📄 Meanflow-Accelerated Multimodal Video-to-Audio Synthesis Via One-Step Generation
#音频生成 #流匹配 #音视频 #实时处理
✅ 7.5/10 | 前25% | #音频生成 | #流匹配 | #音视频 #实时处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Xiaoran Yang(武汉大学电子信息学院)
- 通讯作者:Gongping Huang(武汉大学电子信息学院)
- 作者列表:Xiaoran Yang(武汉大学电子信息学院)、Jianxuan Yang(小米MiLM Plus,武汉)、Xinyue Guo(小米MiLM Plus,武汉)、Haoyu Wang(西南财经大学计算机与人工智能学院)、Ningning Pan(西南财经大学计算机与人工智能学院)、Gongping Huang(武汉大学电子信息学院)
💡 毒舌点评
这篇论文的核心亮点是将MeanFlow的一步生成能力成功“移植”到多模态VTA合成任务上,实现了推理速度的数量级提升,这在实际应用中极具吸引力。然而,其短板也相当明显:核心创新组件(MeanFlow和CFG-scaled)均非作者首次提出,论文更偏向于一项有价值的工程集成与任务适配,且消融实验仅探讨了CFG强度和训练配对比例,对于MeanFlow框架如何具体适配多模态条件融合的机制剖析不够深入。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:训练和评估所用数据集(VGGSound, Kling-Audio-Eval, AudioCaps, WavCaps)均为公开数据集,但论文未说明是否提供其处理后的版本。
- Demo:未提及。
- 复现材料:论文提供了详细的训练配置(优化器、学习率、batch size、训练步数)、超参数设置(模型层数、采样率、时间步采样分布)、硬件环境(8x H800 GPU)和评估指标说明,为复现提供了较好的基础。
- 引用的开源项目/模型:CLIP、Synchformer、VAE(具体模型未说明)、MMAudio、MeanFlow、CFG-Zero。
- 总结:论文中未提及开源计划。
📌 核心摘要
要解决什么问题:现有的基于流匹配的视频到音频(VTA)合成方法依赖多步迭代采样,导致推理速度慢,难以满足实时应用需求。同时,一步生成场景下应用分类器引导(CFG)容易因缺乏迭代修正而产生过冲和失真。
方法核心是什么:提出MeanFlow加速的多模态联合训练框架(MF-MJT)。核心是在多模态联合训练的骨干网络(基于MMAudio)上,采用MeanFlow公式建模平均速度场,从而支持原生一步生成。为稳定CFG,引入标量缩放机制(CFG-scaled),动态调整无条件预测的权重。
