📄 MELA-TTS: Joint Transformer-Diffusion Model with Representation Alignment for Speech Synthesis
#语音合成 #扩散模型 #自回归模型 #端到端 #零样本
✅ 7.0/10 | 前25% | #语音合成 | #扩散模型 | #自回归模型 #端到端
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Keyu An(Alibaba group)
- 通讯作者:Zhiyu Zhang(National Mobile Communications Research Laboratory, Southeast University)
- 作者列表:Keyu An⋆(Alibaba group)、Zhiyu Zhang⋆†(Alibaba group, National Mobile Communications Research Laboratory, Southeast University)、Changfeng Gao⋆(Alibaba group)、Yabin Li⋆(Alibaba group)、Zhendong Peng⋆(Alibaba group)、Haoxu Wang⋆(Alibaba group)、Zhihao Du⋆(Alibaba group)、Han Zhao⋆(Alibaba group)、Zhifu Gao⋆(Alibaba group)、Xiangang Li⋆(Alibaba group)
- 注:⋆表示Alibaba group,†表示National Mobile Communications Research Laboratory, Southeast University。第一作者和通讯作者基于论文标题下方作者列表顺序及贡献说明(“The first two authors contribute equally to this work.”)判断。
💡 毒舌点评
亮点在于用“表示对齐”模块巧妙地借用了预训练ASR编码器的语义知识来指导自回归模型生成更连贯的语义表示,确实显著加速了收敛并提升了内容一致性(WER大幅下降)。但其声称的“端到端”仍依赖预训练的说话人编码器和ASR编码器进行对齐,且声音克隆的说话人相似度(SS)在英文测试集上反而弱于其主要对比基线CosyVoice,暴露了该架构在全局声学上下文利用上的短板。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开的LibriTTS和内部大规模数据集。内部数据集未提及公开获取方式。
- Demo:未提及在线演示。
- 复现材料:论文详细描述了模型架构、训练数据(规模)、超参数(模型维度、层数、帧率、块大小、采样器设置等)、损失函数构成、评估指标和基线模型,提供了较高的可复现信息。
- 论文中引用的开源项目:引用了Qwen2(文本嵌入)、SenseVoice-Large(ASR编码器)、3D-Speaker(说话人编码器)、HiFTNet(声码器)、Whisper/Paraformer(评估工具)等开源工作。
📌 核心摘要
本文提出了MELA-TTS,一种用于端到端文本到语音合成的联合Transformer-扩散模型框架。其旨在解决离散token方法存在的信息损失和多阶段流水线复杂性问题,以及现有端到端连续特征生成方法在内容一致性和训练收敛速度上的不足。方法的核心是自回归Transformer解码器生成连续向量作为条件,由扩散模型生成梅尔谱图块,并引入表示对齐模块,将Transformer解码器的输出与预训练ASR编码器的语义表示进行对齐,以增强语义一致性。与已往方法相比,新在:1)提出无需离散化的端到端连续特征生成框架;2)提出表示对齐模块作为核心创新,以预训练ASR语义特征作为对齐目标,而非梅尔谱图本身;3)统一支持流式和非流式合成。主要实验结果显示:在LibriTTS消融实验中,表示对齐将WER从6.3降至5.3,并加速训练超过3.3倍;在17万小时大规模数据上,MELA-TTS在测试集test-zh上的CER(0.9)优于使用相同数据的CosyVoice 3.0(1.3),在test-en上的WER(2.4)与DiTAR(1.7)可比,但说话人相似度(SS1/SS2)在英文测试集上低于CosyVoice系列。实际意义是为TTS领域提供了一种有竞争力的、基于连续特征的端到端新范式,特别在内容一致性和训练效率上有所提升。主要局限性是声音克隆的说话人相似度仍有优化空间,作者指出这可能源于扩散模块仅利用局部上下文,无法像多阶段系统那样访问全部历史token。
