📄 Membership Inference Attack against Music Diffusion Models via Generative Manifold Perturbation
#音频安全 #扩散模型 #对抗样本 #鲁棒性
✅ 7.5/10 | 前25% | #音频安全 | #扩散模型 | #对抗样本 #鲁棒性
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Yuxuan Liu(未明确标注,按署名顺序为首位)
- 通讯作者:未明确标注
- 作者列表:Yuxuan Liu, Peihong Zhang, Rui Sang, Zhixin Li, Yizhou Tan, Yiqiang Cai, Shengchen Li(均来自Xi’an Jiaotong-Liverpool University, Suzhou, China)
💡 毒舌点评
亮点:首次系统性地将成员推断攻击聚焦于音乐扩散模型,并聪明地将对抗鲁棒性差异转化为Membership Inference的信号,其提出的LSA-Probe在低误报率关键指标上取得了显著且一致的提升。 短板:攻击方法依赖于多轮二分搜索和PGD优化,计算开销巨大,这使其在现实世界中作为大规模审计工具的可行性大打折扣;同时,攻击效果的绝对数值(例如DiffWave上最高的20% TPR@1%FPR)距离“可靠”的审计标准仍有相当差距。
🔗 开源详情
- 代码:论文提供了项目Demo的GitHub仓库链接:https://github.com/kaslim/LSA-Probe。
- 模型权重:论文中未提及是否公开DiffWave和MusicLDM的模型权重。
- 数据集:论文使用了公开数据集MAESTRO v3和FMA-Large,但未说明其预处理脚本是否开源。
- Demo:未提及在线演示。
- 复现材料:论文提供了核心超参数(K, r, β, τ=P95等)、评估协议和部分实现细节。但未提供完整的训练细节、配置文件、检查点。
- 论文中引用的开源项目:DiffWave [13], MusicLDM [1]。攻击基线中的SecMI [22]等可能也依赖开源实现。
📌 核心摘要
- 问题:扩散模型在音乐生成中表现出色,但其训练数据可能涉及版权与隐私问题。如何有效判断一段特定的音乐片段是否被用于训练某个音乐扩散模型(成员推断攻击,MIA),成为审计生成式音乐模型合规性的关键挑战。传统基于损失信号的MIA方法在音频领域效果不佳。
- 方法核心:本文提出Latent Stability Adversarial Probe(LSA-Probe),一种白盒攻击方法。其核心思想是:训练集中的“成员”样本位于模型生成流形的更稳定区域。该方法通过测量在反向扩散过程的中间潜状态中,使生成质量下降到一个固定感知阈值所需的最小归一化扰动预算(对抗成本)来评估这种稳定性。成员样本需要更大的扰动成本才能被降质。
- 创新点:与已有工作相比,LSA-Probe放弃了单一的端点重建损失信号,转而探测沿生成轨迹的动态几何稳定性。它是首个针对音乐扩散模型(包括波形DDPM和潜扩散模型LDM)的系统性MIA研究,并建立了局部生成稳定性与成员身份之间的联系。
- 主要结果:在DiffWave和MusicLDM两个模型,以及MAESTRO v3和FMA-Large两个数据集上的实验表明,在匹配计算量的前提下,LSA-Probe在低误报率(FPR=1%)下的真阳性率(TPR)比最佳基线方法高3-8个百分点。例如,在DiffWave/MAESTRO上,TPR@1%FPR从0.12提升至0.20。消融实验显示,中段扩散时间步、中等扰动预算以及感知度量(CDPAM/MR-STFT)的效果最优。
- 实际意义:为音乐版权持有者和审计方提供了一种潜在的技术工具,用于检测AI音乐生成模型是否未经授权使用了其作品进行训练,有助于规范生成式AI的发展。