与已有方法相比新在哪里:相比之前建模瞬时速度的方法(需多步积分),MF-MJT建模平均速度,实现了原生一步生成。相比其他一步生成方法(如Frieren依赖多阶段蒸馏),MF-MJT通过MeanFlow公式直接支持一步推理。同时,针对一步生成场景提出了CFG-scaled机制来平衡引导质量。
主要实验结果如何:在VGGSound测试集的VTA任务上,MF-MJT一步生成(RTF=0.007)相比Frieren(RTF=0.015)在分布匹配(FAD↓1.46 vs 1.87)、音频质量(IS↑9.39 vs 9.14)等指标上均更优,速度提升一倍以上。在AudioCaps测试集的TTA任务上,MF-MJT一步生成(RTF=0.007)在FAD(↓2.29)、FD(↓21.32)等指标上优于AudioLCM(RTF=0.016)。关键结果见下表:
表1:VGGSound测试集VTA合成结果(一步生成)
方法 FAD ↓ FD ↓ KL ↓ IS ↑ IB ↑ DeSync ↓ RTF ↓ Frieren (1-step) 1.87 16.64 2.56 9.14 21.92 0.85 0.015 MF-MJT (ours) 1.46 11.14 1.87 9.39 21.78 0.86 0.007 表2:AudioCaps测试集TTA合成结果(一步生成)
方法 FAD ↓ FD ↓ IS ↑ CLAP ↑ RTF ↓ AudioLCM (1-step) 4.24 23.16 7.13 0.19 0.016 MF-MJT (ours) 2.29 21.32 6.50 0.20 0.007 实际意义是什么:实现了VTA合成的高效推理(RTF=0.007),为实时视频配音、交互式多媒体内容生成等应用提供了可行的技术方案,并展示了联合训练框架在VTA和TTA任务上的通用性。
主要局限性是什么:方法的性能高度依赖MeanFlow框架本身,创新集成性质较强;消融实验主要集中在CFG强度和训练数据配对比例上,对多模态条件与MeanFlow结合的具体机制探讨较少;论文未提供开源代码或模型。
🏗️ 模型架构
MF-MJT的架构(如图2所示)建立在多模态联合训练骨干之上,主要包含三个阶段:
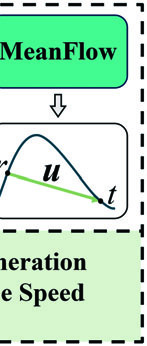 图2:MF-MJT的模型架构图。展示了从多模态输入到输出平均速度场的完整流程。
图2:MF-MJT的模型架构图。展示了从多模态输入到输出平均速度场的完整流程。
多模态条件编码与投影:
- 输入包括视频、文本和音频(训练时为潜在表示,推理时为噪声)。
- 视觉编码:使用预训练的CLIP视觉编码器提取视频特征
Fv(每帧一个token,8 fps),以及Synchformer视觉编码器提取同步特征Fsync(24 fps,768维)。 - 文本编码:使用预训练的CLIP文本编码器提取文本特征
Ft(77 tokens,1024维)。 - 音频处理:使用预训练的VAE将音频转换为潜在表示
