📄 Low-Resource Speech-Based Early Alzheimers Detection via Cross-Lingual and Few-Shot Transfer Learning
#语音生物标志物 #迁移学习 #多语言 #少样本 #低资源
✅ 7.5/10 | 前25% | #语音生物标志物 | #迁移学习 | #多语言 #少样本
学术质量 7.5/7 | 选题价值 8.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Yongqi Shao(上海交通大学)
- 通讯作��:未说明
- 作者列表:Yongqi Shao(上海交通大学), Bingxin Mei(上海交通大学), Hong Huo(上海交通大学), Tao Fang(上海交通大学)
💡 毒舌点评
亮点: 论文首次将参数高效的LoRA技术系统性地应用于跨语言阿尔茨海默症(AD)语音检测,构建了涵盖四种语言的首个多语言基准测试,为低资源医疗AI提供了实用框架。 短板: 多源语言联合训练的效果反而不如单源迁移,这一反直觉的结果暴露了当前多语言数据集规模小、异质性高带来的严重瓶颈,使得“多源更优”的假设未能得到验证,也削弱了框架在复杂场景下的鲁棒性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文中提到所用数据集来自DementiaBank平台,但未提供具体整合后的数据集或下载链接。
- Demo:未提及。
- 复现材料:论文提供了较为详细的实验设置(模型超参数、训练策略),但未提供具体的配置文件、检查点或附录。
- 论文中引用的开源项目:使用了预训练模型Wav2Vec2-large-XLSR-53 [18],并参考了LoRA [17] 方法。
📌 核心摘要
- 要解决什么问题:解决在低资源语音环境下,利用语音进行早期阿尔茨海默症(AD)检测的难题。现有研究多局限于英语和单一数据集,无法有效服务于全球众多低资源语言人群。
- 方法核心是什么:提出一个跨语言、少样本迁移学习框架。以在多语言上预训练的Wav2Vec2.0作为语音编码器骨干,通过逐层分析确定最佳迁移层(第19层),并在此层插入低秩自适应(LoRA) 模块进行参数高效微调。框架支持从单源高资源语言(英语)或多个源语言向低资源目标语言迁移。
- 与已有方法相比新在哪里:1) 首次建立跨语言AD语音检测基准,涵盖英语、普通话、西班牙语、希腊语;2) 创新性地结合了Wav2Vec2.0的层级分析与LoRA,针对AD检测任务优化跨语言适应效率;3) 系统评估了单源和多源两种迁移范式在现实低资源条件下的表现。
- 主要实验结果如何:
- 在单源迁移(EN → ZH/ES/EL)中,LoRA微调一致性地提升了目标语言的分类准确率(例如,希腊语测试准确率从68.75%提升至76.52%)。
