📄 Low-Frequency Harmonic Control for Speech Intelligibility in Open-Ear Headphones
#语音增强 #信号处理 #鲁棒性 #实时处理
✅ 6.5/10 | 前50% | #语音增强 | #信号处理 | #鲁棒性 #实时处理
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Yuki Watanabe(NTT Inc., Tokyo, Japan)(基于作者列表顺序判断,论文未明确标注)
- 通讯作者:未说明
- 作者列表:Yuki Watanabe(NTT Inc., Tokyo, Japan)、Hironobu Chiba(NTT Inc., Tokyo, Japan)、Yutaka Kamamoto(NTT Inc., Tokyo, Japan)、Tatsuya Kako(NTT Inc., Tokyo, Japan)
💡 毒舌点评
亮点:巧妙地利用了语音基频与谐波之间的能量关系,通过“抑制基频、增强谐波”这种反直觉的方式,在特定硬件限制(小扬声器低频弱)和环境掩蔽(低频噪声强)下找到了一个提升可懂度的“巧劲儿”,想法很有针对性。 短板:实验部分过于“迷你”——仅用8位听众和6个语音样本就得出“显著提高”的结论,说服力不足,且完全没有与经典的语音增强算法(如谱减法、维纳滤波)进行对比,让人无法判断其在现有技术体系中的真实位置。
🔗 开源详情
论文中未提及任何开源计划。具体来说:
- 代码:未提供代码仓库链接或提及开源。
- 模型权重:未提及(本方法无需模型权重)。
- 数据集:未提及公开。所用6个评估样本来自内部数据集,未提供获取方式。
