📄 LLAC: Learned Lossless Audio Codec
#音频无损编码 #生成模型 #模型评估
✅ 7.5/10 | 前25% | #音频无损编码 | #生成模型 | #模型评估
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Khanh Quoc Dinh (Samsung Research, Korea)
- 通讯作者:未说明
- 作者列表:Khanh Quoc Dinh (Samsung Research, Korea), Liang Wen (Samsung R&D Institute China-Beijing, China), Lizhong Wang (Samsung R&D Institute China-Beijing, China), Kwang Pyo Choi (Samsung Research, Korea)
💡 毒舌点评
这篇论文的亮点在于勇敢地将无损音频编码的范式从“预测残差”转向“学习分布”,利用自编码器和注意力机制来建模每个样本的概率,最终在标准测试集上取得了可观的比特节省。但其最大的短板在于“黑箱”特性过强——关键训练细节、模型复杂度、推理延迟一概未提,导致这项看似扎实的工作因严重缺乏可复现性信息而打了折扣,读完让人感觉“学到了一个思路,但不知道怎么用”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开数据集(VCTK, LibriSpeech, ZerothKorean, LJSpeech),但未说明是否提供额外的预处理版本或获取指引。
- Demo:未提及。
- 复现材料:未给出训练细节、配置、检查点或附录说明。
- 论文中引用的开源项目:引用了FLAC和ALAC的GitHub实现用于基线对比[6][7],以及LINNE的官方实现[4]。
- 总结:论文中未提及任何针对LLAC本身的开源计划。
📌 核心摘要
- 问题:传统无损音��编码(如FLAC)依赖线性预测和Rice编码,其编码效率在处理复杂或快速变化的音频信号时存在理论饱和,亟需更先进的技术来突破瓶颈。
- 方法核心:提出LLAC框架,摒弃传统的残差编码,转而使用自编码器神经网络为音频块中的每个样本学习一个概率质量函数(PMF)的参数集(如正态分布的均值和标准差),然后利用该PMF进行算术编码等熵编码以实现无损压缩。同时,引入注意力机制对生成的参数集进行校正,并采用多网络自适应策略处理音频信号的多样性。
- 创新点:首次将自编码器用于无损音频编码的PMF建模;设计了基于注意力的参数校正机制,利用过去样本的真实值和预测值进行动态调整;通过按信号梯度分类并训练多个专用网络,提升了模型对不同音频类型的适应性。
- 主要实验结果:在四个语音数据集(VCTK, LibriSpeech, ZerothKorean, LJSpeech)上进行了广泛对比。LLAC的平均比特率为6.9463 bits/sample,平均压缩率为43.41%。与FLAC相比,平均节省了约10.92%的比特;与已有的神经网络方法LINNE相比,平均节省了约7.25%。消融实验证明,参数校正机制贡献巨大(去除后平均比特开销增加15.33%),多网络优化也有明显作用(去除后开销增加2.14%)。
