📄 MAG: Multi-Modal Aligned Autoregressive Co-Speech Gesture Generation Without Vector Quantization
#音频生成 #多模态模型 #扩散模型 #对比学习
🔥 8.0/10 | 前25% | #音频生成 | #多模态模型 #扩散模型 | #多模态模型 #扩散模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Binjie Liu(中国传媒大学信息与通信工程学院,中国移动研究院)
- 通讯作者:Sanyi Zhang(中国传媒大学数据科学与媒体智能学院,媒体音频视频教育部重点实验室)†,Long Ye(中国传媒大学数据科学与媒体智能学院,媒体融合与传播国家重点实验室)† (注:论文中标注†为通讯作者)
- 作者列表:Binjie Liu(中国传媒大学,中国移动研究院)、Lina Liu(中国移动研究院)、Sanyi Zhang(中国传媒大学,媒体音频视频教育部重点实验室)、Songen Gu(复旦大学)、Yihao Zhi(香港中文大学(深圳))、Tianyi Zhu(中国移动研究院)、Lei Yang(中国移动研究院)、Long Ye(中国传媒大学,媒体融合与传播国家重点实验室)
💡 毒舌点评
亮点在于其核心思想——在连续运动嵌入空间进行自回归建模,而非离散化——非常优雅且直击痛点,消融实验也清晰地证明了该设计的必要性。短板在于,虽然声称“无需向量量化”,但并未提供与使用VQ的自回归模型在生成效率、模型规模上的定量对比,其“更优”很大程度上局限于生成质量指标,对于实际应用中的效率考量论述不足。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及。
- 数据集:使用的是公开数据集BEATv2和SHOW。
- Demo:未提及。
- 复现材料:未提供详细的训练配置、超参数、检查点或附录说明。
- 论文中引用的开源项目:引用了WavCaps [8]、HuBERT [12]、fastText [13]、MAR [14]等作为基础组件或灵感来源。
📌 核心摘要
- 问题:现有的语音驱动全身手势生成方法大多依赖基于向量量化(VQ)的自回归模型,这会导致运动信息的离散化损失,降低生成手势的真实感和连续性。
- 方法核心:提出MAG框架,包含两个阶段:1)多模态对齐变分自编码器(MTA-VAE),利用预训练的WavCaps文本和音频特征,通过对比学习将运动、文本和音频对齐到一个连续的潜在空间;2)多模态掩码自回归手势生成模型(MMAG),在连续运动嵌入空间上应用扩散过程,避免离散化,并通过混合粒度音频-文本融合块提供条件。
- 新在哪里:这是首个在共语音手势生成领域实现“无向量量化”的自回归框架。创新点在于:在连续空间进行自回归扩散建模以保持运动连续性;利用对比学习实现运动、文本、音频三模态的语义和韵律对齐;设计HGAT模块融合不同粒度的音频(MFCC, HuBERT)和文本(fastText)特征。
- 实验结果:在BEATv2和SHOW两个基准数据集上,MAG在FGD(弗雷歇手势距离)、BC(节拍一致性)和Diversity(多样性)指标上均达到最优(SOTA)。例如,在BEATv2上,MAG(MTA-VAE)的FGD为4.565×10⁻¹,显著低于基线EMAGE的5.512×10⁻¹。用户研究也显示MAG生成的手势在真实感、多样性和同步性上最受偏好。
