📄 Matching Reverberant Speech Through Learned Acoustic Embeddings
#音频生成 #信号处理 #空间音频 #实时处理
🔥 8.0/10 | 前25% | #音频生成 | #信号处理 | #空间音频 #实时处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Philipp Götz(International Audio Laboratories Erlangen†,Germany)
- 通讯作者:未说明
- 作者列表:Philipp Götz(International Audio Laboratories Erlangen†,Germany)、Gloria Dal Santo(Acoustics Lab, Dpt. of Information and Communications Engineering, Aalto University,Finland)、Sebastian J. Schlecht(Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU),Germany)、Vesa Välimäki(Acoustics Lab, Dpt. of Information and Communications Engineering, Aalto University,Finland)、Emanuël A. P. Habets(International Audio Laboratories Erlangen†,Germany) †International Audio Laboratories Erlangen是Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU)和Fraunhofer IIS的联合机构。
💡 毒舌点评
亮点在于将混响参数盲估计任务巧妙重构为“信号匹配”问题,并利用一个改进的、可微分的FDN结构(尤其是可学习的正交反馈矩阵)显著提升了合成混响在声学参数(如T30)上的准确性。然而,论文的短板在于其对混响早期反射模式的建模能力有限,且当前评估主要局限于语音信号,对音乐等激励源下的泛化能力以及噪声鲁棒性未做充分验证。
🔗 开源详情
- 代码:论文中提及了用于可微分信号处理的开源Python库FLAMO,并提供了GitHub链接(https://github.com/gdalsanto/flamo)。但未明确提供本论文完整方法的训练代码仓库链接。
- 模型权重:未提及是否公开模型权重。
- 数据集:使用了多个公开的RIR和语音数据集(EARS, ACE, ASH-IR等),并提供了获取方式的参考文献,但未提供本实验专用合并数据集的下载链接。
- Demo:提供了在线音频示例链接(https://www.audiolabs-erlangen.de/resources/2026-ICASSP-RMS)。
- 复现材料:论文中给出了模型各组件的参数量(如VAE:393K,语音编码器:1.475M,参数估计器:573K),关键训练设置(优化器、学习率调度、早停策略),以及FDN的具体参数(N, J, m等),复现信息较为充分。
- 论文中引用的开源项目:FLAMO库(用于不同iable FDN实现)。
📌 核心摘要
- 问题:在听觉增强现实(AAR)系统中,如何在没有预先测量声学环境信息的情况下,实时生成逼真的混响,是实现沉浸感的关键挑战。
- 方法核心:提出一个两阶段框架。第一阶段训练一个VAE学习房间脉冲响应(RIR)的“声学先验”嵌入空间。第二阶段训练一个语音编码器,从混响语音中提取嵌入,使其接近该先验。最后,训练一个参数估计网络,从该嵌入直接预测一个可微分反馈延迟网络(FDN)的参数,以合成目标混响。
- 新在哪里:将盲参数估计重新定义为“混响信号匹配”任务。提出了一个比先前工作更灵活的可微分FDN结构,其特点包括:使用每个延迟线独立的衰减滤波器(而非共享)、可训练的正交反馈矩阵、以及明确建模直达声与混响能量比。同时引入了稀疏性正则化以提升听感。
- 实验结果:与领先的基线ARP-net相比,所提方法在七个八度频带上的混响时间(T30)平均绝对百分比误差和清晰度指数(C50)平均绝对误差均更低(误差分布如图4所示),T30的皮尔逊相关系数(PCC)显著更高。在感知真实性上,所提方法生成的混响语音的Fréchet音频距离(FAD)为0.109,远低于基线的0.523(见下表)。
方法 FAD (↓) 提出的方法 0.109 ARP-net [17] 0.523 - 实际意义:该方法为AAR等应用提供了一种高效、模块化且感知一致的实时混响渲染方案,无需预先测量或用户输入环境信息。
- 局限性:论文承认对早期反射模式的捕捉不够精确,且评估主要基于语音信号,未来需在音乐信号和噪声环境下进行更严格的评估与分析。
🏗️ 模型架构
整体是一个三部分组成的级联系统,如图1所示。

- 房间声学先验模块(图1蓝色部分):一个变分自编码器(VAE)。编码器 E_H,φ 将RIR的梅尔频谱图(H)编码为一个低维潜在向量z_H(均值μ_ϕ和方差Σ_ϕ)。解码器 D_H,θ 从潜在向量重构RIR频谱图。其目标是通过优化证据下界(ELBO)来学习RIR的紧凑表示。
- 混响语音嵌入模块(图1绿色部分):编码器 E_Y,ψ 接收混响语音的梅尔频谱图(Y)和对应的无回声语音频谱图(X),输出一个潜在向量z_Y(均值μ_ψ)。其训练目标是最小化q_ψ(z_Y | H, X)与RIR后验q_ϕ(z_H | H)之间的KL散度,从而使得语音编码器能忽略语音内容,仅捕获声学环境信息。
- 参数估计与合成模块(图1红色部分):一系列浅层MLP(回归模型 F),以语音嵌入μ_ψ为输入,分别预测可微分FDN的各项参数(见式6)。预测的参数(如反馈矩阵U、衰减滤波器Γ(z)的控制参数等)被送入可微分FDN,对无回声语音x[t]进行混响处理,生成合成的混响语音ŷ[t]。
可微分FDN结构(图2):其传递函数由式(5)定义。与传统设计不同,本FDN的每个延迟线都连接着一个独立的、可学习的图形均衡器(GEQ)作为衰减滤波器Γ_i(z),而非共享一个滤波器。混合矩阵U通过正交映射(式(27))参数化以保证稳定性。直达声由增益g和短延迟m_d建模。音色校正滤波器T(z)用于匹配目标RIR的初始频谱包络。整个FDN基于FLAMO库在频域中实现。