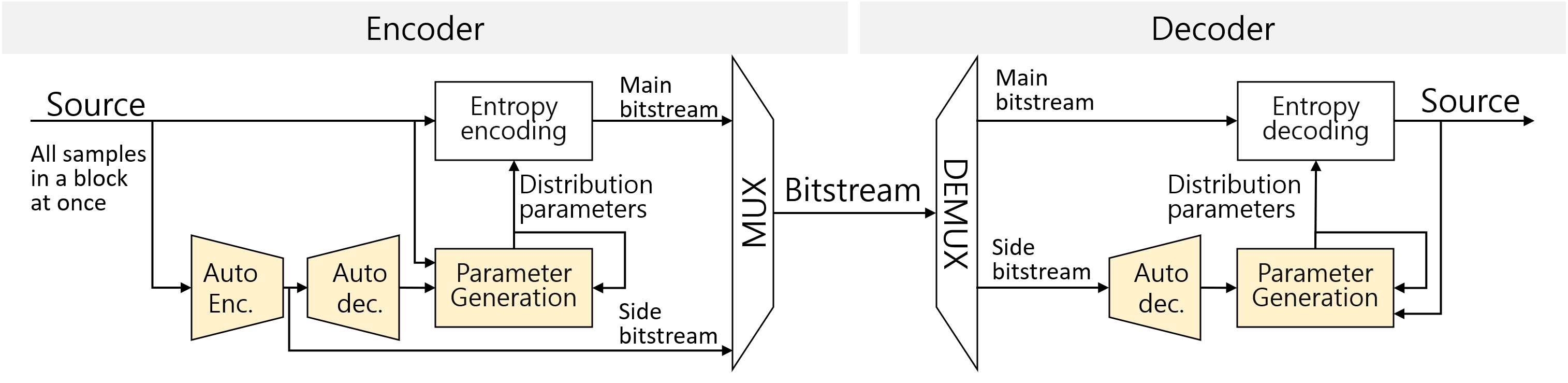 图1说明:展示了LLAC的整体流程。输入音频块x通过编码器网络生成瓶颈表示y。解码器网络从y中同时生成每个样本的PMF初始参数(µNN, σNN)和用于校正的注意力参数(aµ, aσ)。最后,通过注意力机制校正得到最终的PMF参数(µt, σt),用于熵编码。
图1说明:展示了LLAC的整体流程。输入音频块x通过编码器网络生成瓶颈表示y。解码器网络从y中同时生成每个样本的PMF初始参数(µNN, σNN)和用于校正的注意力参数(aµ, aσ)。最后,通过注意力机制校正得到最终的PMF参数(µt, σt),用于熵编码。
- 实际意义:为无损音频编码领域提供了一种全新的、基于学习的架构范式,显著提升了压缩效率,有望在未来应用于对音质有极致要求的高保真音频存储和传输场景。
- 主要局限性:论文未提供模型参数量、计算复杂度、训练时长及硬件配置等关键信息,实际部署的可行性未知;训练细节(如学习率、优化器)缺失;实验仅在语音数据集上进行,对音乐等其他音频类型的泛化能力未验证。
🏗️ 模型架构
LLAC的架构主要包含三个核心组件:自编码器网络、参数校正机制和多网络选择模块。其完整流程如图1所示。
自编码器网络:这是核心的特征提取与PMF参数生成模块。
- 编码器:接收长度为N的音频块x,由4个串行的下采样残差块组成。每个残差块包含两个步长为2的卷积层,最终将输入音频块压缩为一个尺寸小256倍的瓶颈向量y(即
y = EncoderNetwork(x))。y作为紧凑的“侧信息”被编码到比特流中。 - 解码器:接收瓶颈y,由4个对称的上采样残差块组成(每个块含两个上采样步长为2的卷积层)。解码器同时生成三组输出:每个样本的PMF初始均值向量
µNN、初始标准差向量σNN,以及用于参数校正的注意力权重矩阵aµ和aσ(即µNN, σNN, aµ, aσ = DecoderNetwork(y))。
- 编码器:接收长度为N的音频块x,由4个串行的下采样残差块组成。每个残差块包含两个步长为2的卷积层,最终将输入音频块压缩为一个尺寸小256倍的瓶颈向量y(即
参数校正机制:用于提升PMF参数的准确性。
- 均值校正(加性):对于当前样本
t,利用其注意力权重aµ,回顾过去K个样本t-k的真实值x_{t-k}与其初始预测均值µNN_{t-k}的差值,计算一个加性校正项µCRT_t,最终均值µt = µNN_t + µCRT_t(公式5,6)。 标准差校正(乘性):类似地,利用注意力权重aσ,回顾过去样本的绝对归一化误差,计算一个乘性校正项σCRT_t,最终标准差σt = σNN_t σCRT_t(公式7,8)。
- 均值校正(加性):对于当前样本
多网络选择模块:为了适应音频信号的多样性。
- 在训练时,根据音频块的平均梯度
gx(公式10)将其划分为M个类别,并为每个类别训练一个独立的自编码器模型。 - 在测试时,编码器会运行所有M个网络,并将选择的最佳网络索引
Cx写入比特流,解码器据此加载对应网络进行解码。
- 在训练时,根据音频块的平均梯度
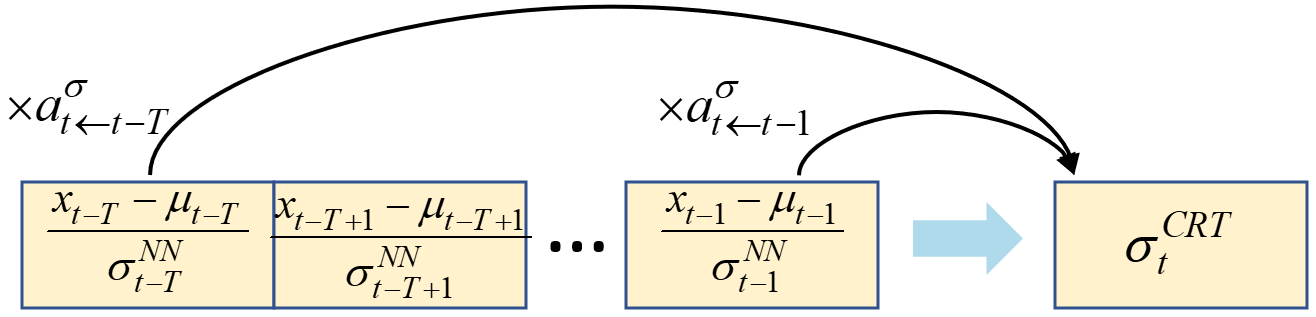 图2说明:详细展示了注意力机制如何校正PMF参数。子图(a)显示对于均值,注意力权重
图2说明:详细展示了注意力机制如何校正PMF参数。子图(a)显示对于均值,注意力权重 aµ 作用于过去样本的“残差”(真实值-预测均值)以产生加性校正。子图(b)显示对于标准差,注意力权重 aσ 作用于过去样本的“归一化绝对误差”以产生乘性校正。
💡 核心创新点