- 实际意义:为构建更自然、生动、与语音高度同步的虚拟人角色提供了新的技术范式,可应用于元宇宙、人机交互、游戏等领域。
- 主要局限性:论文未提供模型参数量、训练时间、推理速度等效率信息,而连续空间扩散模型通常计算成本较高。此外,对比学习高度依赖预训练的WavCaps模型,其特征质量直接影响上限。
🏗️ 模型架构
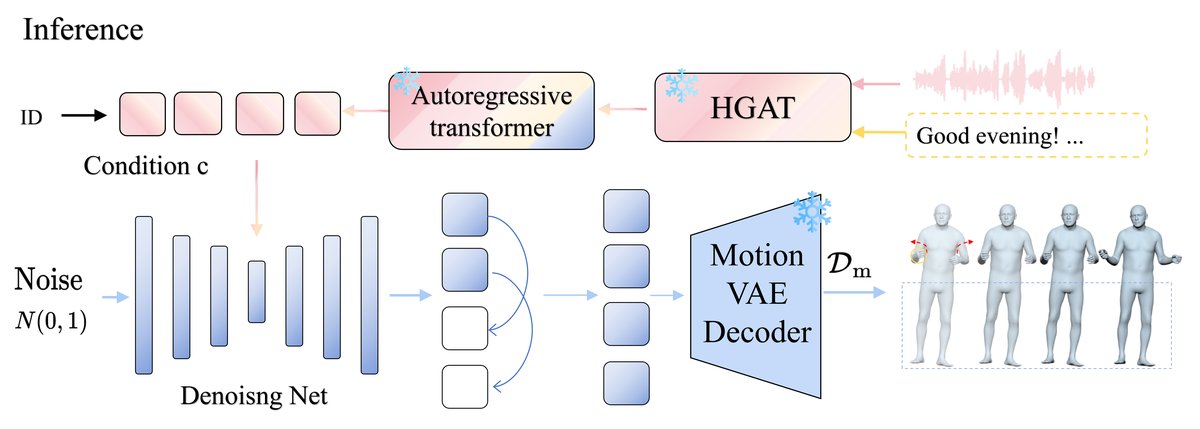
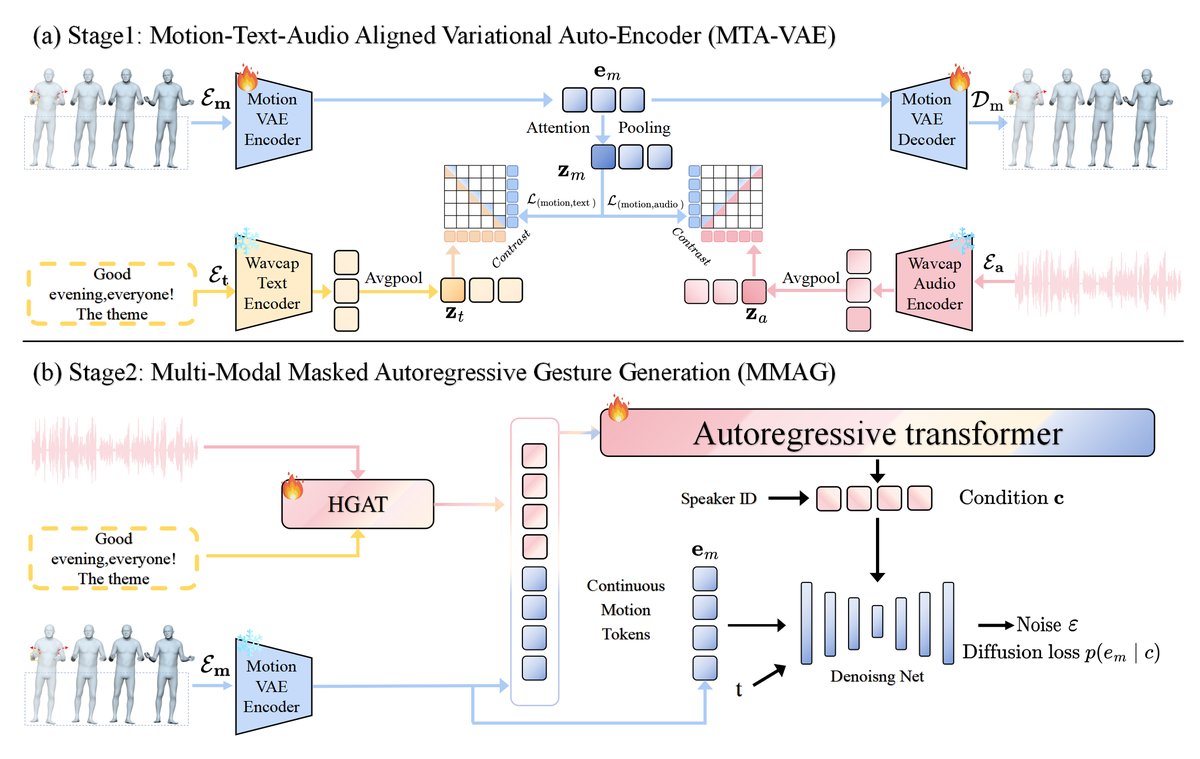
MAG是一个两阶段的框架,其整体架构如图2所示。
阶段一:多模态对齐变分自编码器(MTA-VAE)
- 功能:学习一个将运动、文本、音频统一到连续潜在空间的编码器与解码器,并实现跨模态对齐。
- 内部结构:
- 运动VAE:由运动VAE编码器(Em)和解码器(Dm)构成。编码器Em使用四层时间卷积网络(TCN)处理运动序列m,输出连续运动特征em。解码器Dm从这些特征重建运动序列。其目标是最小化重建损失Lrec(测地距离)、速度损失Lvel和加速度损失Lacc(L1损失)的加权和(公式2)。
- 多模态对比学习:利用预训练的WavCaps模型提取音频特征za(来自HTSAT编码器)和文本特征zt(来自BERT编码器)。运动特征em被投影并聚合为zm,通过对比损失Lm,t,a(公式3)最大化zm与za、zt在正样本对上的相似度,从而将三者对齐。
- 整体训练:MTA-VAE的总损失Ltotal是运动重建损失、对比损失和KL散度的加权和(公式4),以同时保证重建质量、模态对齐和潜在空间的正则化。
- 数据流:输入(运动m,文本t,音频a)→ Em提取em → 投影聚合为zm → 对比学习对齐zm与za, zt → Dm从em重建m。
阶段二:多模态掩码自回归手势生成模型(MMAG)
- 功能:给定音频、文本和说话人身份,预测条件c,然后通过扩散过程在连续运动潜在空间生成运动嵌入。
- 内部结构:
- 身份编码:使用独热编码表示说话人身份。
- 混合粒度音频-文本融合块(HGAT):这是提供条件c的核心。其架构如图4所示。HGAT融合了来自MFCC的声学特征、来自HuBERT的语义音频特征以及来自fastText的文本特征。音频特征被降维,文本特征被升维,然后通过自注意力机制融合成一个统一的多模态表示。
- 掩码自回归与扩散过程:受MAR启发,MMAG将连续运动嵌入作为“token”。训练时,对已知运动序列M(分上肢、手、下肢)用MTA-VAE编码得到eM。扩散过程向其添加噪声得到eM,t。一个MLP去噪网络Eθ在条件c(由HGAT输出)和时间步t的引导下,预测原始的eM或噪声ε(公式5、6)。推理时,从噪声开始,由Eθ迭代去噪,生成运动嵌入,最后由运动VAE解码器Dm生成最终手势。
- 数据流:推理时,噪声+条件c → MLP去噪网络迭代预测 → 生成运动嵌入 → 运动VAE解码器 → 输出手势序列。
💡 核心创新点