x(20维)。在训练时输入x,在推理时输入随机噪声。 - 所有模态的特征经过投影层映射到统一的潜在空间。
多模态扩散Transformer(MM-DiT)融合:
Fv,Ft,Fsync以及时间步嵌入(t,Δt)被送入N1=4个MM-DiT块。- MM-DiT块的核心是跨模态注意力层,允许视频、文本和音频特征之间进行交互与对齐,形成统一的语义表示。
- MM-DiT块的输出被分割回三个模态的特征。
音频专用扩散Transformer(DiT)精炼与输出:
- 音频分支的特征被送入
N2=8个音频专用的DiT块。 - 在这些DiT块中,跨模态注意力被替换为自注意力,专注于精炼音频自身的表征,以提升音频细节和质量。
- 最终,精炼后的音频特征通过自适应层归一化(Adaptive Layer Norm)和一个1D卷积层,输出预测的平均速度场
uθ。
- 音频分支的特征被送入
关键设计选择:
- 采用“先融合后精炼”的两阶段设计:MM-DiT负责跨模态对齐,DiT负责音频细节生成。
- 使用Synchformer特征显式增强音视频同步性。
- 输出为平均速度场
uθ(对应MeanFlow公式中的u(zt, r, t)),而非传统流匹配的瞬时速度场vθ,这是实现一步生成的关键。
💡 核心创新点
将MeanFlow引入多模态VTA合成实现原生一步生成:
- 局限:传统流匹配方法建模瞬时速度,需迭代求解ODE,推理慢。
- 创新:采用MeanFlow公式(公式3-6),直接学习平均速度场。推理时可直接用公式
z0 = z1 - u(z1, 0, 1)一步生成,无需迭代。 - 收益:实现了推理速度的质变(RTF降至0.007),同时通过实验(图3, 图4)证明在一步设置下保持了高质量和强对齐。
提出CFG-scaled机制稳定一步生成中的CFG:
- 局限:一步生成缺乏迭代修正,标准CFG(公式7)在高引导强度下易导致过冲和失真。
- 创新:引入缩放标量
s(公式8-9),动态调整无条件预测分量的权重,使其方向与条件预测更对齐。 - 收益:在一步生成设置下,��同引导强度(ω)下,CFG-scaled的音频质量(IS)均优于标准CFG(图3a),证明了其稳定性。
基于多模态联合训练的统一框架,兼顾VTA与TTA任务:
- 局限:许多VTA模型需要依赖预训练的TTA模型,灵活性受限。
- 创新:构建从头联合训练视频、音频、文本模态的端到端框架(基于MMAudio),使模型同时具备VTA和TTA能力。
- 收益:无需微调即可在TTA任务(AudioCaps)上取得优异表现(表2),证明了统一语义空间的有效性和模型的泛化能力。
🔬 细节详述
- 训练数据:
- VTA数据:VGGSound (~500小时,音视频文本三元组), Kling-Audio-Eval (~58小时,音视频文本三元组)。