- 从残差编码到概率学习的范式转移:这是最大的创新。传统方法(FLAC等)的核心是预测-残差-Rice编码。LLAC完全摒弃此框架,改为使用神经网络直接建模每个样本取值的概率分布(PMF),再利用算术编码等熵编码技术进行压缩。这突破了线性预测和固定Rice编码的效率天花板。
- 基于注意力的样本级参数动态校正:不仅利用神经网络生成一个全局的PMF参数,还设计了一个精巧的注意力机制,允许模型根据过去样本的真实值和预测值的偏差,对当前样本的PMF参数进行动态的、逐样本的校正。这增强了模型对预测不确定性的捕捉能力。
- 基于信号特征的多模型自适应策略:认识到“一刀切”模型的局限性,提出根据音频块的梯度变化特征(反映信号的瞬态/平缓程度)对其进行分类,并为每一类训练一个专用网络。编码时动态选择最合适的网络,这是一种简单但有效的领域自适应设计。
🔬 细节详述
- 训练数据:使用了四个公开语音数据集:VCTK Corpus v0.92 [8], LibriSpeech [9] (100小时训练集), ZerothKorean [10], LJSpeech [11]。VCTK和LJSpeech按80%/20%随机划分训练/测试集。未说明数据预处理、增强策略及每个数据集的具体使用规模。
- 损失函数:以最小化算术编码的熵(公式1)为目标训练网络。即网络输出参数θ(µ, σ)定义的概率分布pt(xt),并计算其信息熵
-Σ pt * log2(pt)作为损失。 - 训练策略:未说明学习率、warmup、batch size、优化器、具体训练步数(仅提及最终模型训练了1.6M迭代)、学习率调度策略。
- 关键超参数:未说明模型具体大小(参数量)、卷积核尺寸、通道数、瓶颈向量y的维度、注意力窗口长度K、网络类别数M等。
- 训练硬件:未说明。
- 推理细节:编码时,需运行M个网络进行选择,并传输最佳网络索引。算术编码的具体实现未说明。论文未探讨流式处理设置。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文在四个语音数据集上与多种基线方法进行了对比,并提供了详细的消融实验。
表1:LLAC与现有方法的性能对比
| 数据集 | FLAC | ALAC | MPEG4-ALS | LINNE | LLAC (Ours) |
|---|---|---|---|---|---|
| 比特每样本 (Bit per sample) | |||||
| VCTK | 6.4542 | 6.6453 | 6.3766 | 6.2998 | 5.9739 |
| LibriSpeech | 8.8328 | 8.9776 | 8.5518 | 8.4859 | 8.0519 |
| ZerothKorean | 6.8798 | 7.2517 | 6.5941 | 6.5415 | 5.7993 |
| LJSpeech | 9.0122 | 9.3107 | 8.6652 | 8.5941 | 7.9600 |
| 平均值 | 7.7948 | 8.0463 | 7.5469 | 7.4803 | 6.9463 |
| 压缩率 (Compression ratio) | |||||
| VCTK | 40.34% | 41.53% | 39.85% | 39.37% | 37.34% |
| LibriSpeech | 55.21% | 56.11% | 53.45% | 53.04% | 50.32% |