- 单源迁移的总体效果优于多源迁移(例如,EN→ZH测试准确率77.96% vs. EN+ES+EL→ZH 64.17%)。
- 存在显著的过拟合现象(训练准确率远高于测试准确率)和目标语言间性能差异。
- 消融实验(表3)证明LoRA在单源和多源设置下均能带来性能提升。
- 实际意义是什么:该研究证明了利用大规模预训练语音模型和参数高效微调技术,有望打破语言壁垒,为全球不同语言背景的人群提供低成本、可扩展的AD早期语音筛查工具,具有重要的公共卫生应用前景。
- 主要局限性是什么:1) 数据集规模小(特别是希腊语仅46人)且异质性大,是制约模型性能(尤其是多源迁移)的主要因素;2) 缺乏与其他现有AD检测方法的直接对比;3) 模型在所有设置下均表现出训练-测试性能差距,泛化能力有待加强。
🏗️ 模型架构
模型采用模块化设计,由三个核心组件构成,整体架构如图1所示。
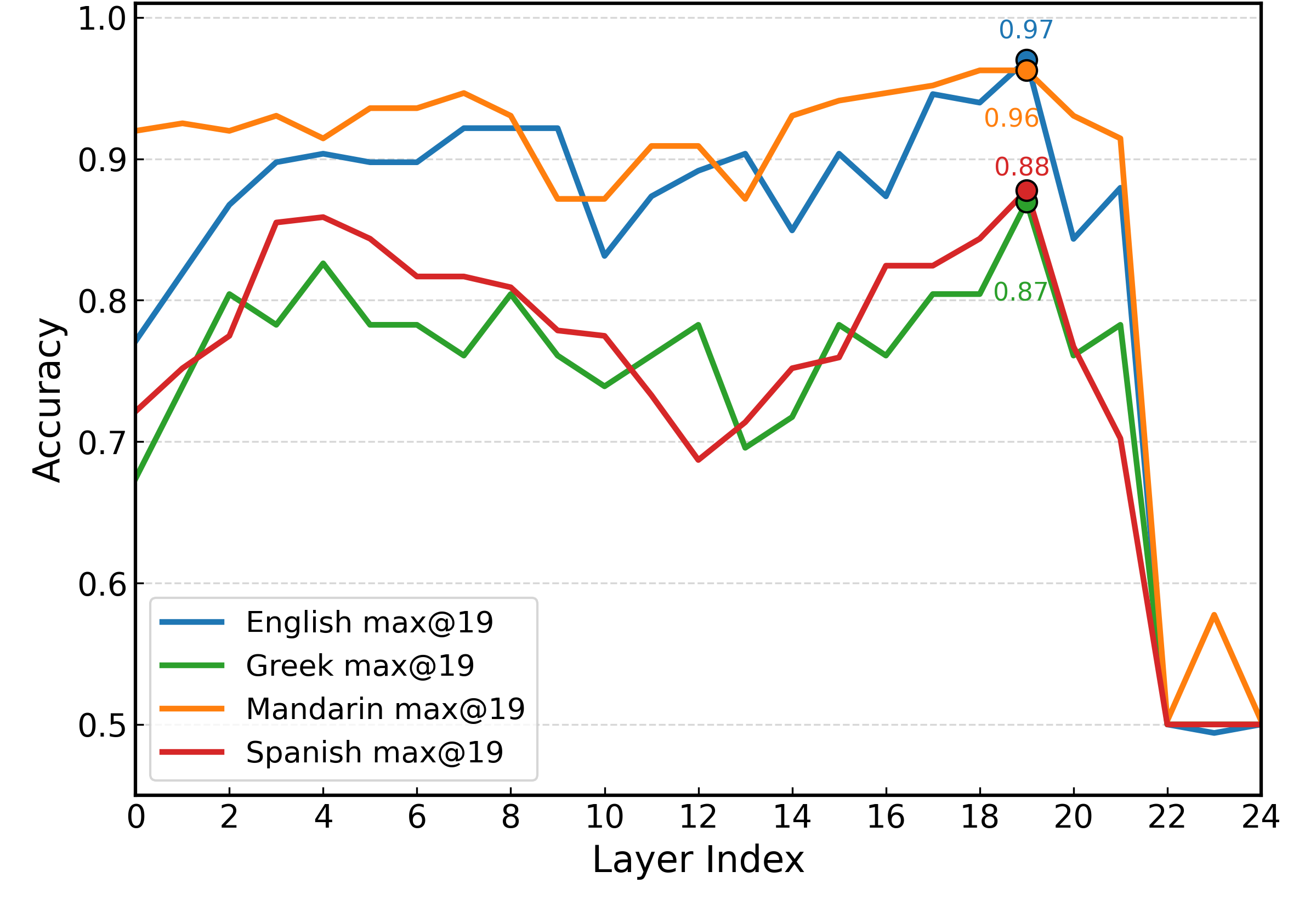 图1展示了模型架构(上)和两种跨语言迁移学习范式(下)。绿色部分为模型:预训练的Wav2Vec2.0编码器共享于所有语言,其上连接语言特定的LoRA适配器,最后是线性分类头。蓝色部分说明单源(一种语言→另一种语言)和多源(多种语言→一种语言)的迁移流程。
图1展示了模型架构(上)和两种跨语言迁移学习范式(下)。绿色部分为模型:预训练的Wav2Vec2.0编码器共享于所有语言,其上连接语言特定的LoRA适配器,最后是线性分类头。蓝色部分说明单源(一种语言→另一种语言)和多源(多种语言→一种语言)的迁移流程。
- 预训练语音编码器 (Wav2Vec2.0):采用Wav2Vec2-large-XLSR-53作为骨干网络。这是一个在53种语言上进行自监督预训练的通用语音表示模型,能从原始音频中提取多层次、富含声学与语言信息的特征。在框架中,编码器权重被冻结,不参与目标语言的训练。
- 参数高效适配器 (LoRA):在冻结的编码器特定层(通过逐层分析确定为第19层)的线性层中,插入可训练的低秩适配矩阵。具体地,对于原始权重矩阵
W,LoRA引入两个小矩阵A和B,将投影变换为Wx + BAx。这使得仅需训练极少量的新增参数(每个LoRA模块仅增加2dr个参数,其中r为远小于d的秩),即可适应目标语言和AD检测任务。LoRA的超参数设置为:秩r=8,缩放系数α=16,丢弃率0.1。 - 任务分类器:在LoRA适配器之后,连接一个单层线性分类器,其输入是编码器第19层在LoRA适配后的隐藏状态,经时间维度平均池化后的向量。分类器输出两个类别:认知正常(CN)和阿尔茨海默症(AD)。
数据流与交互:原始语音 → 预训练Wav2Vec2.0编码器(冻结) → 提取第19层隐藏状态 → 经语言特定的LoRA模块(可训练)进行适应性增强 → 通过线性分类头(可训练)输出分类结果。
💡 核心创新点
