📄 MFF-RVRDI: Multimodal Fusion Framework for Robust Video Recording Device Identification
#视频设备识别 #多模态融合 #注意力机制 #鲁棒性
✅ 7.5/10 | 前25% | #视频设备识别 | #多模态融合 | #注意力机制 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Wei Li(杭州电子科技大学计算机科学与技术学院)
- 通讯作者:Xingfa Shen(杭州电子科技大学计算机科学与技术学院,shenxf@hdu.edu.cn)
- 作者列表:Wei Li(杭州电子科技大学计算机科学与技术学院)、Yu Cao(杭州电子科技大学计算机科学与技术学院)、Xingfa Shen(杭州电子科技大学计算机科学与技术学院)
💡 毒舌点评
亮点:论文敏锐地抓住了“真实噪声下视频设备识别”这一实际痛点,并创新性地设计了SD-BCA模块来解决音视频对齐与融合的核心难题,实验数据也确实显示了其在低信噪比下的强大鲁棒性。短板:作为一篇顶会论文,在模型轻量化和效率上着墨不多,且完全缺少代码、模型和训练细节的公开,这对于一个强调“实用”和“部署”的框架来说,极大地削弱了其可验证性和后续影响力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开数据集QUFVD和Daxing。论文中未提及他们构建的噪声增强版本(QUFVD-NA, Daxing-NA)是否公开。
- Demo:未提及。
- 复现材料:论文提供了一些训练参数(优化器、初始学习率、权重衰减、批大小)和硬件信息(A100 GPU),但缺少模型架构的详细配置(如层数、维度)、完整的训练过程(如总epoch数、验证策略)、以及具体的评估脚本,因此复现信息不充分。
- 论文中引用的开源项目:未提及依赖的特定开源模型或代码库,但使用了FFmpeg进行数据处理。
📌 核心摘要
- 要解决什么问题:现有视频录制设备识别方法大多仅依赖视觉信息,在真实世界存在的压缩、降噪等处理导致信噪比(SNR)降低时,性能会显著下降。