🏗️ 模型架构
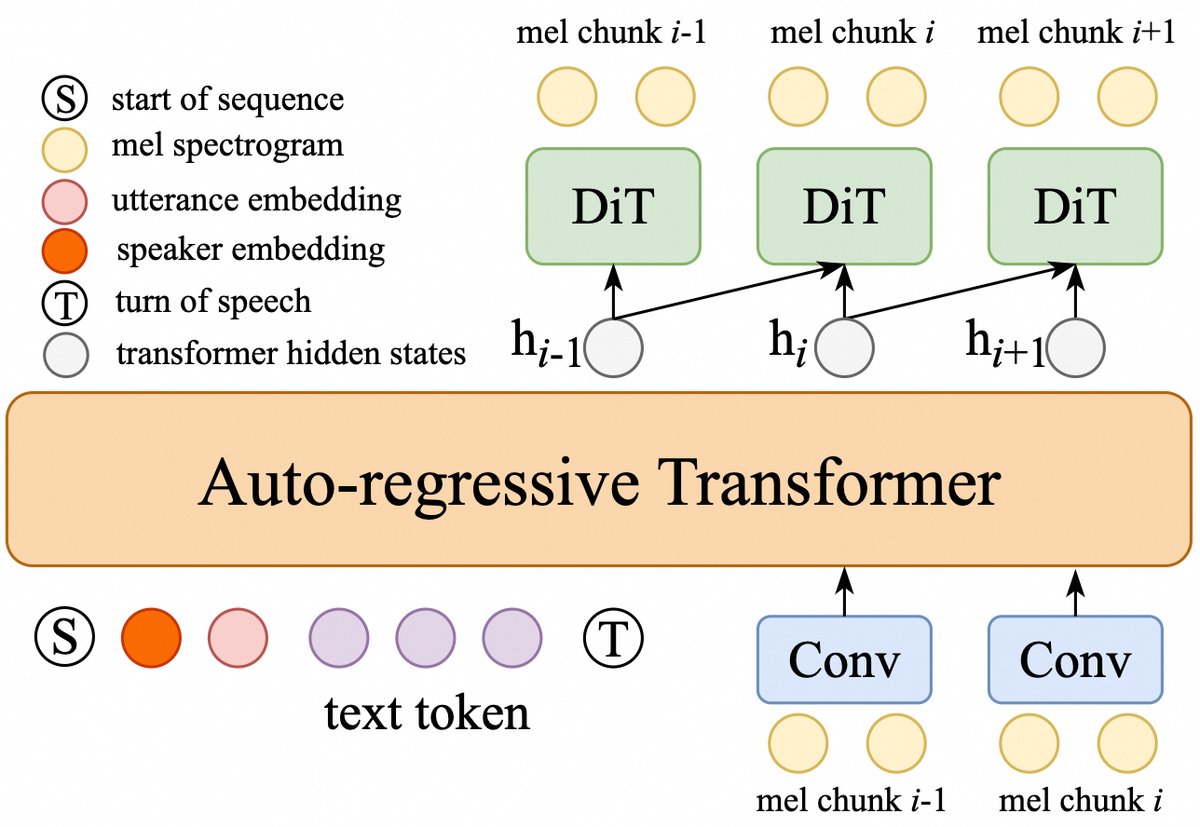
MELA-TTS是一个端到端的文本到语音合成框架,整体架构如图1所示,包含三个核心组件:自回归Transformer解码器、扩散模块和表示对齐模块。
输入输出流程:
- 输入:文本序列(经BPE分词)、参考语音(用于提取说话人嵌入和语句嵌入)。
- 输出:梅尔谱图(mel-spectrogram)块序列,最终由HiFTNet声码器转换为语音波形。
- 核心数据流:文本和参考语音信息经编码后,驱动自回归Transformer解码器按顺序生成连续向量序列
h。向量h作为条件输入扩散模块,扩散模块则对带噪声的梅尔谱图块进行去噪,生成干净的梅尔谱图块。生成是分块(chunk)进行的。
主要组件:
- 自回归Transformer解码器:基于Qwen2-0.5B文本大模型初始化。它按顺序生成连续向量
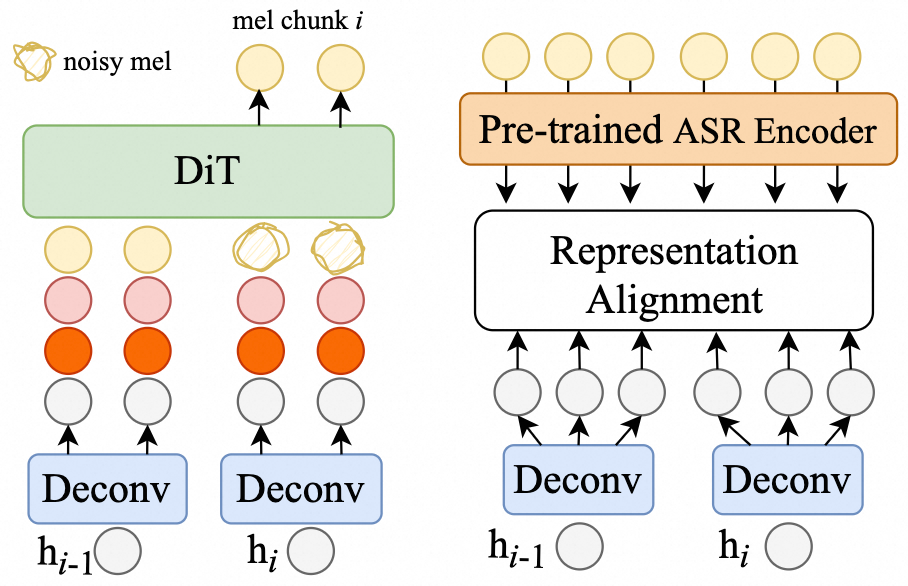
h,条件包括:语句嵌入(Utterance Embedding,从参考语音的随机片段中提取)、说话人嵌入(Speaker Embedding,从参考语音中提取)、文本嵌入(Qwen2的嵌入层输出),以及已生成的梅尔谱图历史(经下采样和投影)。最终层的输出h被送入扩散模块。此外,包含一个停止预测模块,作为二分类器,根据h序列判断何时终止生成。 - 扩散模块:实现为一个扩散Transformer(DiT),共22层,隐藏维度1024,16头。它以
h(具体为当前块和前一块的向量[hi-1, hi])、说话人嵌入v、语句嵌入u以及带噪声的当前梅尔谱图块(并前接前一个干净块)作为条件,预测并去噪生成当前梅尔谱图块X(i)0。训练采用方差保持(VP)前向过程,损失函数为预测值与真实值的L2距离。推理时使用DDIM采样器(NFE=10),并支持无分类器指导(CFG, α=0.7)。 - 表示对齐模块(RAM):如图2右侧所示,这是核心创新模块。它将自回归Transformer解码器的输出
h与预训练ASR编码器(SenseVoice-Large)输出的语义表示hasr进行对齐。由于两者时间分辨率不同(h在6.25Hz,hasr在25Hz),因此引入一个时间对齐模块(TAM),通过线性层和reshape操作将h上采样4倍以匹配hasr。对齐损失为余弦相似度损失Lalign。
