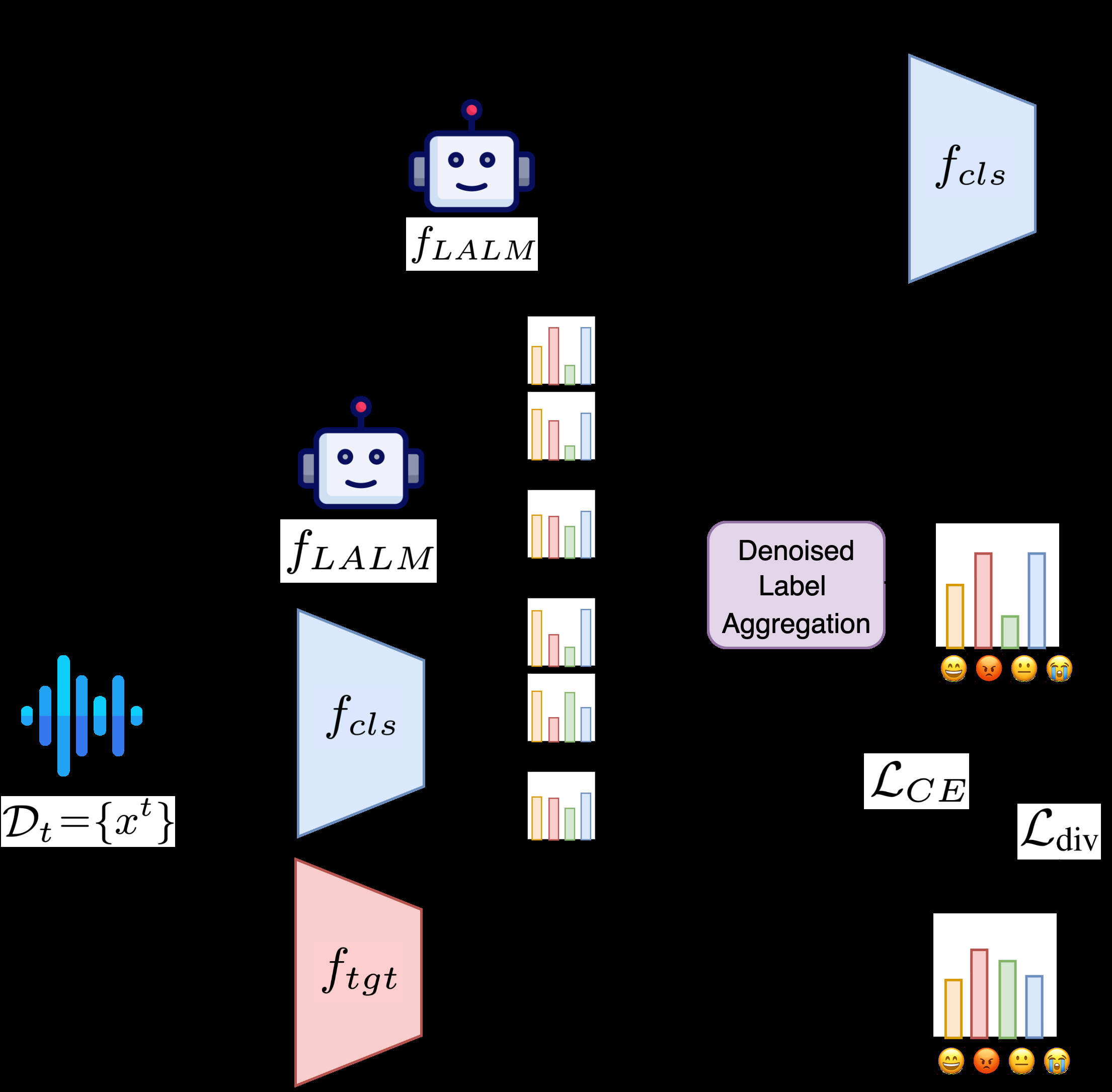
输入与整体流程:
- 输入:未标记的目标域音频数据
x_t。 - 教师1(闭源LALM, f_LALM):通过API查询。对于每个
x_t,使用精心设计的提示(prompt)请求模型输出在情感类别上的概率分布。为估计不确定性,进行N_LM(实验中设为5)次带温度采样(temperature=0.6)的前向传播,得到预测分布集合{p_LM(y|x_t)},并计算其平均分布p̄_LM。 - 教师2(源域分类器, f_cls):基于WavLM Base+骨干网络,在源域数据上预训练。使用蒙特卡洛(MC)Dropout技术对每个
x_t进行N_cls(实验中设为8)次随机前向传播,得到预测分布集合{p_cls(y|x_t)},并计算其平均分布p̄_cls。 - 不确定性估计(互信息MI):对每个教师,根据其多次预测分布计算互信息(公式4),量化其认识不确定性(模型因对新数据不熟悉而产生的预测分歧)。高MI值意味着该教师的预测不稳定、不可信。
- 去噪标签融合:将两个教师的平均分布
p̄_cls和p̄_LM进行加权平均(公式7)。权重为各教师互信息的指数函数e^{-MI},即不确定性越低(MI小)的教师获得越高权重。融合后的分布p_fused作为学生模型训练的软标签。 - 学生模型(f_tgt):初始化为分类器教师
f_cls的参数。使用融合软标签p_fused的交叉熵损失L_CE和一个多样性损失L_div(公式10)进行训练。 - EMA教师更新:每个训练步骤后,分类器教师
f_cls的参数通过学生模型f_tgt参数的指数移动平均(EMA,动量α=0.999)进行更新(公式9)。这使得教师模型随着学生模型的进化而平滑变化,提供更稳定的监督信号,避免早期过拟合。
- 输入:未标记的目标域音频数据
关键设计选择:
- 双教师融合:动机在于结合闭源LALM的通用泛化能力和源域分类器的特定领域知识,以弥补单一教师的缺陷。
- 基于MI的加权:直接利用认识不确定性来动态调整教师的可靠性,比简单的平均或基于熵的加权更能反映模型对新领域的适应程度。