- 主要局限性:攻击方法计算成本高(涉及多次PGD优化和反向传播);其有效性阈值(如TPR@1%FPR)虽有提升,但绝对值仍不高,在需要极低误报率的严格审计场景下实用性受限;评估模型和数据集范围有限。
🏗️ 模型架构
本文未提出新的生成模型架构,而是针对现有音乐扩散模型(DiffWave和MusicLDM)设计一种成员推断攻击方法。因此,架构描述主要围绕LSA-Probe攻击框架的流程。 LSA-Probe是一个双层循环优化过程(图1):
- 外层循环(图1a):执行二分搜索,目标是找到达到固定感知降质阈值(τ)所需的最小扰动预算η。当前η作为对抗成本(Cₐdv)的估计值。
- 内层循环(图1b):执行投影梯度下降(PGD),针对给定的η,在中间潜状态xt上优化一个时间归一化的扰动δt = σt * σ̃(σt = √(1-ᾱt) 是噪声尺度),以最大化扰动前后生成样本之间的感知距离D。优化变量是σ̃,其范数被约束在η内。
- 攻击流程:对于待检测的音频x0,在某个选定的时间步t,首先通过前向过程添加噪声得到xt。然后,外层循环尝试不同的η值,内层循环针对每个η寻找最优扰动σ̃,使得扰动后通过确定性反向操作Rt(·; θ)得到的重建样本与原重建样本之间的感知距离D最大化。当该最大距离首次超过阈值τ时,外层循环记录当前的η作为Cₐdv。最终,用Cₐdv作为判断成员身份的分数(值越大,越可能是成员)。
- 关键设计选择:
- 时间归一化扰动:将扰动δt与噪声尺度σt挂钩,使得不同时间步的扰动预算具有可比性,因为它们匹配了前向噪声的方差。
- 固定前向噪声:为每个(x0, t)对固定前向噪声ε,确保成对评估(扰动前后)隔离了扰动δt本身的影响。
- 潜空间操作(针对LDM):对于MusicLDM,攻击在VAE编码后的潜空间进行,梯度通过冻结的解码器反向传播。
💡 核心创新点
- 首个针对音乐扩散模型的成员推断攻击系统研究:填补了针对音乐生成模型进行版权审计的MIA技术空白。之前的音频MIA研究主要集中于序列模型或未专门针对扩散架构。
- 提出LSA-Probe方法,将生成流形稳定性作为成员信号:创新性地将对抗鲁棒性(达到特定降质所需成本)与生成模型对训练数据的“记忆”程度联系起来。该方法不再依赖于易受内容复杂度和噪声干扰的静态重建损失,而是探索动态的几何属性。
- 连接局部生成稳定性与成员身份的理论分析:论文通过一阶分析(虽未给出详细推导)将成员样本在生成流形上位于更平滑、更稳定的区域这一假设操作化,转化为一个可计算的、无需似然或影子模型的评分函数。
- 全面且控制公平性的实验评估:在两种主流音乐扩散模型(波形DDPM与潜扩散LDM)、两种数据集(独奏钢琴与多流派音乐)上进行验证,并通过匹配计算资源(UNet调用次数)确保与基线的公平比较,增强了结论的说服力。
🔬 细节详述
- 训练数据:
- 数据集:MAESTRO v3(独奏钢琴)、FMA-Large(多流派)。
- 预处理:音频被切分为4秒的片段,按作品/艺术家(MAESTRO)或曲目/艺术家(FMA)分层划分,以避免数据泄漏。使用Chromaprint+LSH去除重复/翻唱版本。
- 规模:未说明具体片段数量。
- 数据增强:未说明。
- 损失函数:攻击本身不涉及训练损失,其内层循环优化目标是最大化感知距离D。论文测试了多种可微距离D:CDPAM(主要使用)、多分辨率STFT(MR-STFT)距离、对数梅尔谱MSE、波形MSE。
- 训练策略:论文描述的是攻击方法,而非模型训练。攻击优化使用PGD,参数为:步数K=12,动量0.9,重启次数r=5,步长α = β*η/K(β∈[0.2, 0.3])。外层二分搜索固定10步。
- 关键超参数:时间步比率t_ratio=0.6(主要设置),扰动范数p=2,最大预算η_max=0.8,固定阈值τ为开发集非成员样本上95分位数(P95)。
- 训练硬件:未说明。
- 推理细节:攻击评估使用确定性DDIM采样(σt=0)。对于DiffWave,直接在波形空间操作;对于MusicLDM,在VAE潜空间操作,然后通过冻结解码器得到波形。