- 自回归Transformer解码器:基于Qwen2-0.5B文本大模型初始化。它按顺序生成连续向量
组件交互:Transformer解码器生成语义和韵律信息的骨架(
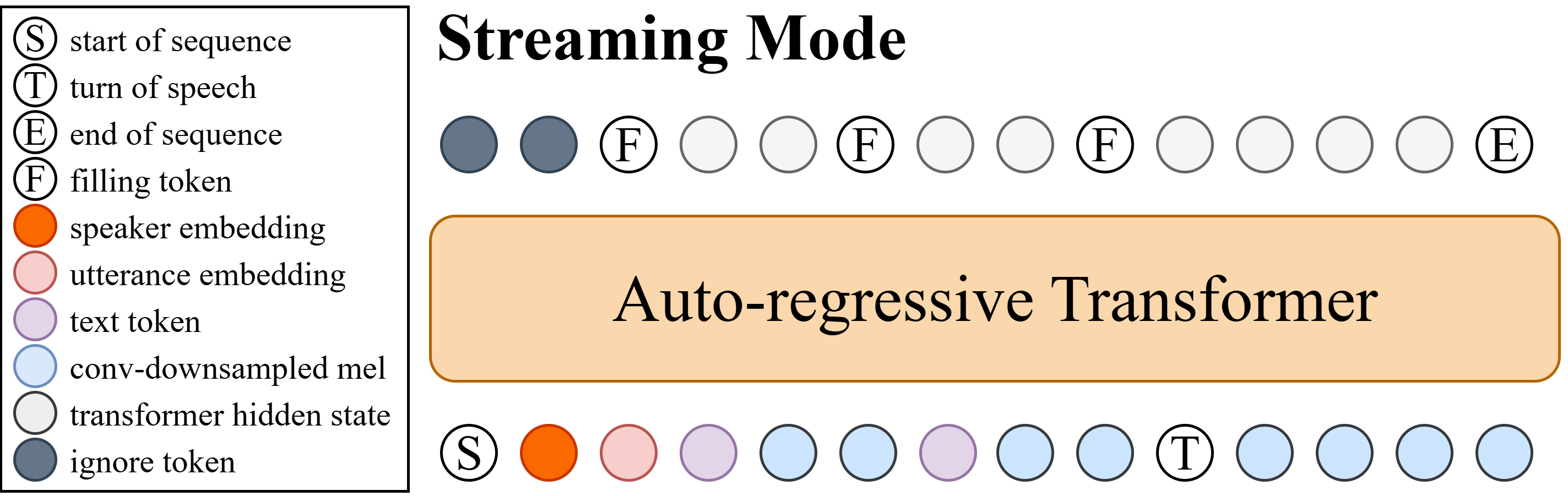
h),RAM在训练时强制该骨架富含语义信息,扩散模型则在该骨架的指导下,负责填充具体的声学细节(梅尔谱图)。这种设计实现了语义建模和声学建模的解耦与协作。流式合成:如图3所示,通过交错文本token和梅尔谱图块(比例n:m=4:3)的训练方式,使单一模型同时支持流式和离流式合成。生成终止由二分类模块控制。
💡 核心创新点
- 端到端的连续特征生成框架:摒弃了离散token的量化步骤和多阶段解码流水线,直接从文本自回归生成梅尔谱图块。这消除了离散化带来的信息损失和系统复杂性,是范式上的一个重要探索方向。
- 表示对齐模块(RAM):这是解决端到端连续生成两大痛点(内容一致性差、训练收敛慢)的关键。创新性地选择对齐目标为预训练ASR编码器的输出(语义表示),而非梅尔谱图本身。实验证明,这一选择至关重要,直接对齐梅尔谱图反而会损害性能。该模块有效引导模型学习语义解耦的表示,加速了收敛。
- 统一的流式/非流式训练与推理:通过交错的训练策略,同一个模型无需修改即可处理完整的离线输入或流式输入,提高了部署灵活性。
- 充分利用预训练大模型:将强大的文本大模型(Qwen2)作为Transformer解码器的初始化,有效利用了其丰富的语言知识,为生成高质量语音提供了基础。
🔬 细节详述
- 训练数据:
- 消融实验:LibriTTS(585小时)。
- 主实验与扩展:内部数据集,总计约170,000小时,包括130k小时中文、30k小时英文、10k小时其他语言。论文未提及具体预处理和数据增强策略。
- 损失函数:总损失
L = Ldiff + Lstop + Lalign。Ldiff:扩散模型的L2损失,用于梅尔谱图去噪。Lstop:停止预测模块的二元交叉熵(BCE)损失。Lalign:表示对齐模块的余弦相似度损失(实际为1-余弦相似度,论文公式中未明确,但通常实现如此)。