- 多样性损失:旨在防止训练过程中所有样本被预测为同一类别(类别坍塌),通过鼓励批次平均预测分布的高熵来实现。
- EMA教师:稳定训练的关键,确保教师模型不会因学生模型早期的不稳定训练或噪声伪标签而剧烈波动。
💡 核心创新点
- 形式化闭源LALM参与的SFUDA场景:定义了一个更贴近现实部署的难题——源数据不可用且“源模型”是一个只能通过API访问的黑盒LALM。这扩展了传统SFUDA的研究范畴。
- 不确定性感知的去噪标签融合:提出一种新颖的标签生成机制,通过互信息量化来自不同知识源(通用大模型与特定分类器)的伪标签的不确定性,并进行加权融合。这有效抑制了因域偏移带来的噪声,提供了比单一教师或简单集成更可靠的监督信号。
- 结合EMA与多样性的稳定训练策略:通过EMA更新分类器教师来平滑监督信号的演变,同时引入多样性损失防止模型退化,共同确保了整个适应过程的稳定性,避免了传统自训练方法中常见的性能震荡或下降。
🔬 细节详述
- 训练数据:
- 数据集:三个公开数据集:MSP-Podcast (POD), MSP-IMPROV (IMP), IEMOCAP (IEM)。过滤为4类情绪(happy, sad, angry, neutral)。
- 规模与划分:论文中未提供具体样本数量。IMPROV和IEMOCAP使用交叉验证(分别为6折和5折),Podcast仅单折。
- 数据增强:未提及使用特定数据增强技术。
- 损失函数:
L = L_CE + λ_div * L_div。L_CE:学生预测分布与融合软标签p_fused之间的交叉熵损失(软标签损失)。L_div:多样性损失,定义为批次平均预测分布p̄_batch的负熵(-H(p̄_batch)),鼓励预测分布均匀。λ_div:平衡系数,实验中设为1。
- 训练策略:
- 优化器:AdamW。
- 学习率:学生模型在
{7.5e-4, 5e-4, 1e-4, 5e-5, 1e-6}中进行网格搜索;分类器教师训练学习率为5e-4。 - Batch Size:32。