- Demo:未提供在线演示。
- 复现材料:未提供训练细节、配置、检查点或附录说明。仅提供了方法原理和实验条件的概述。
- 论文中引用的开源项目:引用了MATLAB的Audio Toolbox中的
pitch函数用于基频估计。
📌 核心摘要
- 解决的问题:开放式耳机因采用小型扬声器单元导致低频输出不足,在嘈杂环境中(尤其是存在大量低频成分的环境噪声时),语音的低频部分容易被掩蔽,导致可懂度下降。
- 方法核心:提出一种名为“低频谐波控制(LFHC)”的低复杂度后处理方法。核心是通过一个延迟为基频周期2.5倍(τ=τ₀/2.5)的FIR梳状滤波器来抑制语音的基频(F0),并同时增强其第二和第三谐波,然后将处理后的信号通过一个截止频率为5倍基频的低通滤波器,最后与原信号相加。
- 创新之处:与传统强调基频的音高增强不同,本方法反其道而行之,专注于将能量从易被掩蔽的基频重新分配到不易被掩蔽且耳机仍能有效重现的第二、三谐波频带。该方法计算复杂度低,适合在开放式耳机的DSP芯片上实时运行。
- 主要实验结果:在棕色噪声(69 dB SPL)环境下,使用类似MUSHRA的主观评估(但标准为可懂度)。当加权因子α=0.6时,处理后语音的可懂度得分(相对于未处理同音量语音)在6个测试语音样本中的3个上获得了显著提升,对另外3个无显著降低;当α=0.9时,过度处理导致2个样本的可懂度显著下降。散点图显示,处理前第二、三谐波能量相对基频较高的语音,处理收益较小(相关系数-0.93)。详细数据见下表:
| 处理条件 | 声压级 (dB SPL) | 说明 |
|---|---|---|
| OR (原始参考) | 60 | 未经处理的原始语音 |