- 连续运动嵌入空间的自回归扩散建模:是什么:将扩散模型应用于由连续变分自编码器(而非VQ-VAE)产生的运动潜在表示上,进行自回归生成。之前局限:VQ-VAE将连续运动离散化,导致信息损失和生成手势不自然。如何起作用:VAE潜在空间保留了运动流形的连续拓扑结构,扩散过程在此连续空间操作,避免了量化伪影。收益:消融实验(表4)显示,仅将VQ-VAE替换为VAE(连续表示),重建误差(Rec)从0.32降至0.06,FGD从1.083大幅改善至0.0194,证明了连续表示对生成真实感的基础性提升。
- 运动-文本-音频三模态联合对比学习对齐:是什么:在MTA-VAE中,通过对比学习将运动嵌入与预训练模型提取的文本和音频嵌入对齐。之前局限:许多方法仅关注文本-运动对齐(如MotionCLIP),忽视了音频在手势韵律同步中的关键作用。如何起作用:设计四方向的对比损失(Lm→a, La→m, Lm→t, Lt→m),使运动嵌入在语义上靠近文本,在韵律上靠近音频。收益:消融实验(表4)表明,MTA-VAE相比仅对齐文本的MT-VAE或仅对齐音频的MA-VAE,在保持FGD优势的同时,提升了BC(节拍一致性)或多样性,证实了三模态对齐的互补性。
- 混合粒度音频-文本融合块(HGAT):是什么:一个专门用于融合多粒度音频和文本特征的模块,为扩散过程提供高质量条件。之前局限:简单拼接或早期融合无法充分利用不同模态特征的层次信息(如MFCC的声学节奏、HuBERT的语义内容、文本的离散语义)。如何起作用:HGAT通过缩放和注意力机制,动态融合不同来源、不同维度的特征,形成更强的多模态一致性条件。收益:消融实验(表3)显示,HGAT将FGD从13.30(无HGAT)大幅降低至4.565,其效果远超单独使用文本、HuBERT或MFCC,是性能飞跃的关键。
🔬 细节详述
- 训练数据:
- BEATv2-Standard数据集:27小时,包含运动、文本、音频。按85%/7.5%/7.5%划分训练/验证/测试集。
- SHOW数据集:26.9小时,3D全身网格与同步音频。按80%/10%/10%划分,使用时长>3秒的序列。
- 损失函数:
- 运动重建损失(Lmotion):包括测地距离重建损失(Lrec)、速度L1损失(Lvel)、加速度L1损失(Lacc)。
- 对比损失(Lm,t,a):L2方向的InfoNCE损失,最大化正样本对(同一视频对应的运动-文本、运动-音频)的相似度。
- KL散度(Lkl):正则化VAE潜在空间,使其接近标准高斯分布。
- 扩散损失:公式5所示的均方误差损失,预测噪声ε。
- 训练策略:
- 论文未明确说明优化器、学习率、batch size、训练轮数等具体超参数。
- MTA-VAE和MMAG是分阶段训练的:先训练MTA-VAE,然后冻结其编码器,再训练MMAG。
- 关键超参数:
- 运动特征维度:em ∈ R^{T×64},投影后 zm ∈ R^{T×1024}。
- 模型组件使用Transformer(用于自回归)和MLP(用于扩散去噪网络)。
- 具体的层数、隐藏维度、注意力头数等未说明。
- 训练硬件:未说明。
- 推理细节:推理流程如图3所示,使用学到的扩散时间步调度进行迭代去噪。解码策略为直接前向传播。温度、beam size等不适用于该生成范式。
- 正则化/稳定训练技巧:使用了KL散度正则化VAE;在扩散模型中使用了标准的噪声调度(公式6中的α_t)。
📊 实验结果