- 训练时长:训练直到损失停止下降1000步。
- 关键超参数:
- LALM查询次数
N_LM= 5,分类器MC-Dropout前向次数N_cls= 8。 - LALM文本生成温度:0.6。
- EMA动量
α= 0.999。 - 分类器Dropout率:0.4。
- L2正则化权重:0.1。
- LALM查询次数
- 训练硬件:论文中未提及。
- 推理细节:
- LALM推理使用温度采样(温度0.6),目的是引入随机性以进行多次采样估计不确定性。
- 最终分类时,对融合后的分布
p_fused取argmax。
- 正则化技巧:使用了Dropout(在MC-Dropout和分类器训练中)、L2正则化、多样性损失、EMA教师更新。
📊 实验结果
- 主要Benchmark与结果:
- 在六种跨数据集迁移任务上评估,使用未加权准确率(Accuracy %)作为指标。核心结果如上文“核心摘要”中的表格所示。
- 与最强基线比较:MI-Fuse平均准确率(58.38%)比单一使用LALM进行SFUDA(LALM SFUDA, 54.48%)高出3.9个百分点,比传统的SOTA SFUDA方法NRC(51.53%)高出6.85个百分点。
- 消融实验(针对IEMOCAP数据集):
| 生成方式 | 相似性门控 | 加权方式 | IMP → IEM | POD → IEM |
|---|---|---|---|---|
| Multi | Direct | MI (Ours) | 59.09 | 57.07 |
| Multi | Direct | Entropy | 57.34 | 55.53 |
| Multi | Direct | Equal | 57.98 | 56.64 |
| Multi | KL | MI | 55.23 | 55.86 |
| Multi | No Fusion | - | 56.08 | 55.43 |
| Single | Direct | Entropy | 56.82 | 55.85 |
| Single | Direct | Equal | 58.26 | 55.23 |