- 方法核心是什么:提出一个多模态融合框架MFF-RVRDI,同时利用视频和音频信息进行设备识别。其核心是一个名为“同步-可变形双向跨模态注意力”(SD-BCA)的模块,用于对齐音视频时间偏移并实现双向细粒度交互;以及一个“集成指纹增强模块”(IFEM),用于在压缩场景下增强设备特有残差。
- 与已有方法相比新在哪里:新在多模态融合视角(引入音频作为补充)和专门设计的跨模态交互模块(SD-BCA)。相比以往仅优化视觉特征或进行简单拼接融合的方法,SD-BCA显式建模了模态间的时间对齐和空间选择性注意力。
- 主要实验结果如何:
- 在标准数据集(QUFVD, Daxing)上,MFF-RVRDI达到了99.9%的Top-1准确率。
- 在模拟真实噪声的增强数据集(QUFVD-NA, Daxing-NA)上,MFF-RVRDI的准确率分别为88.6%和89.3%,比最强的单模态基线(图像仅)高出超过12个百分点,比之前的SOTA方法(如CNN+Fusion)高出超过24个百分点。
- 消融实验证明,SD-BCA中的时间同步、可变形采样和双向注意力设计分别带来了性能提升,完整模块比单向基线提升12-15个百分点。
- 实际意义是什么:为低质量、高噪声环境下的视频来源设备识别提供了一种更鲁棒的解决方案,提升了数字取证在现实复杂场景中的可靠性和实用性。
- 主要局限性是什么:论文未讨论模型的计算复杂度和推理速度;实验在构建的噪声增强数据集上进行,其与真实世界复杂降质的匹配度有待验证;未提供开源代码和模型,可复现性不足。
🏗️ 模型架构
MFF-RVRDI是一个端到端的多模态深度学习框架,整体架构如图1所示,其流程分为三个主要阶段:数据预处理、双分支特征提取、跨模态融合与分类。
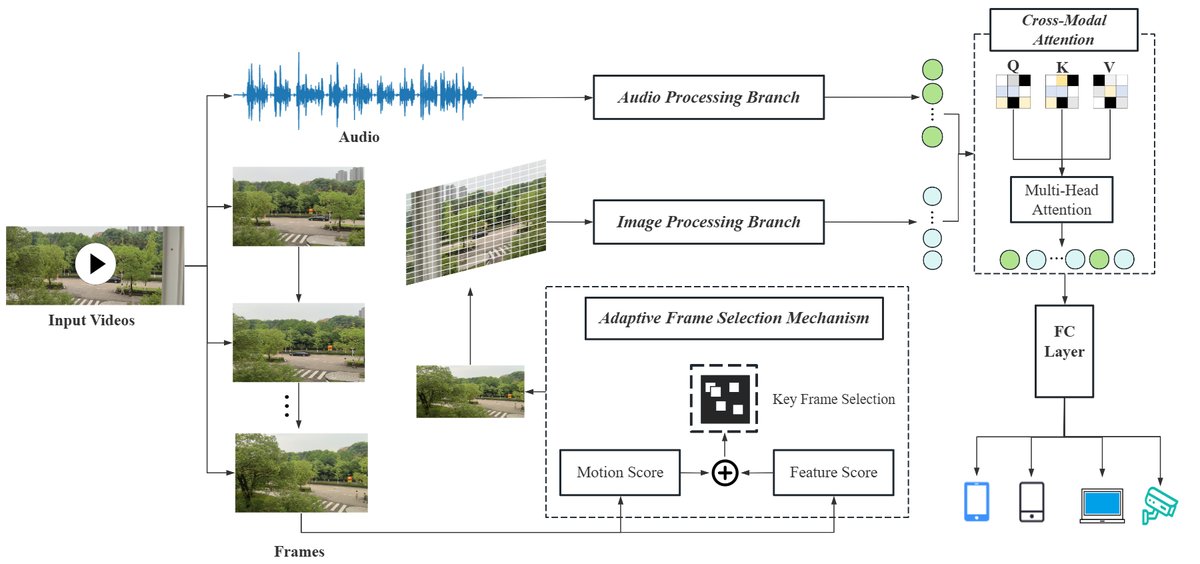
数据预处理:
- 使用FFmpeg将视频分离为音频流和I帧图像流。音频被转换为44.1kHz的PCM格式。
- 设计了一个设备感知关键帧选择器,从运动动态性、纹理显著性和指纹能量(通过PRNU残差计算)三个维度对I帧进行评分,选择少量有信息量的帧进行处理,在保持精度的同时降低计算成本。