| OR-3 | 57 | 未经处理,音量降低3 dB |
| OR-6 | 54 | 未经处理,音量降低6 dB |
| LFHC-3(0.6) | 57 | 使用本文方法(α=0.6),音量与OR-3相同 |
| LFHC-3(0.9) | 57 | 使用本文方法(α=0.9),音量与OR-3相同 |
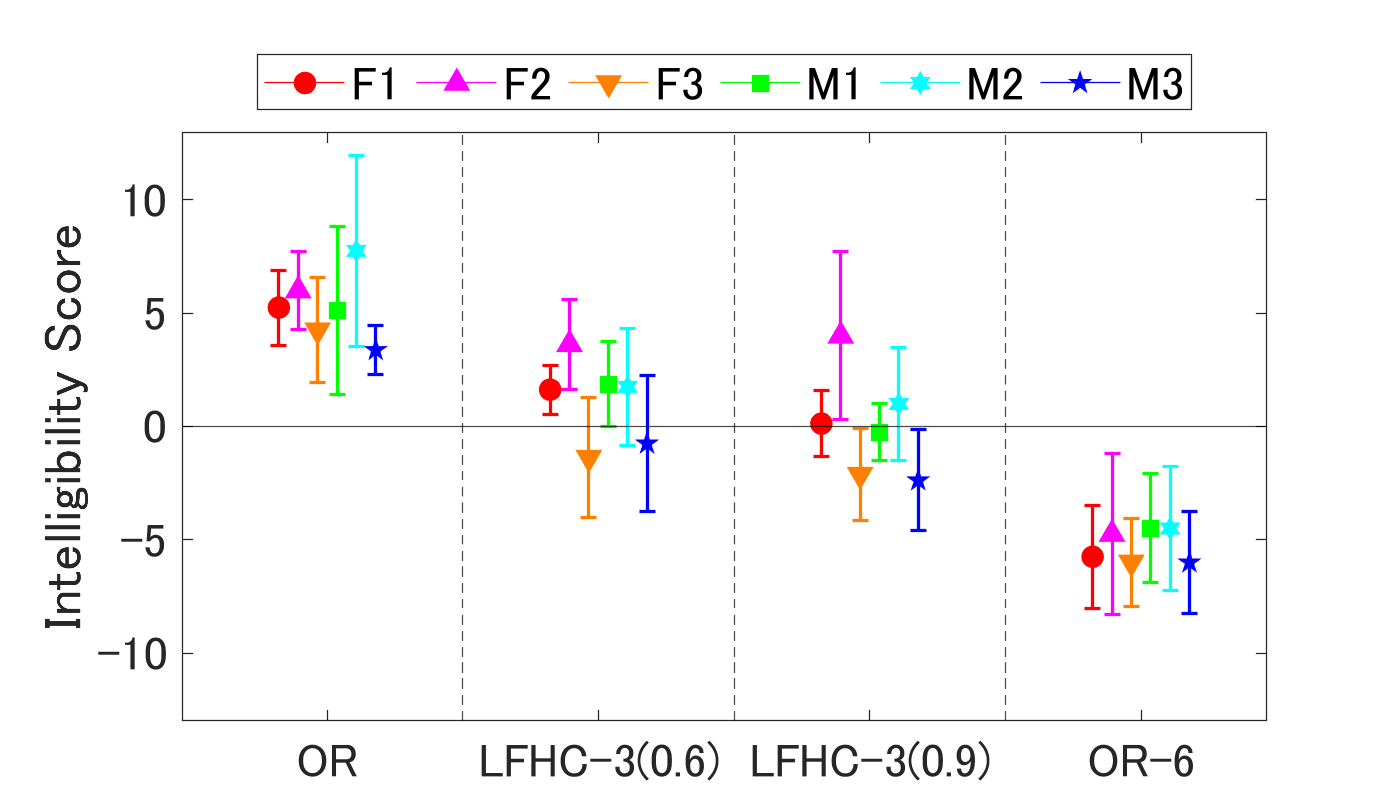 图5(论文中图片4)展示了不同条件下语音可懂度得分的均值及95%置信区间。与未处理的OR-3相比,LFHC-3(0.6)对多数样本有正向提升或无影响,而LFHC-3(0.9)则对部分样本产生负面影响。
图5(论文中图片4)展示了不同条件下语音可懂度得分的均值及95%置信区间。与未处理的OR-3相比,LFHC-3(0.6)对多数样本有正向提升或无影响,而LFHC-3(0.9)则对部分样本产生负面影响。
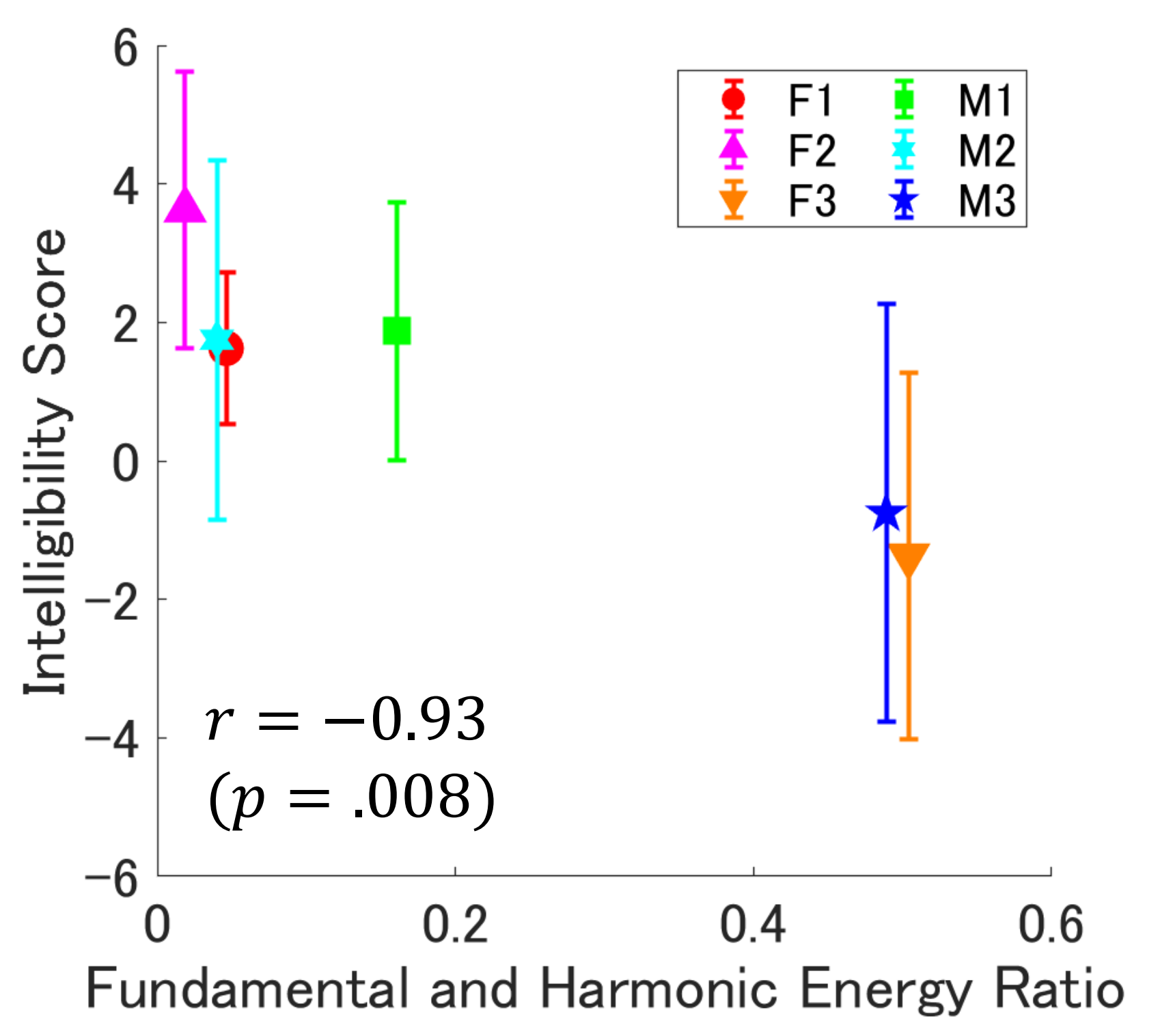 图6(论文中图片5)显示了测试语音样本的(第二谐波能量/F0能量 + 第三谐波能量/F0能量)/2 与使用LFHC-3(0.6)处理后的可懂度得分呈强负相关(-0.93),表明原始谐波结构较弱的语音受益更大。
图6(论文中图片5)显示了测试语音样本的(第二谐波能量/F0能量 + 第三谐波能量/F0能量)/2 与使用LFHC-3(0.6)处理后的可懂度得分呈强负相关(-0.93),表明原始谐波结构较弱的语音受益更大。
- 实际意义:为开放式耳机在噪声环境下的语音通话或播客收听场景提供了一种无需增加音量、计算成本极低的可懂度增强方案,有助于改善用户体验。