- TTA数据:AudioCaps (~128小时, 音频文本对), WavCaps (~7600小时, 音频文本对)。在TTA数据中,视频特征
Fv和同步特征Fsync使用空标记∅v和∅sync代替。 - 评估集:VGGSound测试集 (15,216样本, VTA), AudioCaps测试集 (4,227样本, TTA)。
- 损失函数:
- MeanFlow损失函数(公式5):
LMF(θ) = Er,t,x,ε[ || uθ(zt, r, t) - sg(utgt) ||²₂ ], 其中utgt是基于真实速度场和当前预测uθ计算的目标平均速度。当r=t时,退化为标准流匹配损失。
- MeanFlow损失函数(公式5):
- 训练策略:
- 优化器:AdamW (β1=0.9, β2=0.95)。
- 学习率:峰值
2e-4, 1000步warmup, 250k步衰减至2e-5, 350k步衰减至2e-6。 - 权重衰减:
1e-6。 - 总步数:400,000步。
- 批量大小:每GPU 64, 共8张NVIDIA H800 GPU。
- 关键超参数:
- 模型参数量:157M。
- MM-DiT块数
N1:4; 音频DiT块数N2:8。 - 音频采样率:31.25 fps, 潜在维度:20。
- 时间步
(r, t)采样:来自逻辑正态分布 (μ=-2.0, σ=2.0), 且r≤t。训练时r≠t的比例为10%。
- 推理细节:
- 一步生成:固定
(r, t) = (0, 1)。 - CFG强度
ω:一步生成为1.5, 多步生成为4.5。 - 推理时,音频输入为随机噪声
ε ∼ N(0,1)。 - 支持可变长度音频生成(如VGGSound 8秒, AudioCaps 10秒),因未使用绝对位置编码。
- 一步生成:固定
📊 实验结果
论文在VTA和TTA任务上进行了全面的基线对比和消融实验。
- 主要对比实验(VTA任务 - VGGSound测试集)
 表1(论文中):VGGSound测试集VTA合成方法性能对比。MF-MJT(一步)在FAD、FD、KL、IS和RTF上达到最佳或次佳。
表1(论文中):VGGSound测试集VTA合成方法性能对比。MF-MJT(一步)在FAD、FD、KL、IS和RTF上达到最佳或次佳。
关键结论:
- 效率:MF-MJT一步生成的RTF为0.007,是Frieren(0.015)的2倍以上,是MMAudio(0.098)的14倍,显著领先。
- 质量:在一步生成设置下,MF-MJT在分布匹配(FAD↓1.46, FD↓11.14)和音频质量(IS↑9.39)上优于Frieren。在多步设置下,MF-MJT在KL↓1.59和IS↑16.55上达到最佳,整体与MMAudio竞争力强。
- 对齐与同步:IB分数和DeSync分数与最强基线相当。
- 主要对比实验(TTA任务 - AudioCaps测试集)