结论:
1. 生成方式:`Multi`(多次采样平均)显著优于`Single`(单次推理),证明了多次预测估计不确定性的重要性。
2. 融合策略:`Direct`融合(始终融合两教师)优于`KL`门控(仅在分布相似时融合)和`No Fusion`(单选),表明互补信息的融合总是有益的。
3. 加权方式:基于互信息(MI)的加权优于基于熵(Entropy)的加权和等权重(Equal),验证了使用认识不确定性进行加权的有效性。
- 训练稳定性分析(图2):
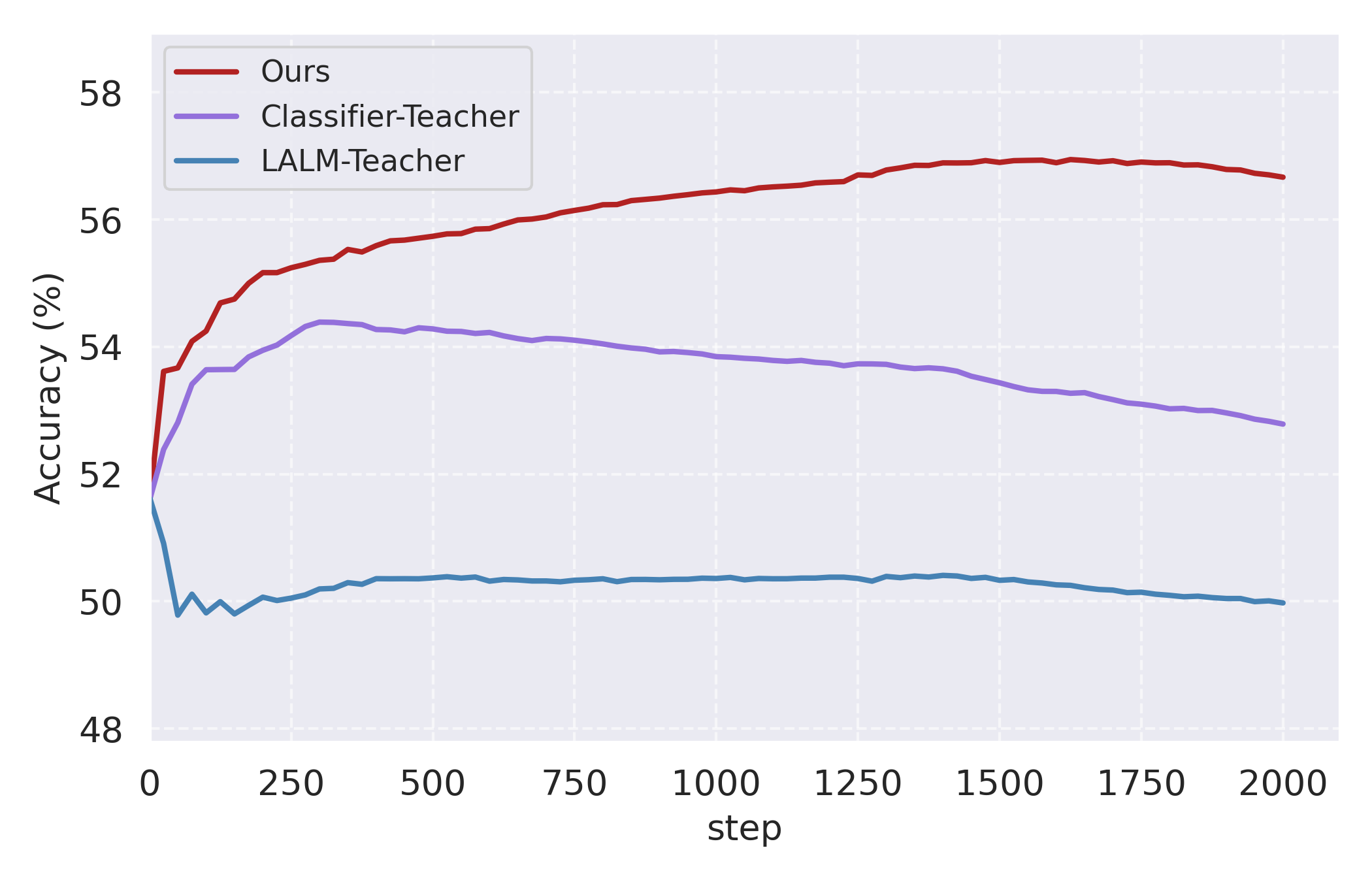 结论:MI-Fuse(红线)的训练曲线持续稳定上升,而分类器教师(紫线)在约400步后因过拟合早期伪标签而下降,LALM教师(蓝线)性能最差且起步即大幅下跌。这直观证明了MI-Fuse通过融合与稳定训练机制,有效平衡了两个教师的信息并抑制了噪声。
结论:MI-Fuse(红线)的训练曲线持续稳定上升,而分类器教师(紫线)在约400步后因过拟合早期伪标签而下降,LALM教师(蓝线)性能最差且起步即大幅下跌。这直观证明了MI-Fuse通过融合与稳定训练机制,有效平衡了两个教师的信息并抑制了噪声。
⚖️ 评分理由
- 学术质量:6.0/7:论文针对一个定义清晰、有现实意义的约束性问题,提出了一套技术路线正确、组件设计合理(MI融合、多样性损失、EMA教师)的完整解决方案。实验设计全面,覆盖了多种迁移场景、多种基线对比和深入的消融实验,结果分析充分,证据可信度高。创新性体现在对现有技术的巧妙整合与对新场景的定义上,而非提出全新的基础模块,故未给予更高分。
- 选题价值:1.5/2:选题切中了AI模型闭源化、数据隐私受限的实际部署痛点,为“如何在不接触源数据且仅能调用黑盒API的情况下提升特定任务模型性能”提供了有价值的范例,对音频/语音领域的应用研究有明确指导意义。
- 开源与复现加成:0.0/1:论文未提供代码、模型或数据集链接,也未承诺开源。虽然文中有详细的训练细节,但缺乏可直接复现的材料,因此无法给予加成。