双分支特征提取:
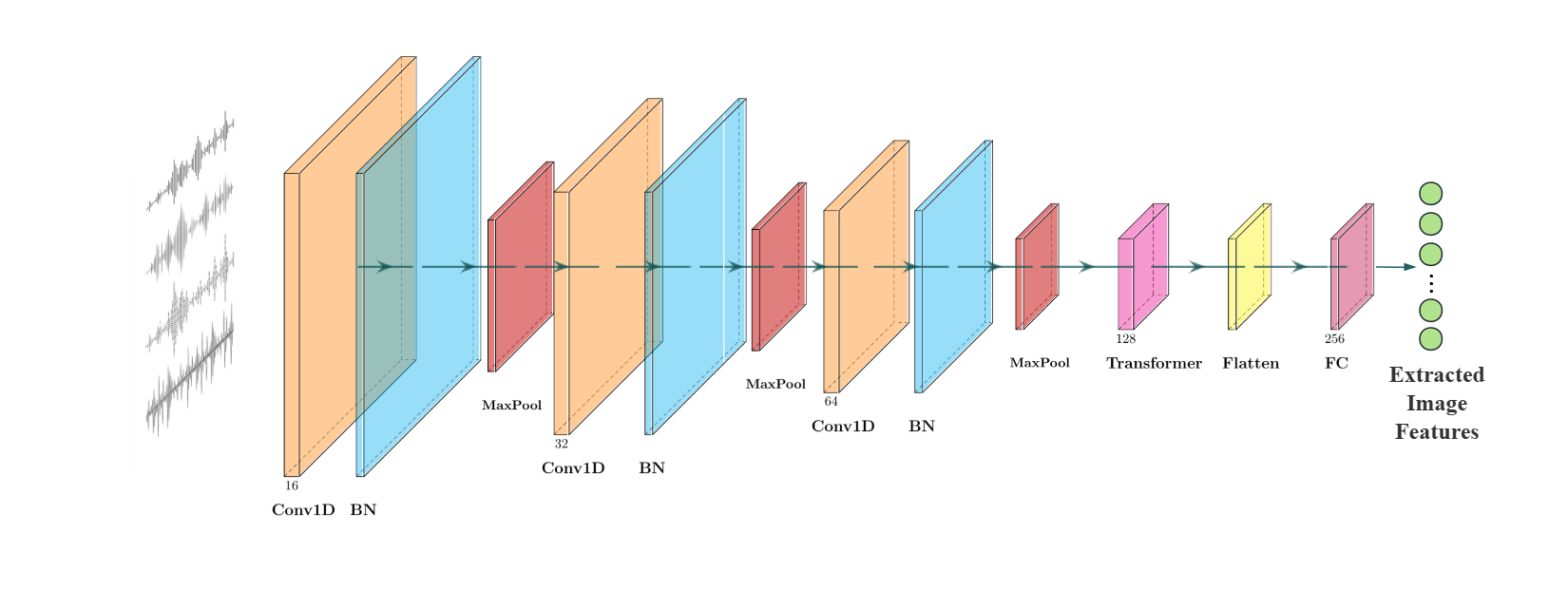
音频处理分支(如图2):
- 局部特征提取:使用堆叠的1D卷积层,配合批归一化(BN)、激活函数和池化,逐步提取从粗到细的局部频谱和时序特征,捕获设备相关的麦克风或编码器噪声特征。
- 全局上下文建模:接入一个轻量级Transformer编码器,建模长距离依赖关系,强调波形中的关键段落。
- 输出是一个紧凑的音频嵌入向量,准备与视觉特征融合。
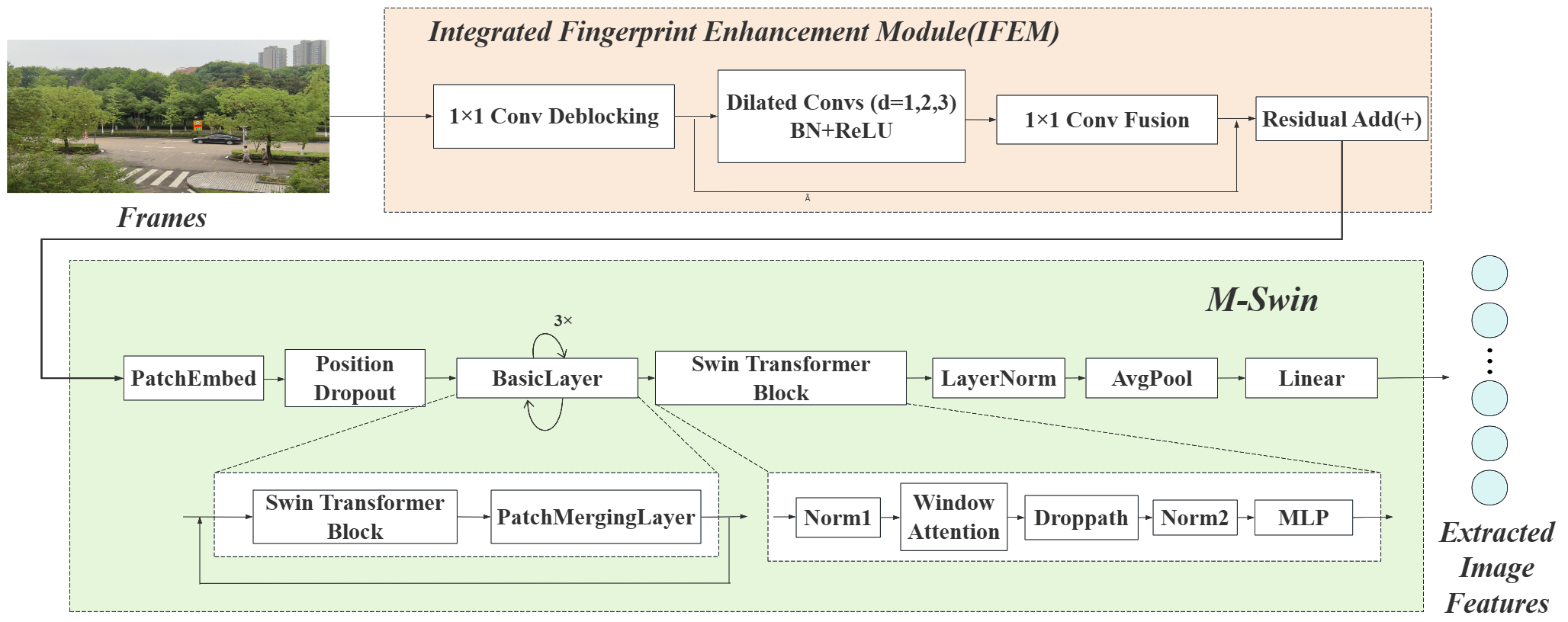
图像处理分支(如图3):
- 集成指纹增强模块(IFEM):这是一个关键组件。它在一个残差块中集成了轻量级去块效应和多尺度放大操作。其动机是避免传统先去块再提取指纹流程造成的过度平滑,在抑制压缩伪影的同时增强细微的设备指纹信号。
- M-Swin编码器:基于Swin Transformer进行改进,优化了注意力机制和嵌入策略。它通过层级结构逐步聚合上下文,在保留局部细节和捕获全局信息之间取得平衡,计算开销低于全局ViT。
- 输入是预处理后选择的关键帧,经过IFEM增强后,被分块(tokenized)并送入M-Swin,输出视觉特征嵌入。
跨模态特征融合(SD-BCA)(如图4): 这是论文的核心模块,旨在解决音视频融合的两大挑战:时间未对齐和单向交互的局限性。它包含三个子模块:
- 时间对齐(Sync):一个轻量级同步器
g_sync接收图像嵌入I和音频嵌入A,预测一个帧级时间偏移Δt。音频流随后根据此偏移进行平移,以补偿可能的录制延迟。 - 可变形采样(Deformable):受可变形DETR启发,每个注意力头学习采样偏移
Δp。这使得模型能够自适应地关注特征图上高能量的指纹区域,而非均匀扫描整个空间,提高了效率和针对性。 - 双向跨注意力(Bidirectional Cross-Attention):两个并行路径允许模态间相互强化。
C_I→A路径让图像模态查询音频特征(Q_I,K_A,V_A),C_A→I路径让音频模态查询图像特征(Q_A,K_I,V_I)。这种双向机制确保了信息的双向流动和相互增强。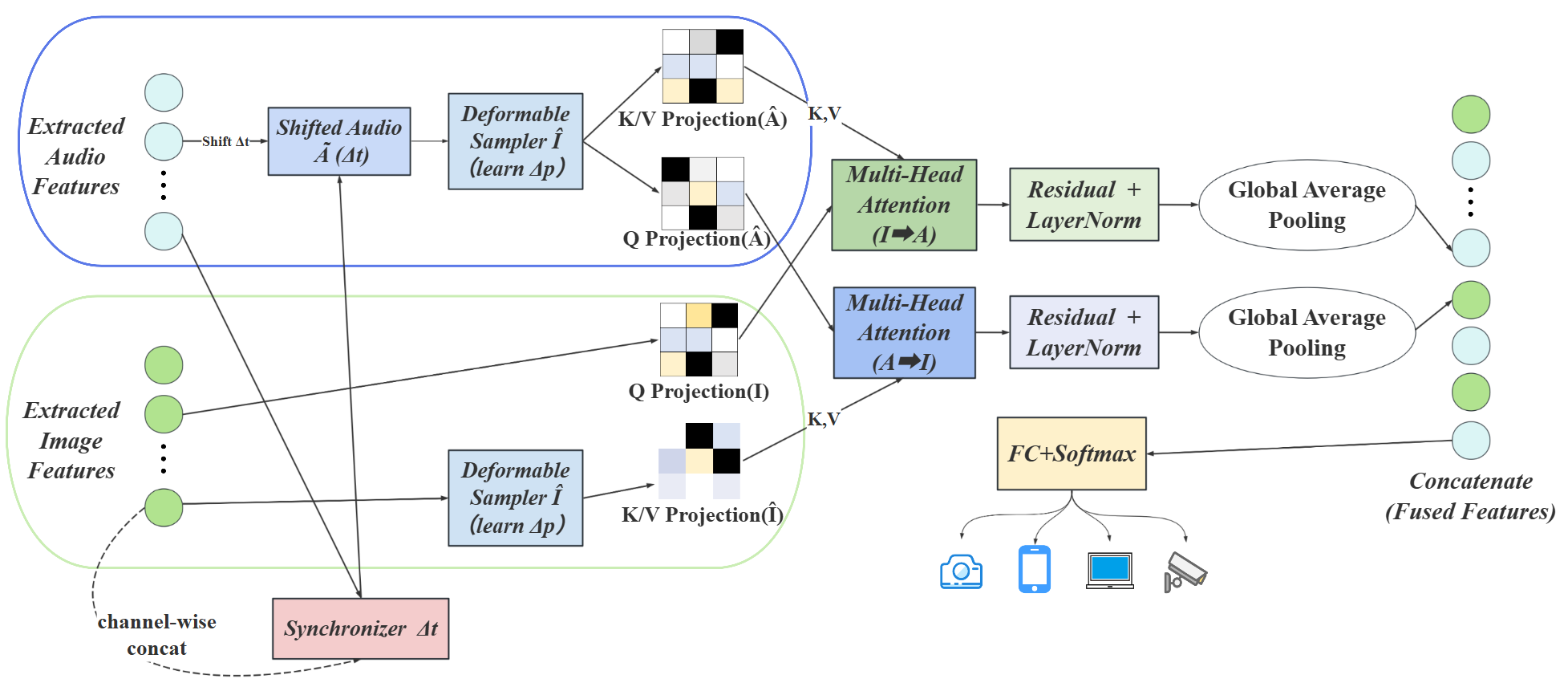