- 主要局限性:实验规模非常有限(仅6个测试语音,8位听众),结论的普遍性存疑;缺乏与现有标准语音增强算法的对比,无法确立其技术优势;未探讨该方法对不同语言、不同噪声类型的泛化性能;方法高度依赖准确的基频估计,论文未讨论估计误差的影响及鲁棒性。
🏗️ 模型架构
本文并未提出传统意义上的“模型”架构,而是描述了一个轻量级的信号处理流程(如图1所示)。其输入输出与组件如下:
- 完整输入输出流程:输入语音信号 s[n] → 基频估计 → 梳状滤波(抑制基频、增强谐波) → 低通滤波 → 与原始信号相加 → 输出增强信号 sout[n]。
- 主要组件及功能:
- 基频估计器:对输入信号 s[n] 的每一帧(数十毫秒)进行自相关分析,估计当前帧的基频周期 τ₀。动机:语音的基频在短时内相对稳定。
- 单抽头FIR梳状滤波器:实现延迟信号 r[n] = s[n − τ]。关键创新在于延迟量 τ 被设定为 τ₀/2.5(而非传统的 τ₀),其目的是通过梳状滤波器的频率响应,在基频及其奇数次谐波处形成陷波(抑制),同时在第二、三次谐波处形成峰值(增强)。
- 移动平均FIR低通滤波器:对梳状滤波后的信号 r[n] 进行低通滤波,得到 rLP[n]。截止频率 F_C 设置为5倍基频,目的是限制处理效果,避免对第三谐波以上的高频成分产生不期望的影响。滤波器长度 N 由采样频率 F_S 和 F_C 估算,实际延迟 τ 需补偿该滤波器的群延迟 τ_g。
- 加法器:将低通滤波后的延迟信号 rLP[n] 与原始信号 s[n] 相加,得到最终输出。加权因子 α 控制增强强度。
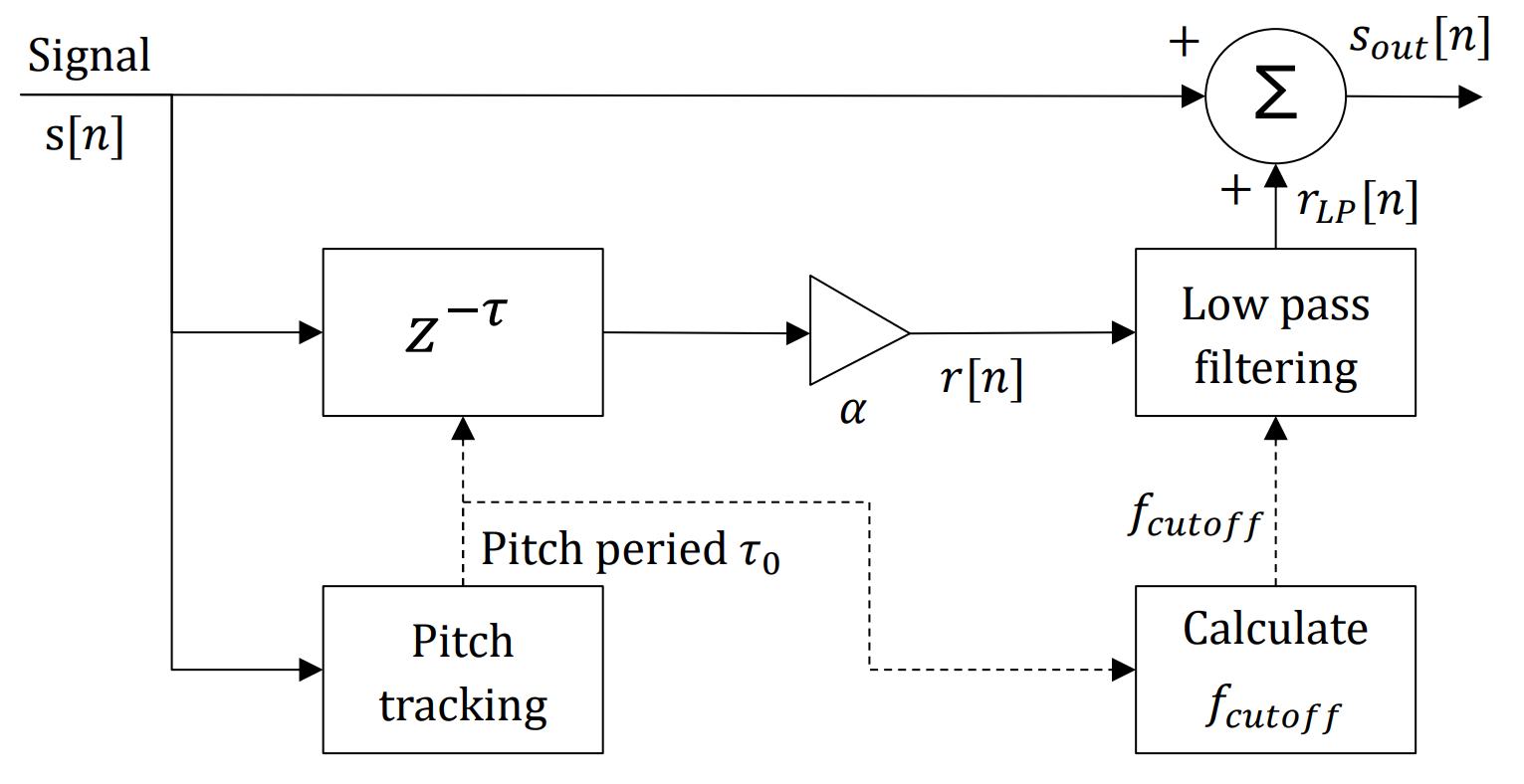 图1(论文中图片0)是传统音高增强的流程图,本文的LFHC方法修改了其中的延迟量τ,并在最终相加前对延迟信号进行了低通加权。
