📄 Low-Bandwidth High-Fidelity Speech Transmission with Generative Latent Joint Source-Channel Coding
#语音增强 #语义通信 #端到端 #生成对抗网络 #流式处理
✅ 7.5/10 | 前25% | #语音增强 | #端到端 | #语义通信 #生成对抗网络
学术质量 6.5/7 | 选题价值 0.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Guangkuan Li(北京邮电大学)
- 通讯作者:Jincheng Dai(北京邮电大学)
- 作者列表:Guangkuan Li(北京邮电大学)、Shengshi Yao(北京邮电大学)、Sixian Wang(上海交通大学)、Zhenyu Liu(University of Surrey)、Kai Niu(北京邮电大学)、Jincheng Dai(北京邮电大学)
💡 毒舌点评
亮点:该工作聪明地将神经音频编解码器(RVQ-GAN)与联合源信道编码(JSCC)解耦后又紧密融合,利用生成模型在低带宽下提供先验信息,有效缓解了传统JSCC在极低带宽下的质量崩塌问题。短板:虽然声称“节省60%带宽”,但对比基线(Opus+LDPC, Encodec+LDPC)的配置细节(如Opus的码率、LDPC的开销)未在文中清晰界定,使得“节省”的绝对值在不同实际部署条件下可能有所变化。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用LibriSpeech数据集,该数据集为公开数据集。
- Demo:提供了在线演示链接:https://semcomm.github.io/GLJSCC 。
- 复现材料:论文详细描述了模型架构、三阶段训练策略、损失函数、关键超参数(如网络维度、码本大小、学习率等),为复现提供了必要的理论细节。但未提供训练配置文件、预训练检查点或更细粒度的超参数搜索范围。
- 论文中引用的开源项目:引用了Encodec(神经音频编解码器)、5G LDPC编码等作为对比基线。具体代码仓库未在提供的文本中列出。
- 总结:论文提供了理论框架和部分实现细节,并附有Demo,但未开源核心代码和模型,因此严格复现仍需一定工作量。
