📄 Mambaformer: State-Space Augmented Self-Attention with Downup Sampling for Monaural Speech Enhancement
#语音增强 #状态空间模型 #Transformer #双路径模型 #时频分析
✅ 7.0/10 | 前25% | #语音增强 | #状态空间模型 | #Transformer #双路径模型
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明
- 通讯作者:未说明
- 作者列表:Shengkui Zhao, Haoxu Wang, Zexu Pan, Yiheng Jiang, Biao Tian, Bin Ma, Xiangang Li (阿里巴巴通义实验室,新加坡)
💡 毒舌点评
这篇论文在工程集成上确实下足了功夫,将Mamba、Conformer、ZipFormer等多种组件巧妙地缝合在一个双路径框架里,最终在标准测试集上刷新了指标。然而,其核心创新更偏向于“有效的组合技”而非“范式革新”,更像是对现有技术模块进行了一次成功的超参调优和工程排列组合,略显缺乏令人眼前一亮的原创思想火花。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用的是公开基准数据集(VoiceBank+DEMAND, DNS Challenge 2020),获取方式未在论文中说明,但可通过相关官网获取。
- Demo:未提及在线演示。
- 复现材料:论文提供了详细的架构描述、训练配置(数据集、损失函数、优化器、学习率策略、超参数表)和硬件信息,复现信息较为充分。
- 论文中引用的开源项目:论文中引用了多个先前工作(如DPRNN, DPT-FSNet, CMGAN, MP-SENet, ZipEnhancer, SEMamba等)并进行了对比,这些是相关领域的重要开源工作,但MambaFormer本身未表明基于或依赖哪个具体开源仓库。
📌 核心摘要
这篇论文要解决的是单通道语音增强任务中,如何更有效地结合Transformer的全局建模能力和状态空间模型(SSM)的高效序列处理能力的问题。 方法核心是提出了MambaFormer模型,它在一个双路径(时间-频率)框架内,将Mamba模块嵌入到Transformer的自注意力机制中,并辅以Conformer卷积和对称的降采样/上采样结构。 与已有方法相比,新在三个方面:1)首次在SE任务中将Mamba与自注意力深度融合,而非简单堆叠;2)设计了双层自注意力结构并共享注意力权重以提升效率;3)采用了可学习的下采样/上采样模块来平衡计算效率与表征保真度。 主要实验结果:在VoiceBank+DEMAND测试集上,其MambaFormer (M)模型取得了3.69的PESQ得分;在DNS Challenge 2020测试集上取得了3.82的PESQ得分,均报告为新的最先进水平。关键对比数据见下表:
| 模型 | VoiceBank+DEMAND PESQ | DNS2020 PESQ | 参数量(M) |
|---|---|---|---|
| ZipEnhancer (S) | 3.63 | 3.69 | 2.04 |
| MambaFormer (S) | 3.66 | 3.75 | 2.14 |
| MambaFormer (M) | 3.69 | 3.82 | 9.04 |
实际意义在于验证了SSM与Transformer协同工作的有效性,为语音增强模型设计提供了新的模块化组合思路。主要局限性在于:1)创新更多是组合与适配,原创性有限;2)论文未提供代码和模型权重,复现性未验证;3)虽然提出了新的SOTA,但与基线的绝对提升幅度并不巨大。
🏗️ 模型架构
MambaFormer采用编码器-解码器结构,核心是堆叠的N个DP_MambaFormer块,整体流程如图1所示。