图1(论文中图片0)是传统音高增强的流程图,本文的LFHC方法修改了其中的延迟量τ,并在最终相加前对延迟信号进行了低通加权。
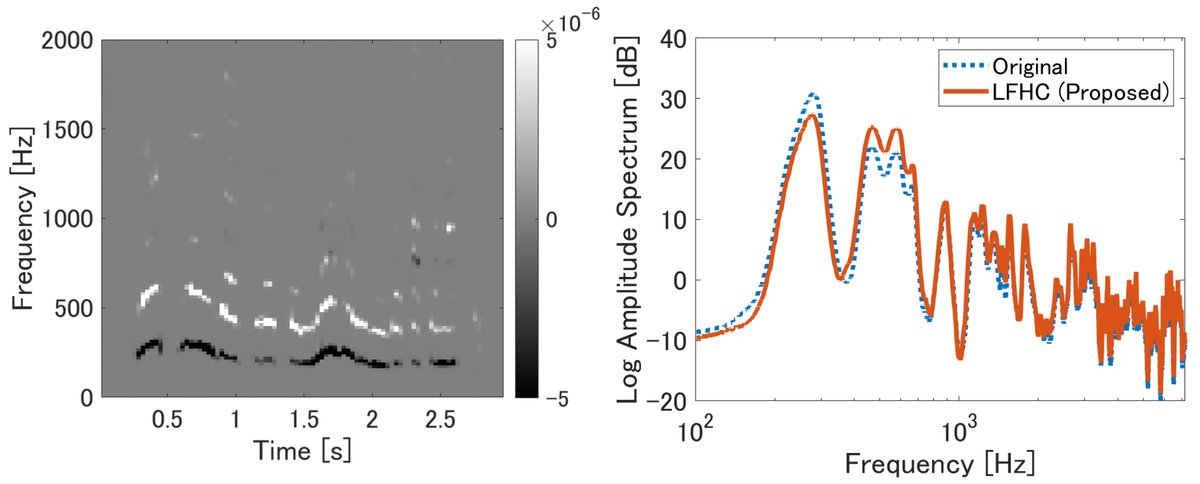 图2(论文中图片1)展示了LFHC处理前后的频谱图对比(左)和频谱包络(右),清晰可见基频被抑制,第二、三次谐波被增强的现象。
图2(论文中图片1)展示了LFHC处理前后的频谱图对比(左)和频谱包络(右),清晰可见基频被抑制,第二、三次谐波被增强的现象。
- 关键设计选择及动机:选择 τ=τ₀/2.5 是为了在抑制基频(接近τ₀/2的效果)和增强第三谐波(避免过于接近τ₀/3,因第三谐波通常能量较弱)之间取得平衡。整个流程基于单抽头FIR和移动平均FIR,计算极其简单,符合实时、低功耗的嵌入式要求。
💡 核心创新点
- 针对硬件缺陷的反向增强策略:传统方法试图补偿耳机的低频衰减(直接增强低频),但易引起失真。本文洞察到开放式耳机低频输出弱与环境低频噪声强的双重困境,转而抑制耳机最无力、噪声最强烈的基频,转而增强耳机仍可有效重现的第二、三次谐波,是一种“扬长避短”的新思路。
- 低复杂度的谐波结构控制实现:利用语音编码后处理中的梳状滤波技术,通过精心选择延迟量(τ₀/2.5),用一个极低复杂度的FIR滤波器实现了对特定谐波的选择性抑制与增强,无需复杂的频域处理或神经网络。
- 针对特定场景的轻量级后处理方案:将语音编解码领域的后滤波(Post-filtering)思想,创新性地应用于解决开放式耳机在噪声环境下的可懂度问题,为这一特定硬件场景提供了实用的解决方案。
🔬 细节详述
- 训练数据:论文中未提及任何训练数据,因为该方法是基于信号处理原理的,无需数据驱动训练。