- 构建首个多语言AD语音检测基准:整合并标准化了来自英语、普通话、西班牙语和希腊语的四个公开数据集,形成了首个覆盖四种语言、适用于跨语言研究的统一基准,填补了该领域在多语言系统评估上的空白。
- 提出基于层级分析与LoRA的参数高效跨语言适应框架:创新性地将Wav2Vec2.0的层级分析与LoRA技术结合。通过实验确定最具有跨语言迁移性的编码器层(第19层),并仅在该层插入LoRA进行微调,极大降低了在低资源条件下适应新语言和新任务的参数与计算开销。
- 系统评估了现实场景下的迁移学习范式:设计并对比了“单源迁移”(从英语迁移到其他语言)和“多源迁移”(从三种语言联合迁移到剩余一种语言)两种范式。这超越了以往简单对比不同语言对的研究,更全面地模拟了现实中可能遇到的资源可用性情况(如只有一个高资源语言支撑 vs. 有多种语言资源可用)。
- 在低资源AD检测中验证了LoRA的有效性:通过消融实验定量证明了,在数据稀缺的跨语言AD检测任务中,即使冻结了大部分预训练参数,仅微调少量LoRA参数也能带来显著的性能提升,证实了该方法在特定垂直领域的有效性。
🔬 细节详述
- 训练数据:
- 数据集:英语(ADReSSo, AD/CN共237人),普通话(NCMMSC, 187人),西班牙语(Ivanova, 262人),希腊语(ADReSS-M, 46人)。数据来自DementiaBank平台。
- 数据预处理:音频转为单声道,重采样至16kHz,截断至30秒。
- 数据增强:论文未提及。
- 数据划分:在单源迁移中,目标语言数据按80%/20%划分为微调集和测试集;在多源迁移中,目标语言数据按70%用于测试,剩余30%划分为训练集(80%)和开发集(20%)。源语言使用全部标记数据。
- 损失函数:使用交叉熵损失。为解决源语言数据集中的类别不平衡问题,对损失进行了基于源语言标签频率的加权。
- 训练策略:
- 优化器:AdamW。
- 学习率:源语言预训练阶段为
2 × 10⁻⁴;目标语言微调阶段为5 × 10⁻⁵。 - 调度策略:余弦退火调度器。
- 训练轮数:最多100轮,配合早停(基于开发集损失)。
- 训练流程:两阶段。先在源语言上预训练分类头(和LoRA),再在目标语言上微调LoRA和分类头。
- 标签平滑:在目标语言微调阶段使用。
- 训练/测试重复:每个实验运行5次,报告平均结果。
- 关键超参数:使用Wav2Vec2-large-XLSR-53模型;LoRA插入第19层;LoRA秩
r=8,α=16, 丢弃率0.1;分类器前使用dropout层(具体值未说明)。 - 训练硬件:GPU-enabled PyTorch环境(具体GPU型号和数量未说明)。
- 推理细节:未提及特殊解码策略,模型直接输出分类概率。
- 正则化技巧:使用dropout(分类器和LoRA模块)、标签平滑、权重初始化固定随机种子、早停。
📊 实验结果