- 训练策略:
- 优化器与调度:未明确说明。
- 批量大小、学习率、训练轮数/步数:未说明。
- 硬件:未说明。
- 其他:表示对齐的目标是SenseVoice-Large编码器的输出。在训练时,ASR编码器权重冻结。Transformer解码器与扩散模型、语句嵌入编码器联合优化。
- 关键超参数:
- 音频:24kHz采样率,80维梅尔谱图(50Hz帧率)。
- 块大小:8帧(160ms)。因此自回归Transformer工作在6.25Hz。
- 扩散模块:22层DiT,1024维,16头。
- CFG强度α:0.7。
- DDIM采样步数(NFE):10。
- 流式交错比:n:m=4:3。
- ASR编码器(SenseVoice-Large):输入16kHz波形,128维梅尔谱图,下采样4倍,输出25Hz语义表示
hasr。
- 推理细节:
- 采用DDIM采样器进行确定性采样以加速生成。
- 支持无分类器指导(CFG)以提升生成质量。
- 流式合成中,文本和梅尔谱图块交错输入,生成由停止模块终结。
- 正则化技巧:论文未明确提及Dropout、权重衰减等具体设置。
📊 实验结果
论文在消融实验(LibriTTS)和主实验(170k小时数据)上,评估了内容一致性(WER/CER)和说话人相似度(SS)。
表1:LibriTTS上的消融实验结果(在seed-tts-eval test-en上评估)
| Exp ID | Streaming | Utt Emb | Rep Align | WER ↓ | SS1 ↑ | SS2 ↑ |
|---|---|---|---|---|---|---|
| 0 | ✗ | ✗ | ✗ | 6.3 | 0.46 | 0.55 |
| 1 | ✗ | ✗ | ✓ | 5.3 | 0.46 | 0.54 |
| 2 | ✗ | ✗ | ✓* (对齐梅尔) | 6.7 | 0.41 | 0.48 |
| 3 | ✗ | ✓ | ✗ | 6.0 | 0.47 | 0.57 |
| 4 | ✗ | ✓ | ✓ | 5.2 | 0.48 | 0.58 |
| 5 | ✓ | ✗ | ✗ | 6.6 | 0.46 | 0.55 |
| 6 | ✓ | ✓ | ✓ | 5.0 | 0.48 | 0.58 |