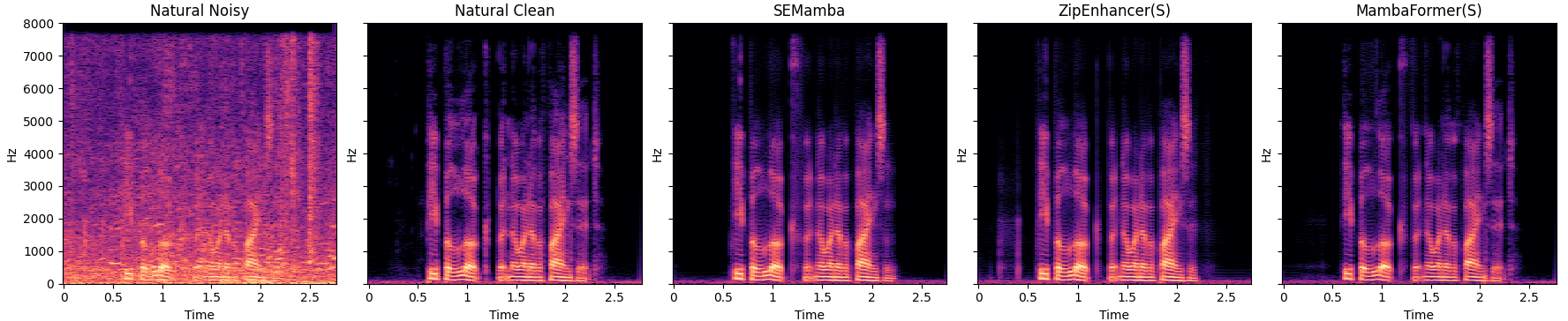 图1:MambaFormer模型概述。(a) 包含STFT/iSTFT、编码器/解码器以及N个堆叠的DP_MambaFormer块的模型流程图。(b) 用于频率建模的F_MambaFormer模块配置(用于时间建模的T_MambaFormer模块采用相同结构)。(c) Mamba结构。(d) 非线性注意力(NLA)结构。
图1:MambaFormer模型概述。(a) 包含STFT/iSTFT、编码器/解码器以及N个堆叠的DP_MambaFormer块的模型流程图。(b) 用于频率建模的F_MambaFormer模块配置(用于时间建模的T_MambaFormer模块采用相同结构)。(c) Mamba结构。(d) 非线性注意力(NLA)结构。
- 输入与编码器:输入为含噪语音波形
y。首先进行STFT,得到幅度谱Y_mag和相位谱Y_pha,将两者拼接Y_in = [Y_mag, Y_pha]作为编码器输入。编码器(Encoder)由两个卷积块和中间的膨胀密集网络(Dilated DenseNet)组成,将输入映射到紧凑的时-频特征空间。 - DP_MambaFormer块(核心处理单元):
- 下采样模块(Down-Sampler):通过可学习的权重,沿时间和频率轴对特征进行降维,从
T×F×C变为(T/r)×(F/r)×C,其中r是下采样率,旨在减少计算量。 - 双路径建模:下采样后的特征依次经过 F_MambaFormer(沿频率轴建模)和 T_MambaFormer(沿时间轴建模)模块。这两个模块结构相同。
- F/T_MambaFormer模块内部:如图1(b)所示,每个模块内部结构是对Conformer块的改进。它首先是一个包含 Mamba模块(图1(c))的线性层,用于高效的自适应序列建模;随后是一个包含 非线性注意力(NLA) 和 共享权重多头注意力(MHAW) 的自注意力层(图1(d)),用于强化全局上下文建模;然后是 卷积模块(Conv) 和 前馈网络(FFN),沿用Conformer设计以捕获局部模式。模块内使用Bypass操作进行残差连接,并用BiasNorm替代LayerNorm。
- 上采样模块(Up-Sampler):将处理后的低分辨率特征恢复到原始分辨率。
- 旁路连接(Bypass):块的最终输出与块的输入进行加权融合。
- 下采样模块(Down-Sampler):通过可学习的权重,沿时间和频率轴对特征进行降维,从
- 解码器与输出:经过所有DP_MambaFormer块处理后,特征被送入并行的幅度解码器和相位解码器。两者分别重建增强后的幅度谱
X_mag和相位谱X_pha。最后通过iSTFT将增强的幅度和相位谱合并,得到最终的增强波形x。
关键设计动机:
- Mamba + 自注意力:利用Mamba高效的、输入依赖的序列建模能力处理局部连续性,同时用自注意力捕获全局的、非序列依赖关系,形成互补。
- 双路径(DP):分别沿时间轴和频率轴建模,更有效地捕捉二维时频图的结构依赖,这是语音增强领域的经典有效范式。
- 降采样/升采样:通过降低时频分辨率来减少计算复杂度,同时通过可学习权重和对称结构尽量保留信息,实现效率与性能的平衡。
💡 核心创新点
- Mamba与Transformer自注意力的深度融合:不同于以往SE-Mamba仅使用Mamba,或ZipEnhancer仅使用Transformer,MambaFormer创新性地将Mamba模块作为自注意力模块前的一个关键组件,形成了“Mamba -> 双层自注意力(NLA + SA)”的序列。这使得模型能在早期利用Mamba进行高效的自适应序列推理,再通过后续注意力层精炼全局交互,理论上结合了二者的互补优势。