- 损失函数:未说明,该方法不涉及优化训练。
- 训练策略:未说明。
- 关键超参数:
- 梳状滤波延迟:τ = τ₀/2.5 (经群延迟补偿后)
- 低通滤波器截止频率:F_C = 5 * f₀(f₀为当前基频)
- 低通滤波器长度:N ≈ F_S / (2*F_C),F_S为采样频率。
- 增强强度(加权因子):α(实验测试了0.6和0.9)。
- 训练硬件:未说明。
- 推理细节:
- 基频估计方法:使用MATLAB的
pitch函数(PEF方法)。 - 实时处理:方法本身为帧处理,计算量低,理论上适合实时应用。
- 音频设置:输入采样率16kHz,噪声采样率48kHz。
- 基频估计方法:使用MATLAB的
- 正则化或稳定训练技巧:未说明,方法为非学习型。
📊 实验结果
- 主要基准/指标:主观可懂度评估(类MUSHRA评分)。
- 数据集:未使用标准公开数据集。实验使用了6个从内部30句对数据集中选出的语音样本(3男3女说话人,每人一句),选择标准是第二、三次谐波与基频能量比算术平均值最低的句子。
- 具体数值:见“核心摘要”中的表格及图5、图6描述。关键数字:α=0.6时,在6个测试句中,3句可懂度得分显著提升(置信区间不与0重叠),3句无显著变化;α=0.9时,2句显著下降。能量比与得分的相关系数为-0.93。
- 与最强基线对比:论文未与任何传统的语音增强基线(如谱减法、MMSE估计器等)或近年基于深度学习的语音增强方法进行对比。评估基准(OR-3)是未经处理的语音在较低音量下的表现,而非当前先进的算法。
- 消融实验:未进行严格的消融实验。但通过对比α=0.6和α=0.9的结果,可以推断出增强强度过大对可懂度有负面影响,验证了适度增强的必要性。