主要Benchmark与指标:自建多语言基准。评估指标包括:训练/测试准确率(Train Acc/ Test Acc)、精确率(Precision)、召回率(Recall)、F1分数(F1-score)。
主要结果:
设置 目标语言 训练准确率 测试准确率 AD 召回率 AD F1分数 单源 中文(ZH) 0.9873 0.7796 0.7823 0.8032 西班牙语(ES) 0.9831 0.8023 0.5333 0.8682 希腊语(EL) 0.9705 0.7652 0.7364 0.7538 多源 中文(ZH) 0.9174 0.6417 0.5811 0.6969 西班牙语(ES) 0.9447 0.6734 0.4154 0.7772 希腊语(EL) 0.9125 0.6739 0.6842 0.7059 表2:跨语言评估结果(关键行摘录)。 关键发现:
- 单源优于多源:在所有目标语言上,单源迁移(EN→)的测试准确率均显著高于多源迁移(例如,希腊语:76.52% vs. 67.39%)。
- 过拟合严重:训练准确率(>91%)远高于测试准确率(<81%),表明模型在有限数据上容易过拟合。
- 性能差异:西班牙语在单源测试中准确率最高(80.23%),但其AD召回率(53.33%)最低,表明模型在识别AD患者方面存在困难,可能与数据集不平衡和领域差异有关。
消融实验:
目标语言 单源(无LoRA / 有LoRA) 多源(无LoRA / 有LoRA) 中文(ZH) 0.7112 / 0.7796 0.6310 / 0.6417 西班牙语(ES) 0.7481 / 0.8023 0.6336 / 0.6734 希腊语(EL) 0.6875 / 0.7652 0.6087 / 0.6739 表3:有无LoRA微调的测试准确率对比。 - 结论:无论单源还是多源设置,加入LoRA微调均能稳定提升测试准确率。在单源设置下提升幅度更明显(平均提升约6-8个百分点),证实了LoRA作为参数高效适应工具的有效性。
与SOTA对比:论文未与其他已发表的AD语音检测模型或跨语言迁移学习方法进行直接对比,仅报告了自身框架在不同设置下的结果。
⚖️ 评分理由
- 学术质量:5.5/7 - 创新性体现在将LoRA引入该垂直领域并构建多语言基准,技术路线正确,实验设计包含消融研究。然而,实验规模有限(尤其是希腊语数据极少),多源迁移效果不佳且未深入分析原因,缺乏与现有方法的横向对比,结论的强度和普适性受限。
- 选题价值:2.0/2 - 题目紧扣“低资源”和“早期检测”两大社会与科研痛点,利用语音进行无创、低成本的AD筛查具有极高的应用前景和跨学科价值,与音频/语音处理在健康监测领域的前沿趋势高度相关。
- 开源与复现加成:0/1 - 论文详细说明了模型配置和训练流程,但未提供代码、模型权重或其整合的多语言数据集。虽然依赖的Wav2Vec2.0是公开的,但完整的复现(尤其是数据处理部分)仍存在门槛,因此无加成。