📄 MECap-R1: Emotion-Aware Policy with Reinforcement Learning for Multimodal Emotion Captioning
#语音情感识别 #强化学习 #多模态模型 #生成模型
✅ 7.5/10 | 前25% | #语音情感识别 | #强化学习 | #多模态模型 #生成模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Haoqin Sun(南开大学计算机科学学院TMCC;阿里巴巴国际数字商务)
- 通讯作者:Yong Qin(南开大学计算机科学学院TMCC)、Haoqin Sun(从邮箱判断,同属上述两机构)
- 作者列表:Haoqin Sun¹,², Chenyang Lyu²,, Xiangyu Kong³, Shiwan Zhao¹, Jiaming Zhou¹, Hui Wang¹, Aobo Kong¹, Jinghua Zhao¹, Longyue Wang², Weihua Luo², Kaifu Zhang², Yong Qin¹, ¹南开大学计算机科学学院TMCC ²阿里巴巴国际数字商务 ³埃克塞特大学
💡 毒舌点评
亮点:该工作巧妙地将DeepSeek-R1中GRPO的思想迁移到情感描述任务,并创新性地设计了“情感锚点空间”来计算奖励,这比简单的规则匹配或BLEU分数更能捕捉情感语义的对齐度,实验也验证了其有效性。短板:所有实验仅在一个中文数据集(EmotionTalk)上进行,且情感锚点的构建严重依赖预定义的离散情绪类别和对应词汇表,这可能限制了模型在更开放、更细微的情感描述上的泛化能力,通用性存疑。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:论文使用了EmotionTalk数据集,并提供了引用信息[12](指向一个arXiv预印本)。论文中未明确说明该数据集是否开源或如何获取。
- Demo:未提及。
- 复现材料:提供了SFT和GRPO阶段的详细超参数设置(学习率、批大小、梯度累积、LoRA秩、KL系数、温度、最大长度等),这属于重要的复现信息。
- 论文中引用的开源项目/模型:Sentence-BERT(shibing624/text2vec-base-chinese)用于构建情感锚点;HuBERT用作音频编码器;基线模型包括BART、GPT-2、Qwen-2、Qwen2.5-Omni、Qwen3-Omni。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:传统的语音情感识别(SER)将情感简化为离散标签,无法捕捉情感的细微差别和丰富语义。新兴的语音情感描述(SEC)任务旨在生成自然语言来描述语音中的情感,但现有方法存在对视觉信息利用不足、以及强化学习方法中奖励机制不完善的问题。
- 方法核心:提出MECap-R1框架,采用两阶段训练。第一阶段是监督微调(SFT)进行冷启动。第二阶段是核心创新:采用组相对策略优化(GRPO)强化学习算法,并设计了情感感知奖励(Emo-GRPO)。该奖励通过构建“情感锚点空间”来衡量生成文本与参考文本在情感语义上的相似度,并与BLEU、SPICE等文本质量指标线性组合成总奖励。
- 与已有方法相比新在哪里:这是首次在SEC任务中系统性地应用GRPO算法和视觉信息。与单纯使用SFT或传统RL(如PPO)的方法相比,Emo-GRPO通过专门的情感锚点奖励,能更精准地引导模型生成情感更准确、更多样化的描述。
- 主要实验结果:在EmotionTalk数据集上,MECap-R1显著优于BART、GPT-2、Qwen系列等基线模型。例如,BLEU-4得分从基线最高3.3提升至7.2,ROUGE-L从53.5提升至54.7,METEOR从26.8提升至29.3。消融实验表明,移除SFT、视频模态或emo-GRPO均会导致性能下降,特别是emo-GRPO对提升描述多样性和准确性至关重要。GPT-4评估的案例(图3)也显示了模型在捕捉细微情感(如“语气升高”、“激动情绪”)上的优势。
