📄 Marco-Voice: A Unified Framework for Expressive Speech Synthesis with Voice Cloning
#语音合成 #语音克隆 #流匹配 #情感合成 #数据集
🔥 8.0/10 | 前25% | #语音合成 | #流匹配 | #语音克隆 #情感合成
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文作者列表未按顺序注明第一作者)
- 通讯作者:Chenyang Lyu(标注为)
- 作者列表:Fengping Tian, Peng Bai, Xuanfan Ni, Haoqin Sun, Qingjuan Li, Zhiqiang Qian, Chenyang Lyu*, Haijun Li, Longyue Wang, Zhao Xu, Weihua Luo, Kaifu Zhang
- 机构列表:Alibaba International Digital Commerce(阿里巴巴国际数字商业)
💡 毒舌点评
亮点:该工作最大的亮点在于将“说话人身份”与“情感表达”的解耦做到了一个相当精细和可控的程度,通过旋转嵌入、正交约束等系列“组合拳”,不仅理论动机清晰,实验效果(尤其是说话人相似度和情感表达分数)也远超基线,且贡献了宝贵的中文情感语音数据集。短板:其创新更多是模块化组合的“系统工程”优势,对每个单独模块(如对比学习、交叉注意力)的分析深度相对有限,且情感类别的准确率(最高0.75)仍有提升空间,表明对复杂情感的建模仍是难点。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/AIDC-AI/Marco-Voice
- 模型权重:论文中未明确提及是否公开预训练模型权重。
- 数据集:公开了自行构建的CSEMOTIONS数据集,获取链接:https://huggingface.co/datasets/AIDC-AI/CSEMOTIONS
- Demo:论文中未提及在线演示链接。
- 复现材料:提供了详细的实现细节,包括模型基于CosyVoice1实现、训练硬件(8xA100)、优化器设置(Adam, 不同模块不同学习率)、批大小(32/GPU)、关键超参数选择(如N=10)等。未提供预训练配置文件或检查点说明。
- 论文中引用的开源项目/模型:CosyVoice1/2(基线系统),emotion2vec(情感特征提取器),Whisper(用于WER计算)。
📌 核心摘要
- 解决的问题:现有语音合成系统难以独立、高质量地控制“说话人身份”和“情感表达”,两者容易纠缠,且缺乏高质量的中文情感语音数据。
- 方法核心:提出Marco-Voice统一框架,核心是旋转情感嵌入(通过情感/中性语音对差分向量构建)、说话人-情感正交解耦与批内对比学习(强制特征空间分离),以及在流匹配模型中引入情感与语音token的交叉注意力进行深度融合。
- 与已有方法相比新在何处:不同于以往将说话人和情感编码器分离的模块化方法,Marco-Voice通过一个统一的语言模型和流匹配模型,利用上述解耦与融合技术,在一个框架内实现了高质量、高可控的克隆与情感合成。
- 主要实验结果:
- 主实验(主观评价):在语音克隆任务上,Marco-Voice在所有指标上超越CosyVoice1和2,说话人相似度(SS)达到0.828。在情感语音合成任务上,情感表达(EE)得分4.225,整体满意度(OS)4.430。
- 消融实验:逐步添加各模块(v1-v4),WER在英文(LibriTTS)数据集上从12.1降至11.4,DNS-MOS保持竞争力。情感准确率在中/英文上分别达到约0.74和0.76。
- A/B测试:Marco-Voice在直接对比中60%-65%的情况下优于基线。
System SC ↑ RS ↑ SN ↑ OS ↑ SS ↑ CosyVoice1 3.000 3.175 3.225 2.825 0.700 CosyVoice2 3.770 4.090 3.150 3.330 0.605 Marco-Voice 4.545 4.290 4.205 4.430 0.828
- 实际意义:为需要高度个性化与情感表现力的语音应用(如虚拟人、有声书、交互式助手)提供了一个强大的技术方案和数据资源。
- 主要局限性:情感分类准确率并非100%,对某些情感(如“惊讶”)或特定性别说话人的建模可能更弱;框架基于已有的CosyVoice进行扩展,其通用性有待在更多架构上验证。