关键结论:
- 表示对齐(Exp 1 vs 0)将WER从6.3降至5.3,并使训练收敛速度提升超过3.3倍(图4)。
- 对齐目标选择至关重要:对齐梅尔谱图(Exp 2)相比对齐ASR表示(Exp 1),WER反而恶化,且SS大幅下降,证实了语义-声学解耦的有效性。
- 语句嵌入(Exp 3 vs 0)主要提升SS。
- 结合两者(Exp 4)达到最优离线性能,显示协同效应。
- 流式模式(Exp 6)与离线模式(Exp 4)性能相当,证明模型鲁棒性。
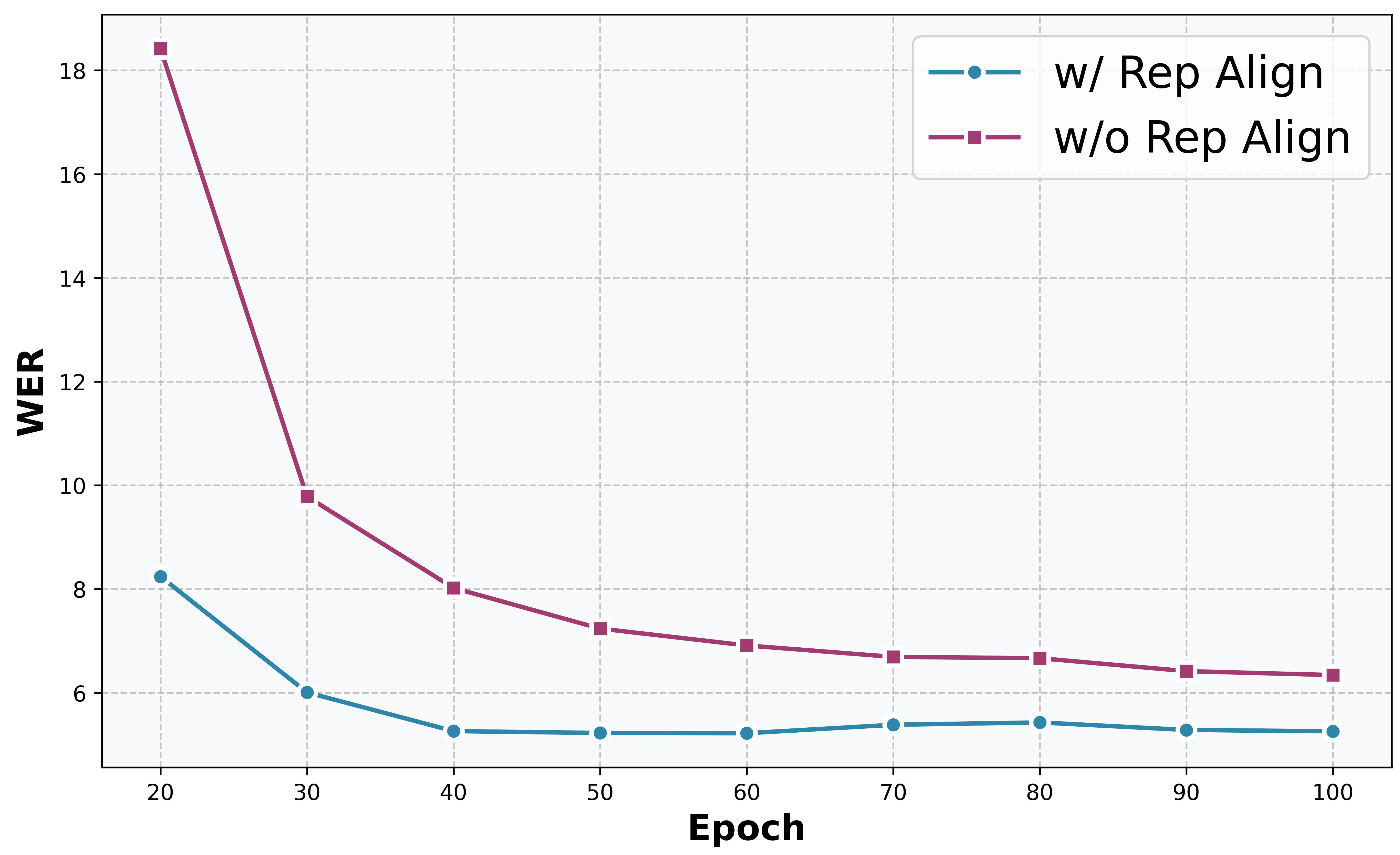
表2:在170k小时数据上的零样本TTS性能对比(在seed-tts-eval上评估)
| 模型 | test-zh | test-en | test-hard |
|---|---|---|---|
| 非自回归模型 | CER↓, SS1↑, SS2↑ | WER↓, SS1↑, SS2↑ | CER↓, SS1↑, SS2↑ |
| F5-TTS | 1.6, 0.74, 0.80 | 1.8, 0.65, 0.74 | 8.7, 0.71, 0.76 |
| MaskGCT | 2.3, 0.77, 0.75 | 2.6, 0.71, 0.73 | 10.3, 0.75, 0.72 |
| 自回归模型 | |||
| Seed-TTS | 1.1, 0.80, - | 2.3, 0.76, - | 7.6, 0.78, - |
| DiTAR | 1.0, 0.75, - | 1.7, 0.74, - | - |
| CosyVoice† | 3.6, 0.72, 0.78 | 4.3, 0.61, 0.70 | 11.8, 0.71, 0.76 |
| CosyVoice 2.0† | 1.5, 0.75, 0.81 | 2.6, 0.65, 0.74 | 6.8, 0.72, 0.78 |
| CosyVoice 3.0-0.5B† | 1.3, 0.75, 0.81 | 2.5, 0.65, 0.75 | 7.0, 0.72, 0.79 |
| MELA-TTS w/o rep align† | 1.2, 0.74, 0.79 | 4.0, 0.60, 0.68 | 10.9, 0.72, 0.78 |