📌 核心摘要
- 问题:现有的语音联合源信道编码(JSCC)方法在带宽极度受限时,感知质量会急剧下降,难以满足高保真传输需求。
- 核心方法:提出生成式潜在联合源信道编码(GL-JSCC)框架。该框架首先使用RVQ-GAN将语音压缩到一个与人感知对齐的潜在空间,然后在该潜在空间内使用流式Transformer执行JSCC,最后采用三阶段渐进式训练策略进行优化。
- 创新点:与传统在源空间或简单神经网络潜空间进行JSCC不同,本文在生成式潜在空间中进行JSCC,该空间具有更高的稀疏性和感知对齐性,且生成模型本身为低带宽下的重建提供了额外的先验知识。
- 主要实验结果:在AWGN和COST2100衰落信道下,GL-JSCC在低信噪比(SNR)和低带宽条件下均优于传统方法(Opus+LDPC, AMR-WB+LDPC)和神经网络基线(DeepSC-S, Encodec+LDPC)。例如,在SNR=2dB的AWGN信道下,GL-JSCC能达到与Opus+LDPC相同的感知质量(PESQ分数),但节省高达60%的带宽。主观MUSHRA测试也证实了其优越的听感。
- 实际意义:该框架为在带宽受限的弱网络(如工业物联网、偏远地区)中进行高质量语音传输提供了一种有效解决方案,推动了语义通信在音频领域的实用化。
- 主要局限性:性能上限受限于RVQ-GAN神经编解码器本身的重建质量(PESQ分数最高约4);实验主要基于英文语音数据集(LibriSpeech),在其他语言或声学环境下的泛化能力未验证。
🏗️ 模型架构
GL-JSCC的整体架构分为两个核心部分:生成式潜在编解码器(Latent Codec) 和 联合源信道编解码器(JSCC Codec),其流程如公式(1)所示:语音 x -> 潜在编码器 E -> 潜在表示 l -> JSCC编码器 J_e -> 发送符号 s -> 无线信道 -> 接收符号 ŝ -> JSCC解码器 J_d -> 潜在表示 l̂ -> 潜在解码器 D -> 重建语音 x̂。
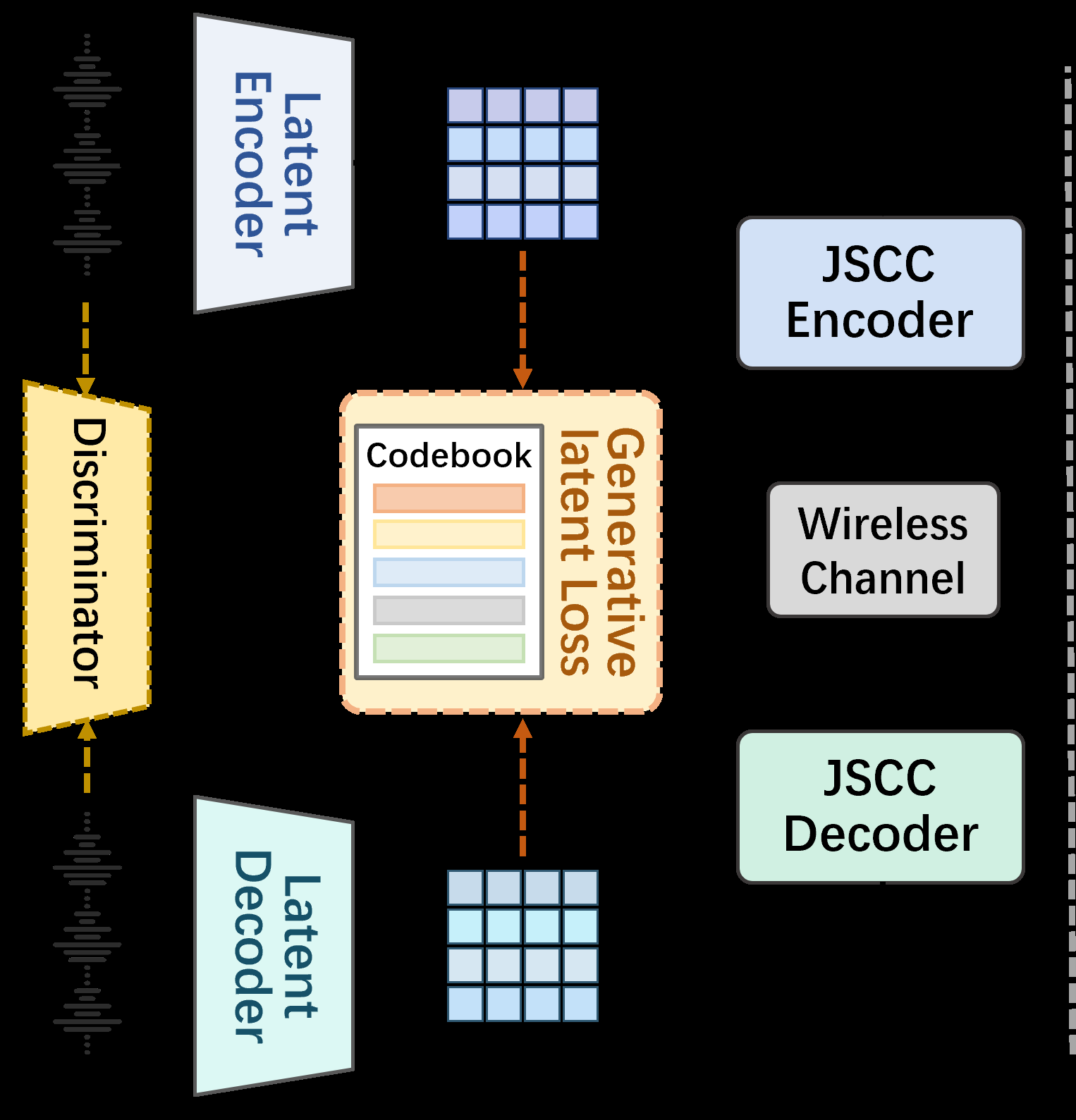 图1: (a) GL-JSCC的整体架构。语音经潜在编码器E压缩为潜在表示l,JSCC编码器Je将其转换为信道符号s传输。接收端经JSCC解码器Jd恢复潜在表示l̂,再经潜在解码器D重建语音x̂。(b) JSCC编码器Je的具体结构,采用带RoPE的流式Transformer,输入为潜在帧和SNR token,输出为信道符号。