🏗️ 模型架构
Marco-Voice是一个四阶段的统一语音合成系统,其整体架构如图1所示。

完整输入输出流程:输入为文本和可选的参考语音(用于克隆和/或情感提示)。输出为合成的情感语音波形。
主要组件及数据流:
- 输入编码器:包括文本编码器和语音tokenizer。文本编码器处理输入文本;语音tokenizer将参考语音转换为离散的语音token。
- 文本到Token语言模型:这是系统的核心生成模块。它以文本token、说话人嵌入(S) 和情感嵌入(E) 为条件,自回归地生成离散的语音token序列。该模块内部应用了说话人-情感正交解耦和批内对比学习策略,以确保生成的语音token能同时编码说话人身份和情感信息,且二者可分离。
- 条件流匹配模型:这是一个编解码器结构,负责将离散的语音token转化为连续的声学特征(如梅尔频谱)。其编码器接收语音token和情感嵌入,并在两者之间引入交叉注意力模块,使情感信息能动态调制声学表示。其解码器则以编码器输出、说话人嵌入、时间步嵌入和随机噪声为输入,预测最终的声学特征。流匹配模块进一步利用说话人和情感嵌入作为条件,增强合成语音的可控性。
- 声码器:将流匹配模型输出的声学特征转换为最终的波形音频。
关键设计选择与动机:
- 统一架构:旨在解决传统模块化设计导致的特征交互弱、合成质量下降问题。
- 旋转情感嵌入:动机是假设情感差异向量在说话人嵌入空间中,能有效分离情感与说话人身份。
- 正交约束与对比学习:动机是在特征空间中强制说话人与情感表示正交(无关),并增强情感特征的区分度,从而实现独立控制。
- 交叉注意力:动机是让情感信息在声学特征生成阶段能更精细、动态地与语音内容融合,确保情感连贯性。
💡 核心创新点
- 旋转情感嵌入与正交解耦方法:创新性地利用同一说话人的情感与中性语音对,在预训练情感编码器的嵌入空间中,通过差分向量构建与说话人无关的纯情感嵌入。进一步施加正交约束,从优化目标上强制说话人和情感特征子空间不相关,为独立控制奠定了坚实基础。
- 情感与语音Token的交叉注意力融合:在流匹配模型的编码器中,设计交叉注意力机制,让情感嵌入作为查询(Q)去关注语音token(K,V)。这比简单的向量相加或拼接更灵活,能根据情感需求动态调整声学表示,提升了情感表达的细腻度和与内容的匹配度。
- 构建高质量中文情感数据集CSEMOTIONS:针对非英语情感语音数据稀缺的问题,构建了一个包含10位专业说话人、7类情感、约10小时的高质量中文情感语音数据集,并配套制定了标准化的评估提示集。这填补了领域内的重要空白,为研究提供了宝贵资源。
- 模块化的系统集成与验证:系统性地将上述创新点(旋转嵌入、解耦、对比学习、交叉注意力)集成到一个基于LLM和流匹配的现代TTS框架中,并通过详尽的消融实验(v1-v4)逐一验证了每个组件的贡献,展示了清晰的性能提升路径。
🔬 细节详述
- 训练数据:
- 主训练集:ESD(约29小时,5种情感,20说话人)和CSEMOTIONS(约10小时,7种情感,10位中文母语专业说话人,录音室环境)。
- 评估集:英文从LibriTTS采样400句,中文从AISHELL-3采样400句。为全面评估情感,为每种情感(跨ESD和CSEMOTIONS)在中英双语下各设计了100条评估提示。
- 预处理:音频统一为24/48kHz,16bit深度,并进行了音量归一化。
- 损失函数:
- 主要TTS损失(LTTS):在文本到token语言模型中是交叉熵损失;在流匹配模型中是声学特征重建的MSE损失。
- 正交性损失(Lort):如公式(2)所示,包含两部分:一是投影说话人嵌入矩阵和情感嵌入矩阵的Frobenius范数(衡量整体正交性),二是它们逐样本余弦相似度的均值的Frobenius范数(衡量批次内平均正交性)。
- 对比学习损失(Lcont):如公式(3)所示,最小化批次内所有样本对的说话人-情感混合嵌入(hi)与对方情感嵌入(ej)的点积绝对值之和,促使不同样本的情感特征可区分。
- 总损失:L = LTTS + λort Lort + λcont Lcont。λort和λcont的具体值论文未说明。
- 训练策略:
- 优化器:Adam。
- 学习率:LLM部分为1e-5,流匹配部分为1e-4,采用余弦衰减调度。
- 批大小:每张GPU 32。
- 旋转情感嵌入构建:选择N=10个非中性情感样本对进行平均。
- 超参数:通过在验证集上搜索确定。
- 关键超参数:论文未说明模型具体参数量(如隐藏维度、层数)。