- 时间对齐(Sync):一个轻量级同步器
融合与分类:SD-BCA的两个输出路径通过残差连接和全局池化合并,形成一个紧凑的融合表示,最后送入一个线性分类器进行设备类别预测。
💡 核心创新点
提出针对视频设备识别的多模态融合框架(MFF-RVRDI):
- 之前局限:绝大多数现有方法是单模态的,仅使用视觉信息,在视觉信号因压缩、降噪等原因受损时性能急剧下降。
- 如何起作用:同时建模音频和视觉信号。音频信号(如麦克风自噪声、音频编码特征)可以提供与视觉指纹互补的、对视觉降质更具鲁棒性的设备线索。
- 收益:在低SNR(0 dB)条件下,相比最强的单模态(图像)基线,性能提升超过12个百分点(见表2)。
设计同步-可变形双向跨模态注意力(SD-BCA)模块:
- 之前局限:简单的跨模态融合(如拼接、单向注意力)无法有效处理音视频间可能存在的时序偏移,且融合不够精细,导致次优结果。
- 如何起作用:通过时间同步解决时序错位;通过可变形采样自适应聚焦于最有鉴别力的特征区域;通过双向注意力实现模态间信息的相互引导和增强。
- 收益:消融实验(表3)表明,完整的SD-BCA模块(同步+可变形+双向)比无同步的基线在两个数据集上分别提升3.9和4.3个百分点,比单向融合基线提升12-15个百分点。
提出集成指纹增强模块(IFEM):
- 之前局限:传统的两阶段流水线(先去块效应,再提取指纹)可能会在第一步过度平滑掉有用的设备特有高频残差。
- 如何起作用:将去块效应与多尺度指纹放大操作集成在一个紧凑的残差块中,以端到端的方式同时抑制伪影并增强指纹信号,且计算开销低。
- 收益:论文未单独对IFEM进行消融,但从整体框架在压缩数据集上的优异表现可以推断其有效。
🔬 细节详述
- 训练数据:
- 数据集:QUFVD(6000个片段,20部手机)和Daxing(1400个片段,90部手机)。为评估鲁棒性,构建了噪声增强版本QUFVD-NA和Daxing-NA。