图1: (a) GL-JSCC的整体架构。语音经潜在编码器E压缩为潜在表示l,JSCC编码器Je将其转换为信道符号s传输。接收端经JSCC解码器Jd恢复潜在表示l̂,再经潜在解码器D重建语音x̂。(b) JSCC编码器Je的具体结构,采用带RoPE的流式Transformer,输入为潜在帧和SNR token,输出为信道符号。
主要组件:
潜在编解码器(E 和 D):基于RVQ-GAN。
- 编码器 E:由一个卷积层和四个编码块组成,步长分别为(2,4,5,8),总步长为320。对于16kHz语音,每320个采样点(20ms)对应一个潜在帧,产生50帧/秒的潜在表示l ∈ ℝ^{C×T/320},其中C=128。所有卷积均为因果卷积,支持流式处理。
- 残差向量量化(RVQ):包含N_q=32个量化器,每个量化器的码本大小为1024。它通过逐层量化残差,将连续潜在特征l离散化为语义token索引。训练时使用直通估计器(STE)传递梯度。
- 解码器 D:结构与编码器镜像对称,负责从量化后的潜在表示重建语音波形。训练时引入了多尺度短时傅里叶变换(MS-STFT)判别器进行对抗训练,以提升感知质量。
联合源信道编解码器(JSCC Codec):基于流式Transformer。
- JSCC编码器 J_e:如图1(b)所示,是一个8层Transformer(隐藏维度d=200)。它接收潜在帧序列l和对应的SNR token作为输入,将其映射为K个信道符号s。关键设计是:流式处理——每个帧仅关注历史帧(通过RoPE实现);状态缓冲——缓存上一帧的中间特征,避免重复计算;SNR适应——通过输入SNR token,使单一模型能适应不同信噪比(训练时SNR随机取-2dB至10dB)。
- JSCC解码器 J_d:与编码器结构镜像,负责从接收符号ŝ重建潜在表示l̂。
关键设计动机:在生成式潜在空间而非原始语音空间进行JSCC,是因为该空间更稀疏、更符合人感知,且生成模型本身能提供高质量重建的先验,这在低带宽时尤为重要。
💡 核心创新点