- 基于ZipFormer改进的双层自注意力与权重共享:采用并行两次注意力计算(先NLA,后标准SA)来增强全局建模能力。通过预计算并共享多头注意力权重(MHAW),在增强表征能力的同时控制了计算成本的大幅增长。
- 可学习的对称降采样/升采样策略:设计了一种带有可学习softmax权重的降采样模块,并在块后使用对称的升采样模块。消融实验证明,这种设计在显著降低计算量(FLOPs)的同时,只引起微小的性能损失,实现了良好的效率-性能权衡。
🔬 细节详述
- 训练数据:
- VoiceBank+DEMAND:训练集包含11,572段干净语音(来自28位说话人)与10种噪声在0-15dB SNR下混合;测试集包含872段语音(来自2位未见说话人)与5种未见噪声在2.5-17.5dB SNR下混合。
- DNS Challenge 2020 (DNS2020):训练数据由500小时干净语音(来自2150位说话人)与180+小时噪声在-5-15dB SNR下混合生成,共约3000小时;评估使用官方非盲测试集,包含150对含噪-干净语音对(来自20位未见说话人)。
- 预处理:所有音频重采样至16kHz,分割为2秒片段。STFT参数:FFT点数400,窗长25ms,窗移6.25ms,生成201个频率单元。
- 损失函数:采用加权组合损失,公式为
L = λ1L_pesq + λ2L_stft + λ3L_mag + λ4L_com + λ5L_pha + λ6L_time。具体项包括:基于PESQ的GAN判别器损失(L_pesq)、STFT一致性损失(L_stft)、幅度损失(L_mag)、复数损失(L_com)、相位损失(L_pha)和时域损失(L_time)。各权重为:λ1=0.05, λ2=0.1, λ3=0.9, λ4=0.1, λ5=0.3, λ6=0.2。 - 训练策略:
- 优化器:使用ScaleAdam。
- 学习率调度:使用Eden调度器,基础学习率
α_base = 0.04,预热步数t_warmup = 4000,步长α_step = 2500,周期α_epoch = 24。 - 批次大小:4。
- 训练步数:VoiceBank+DEMAND为50万步,DNS2020为200万步。
- 稳定训练技巧:Bypass连接中的融合权重
c在前2000步初始化在[0.9, 1.0]之间,之后放宽至[0.2, 1.0],以稳定训练初期。使用BiasNorm替代LayerNorm。
- 关键超参数:论文提供了两种模型配置(S和M),见下表:
| 配置 | 块数(N) | 各块降采样率列表 | 通道数(C) | 注意力头数 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|---|---|
| MambaFormer (S) | 4 | {1, 2, 2, 1} | 64 | 4 | 2.14 | 43.55 |
| MambaFormer (M) | 6 | {1, 2, 3, 4, 2, 1} | 128 | 8 | 9.04 | 163.12 |
- 训练硬件:使用单块80GB NVIDIA A800 GPU。
- 推理细节:论文未明确说明解码策略(如波束搜索等),对于增强任务,通常是直接前向推理得到增强谱后做iSTFT。未提及流式设置。
- 正则化:论文未明确提及Dropout等额外正则化手段。
📊 实验结果
论文在两个主流基准测试集上进行了全面评估,并与多种最新方法进行了对比。
表1:在VoiceBank+DEMAND测试集上的性能与计算成本对比。
| 模型 | 年份 | 双路径 | 参数量(M) | FLOPs(G) | WB-PESQ | CSIG | CBAK | COVL | STOI | SSNR | SI-SDR |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ZipEnhancer (S) | 2024 | 是 | 2.04 | 62.85 | 3.63 | 4.81 | 3.87 | 4.36 | 96.19 | 8.33 | 19.09 |