💡 核心创新点
- 信号匹配范式:将传统“从混响语音估计RIR”的任务,重新定义为“从混响语音预测参数,使FDN合成信号与原始混响信号匹配”。这使得模型可以专注于优化最终听感,而非中间表示的精确性。
- 增强的FDN结构:改进了前人(���ARP-net)的FDN设计。a) 独立的衰减滤波器:允许为每个延迟线建模不同的频率衰减特性,更灵活地匹配复杂RIR。b) 可训练的正交反馈矩阵:相较于固定的Householder矩阵,提供了更好的扩散性能和优化灵活性。
- 模块化多阶段框架:将流程解耦为“先验学习”、“嵌入提取”和“参数估计”三个阶段。这增加了系统的可解释性和模块化程度(如图3所示),允许独立评估每个阶段的质量。

- 稀疏性正则化:在训练参数估计器时,引入反馈矩阵的稀疏性惩罚项L_U,以鼓励更密集的反馈连接,从而加快回声密度的建立,获得更平滑的混响尾音。
🔬 细节详述
- 训练数据:使用了EARS无回声语音数据集,并与来自ACE, ASH-IR, Multi-Room Transition等11个公开RIR数据集中的RIR进行卷积。训练、验证、测试集互斥。生成了约18小时4秒长、48kHz采样的混响语音片段。RIR经过能量归一化和起始时间移除,频谱图标准化为零均值单位方差。假设无背景噪声。
- 损失函数:
- L_H (式2):VAE的训练目标,为KL散度与重构损失的加权和。
- L_Z (式4):语音编码器的训练目标,为两个高斯分布间的KL散度解析解。
- L_Y (式7):参数估计器的核心损失,是多分辨率梅尔频谱图间的均方误差。
- L_U:对反馈矩阵U施加的稀疏性惩罚(论文中未给出具体公式,仅描述其目的)。
- 总损失 L₃:L₃ = L_Y + λL_U,其中λ为权重系数(论文未给出具体值)。
- 训练策略:所有模型使用AdamW优化器(解耦权重衰减)和学习率调度策略。采用早停法(耐心16个epoch),选择验证损失最低的模型。
- 关键超参数:
- VAE维度 D:未明确说明具体数值,但从上下文推断为较小维度(如128或256)。
- FDN延迟线数量 N = 8。
- GEQ段数 J = 11(包含9个峰、2个搁架)。
- 延迟线长度 m:[809, 877, 937, 1049, 1151, 1249, 1373, 1499] 样本(互质,对数分布)。
- 采样率:48 kHz。
- 训练硬件:论文中未提及。
- 推理细节:给定一段混响语音,经过语音编码器得到嵌入μ_ψ,再由参数估计器F直接预测出FDN的一组参数P,最后用这些参数对输入的无回声语音进行FDN处理,得到输出。
- 正则化/稳定训练:a) 对反馈矩阵U使用正交映射(式27)确保稳定性。b) 对GEQ参数p_T, p_Γ使用tanh和sigmoid激活函数限制在特定范围内。c) 引入L_U稀疏性惩罚改善听感。
📊 实验结果
主要对比基线为ARP-net [17]。
声学参数对比(图4):
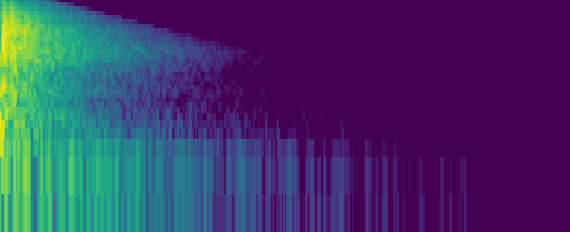
- T30和C50误差:顶部的箱线图/误差分布图显示,在所有八度频带上,所提方法的误差分布更紧凑、中位数更接近零,表明其估计更准确。
- 皮尔逊相关系数(PCC):底部的折线图显示,所提方法在T30上的PCC(蓝色实线)显著高于ARP-net(蓝色虚线),在500Hz-2kHz范围内尤为明显。在C50上,两者PCC接近,但所提方法略优。
感知真实性对比(表1):
| 方法 | FAD (↓) |
|---|---|
| 提出的方法 | 0.109 |
| ARP-net [17] | 0.523 |
| FAD值越低表示生成的音频与真实音频分布越接近。所提方法的FAD值(0.109)远低于基线(0.523),表明其合成的混响语音在感知上更真实。 |
定性结果(图3):
- 图3(a)是真实RIR频谱图。
- 图3(b)是VAE从RIR编码再解码的重构,显示先验模型能较好地捕获RIR的整体能量衰减和频谱特性。
- 图3(c)是从混响语音嵌入解码出的RIR近似,显示了语音编码器能有效提取环境声学特征。
- 图3(d)是所提FDN合成的RIR频谱图,与(a)在能量衰减模式上高度相似,直观证明了方法的有效性。
⚖️ 评分理由
- 学术质量:6.0/7:论文贡献清晰(新范式、改进FDN),技术路线正确,实验对比充分(定量指标+定性可视化),数据规模合理。但创新属于对现有技术的改进与组合,未提出根本性新理论,且部分实验细节(如λ值)未公开。
- 选题价值:1.5/2:研究针对AAR这一新兴且重要的应用场景,解决其核心痛点,具有明确的实用价值和前沿性。但领域相对细分。
- 开源与复现加成:0.5/1:提供了关键的开源工具库(FLAMO)和示例,详细描述了网络结构、数据预处理、损失函数,极大地方便了复现。但未提及训练代码和预训练权重的发布,数据集虽公开但未提供专用下载链接。