- 生成式潜在空间中的JSCC:这是最核心的创新。不同于传统JSCC在源信号空间或简单的端到端神经网络隐空间操作,GL-JSCC首先利用RVQ-GAN构建一个高质量、感知对齐的生成式潜在空间,然后在此空间内进行JSCC。这使得信道编码能更有效地保护语义和感知关键信息。
- 三阶段渐进式训练策略:该策略确保了复杂系统的有效训练和各组件间的对齐。
- 阶段I:独立训练RVQ-GAN,获得稳定的潜在编解码器。
- 阶段II:固定潜在编解码器,训练JSCC模块以最小化潜在表示的MSE并预测RVQ索引,实现低带宽传输适配。
- 阶段III:端到端微调,联合优化除潜在编码器外的所有模块,结合潜在空间监督和原始感知损失,实现最优重建。
- 针对低带宽与低信噪比的针对性设计:包括RVQ带来的高压缩率、Transformer的状态缓冲以实现高效流式推理、以及显式的SNR token以增强模型对恶劣信道的适应能力。
🔬 细节详述
- 训练数据:使用LibriSpeech数据集(英文语音,16kHz采样)。训练时随机截断语音至最长3秒。
- 损失函数:
- 阶段I:L_{Stage I} = ||x - x̂|| + L_f(x, x̂) + λ_{adv}L_{adv}(x, x̂) + λ_{feat}L_{feat}(x, x̂) + L_{commit}。包含时域重建损失、多尺度梅尔谱损失(L_f)、对抗损失(L_{adv})、特征匹配损失(L_{feat})和RVQ的承诺损失(L_{commit})。λ_{adv}和λ_{feat}均设为2。
- 阶段II:L_{Stage II} = D(l, l̂) = α · CE(m, ĥ) + ||l - l̂||₂²。其中CE是RVQ索引的交叉熵损失,α=0.5。
- 阶段III:L_{Stage III} = L_{Stage I} + λ_{pred}D(l, l̂)。在阶段I损失基础上增加了潜在空间监督项D(l, l̂),权重λ_{pred}=10。
- 训练策略:优化器为Adam,批量大小为16,学习率为1×10⁻³。训练分三阶段依次进行。
- 关键超参数:潜在通道数C=128;RVQ量化器数量N_q=32,码本大小1024;JSCC Transformer层数N=8,隐藏维度d=200;信道符号数K根据带宽设置调整(实验中为2kHz或4kHz带宽)。
- 训练硬件:论文中未说明。