- 不同条件下结果:实验仅在一种噪声(棕色噪声,69 dB SPL)下进行,未测试其他噪声类型或不同信噪比。
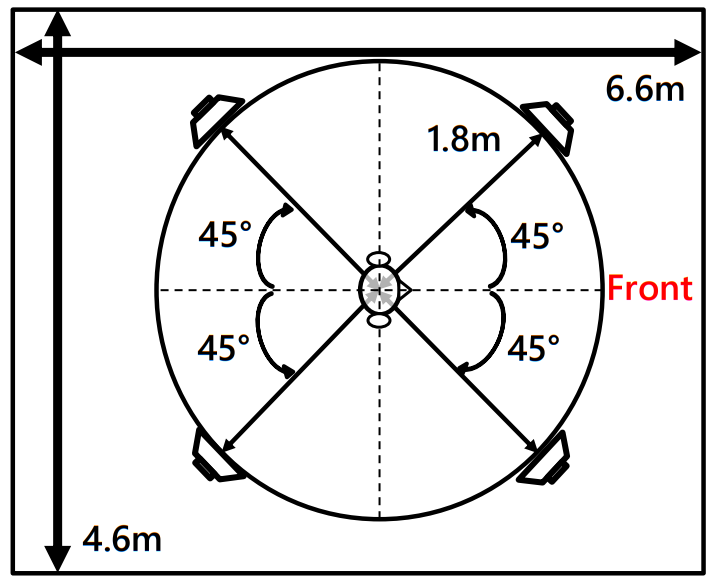 图3(论文中图片2)展示了主观评估的物理环境:噪声由扬声器在房间内播放,语音通过开放式耳机给受试者聆听。
图3(论文中图片2)展示了主观评估的物理环境:噪声由扬声器在房间内播放,语音通过开放式耳机给受试者聆听。
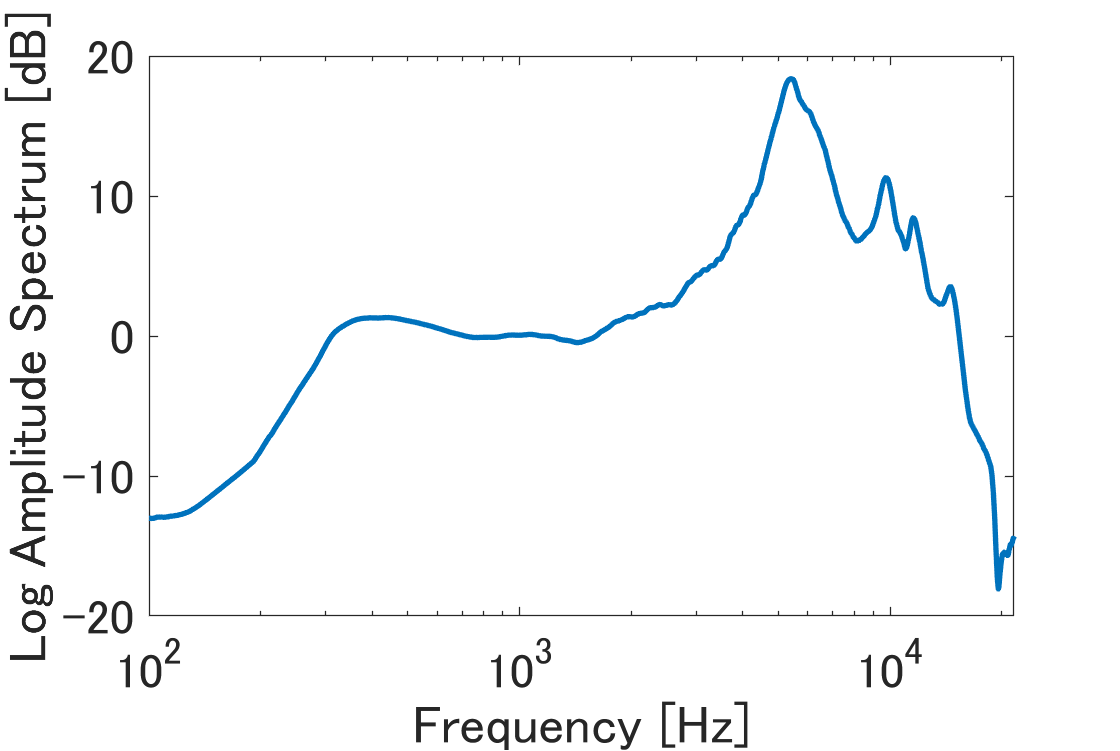 图4(论文中图片3)显示了所用开放式耳机(nwm wired)的耳机传递函数(HP),可见其低频(200Hz以下)输出衰减严重,与论文描述的硬件限制一致。
图4(论文中图片3)显示了所用开放式耳机(nwm wired)的耳机传递函数(HP),可见其低频(200Hz以下)输出衰减严重,与论文描述的硬件限制一致。
⚖️ 评分理由
- 学术质量:5.0/7 - 创新点明确且有实用价值,技术方案自洽。主要扣分项在于实验部分严重不足:样本量(6句语音)和听众数量(8人)过少,使得统计结论可靠性存疑;完全缺乏与现有技术的横向对比,无法定位其真实性能水平;未探讨方法的局限性(如基频估计错误的影响)。
- 选题价值:1.5/2 - 选题切中开放式耳机的实际痛点,应用场景明确(通话、会议),方案轻量,具有直接的产品化潜力。但研究问题非常具体和垂直,对整个语音增强或音频处理领域的推动力有限。
- 开源与复现加成:0.0/1 - 论文未提供任何实现细节的补充材料、代码、数据或预训练模型。关键参数(如基频估计的具体配置、低通滤波器的精确设计)依赖读者自行复现,可复现性低。