| MELA-TTS w/ rep align† | 0.9, 0.72, 0.77 | 2.4, 0.59, 0.68 | 7.6, 0.71, 0.76 |
| MELA-TTS streaming† | 0.9, 0.72, 0.78 | 2.5, 0.59, 0.68 | 7.7, 0.71, 0.77 |
注:†表示使用相同训练数据。
关键结论:
- 内容一致性:在test-zh和test-hard上,MELA-TTS(w/ rep align)取得了最佳CER(0.9和7.6),显著优于同数据的CosyVoice系列。在test-en上,WER(2.4)接近最强连续生成模型DiTAR(1.7),远优于CosyVoice系列。
- 说话人相似度:在test-zh上与顶尖模型相当,但在test-en和test-hard上(SS1: 0.59, SS2: 0.68)略弱于CosyVoice 3.0(SS1: 0.65, SS2: 0.75)等离散token模型。论文作者将此归因于扩散模块的局部上下文限制。
- 表示对齐有效性:在大规模数据上,加入表示对齐后,CER/WER相对降低了25%-40%,证明了其良好的可扩展性。
- 流式性能:流式模式与离流式模式在各项指标上几乎无差别。
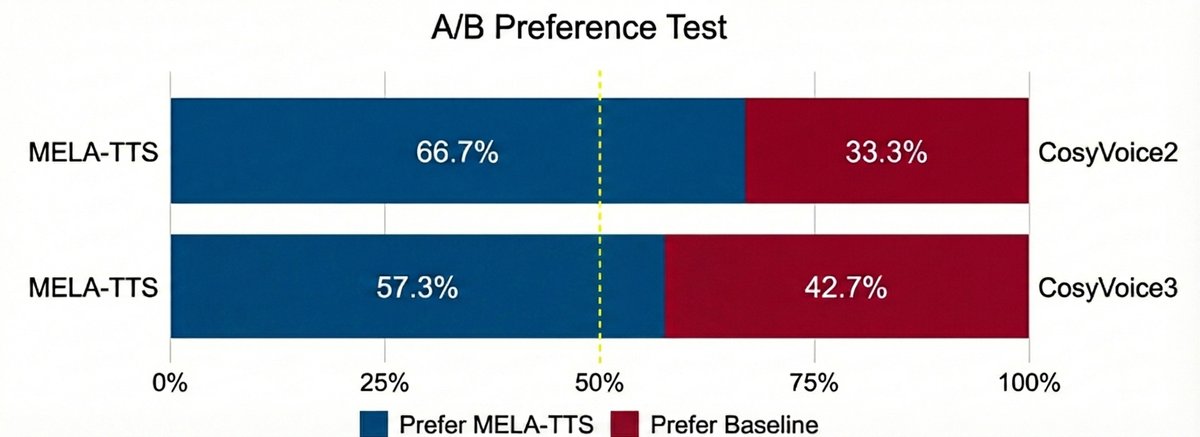
- 主观评价(图5):MELA-TTS在A/B测试中,以66.7%的胜率优于CosyVoice2,以57.3%的胜率优于CosyVoice3。
⚖️ 评分理由
- 学术质量(5.5/7):论文技术路线正确,实验设计全面(消融实验、大规模数据验证、主观客观评测),数据支撑有力。核心创新点“表示对齐模块”设计合理且效果显著。但整体创新属于在连续生成范式上的重要改进,而非颠覆性创新。在说话人相似度上的不足被诚实分析,但也暴露了当前架构的局限。
- 选题价值(1.0/2):TTS是刚需领域,端到端连续生成是重要研究方向。本文工作具有明确的应用价值和工程意义。然而,该赛道竞争激烈,本文是众多优秀工作中的一员,而非开创者。
- 开源与复现加成(0.5/1):论文详细披露了模型配置、数据规模、损失函数、推理设置等关键信息,为复现提供了良好基础。尽管未提及代码和模型公开,但信息的透明度值得肯定。