- 正则化或稳定训练技巧:攻击优化中使用了梯度裁剪(投影到ℓp球内)和早停策略(连续3步ΔD/D < 1%或梯度范数<1e-6)。
📊 实验结果
主要评估指标为TPR@1%FPR(低误报率下的检出率)和AUC-ROC。
表1:主要结果(匹配计算量,DDIM, t_ratio=0.6, p=2, η_max=0.8)
| 模型 | 数据集 | 最佳基线 (TPR@1% / AUC) | Ours (TPR@1% / AUC) | Δ (Ours - 最佳基线) |
|---|---|---|---|---|
| TPR@1% | AUC | TPR@1% | ||
| MusicLDM | MAESTRO | 0.10 [0.07–0.12] / 0.58±0.02 | 0.13 [0.10–0.15] / 0.61±0.03 | +0.03 |
| MusicLDM | FMA-Large | 0.08 [0.05–0.10] / 0.56±0.01 | 0.14 [0.10–0.16] / 0.59±0.02 | +0.06 |
| DiffWave | MAESTRO | 0.12 [0.09–0.15] / 0.63±0.02 | 0.20 [0.16–0.24] / 0.67±0.02 | +0.08 |
| DiffWave | FMA-Large | 0.11 [0.08–0.14] / 0.62±0.02 | 0.18 [0.14–0.22] / 0.66±0.02 | +0.07 |
- 与最强基线对比:LSA-Probe在所有设置下均优于最佳基线(Loss/Trajectory/SecMI)。在DiffWave模型上的提升尤为明显(TPR@1%FPR绝对提升7-8个百分点)。同时表明LDM(MusicLDM)比DDPM(DiffWave)对成员推断攻击更具鲁棒性。
图2:关键分析(固定τ=P95,DDIM, p=2, η_max=0.8)
- (a) ROC曲线:在t_ratio=0.6时,LSA-Probe(红线)在低FPR区域(左侧)明显高于基线,与表1结果一致,证实了其在低误报率场景下的优势。
- (b) 时间步消融:扫描t_ratio∈{0.2, 0.4, 0.6, 0.8},中段时间步(0.6)展现出最强的分离度(最高的TPR@1%FPR)。这符合直觉:反向路径早期关注全局布局,晚期关注细节,而中期可能包含了与训练数据关联最强的特征。
- (c) 预算消融:增加扰动预算η能持续提升TPR@1%FPR,但在η≈0.6-0.8附近出现轻微饱和。这表明在一定范围内,更大的搜索空间有助于发现更优的对抗方向。
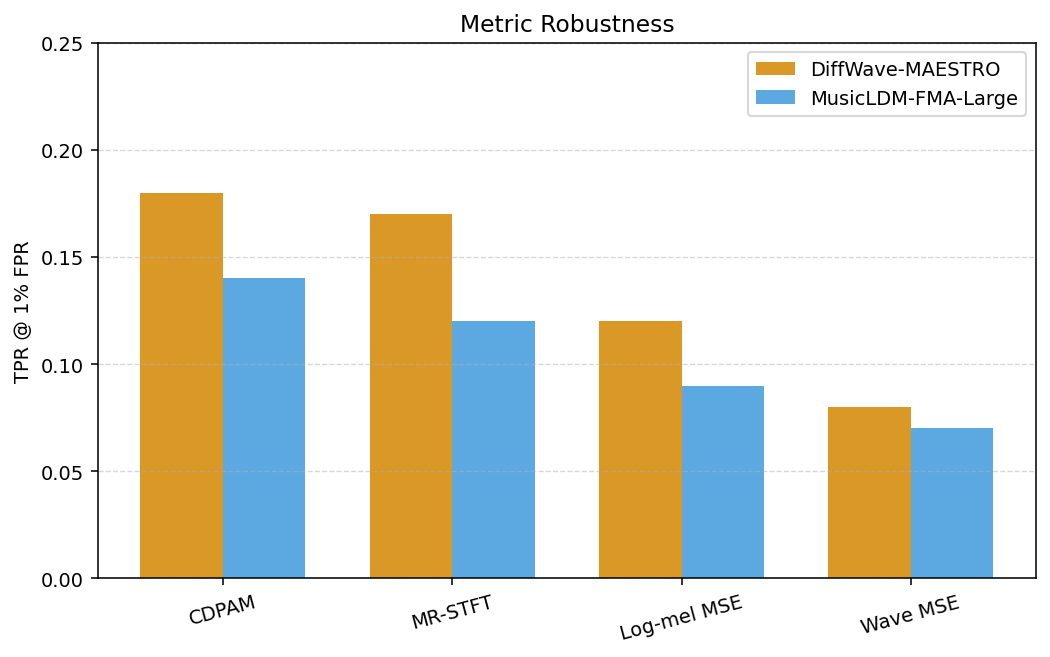
- (d) 距离度量消融:在低FPR区域,感知度量(CDPAM, MR-STFT)比训练对齐的MSE(波形MSE, 对数梅尔MSE)提供了更强的区分能力。这验证了论文的动机,即感知降质比简单的信号重建误差更适合作为成员信号。
⚖️ 评分理由
- 学术质量:5.5/7:论文问题明确,动机清晰,提出的LSA-Probe方法具有新颖性和技术合理性,实验设计控制了计算公平性,结果在统计上显著,支撑了其核心假设。扣分点在于:该方法的核心思想(利用对抗鲁棒性差异)在图像/视频领域已有类似工作(如引用的[9,11]),并非完全原创;作为攻击方法,其绝对有效性(如TPR@1%FPR)仍有较大提升空间;部分实现细节(如完整的训练数据描述)缺失。
- 选题价值:1.5/2:将成员推断攻击应用于音乐扩散模型,直接回应了AI生成内容版权合规的热点问题,具有明确的实际应用前景和学术前沿性。音乐领域相对图像/文本较小众,因此未能给满分。
- 开源与复现加成:0.5/1:论文在摘要和作者信息部分提供了项目Demo的GitHub链接(https://github.com/kaslim/LSA-Probe),这极大地促进了方法的透明度和可复现性。然而,论文未提及模型权重、具体训练数据集的获取方式,且代码仓库的完整性(是否包含攻击所有组件、预训练模型等)无法从当前文本中确认。