- 预处理与增强:音频提取为44.1kHz PCM。I帧选择采用设备感知关键帧选择器。训练时对图像帧应用随机裁剪、颜色抖动、翻转、旋转等标准数据增强。
- 损失函数:论文中未说明具体损失函数名称,但根据任务(分类)和描述(“passed to a linear classifier for device prediction”),可推断使用的是交叉熵损失(Cross-Entropy Loss)。
- 训练策略:
- 优化器:AdamW。
- 学习率调度:余弦退火(Cosine Annealing),初始学习率
1e-4。 - 权重衰减:
5e-2。 - 批大小(Batch Size):32。
- 训练轮数/步数:未说明。
- 关键超参数:模型各分支的具体网络深度、隐藏维度、注意力头数等超参数均未在论文中提供。
- 训练硬件:在NVIDIA A100 GPU上训练,具体数量未说明。
- 推理细节:未说明具体的解码策略、温度、beam size等(此任务为分类,通常不涉及生成式解码)。
- 正则化或稳定训练技巧:除标准数据增强外,未提及其他技巧(如Dropout、Label Smoothing)。
📊 实验结果
论文在四个数据集(QUFVD, QUFVD-NA, Daxing, Daxing-NA)上评估了Top-1识别准确率。
表1:不同方法在四个数据集上的准确率(%)
| 方法 | QUFVD | QUFVD-NA | Daxing | Daxing-NA |
|---|---|---|---|---|
| SPN+WCS [12] | 78.7 | 57.8 | 79.2 | 55.9 |
| PRNU+FMT [7] | 81.5 | 49.8 | 82.4 | 47.9 |
| CNN+Fusion [8] | 92.4 | 63.8 | 92.1 | 64.0 |
| PRNU-Net [10] | 90.5 | 61.4 | 90.7 | 60.8 |
| MFF-RVRDI (Ours) | 99.9 | 88.6 | 99.9 | 89.3 |
关键结论:
- 在标准数据集上,所有深度学习方法均表现优异,MFF-RVRDI达到近乎完美的准确率。