- 推理细节:使用状态缓冲实现低延迟流式推理,上下文窗口为50帧。解码时无需特殊策略(如beam search),直接前向传播。
- 正则化/稳定训练技巧:采用对抗训练和特征匹配损失稳定GAN训练;使用STE解决量化器的梯度传播问题;分阶段训练确保稳定性。
📊 实验结果
主要评估设置:数据集LibriSpeech(16kHz)。信道模型:AWGN和COST 2100室内5.3GHz衰落信道。评估指标:客观PESQ,主观MUSHRA测试。
与基线对比:
- 带宽-质量权衡(AWGN信道,SNR=2dB):如图3(a)所示,在0.5-10kHz带宽范围内,GL-JSCC始终优于所有基线。关键数据:在PESQ达到与Opus+LDPC同等质量时,GL-JSCC节省高达60%的带宽;在2kHz带宽下,比Encodec+5G LDPC节省约50%带宽。
- 不同SNR下的性能(AWGN信道,K=2kHz):如图3(b)所示,GL-JSCC在所有SNR(-2dB到10dB)下PESQ得分均最高,优势在低SNR时尤为明显。
- 不同SNR下的性能(AWGN与COST2100信道,K=4kHz):如图3(c)(d)所示,GL-JSCC在两种信道、所有SNR下均表现最佳,展现了强大的鲁棒性。注意DeepSC-S的带宽为12kHz(图中绿线)。
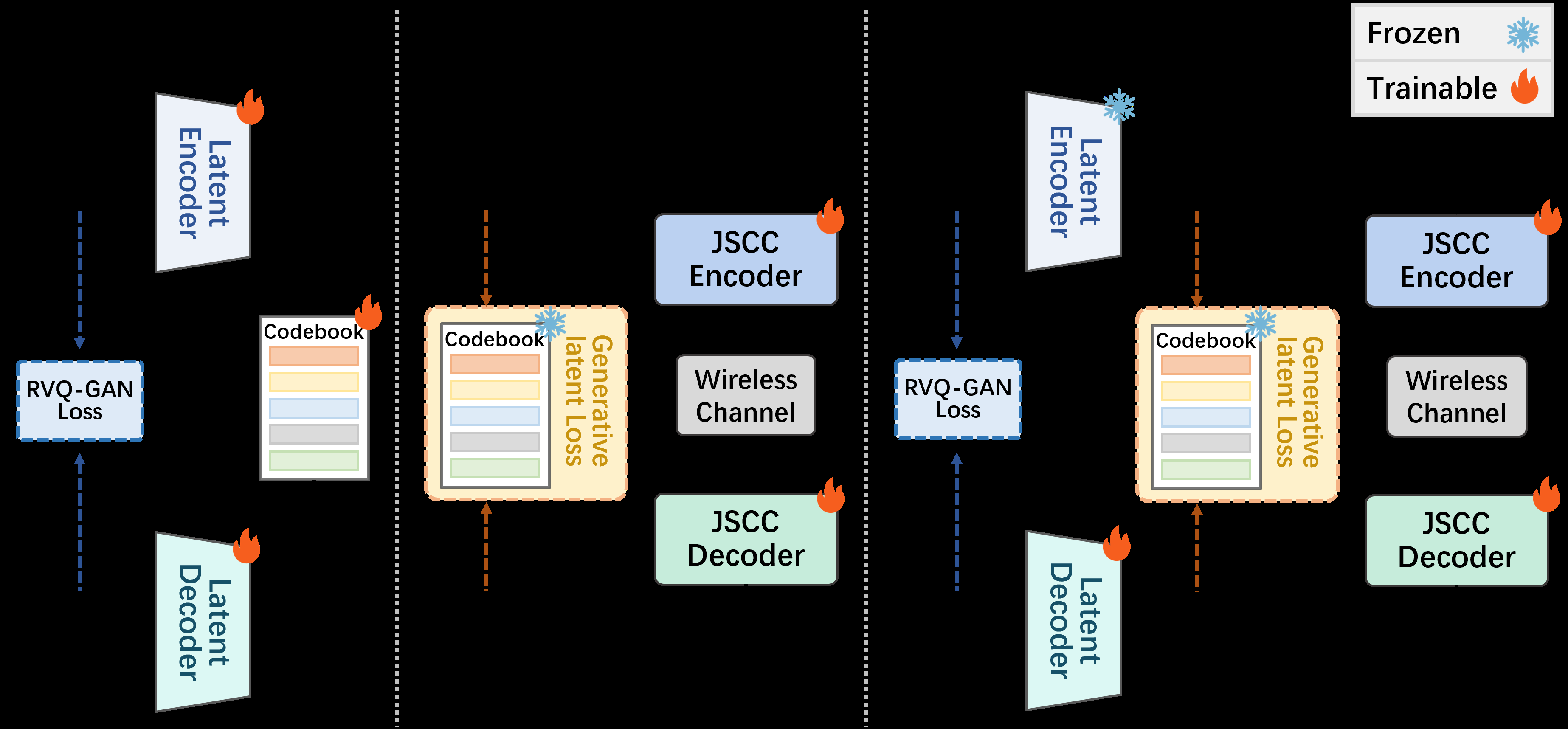 图3: (a) AWGN信道,SNR=2dB时PESQ与带宽关系。GL-JSCC以更少带宽达到更高质量。(b) AWGN信道,K=2kHz时PESQ与SNR关系。(c)(d) AWGN和COST2100信道,K=4kHz时PESQ与SNR关系。GL-JSCC均表现最优。
图3: (a) AWGN信道,SNR=2dB时PESQ与带宽关系。GL-JSCC以更少带宽达到更高质量。(b) AWGN信道,K=2kHz时PESQ与SNR关系。(c)(d) AWGN和COST2100信道,K=4kHz时PESQ与SNR关系。GL-JSCC均表现最优。
主观评估(MUSHRA测试): 如图4所示,在两种低带宽设置下,GL-JSCC的MUSHRA得分均显著高于其他方法。
- SNR=2dB,AWGN信道:GL-JSCC得分最高。
- SNR=6dB,AWGN信道:GL-JSCC得分依然最高,且用更少带宽提供更好听感。 Demo链接已提供。