- 实际意义:该工作为情感计算提供了一种更精细、更富表现力的情感建模方式,推动了从情感“分类”到“描述”的范式转变,对增强人机交互的同理心和理解能力具有潜在价值。
- 主要局限性:研究仅在单一的中文多模态数据集(EmotionTalk)上进行验证,模型的跨语言、跨场景泛化能力未被评估。情感锚点的构建依赖于预定义的情绪词汇库,对于更开放、更个性化的描述可能存在局限。
🏗️ 模型架构
MECap-R1是一个两阶段训练的文本生成模型,用于根据语音和视频输入生成描述性文本。
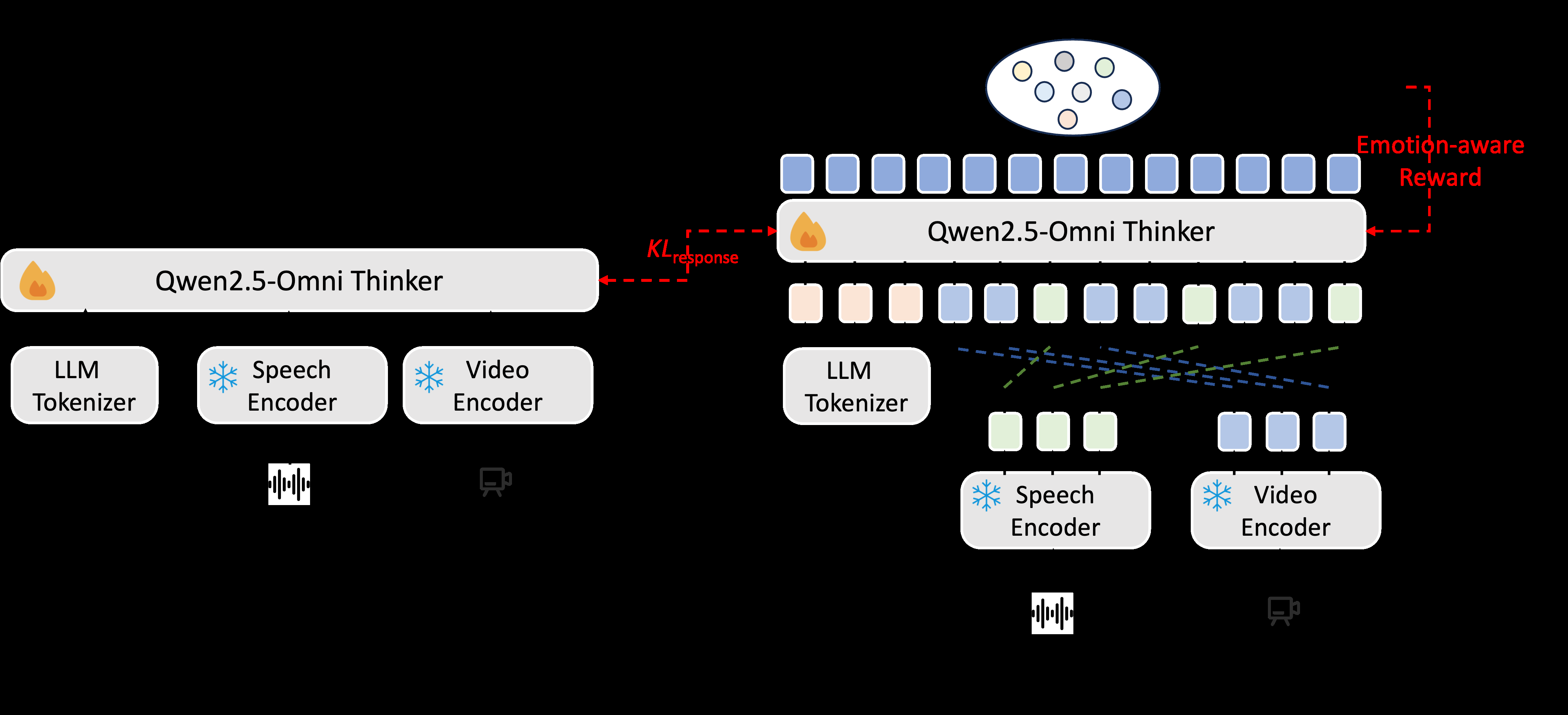 图1:MECap-R1整体框架图。展示了从多模态输入到文本输出的流程,包括SFT预训练阶段和Emo-GRPO强化学习微调阶段。
图1:MECap-R1整体框架图。展示了从多模态输入到文本输出的流程,包括SFT预训练阶段和Emo-GRPO强化学习微调阶段。
完整输入输出流程:
- 输入:多模态上下文
Mi,包含语音(音频)和视频信息。论文中提到使用HuBERT作为编码器处理音频,视觉信息也作为输入的一部分。 - 输出:自然语言文本序列
Yi,是对输入语音中情感的描述性语句。
主要组件与交互:
- 多模态编码器:论文中未详细说明具体架构,但提到使用HuBERT作为音频编码器,并整合了视频信息。其功能是将原始的音频、视频数据转换为模型可处理的嵌入表示。
- 生成器
Gθ:一个自回归语言模型(具体是Transformer解码器结构)。在SFT阶段,它被训练来最大化目标文本序列Yi在给定多模态上下文Mi下的似然概率,通过最小化负对数似然损失L_SFT(公式2)来优化。 - 情感锚点空间(Emotion Anchor Space):这是Emo-GRPO奖励机制的核心。它是一个D维潜在语义空间。
- 情感锚点
ai:对于每个预定义情绪类别Ei,收集一组相关词汇Wi,使用预训练的Sentence-BERT模型(text2vec-base-chinese)将每个词汇映射为D维向量,然后计算这些向量的质心(公式3),得到该情绪的“锚点”向量ai。所有锚点{ai}构成了情绪空间的基底。 - 情绪坐标映射函数
Φ:对于任意文本T,首先用Sentence-BERT将其编码为向量t,然后通过计算t与每个锚点ai的余弦相似度(公式5),将其投影到n维的“情绪坐标空间”,得到向量cT。这个向量的每一维代表文本与对应情绪类别的相关强度。
- 情感锚点
- 奖励函数
R_total:用于在Emo-GRPO阶段指导强化学习。它是两个部分的加权和:R_emo(公式6):计算生成文本Tgen和参考文本Tref在情绪坐标空间中的向量Φ(E(Tgen))和Φ(E(Tref))的余弦相似度。这衡量了情感内容的结构对齐度,而非字面重合。- 文本质量分数:包括
S_BLEU和S_SPICE。 - 总奖励:
R_total = α R_emo + β (S_BLEU + S_SPICE),其中α,β是权重超参数。
- GRPO算法:在第二阶段,生成器
Gθ的策略通过GRPO进行优化。GRPO会生成一组响应,然后根据R_total计算每个响应的奖励,并利用组内相对比较来更新策略,旨在最大化期望奖励,同时保持与SFT模型策略的KL散度约束。
💡 核心创新点
- 情感感知奖励机制(Emo-GRPO):这是最核心的创新。与传统使用固定规则或简单n-gram匹配的奖励不同,本文构建了一个基于语义嵌入的“情感锚点空间”。通过将文本映射到情绪坐标并计算与参考文本的相似度作为奖励,能够更精细、更灵活地评估生成文本在情感语义层面的准确性,直接针对情感描述任务的核心目标。