| ZerothKorean | 43.00% | 45.32% | 41.21% | 40.88% | 36.25% |
| LJSpeech | 56.33% | 58.19% | 54.16% | 53.71% | 49.75% |
| 平均值 | 48.72% | 50.29% | 47.17% | 46.75% | 43.41% |
| LLAC的比特节省率 (Bit saved by LLAC) | |||||
| VCTK | -7.44% | -10.10% | -6.32% | -5.17% | 0.00% |
| LibriSpeech | -8.84% | -10.31% | -5.85% | -5.11% | 0.00% |
| ZerothKorean | -15.71% | -20.03% | -12.05% | -11.35% | 0.00% |
| LJSpeech | -11.68% | -14.51% | -8.14% | -7.38% | 0.00% |
| 平均值 | -10.92% | -13.74% | -8.09% | -7.25% | 0.00% |
注:节省率为负表示LLAC优于该方法。
关键结论:LLAC在所有测试集上均取得了最佳的比特每样本和压缩率。平均而言,它比FLAC节省10.92%的比特,比当前神经网络方法LINNE节省7.25%的比特。
表2:消融实验
| 方法 | VCTK | LibriSpeech | ZerothKorean | LJSpeech | 平均比特开销 |
|---|---|---|---|---|---|
| 完整LLAC (比特/样本) | 5.9739 | 8.0519 | 5.7993 | 7.9600 | 0.00% |
| 去除参数校正 (w/o Correct.) | 6.9224 | 8.8888 | 6.9844 | 9.1232 | +15.33% |
| 去除多网络优化 (w/o Optimiz.) | 6.0128 | 8.0916 | 6.1601 | 8.0564 | +2.14% |
关键结论:去除参数校正机制会导致平均比特开销大幅增加15.33%,证明了该机制的不可或缺性。去除多网络优化也会带来2.14%的开销,说明其对提升性能有积极作用。
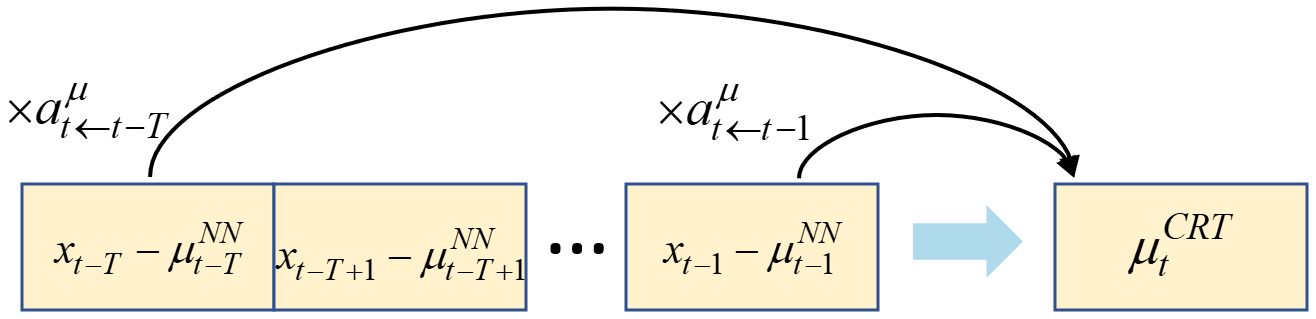 图3说明:论文中提到的图3内容在提供的文本中没有具体描述。根据上下文,它可能是与消融实验或注意力机制可视化相关的图表,但无法基于现有信息进行解读。
图3说明:论文中提到的图3内容在提供的文本中没有具体描述。根据上下文,它可能是与消融实验或注意力机制可视化相关的图表,但无法基于现有信息进行解读。
⚖️ 评分理由
- 学术质量:6.0/7:创新性突出,提出了清晰的范式转移路径;技术路线自洽,实验对比全面且结果显著。但扣分点在于:网络具体设计细节模糊,所有训练与超参数信息完全缺失,严重削弱了论文的技术严谨性和可评估性。
- 选题价值:1.5/2:无损音频编码是经典且有实际需求的任务,用机器学习方法突破传统瓶颈具有明确的理论和应用价值。但该任务领域相对垂直,不如通用音频理解或生成任务那样吸引广泛研究者。
- 开源与复现加成:0.0/1:论文未提供任何代码、模型或复现相关信息。引用的开源工具(如FLAC)仅是基线比较对象,与本文核心贡献的复现无关。这导致工作完全无法验证或应用。