- 训练硬件:8张NVIDIA A100 GPU。训练时长未说明。
- 推理细节:论文未详细说明解码策略、温度、beam size等具体推理参数。
- 正则化/稳定训练:未明确提及除上述损失约束外的其他技巧。
📊 实验结果
语音克隆主观评估
System SC ↑ RS ↑ SN ↑ OS ↑ SS ↑ CosyVoice1 3.000 3.175 3.225 2.825 0.700 CosyVoice2 3.770 4.090 3.150 3.330 0.605 Marco-Voice 4.545 4.290 4.205 4.430 0.828 结论:Marco-Voice在所有指标上显著领先,特别是说话人相似度(SS)从0.700/0.605大幅提升至0.828。 情感语音合成主观评估
System SC ↑ EE ↑ RS ↑ SN ↑ OS ↑ CosyVoice2 3.770 3.240 4.090 3.150 3.330 Marco-Voice 4.545 4.225 4.290 4.205 4.430 结论:在情感表达(EE)上,Marco-Voice(4.225)远超CosyVoice2(3.240),整体满意度也大幅领先。 A/B 偏好测试
Compared System Marco-Voice Win Rate CosyVoice1/Marco-Voice 60% (12/20) CosyVoice2/Marco-Voice 65% (13/20) 结论:在直接盲听对比中,Marco-Voice有明显优势。 消融实验(客观指标)
- 在LibriTTS(英文)数据集上:
System WER ↓ Del & Ins ↓ Sub ↓ DNS-MOS ↑ CosyVoice1 12.1 413 251 3.899 Marco-v1 12.4 387 251 3.926 Marco-v2 12.5 398 286 3.900 Marco-v3 12.0 415 251 3.923 Marco-v4 11.4 395 242 3.860 - 在AISHELL-3(中文)数据集上:
System WER ↓ Del & Ins ↓ Sub ↓ DNS-MOS ↑ CosyVoice1 17.6 252 388 3.673 Marco-v1 17.6 212 485 3.687 Marco-v2 15.9 211 408 3.701 Marco-v3 18.2 212 496 3.689 Marco-v4 17.6 218 471 3.656 结论:各版本Marco-Voice的WER与基线相当或更优,DNS-MOS保持较高水平,表明增强情感和说话人控制能力并未牺牲基础合成质量。
情感准确率分析(图2)
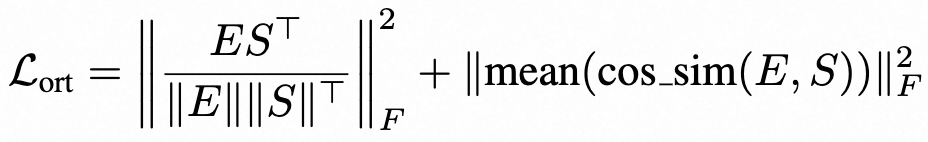 结论:随着模块逐个添加,情感准确率整体呈上升趋势。Marco-V4在中文上最高(~0.74),Marco-V3在英文上最高(~0.76)。
结论:随着模块逐个添加,情感准确率整体呈上升趋势。Marco-V4在中文上最高(~0.74),Marco-V3在英文上最高(~0.76)。分性别情感准确率分析(图3,中文)
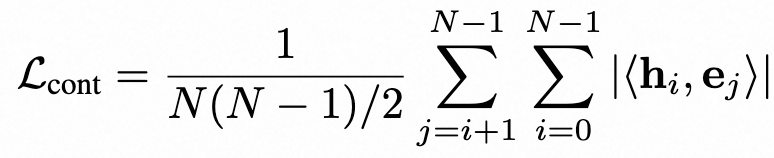 结论:女性说话人在多数情感上的识别准确率高于男性,尤其在“惊讶”和“悲伤”情感上差异明显。
结论:女性说话人在多数情感上的识别准确率高于男性,尤其在“惊讶”和“悲伤”情感上差异明显。
⚖️ 评分理由
- 学术质量:6.0/7 - 本文提出了一套完整且有洞察力的技术方案来解决语音合成中说话人与情感解耦的难题,创新点(旋转嵌入、正交约束、交叉注意力)明确且经过系统集成。实验设计全面,包括多基线对比、主观/客观指标、充分的消融实验和细分分析,结果令人信服。论文写作清晰,技术细节较为丰富。扣分点在于各单独创新点并非完全新颖,且对更复杂情感的建模能力仍有提升空间。
- 选题价值:1.5/2 - 该问题(高可控、高表现力语音合成)是当前语音领域的热点和关键挑战,具有极高的学术研究价值和工业应用前景(虚拟人、人机交互)。论文的解决方案和贡献的数据集直接推动了该方向的发展。
- 开源与复现加成:+0.5/1 - 论文提供了完整的代码仓库、数据集下载链接,并在“Implementation Details”中给出了足够详细的训练配置信息(优化器、学习率、硬件、批大小等),为复现提供了极大便利。这是该论文的重要加分项。