- 系统性地将GRPO应用于语音情感描述任务:论文首次将源自DeepSeek-R1的GRPO强化学习算法引入SEC任务。相比于常用的PPO,GRPO通过组内比较进行策略更新,更稳定且可能更高效。这一迁移应用为利用强化学习提升生成模型的表达能力提供了新的路径。
- 明确利用多模态信息(特别是视频):论文指出并尝试解决现有SEC方法对视觉信息利用不足的问题。消融实验(“w/o video”)也证实了视频模态对提升生成质量有贡献,尽管具体融合机制未详述。
- 解决描述多样性与准确性的权衡:传统基于规则(如SPICE)的强化学习奖励可能导致输出僵化。情感感知奖励与文本质量奖励的结合,允许模型在保证描述基本准确和流畅的前提下,探索更多样化、更自然的表达方式,这从实验中的词汇多样性(Vocab)提升可以看出。
🔬 细节详述
- 训练数据:
- 数据集:EmotionTalk(参考文献[12])。这是一个由南开大学开发的中文多模态情感数据集。
- 规模:19位专业演员,23.6小时对话,19,250个话语,包含音频、视频、文本三种模态。
- 标注:包含四种类型的情感说话风格标注。
- 预处理/数据增强:论文中未提及具体的预处理步骤或数据增强策略。
- 损失函数:
- SFT阶段:标准的自回归负对数似然损失(公式2)。
- GRPO阶段:使用GRPO算法的损失函数,其优化目标是最大化奖励信号
R_total。具体实现细节(如如何计算损失)论文中未详细说明。
- 训练策略:
- SFT阶段:优化器AdamW,学习率1e-4,批大小1,梯度累积步数2,LoRA秩为8。
- GRPO阶段:批大小1,梯度累积步数4,预热比例0.05。α=β=1。学习率、优化器、LoRA配置与SFT阶段一致。KL系数0.5,最大响应长度2048,温度1.0(表1)。
- 关键超参数:
- 模型大小/架构:未说明(仅提到生成器
Gθ和LoRA的应用)。 - 情感锚点数量
n:未说明(对应情绪类别数)。 - Sentence-BERT嵌入维度D:未说明(取决于所用text2vec-base-chinese模型)。
- 模型大小/架构:未说明(仅提到生成器
- 训练硬件:论文中未提及。
- 推理细节:
- 解码策略:未说明(通常自回归生成会使用采样或束搜索)。
- 表1中提到了GRPO阶段的采样温度为1.0。
- 正则化/稳定训练技巧:在GRPO阶段使用了KL系数(0.5)来约束新策略与旧策略(可能是SFT模型)的偏离,这是强化学习中防止策略退化的常用技巧。
📊 实验结果
主要对比实验(表2):
| 模型 | BLEU1 | BLEU2 | BLEU3 | BLEU4 | ROUGEl | METEOR | SPIDER | Vocab |
|---|---|---|---|---|---|---|---|---|
| BART | - | - | - | 1.8 | 46.9 | 23.3 | 23.0 | - |
| GPT-2 | - | - | - | 1.5 | 46.2 | 21.4 | 22.7 | - |
| Qwen-2 | - | - | - | 3.3 | 53.5 | 26.8 | 12.1 | - |
| Qwen2.5-Omni* | 26.2 | 0.9 | 0.3 | 0.0 | 36.1 | 13.1 | 10.8 | 100 |
| Qwen3-Omni* | 18.5 | 0.4 | 0.0 | 0.0 | 28.8 | 14.5 | 15.9 | - |
| Qwen3-Omni** | 28.4 | 0.6 | 0.0 | 0.0 | 36.8 | 12.6 | 19.2 | - |
| MECap-R1 | 54.6 | 27.0 | 18.1 | 7.2 | 54.7 | 29.3 | 12.8 | 229 |
注:表示零样本,**表示少样本。