| MambaFormer (S, λ6=0.0) | 2025 | 是 | 2.14 | 43.55 | 3.66 | 4.84 | 3.95 | 4.41 | 96.18 | 10.0 | 19.04 |
| MambaFormer (M, λ6=0.0) | 2025 | 是 | 9.04 | 163.12 | 3.69 | 4.86 | 3.98 | 4.43 | 96.36 | 9.47 | 19.17 |
结论:MambaFormer (M)在PESQ上达到了3.69的新SOTA,相较于前SOTA ZipEnhancer (S)提升了0.06分,同时MambaFormer (S)在参数量相近的情况下,PESQ也优于ZipEnhancer (S)。值得注意的是,不使用时域损失(λ6=0.0)的配置在PESQ等指标上更好,而使用时域损失(λ6=0.2)则提升了STOI和SI-SDR,表明存在指标间的权衡。
表2:在DNS Challenge 2020非盲测试集(无混响)上的性能对比。
| 模型 | 参数量(M) | WB-PESQ | NB-PESQ | STOI | SI-SDR |
|---|---|---|---|---|---|
| ZipEnhancer (S) | 2.04 | 3.69 | 3.99 | 98.3 | 21.2 |
| MambaFormer (S) | 2.14 | 3.75 | 4.03 | 98.3 | 19.2 |
| ZipEnhancer (M) | 11.34 | 3.81 | 4.08 | 98.6 | 22.2 |
| MambaFormer (M) | 9.04 | 3.82 | 4.09 | 98.6 | 20.9 |
结论:MambaFormer (M)在DNS2020上取得了3.82的PESQ新SOTA,略高于ZipEnhancer (M)。MambaFormer (S)也在小模型类别中取得了领先的PESQ分数。
消融研究:
- 表1(配置消融):展示了不同降采样率配置对性能的影响。完全不降采样(S2)计算量最大但性能与S相当;适度降采样(S, S3-S8)能在轻微性能损失下大幅降低FLOPs,验证了降采样设计的有效性。
- 表2(组件消融):证明了每个核心组件的贡献:将Mamba替换为自注意力,PESQ下降0.03;去掉卷积模块,PESQ下降0.04;去掉FFN模块,PESQ下降0.08(主要因参数减少);去掉Bypass连接或替换BiasNorm为LayerNorm,性能也有轻微下降。
图2:语音谱图可视化对比。 (由于当前上下文未提供此图片的URL,无法插入。) 描述:该图可视化了含噪语音、干净真值以及SEMamba、ZipEnhancer (S)和MambaFormer (S)的增强输出谱图。MambaFormer的输出在语音成分的清晰度和噪声抑制方面���现良好,直观地展示了其增强效果。
⚖️ 评分理由
- 学术质量:6.5/7:论文技术路线清晰,实验设计规范,在两个权威数据集上均报告了SOTA结果,消融实验充分验证了各组件的有效性。主要扣分点在于创新性偏工程集成,虽然组合巧妙,但未提出颠覆性的新概念或新框架,属于优秀但非突破性的渐进式工作。
- 选题价值:1.0/2:语音增强是成熟且重要的研究方向,Mamba(SSM)与Transformer的结合是当前热门趋势,论文选题具有前沿性。但其应用场景(单通道语音增强)相对具体,对广泛的音频/语音读者的直接普适性价值中等。
- 开源与复现加成:-0.5/1:论文详细报告了训练数据、超参数、损失函数权重、硬件环境等信息,具备较好的文字复现指导性。然而,论文中未提及代码、模型权重或任何开源计划的链接或说明,这是重大的扣分项,严重影响社区的可复现性和验证效率。