论文在BEATv2和SHOW两个数据集上进行了定量比较、用户研究和消融实验。
主要定量对比(表1):
| 方法 | 数据集 | FGD ↓ (×10⁻¹) | BC ↑ (×10⁻¹) | Diversity ↑ |
|---|---|---|---|---|
| EMAGE | BEATv2 | 5.512 | 7.72 | 13.06 |
| TheLO | BEATv2 | 5.300 | 7.78 | 15.16 |
| MAG (VAE) | BEATv2 | 4.835 | 7.84 | 12.85 |
| MAG (MTA-VAE) | BEATv2 | 4.565 | 7.84 | 13.27 |
| TalkSHOW | SHOW | 1155.6 | 8.70 | 4.365 |
| MAG (VAE) | SHOW | 592.7 | 8.28 | 5.190 |
结论:MAG在两个数据集的核心指标FGD上均取得最优,表明生成手势与真实分布最接近。在BC上保持了顶尖水平,多样性也具竞争力。在SHOW数据集上,MAG的FGD(592.7)远优于最强基线TalkSHOW(1155.6),优势显著。
用户研究(表2):在真实感(Real)、多样性(Div)、手势-语音同步(G-S Sync)、语义对齐(Sem)四个维度上,MAG的平均排名均为第一,说明其生成结果最受人类评委青睐。
关键消融实验:
- HGAT模块消融(表3):证明了HGAT是性能提升的关键。移除HGAT(wo HGAT)后,FGD急剧恶化至13.30;仅使用单一特征(Text, HuBERT, MFCC)的效果远不如HGAT融合后的4.565。
- 核心设计消融(表4):
- 连续 vs 离散表示:将基线VQ-VAE换成VAE(连续),FGD从1.083(表格单位下)降至0.0194,Rec从0.32降至0.06,直接验证了连续空间的优势。
- 多模态对齐:MTA-VAE相比不进行对齐的VAE,在下游生成任务中进一步降低了FGD(0.0174 vs 0.0194),并提升了BC。
- 端到端效果:完整的MAG (MTA-VAE) 相比使用简单VAE的MAG (VAE),在最终FGD上从4.835优化至4.565。

 结论:定性结果(图5、图6)显示,MAG生成的手势在动作幅度和与语音的同步性上更接近Ground Truth,尤其在强语义词汇处反应更明显。
结论:定性结果(图5、图6)显示,MAG生成的手势在动作幅度和与语音的同步性上更接近Ground Truth,尤其在强语义词汇处反应更明显。
⚖️ 评分理由
- 学术质量:6.5/7:创新性高,提出了无量化的连续自回归扩散范式,思路新颖。技术实现完整,架构设计合理。实验非常充分,在两个数据集上进行了全面对比、消融和用户研究,数据详实,证据链强。得分未达更高是因为缺乏对计算开销等实用层面的讨论。
- 选题价值:1.5/2:共语音手势生成是构建沉浸式虚拟人、提升人机交互自然度的核心课题,具有明确的学术前沿性和广阔的产业应用前景(游戏、元宇宙、辅助技术)。对于从事音频、动画、多模态AI的研究者和开发者有直接参考价值。
- 开源与复现加成:0/1:论文全文未提及代码、模型、权重或任何详细的超参数配置,也未声明���源计划。这使得外部研究者难以直接复现工作,构成了明显的复现障碍。