- 关键结论:MECap-R1在BLEU-4(7.2 vs 次高3.3)、ROUGE-L(54.7 vs 次高53.5)和METEOR(29.3 vs 次高26.8)等核心生成指标上显著领先所有基线,包括专门训练的BART/GPT-2和强大的零/少样本多模态大模型。在词汇多样性(Vocab=229)上也表现优异。SPIDER分数相对较低,但论文解释其词汇量更大,语言表达更丰富。
消融实验(表2下半部分):
| 模型变体 | BLEU1 | BLEU2 | BLEU3 | BLEU4 | ROUGEl | METEOR | SPIDER | Vocab |
|---|---|---|---|---|---|---|---|---|
| MECap-R1 | 54.6 | 27.0 | 18.1 | 7.2 | 54.7 | 29.3 | 12.8 | 229 |
| w/o SFT | 53.5 | 24.2 | 15.8 | 0.0 | 53.7 | 22.0 | 11.6 | 557 |
| w/o emo-GRPO | 49.9 | 18.3 | 11.1 | 3.5 | 50.5 | 19.5 | 12.7 | 181 |
| w/o emotion-aware reward | 54.6 | 26.6 | 17.7 | 6.6 | 54.6 | 29.1 | 12.7 | 209 |
| w/o video | 53.1 | 25.5 | 16.6 | 5.4 | 53.2 | 27.7 | 11.3 | 209 |
- 关键结论:
- w/o SFT:BLEU-4降为0.0,证明SFT阶段对模型冷启动至关重要。
- w/o emo-GRPO:所有指标显著下降,词汇多样性从229降至181,强有力地证明了GRPO阶段对提升描述质量和多样性的核心作用。
- w/o emotion-aware reward:各项自动指标略有下降,但通过GPT-4评估的“情感重叠度”下降更明显(见下文案例)。这说明情感感知奖励对引导生成更准确的情感描述至关重要。
- w/o video:所有指标均下降,证实视频模态提供了对情感理解有价值的上下文信息。
GPT-4自动情感评估案例(对应图2的评估提示): 论文提供了两个例子(Table 3),对比了移除情感感知奖励(S1)和完整模型(S2)的生成结果。
- 案例1(G00006):S1描述较为笼统(“heightened emotional excitement”),S2则更具体(“tone rises”, “agitated with a forceful tone”),与真实标签(“dissatisfaction”)更接近,情感分数更高。
- 案例2(G00001):S1的描述(“upward inflection indicating urgency”)与真实标签(“calm”)完全矛盾,得分极低;S2的描述(“calm and natural”)则准确匹配,得分高。 图2: pdf-image-page3-idx1 图2:用于GPT-4评估的提示模板。要求模型从情绪重叠、表达丰富度、语气语速分析等方面对生成的描述进行打分和解释。
⚖️ 评分理由
- 学术质量:6.0/7:创新性较强,技术方案设计巧妙,实验对比充分,消融研究深入。主要扣分点在于:1)核心创新(情感锚点)依赖预定义情绪类别和词汇库,通用性受限;2)仅在单一数据集上验证,缺乏跨数据集、跨语言的泛化实验;3)部分技术细节(如多模态编码器具体结构、GRPO的具体损失计算)未充分公开。
- 选题价值:1.5/2:切中了情感计算从离散分类向细粒度描述发展的前沿趋势,对于提升人机交互的丰富度和自然度有明确的应用价值。与语音/音频研究者高度相关。
- 开源与复现加成:0.5/1:论文提供了相当详细的训练超参数和阶段设置,为复现指明了方向。但未提供代码、模型权重,且训练数据集EmotionTalk的获取方式(论文仅引用,未明确说开源)不够清晰,这显著增加了复现门槛。