 表2(论文中):AudioCaps测试集TTA合成方法性能对比。MF-MJT(一步)在FAD和FD上大幅领先AudioLCM。
表2(论文中):AudioCaps测试集TTA合成方法性能对比。MF-MJT(一步)在FAD和FD上大幅领先AudioLCM。
关键结论:
- 效率:MF-MJT一步生成RTF=0.007, 优于AudioLCM的0.016。
- 质量:MF-MJT(一步)在FAD(↓2.29)和FD(↓21.32)上显著优于AudioLCM(FAD↓4.24, FD↓23.16)。在多步设置下,MF-MJT与MMAudio性能接近,在FD和CLAP上略优。
- 消融实验
- CFG策略消融(图3):对比了标准CFG(CFG-stand)和提出的CFG-scaled。
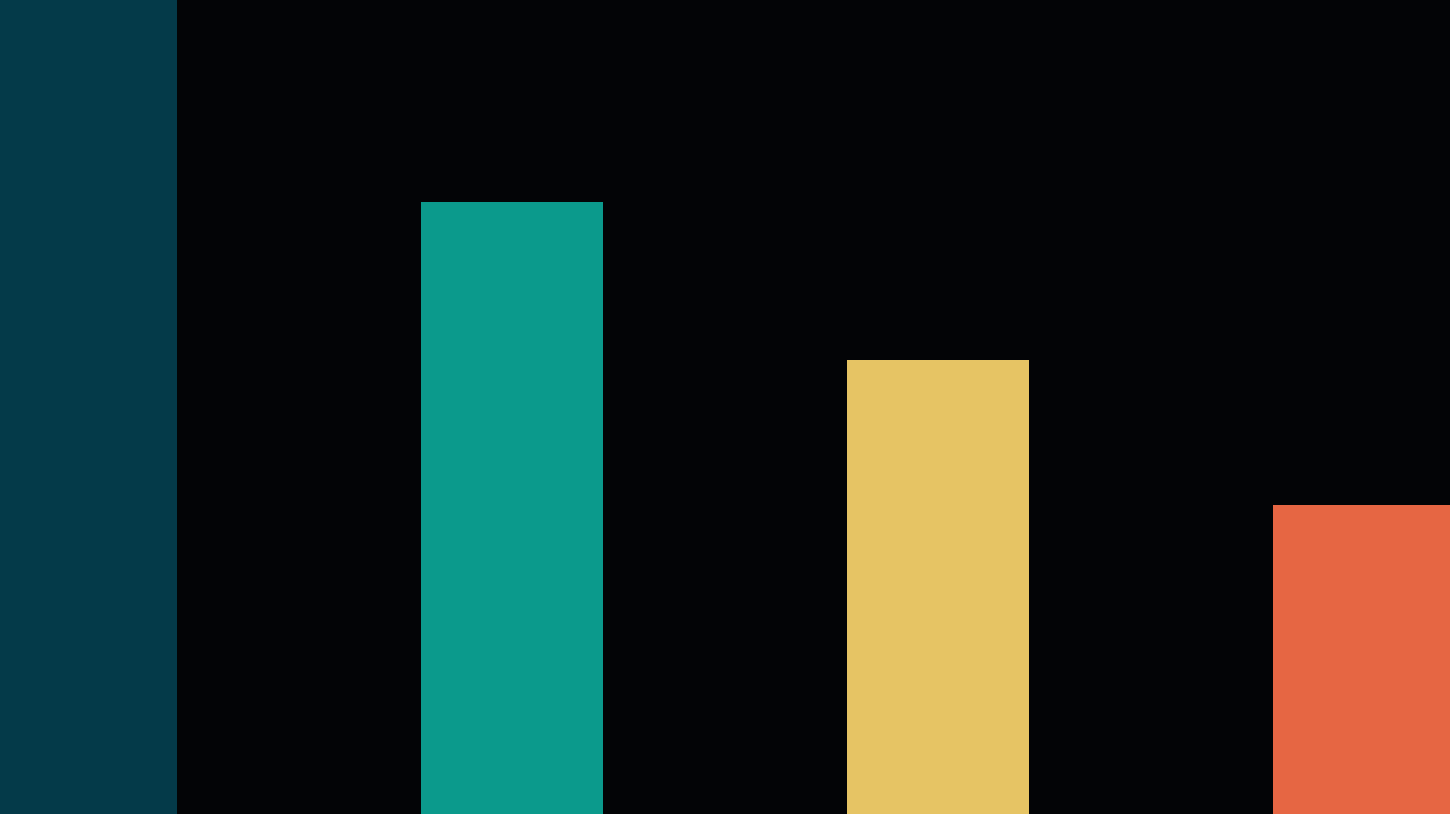 图3a:一步生成下,IS分数随CFG强度ω变化。CFG-scaled在所有ω>1时均优于CFG-stand,且随着ω增加下降更缓。
图3a:一步生成下,IS分数随CFG强度ω变化。CFG-scaled在所有ω>1时均优于CFG-stand,且随着ω增加下降更缓。
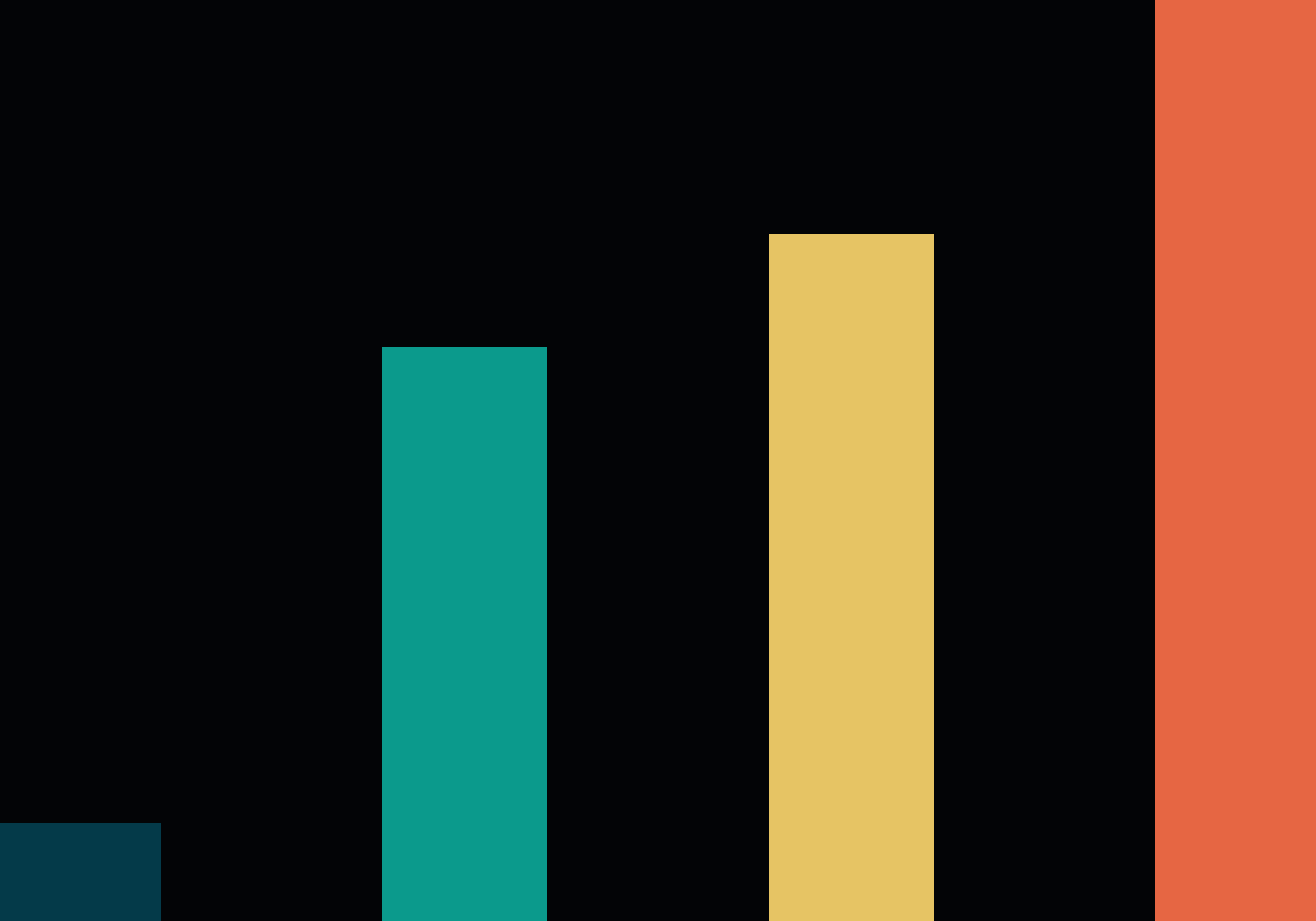 图3b:多步生成下,IS分数随CFG强度ω变化。趋势与一步生成不同,多步生成下更高ω带来更好质量。
图3b:多步生成下,IS分数随CFG强度ω变化。趋势与一步生成不同,多步生成下更高ω带来更好质量。- 结论:在一步生成中,CFG-scaled能有效缓解过冲,在更高引导强度下保持更好的感知质量(IS)。
- 训练中r≠t比例消融(图4):研究了训练时
r≠t采样对的比例对性能的影响。 图4:不同r≠t比例对IB分数(语义对齐)和DeSync分数(时间同步)的影响(一步生成, ω=1.5)。
图4:不同r≠t比例对IB分数(语义对齐)和DeSync分数(时间同步)的影响(一步生成, ω=1.5)。- 结论:更低的
r≠t比例(如10%)能带来更好的语义对齐(IB↑)和时间同步(DeSync↓)。这表明在平均速度场学习中,提供与r=t对应的直接点对点监督信号对跨模态对齐至关重要。
- 结论:更低的
⚖️ 评分理由
- 学术质量:6.0/7:论文问题定义清晰,方法逻辑严谨,实验设计全面且对比充分,结果令人信服。主要扣分点在于核心技术创新(MeanFlow, CFG-scaled)并非作者首次提出,论文的贡献在于将这些技术有效组合并适配到多模态VTA合成任务中,属于扎实的系统改进而非基础突破。
- 选题价值:1.5/2:选择推理效率这一关键瓶颈进行优化,具有明确的实际应用价值。VTA合成是前沿热点,加速推理能直接推动该技术的实用化。与音频/语音读者的相关性较高。
- 开源与复现加成:0.0/1:论文未提及任何开源代码、模型权重或在线演示。虽然提供了详尽的训练细节,有利于复现,但无实际开源资源释放,因此该项加分为0。