- 在噪声增强数据集(NA)上,传统方法性能崩溃(下降30-40个百分点),CNN-based方法也有显著下降。MFF-RVRDI则保持了88%以上的准确率,体现了其强大的鲁棒性。
表2:0 dB SNR下单模态与多模态输入的性能对比
| 变体 | QUFVD-NA | Daxing-NA |
|---|---|---|
| 仅图像 | 76.2 | 75.7 |
| 仅音频 | 67.2 | 64.9 |
| 融合 (Ours) | 88.55 | 89.34 |
关键结论:多模态融合显著优于任何单一模态,证实了音频线索的互补价值。
表3:SD-BCA模块在0 dB SNR下的消融实验
| 变体 | QUFVD-NA | Daxing-NA |
|---|---|---|
| 无同步 + 密集采样 | 84.7 | 85.0 |
| + 仅同步 | 87.0 | 88.0 |
| + 仅可变形 | 86.1 | 87.1 |
| 同步 + 可变形 + 双向注意力 | 88.6 | 89.3 |
关键结论:同步和可变形采样各自带来性能提升,而三者结合(完整SD-BCA)达到最佳效果,证明了其设计的必要性。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个新颖且有效的多模态融合框架来解决一个实际问题。SD-BCA和IFEM的设计具有针对性的创新,技术路线合理。实验设计完整,包含了与强基线的对比、模态消融和核心模块消融,数据充分支撑了结论。扣分主要因为部分关键实现细节(如损失函数具体形式、各分支网络结构详细参数)未给出,且缺乏对模型效率(计算量、推理速度)的分析。
- 选题价值:1.5/2:视频设备识别是数字取证的重要课题,提升其在真实噪声下的鲁棒性具有明确的应用价值。多模态融合是解决此类问题的先进思路。但该任务属于相对垂直的特定应用领域,对更广泛的音频/语音研究社区的直接普适性有限。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重、详细超参数和训练日志。这极大地阻碍了其他研究者复现、验证和基于此工作进行改进,是该论文的一个显著缺陷。