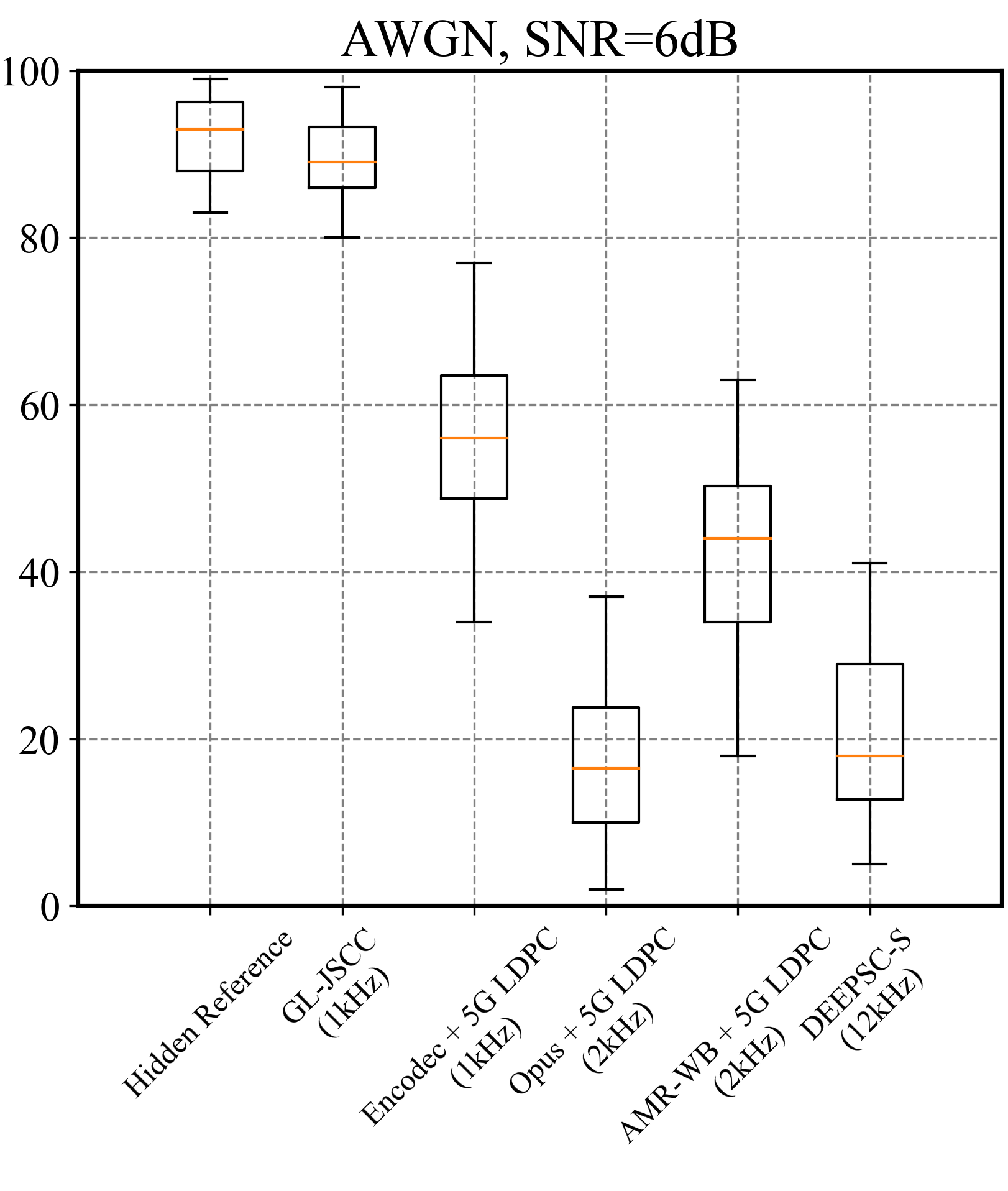 图4: 不同信道条件下的MUSHRA主观评分。(a) SNR=2dB,(b) SNR=6dB。GL-JSCC在低带宽下均获得更高主观分数。
图4: 不同信道条件下的MUSHRA主观评分。(a) SNR=2dB,(b) SNR=6dB。GL-JSCC在低带宽下均获得更高主观分数。
消融研究(潜在空间监督): 表1展示了在2kHz带宽下,有无潜在空间监督(来自阶段II和III的D(l, l̂)损失)的PESQ对比。 关键结论:加入潜在空间监督后,PESQ在所有SNR下均获得显著提升,尤其在低SNR(如1dB)下提升最大(从2.55到3.14),证明了显式监督潜在表示对鲁棒性和感知质量的重要性。
| SNR (dB) | 1 | 3 | 4 | 5.5 | 7 | 10 |
|---|---|---|---|---|---|---|
| w/ ℓsupervision | 3.14 | 3.40 | 3.50 | 3.65 | 3.74 | 3.87 |
| w/o ℓsupervision | 2.55 | 2.88 | 3.02 | 3.19 | 3.31 | 3.43 |
表1:潜在空间监督的消融实验。在2kHz带宽下,加入监督能全面提升PESQ。
⚖️ 评分理由
- 学术质量:6.5/7:创新性在于将生成式模型与JSCC在潜在空间结合,并设计了完整的三阶段训练流程,解决了低带宽下的质量崩塌问题。技术实现严谨,实验设计全面(包括客观/主观评估、多信道模型、消融研究)。主要扣分点:对比的神经编解码器基线(Encodec)并非专为JSCC设计,未能直接体现GL-JSCC相对于“神经JSCC+神经编解码器”这一更强范式的增益;对RVQ-GAN本身重建质量上限(PESQ~4)的分析和改进讨论有限。
- 选题价值:0.5/2:选题聚焦于工业物联网、弱网环境等实际场景中的低带宽高保真语音传输,具有明确的应用需求和前沿性。但相较于通用语音理解或生成任务,应用面相对垂直,且框架的实用部署可能还需考虑计算复杂度、标准化等因素。
- 开源与复现加成:0.5/1:论文未提供代码、模型权重或训练脚本链接。但详细给出了网络结构参数、损失函数公式、训练阶段策略及部分超参数,为同行复现提供了较扎实的理论蓝图。因此给予中等加分。